扩散 Transformer 策略:用于通才视觉-语言-动作学习的规模化扩散 Transformer
25年2月来自上海AI实验室、浙大、香港中文大学、北大、商汤科技、清华和中科院香港科学创新研究院的论文“Diffusion Transformer Policy: Scaling Diffusion Transformer for Generalist Vision-Language-Action Learning”。
最近,在多样化的机器人数据集上进行预训练的大型视觉-语言-动作模型,已展示出利用少量域内数据泛化到新环境的潜力。然而,这些方法通常通过小型动作头预测单个离散或连续动作,这限制处理多样化动作空间的能力。相比之下,用大型多模态扩散Transformer(称为扩散Transformer策略)对连续动作序列进行建模,其中直接通过大型Transformer模型对动作块进行去噪,而不是使用小型动作头进行动作嵌入。通过利用Transformer的扩展能力,所提出的方法可以有效地在大型多样化机器人数据集上对连续末端执行器动作进行建模,并获得更好的泛化性能。
大量实验证明,扩散Transformer策略在 Maniskill2、Libero、Calvin 和 SimplerEnv 以及真实世界的 Franka Arm 上的有效性和泛化性,与 OpenVLA 和 Octo 相比,在 Real-to-Sim 基准 SimplerEnv、真实世界的 Franka Arm 和 Libero 上实现一致更好的性能。具体来说,所提出的方法无需任何花哨的手段,在 Calvin 任务 ABC→D 中仅使用单个第三视角摄像机流就实现最佳性能,将一行 5 个任务中连续完成的平均数量提高到 3.6 个,并且预训练阶段显著提高 Calvin 上的成功序列长度超过 1.2。
传统的机器人学习范式通常依赖于为特定机器人和任务收集的大规模数据,但由于现实世界中机器人硬件的限制,为通用任务收集机器人数据既耗时又昂贵。如今,自然语言处理和计算机视觉中的基础模型 [37, 46– 48, 58] 在广泛、多样、与任务无关的数据集上进行预训练,已展示出强大的能力,无论是零样本还是使用少量任务特定样本解决下游任务。原则上,暴露于大规模多样化机器人数据集的通用机器人策略,可能会提高下游任务的泛化和性能 [6, 7]。然而,在具有多样化传感器、动作空间、任务、相机视图和环境的大规模跨具身数据集上训练通用机器人策略是一项挑战。
为了实现统一的机器人策略,现有的研究直接将视觉观察和语言指令映射到具有大型视觉-语言-动作模型的动作上,用于机器人导航 [62, 63] 或操控 [6, 7, 28, 69],并展示对新环境的零样本或少样本泛化。机器人 Transformers [6, 7, 50] 提出基于 Transformer 架构的机器人策略,并通过在大规模 Open X-Embodiment 数据集 [50] 上进行训练展示稳健的泛化能力。Octo [69] 遵循带有扩散动作头的自回归 Transformer 架构,而 OpenVLA [28] 则将动作空间离散化,并利用预训练的视觉-语言模型来构建暴露于 Open X-Embodiment 数据集 [50] 的 VLA 模型。尽管那些视觉-语言-动作 (VLA) 模型 [28, 69] 已经显示出从大型跨具身数据集 [50] 中学习机器人策略的潜力,但跨具身数据集中机器人空间的多样性仍然限制泛化。
最近的扩散策略 [12, 26, 57, 77] 已经展示其在机器人策略学习中的稳定能力,用于使用 UNet 或交叉注意架构进行单任务模仿学习,而扩散Transformer则展示其在多模态图像生成中的可扩展性 [52]。具体而言,Octo [69] 提出一种通用策略,该策略使用以自回归多模态 Transformer 单嵌入为条件的小型 MLP 网络,对动作进行去噪。然而,大规模跨具身数据集的机器人空间,包含各种摄像机视图和不同的动作空间,这对小型 MLP 分别对单动作头嵌入为条件的每个连续动作进行去噪提出重大挑战。同时,先前的扩散策略 [26, 57, 69] 首先将历史图像观察和指令融合到嵌入中,然后再进行去噪过程,这可能会限制动作去噪学习,因为动作预期通常直接依赖于详细的历史观察,而不是融合嵌入。
去噪扩散技术 [8、15、21、52、59] 是图像生成的先驱,而最近的扩散策略 [9、10、12、26、35、57、71、72、77] 与之前的机器人策略相比,表现出强大的多模态动作建模能力。当前的扩散策略方法通常遵循 Unet 结构或浅层交叉注意网络来完成单个操作任务,而大规模多模态扩散策略研究甚少。例如,3D 扩散策略 [77] 对以 3D 点云为条件的策略进行去噪,而 3D 3D diffuser actor [26] 提出一种基于点云的交叉注意 3D 扩散策略。最近的通用策略 Octo [69] 使用小型 MLP 扩散器对 Transformer 模型的嵌入进行降噪处理。
语言条件策略 [11, 19, 39, 45, 56, 78] 更适合实际应用,并且具身社区对通才机器人策略的兴趣日益浓厚,其基础多模态模型可用于机器人导航 [4, 23, 62, 63, 67, 76] 和操控 [2, 5– 7, 16, 17, 25, 28, 40, 42, 50, 51, 56, 60, 64, 65, 69, 74, 75]。最近的方法 [6, 7, 28, 50, 69] 旨在通过可扩展的视觉-语言-动作模型实现通才策略。[6, 7, 28, 50] 通过将机器人动作的每个维度分别离散化为 256 bins来构建动作 tokens。然而,这种离散化策略会导致机器人执行的内部偏差。
DiT,是一个用于通才机器人策略学习的扩散 Transformer 架构。与之前的机器人 transformer 模型 [6、7、28、50、69] 类似,利用 transformer 作为基础模块,保留大规模跨具身数据集的可扩展性。
架构
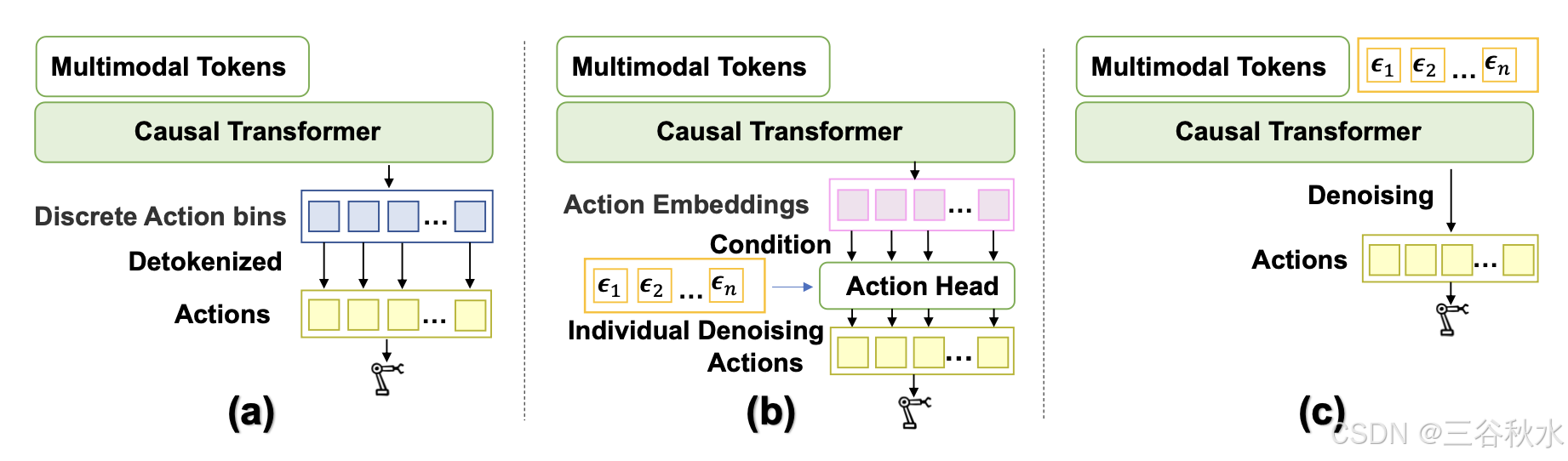
如图所示不同的机器人策略架构:
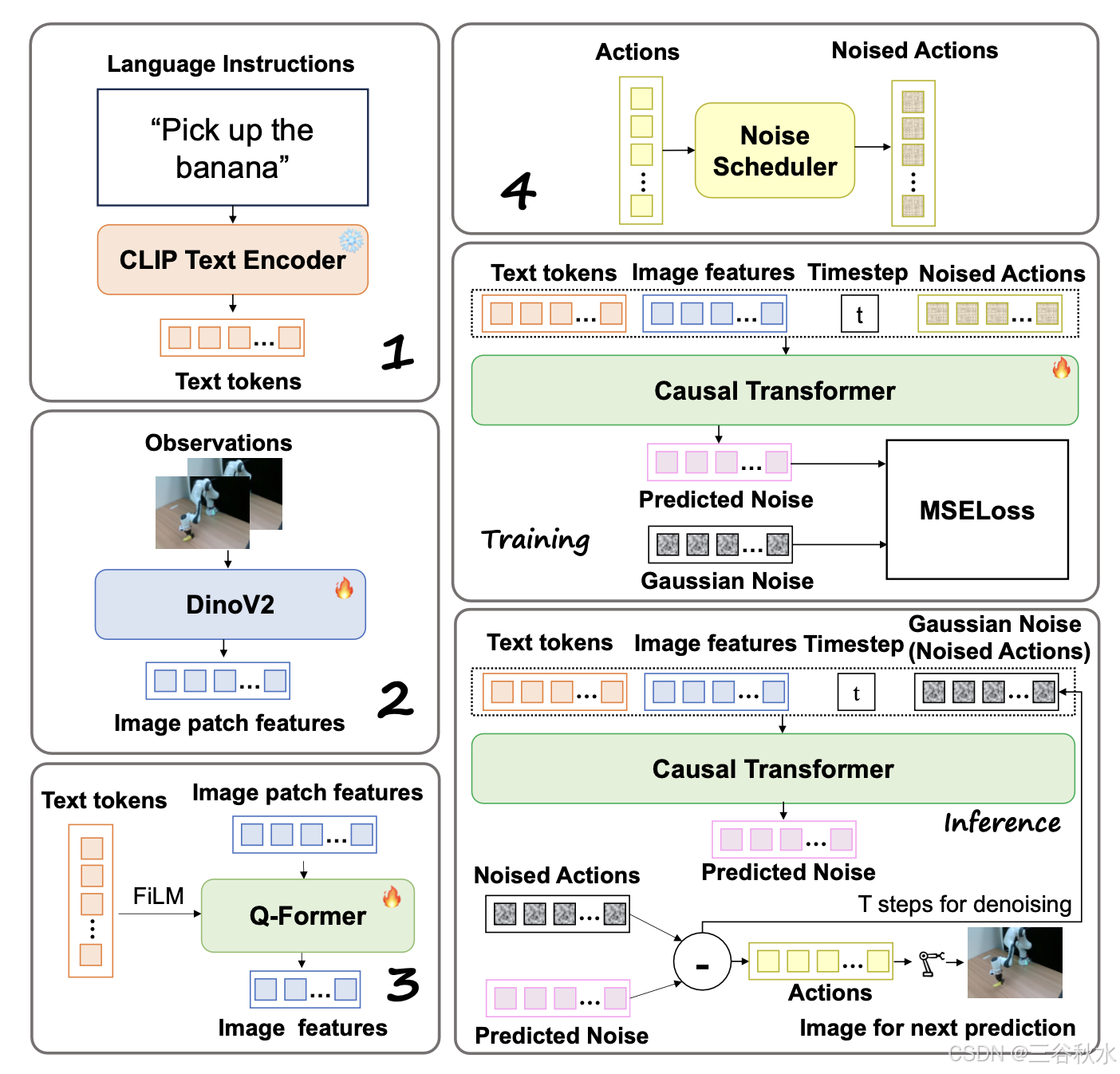
指令token化。语言指令由 frozon CLIP [55] 模型token化。
图像观察表示。图像观察首先传递到 DINOv2 [49] 以获得图像块特征。注:DINOv2 是在与机器人数据不同的网络数据上训练的,因此通过端到端的方式与 Transformers 一起联合优化 DINOv2 参数。
Q-Former。为了降低计算成本,结合 Q-Former [30] 和 FiLM [53] 条件,根据指令上下文从 DINOv2 [49] 的块特征中选择图像特征。
动作预处理。用末端执行器动作,并用 7D 向量表示每个动作,包括 3 个平移向量维度、3 个旋转向量维度和 1 个夹持器位置维度。为了将维度与图像和语言token对齐,只需用零填充连续动作向量即可构建动作表示。仅在去噪扩散优化期间将噪声添加到 7D 动作向量中。
架构。核心设计是扩散Transformer结构 [52],它对动作token块进行去噪,而不是对每个单个动作token进行去噪,直接以图像观察和指令token为条件,通过具有因果Transformer的上下文条件风格进行条件化,即,只需将图像特征、语言token和时间步嵌入连接到序列的前面,平等地处理来自指令token的嘈杂动作,如图所示。这种设计保留了Transformer网络的缩放属性,并允许直接以图像块为条件进行去噪学习,从而有助于模型捕捉历史观察中的详细动作变化。该模型以语言指令和图像观察为条件,具有因果Transformer结构,由添加到连续动作中的噪声进行监督。换句话说,用大型Transformer模型直接在动作块空间中执行扩散目标,这与具有几个 MLP 层的共享扩散动作头不同 [69]。
提出的扩散Transformer策略是一种通用设计,可以扩展到不同的数据集,并表现出色。同时,还可以向Transformer 结构中添加其他观察token和输入。
训练目标
在架构中,去噪网络 ε_θ(x^t, c_obs, c_instru, t) 是整个因果Transformer,其中 c_obs 是图像观察,c_instru 是语言指令,t ∈ 1, 2, …T 是实验中的步进索引。在训练阶段,在时间步 t 处采样一个高斯噪声向量 x^t ∈ N (0, I),其中 T 是去噪时间步数,并将其作为 aˆ 添加到动作 a 中以构造噪声动作token,最后根据去噪网络 ε_θ(aˆ, c_obs, c_instru, t) 预测噪声向量 xˆ,其中 t 是在训练期间随机采样的。利用 xt 和 ˆx^t 之间的 MSE 损失优化网络。
为了生成一个动作,使用优化的 Transformer 架构 ε_θ 从采样的高斯噪声向量 x^T 应用 T 步去噪,如下所示,
xt−1 = α(xt−γε_θ(xt, c_obs, c_instru, t)+N(0, σ^2I))
其中 α、γ、σ 是噪声调度器 [21]。在实验中,ε_θ 用于预测添加到操作中的噪声。
预训练数据
为了评估所提出的 Diffusion Transformer 策略,选择 Open X-Embodiment 数据集 [50] 对模型进行预训练。主要遵循 [28, 69] 来选择数据集并为每个数据集设置权重。对类似于 [50] 的动作进行规范化,并过滤掉数据集中的异常动作。
预训练细节
设计所提出的 Diffusion Transformer 架构,并在大型跨具身数据集 [50] 中评估预训练方法。在 Open X-Embodiment 数据集 [50] 的预训练阶段使用 DDPM [21] 扩散目标,T = 1000,而本文用 DDIM [66] 将 T = 100 设置为零样本评估以加速推理。根据 Maniskill2 [18] 的初步实验,用 2 张观察图像并预测 32 个动作块。用 AdamW [38]将 casual transformer 和 Q-Former 的学习率设置为 0.0001,DINOv2 的学习率设置为 0.00001,批量大小设置为 8902。
实验
SimplerEnv [34] 是一个 Real-to-Sim 平台,用于使用模拟平台评估从真实机器人数据中学习的策略。CALVIN(从语言和视觉组合动作)[43] 是一个开源模拟基准,用于学习长期语言条件任务。
LIBERO 是一个通用基准,专注于多任务和终身机器人学习问题中的知识转移[36]。Maniskill2 [18] 是 SAPIEN Maniskill 基准 [44] 的下一代版本,被广泛用于评估具体模型的广义操纵能力。
将 Franka 设置在黑色背景的桌子上。同时,用距 Franka Arm 约 1.5 米的单个第三人称 RGB 相机。考虑到 Franka 设置环境与预训练数据 Open X-Effirmation [68] 中的场景不同,主要在开箱即用生成和小样本生成方面评估所提出的方法。实验中,用相同的场景评估每个模型,并且将物体放置在 Franka Arm 前面的 9 个相似位置中,形成 9 宫格格式。同时,在放置物体的位置上保持较小的差异以进行评估。
为了评估使用少量训练样本进行快速微调的能力,设置两个拾取和放置任务,并进一步收集五个复杂的操作任务,即“拿起碗并将球倒入盒子中”,“打开盒子并拿起盒子内的积木”,“拿起香蕉并将其移入笔筒”,“叠起碗”和“拿起杯子并将咖啡豆从杯中倒入碗中”。为每个任务收集10个样本以进行10次微调泛化。如图展示场景和任务。图中的图像是模型输入。现实环境具有挑战性,因为物体(小于20毫米)与整个场景相比很小。还对域内评估进行简单的评估,用于比较域内泛化下的不同动作策略,其中5个拾取和放置任务包括“绿色积木”,“猕猴桃”,“香蕉在前三个任务中为每个任务收集了 50 条轨迹,而将剩余两个任务(“拾起绿色小块”和“拾起粉色块”)留作分布外评估。

微调细节。在实验中,用 Lora [22] 和 AdamW [38] 在真实的 Franka Arm 上对所提出的方法进行 10,000 步的微调。将 DDPM [21] 的时间步数设置为 100,将批处理大小设置为 512。