每天一篇《目标检测》文献(二)
今天看的是《改进 YOLOv8 的无人机航拍图像小目标检测算法》。
目录
一、摘要
二、背景介绍
三、改进结构介绍
3.1 小目标检测层
3.2 改进骨干网络结构
3.2.1 改进的ConvSPD模块
3.2.2 融合BiFomer注意力模块
3.3 改进Rep-PAN Neck网络
3.4 改进损失函数
四、实验结果
一、摘要
无人机拍摄影像存在大量分布密集的小目标,针对通用目标检测方法对小目标容易造成漏检和错检的 问题,提出了一种改进 YOLOv8 的无人机航拍图像小目标检测算法。首先,利用高分辨率浅层特征信息具有 较小的感受野和更精细的空间信息特性,改进算法增加小目标物体检测头,采用四个特征检测头提升小目标 检测率。其次,设计构造 ConvSPD 卷积模块和 BiFormer 注意力增强模块的小目标检测模块组改进 YOLOv8 骨干网络,有效增强小目标浅层细节特征信息的捕获能力。随后,为确保模型的硬件终端部署需求,采用可 重参数化的 Rep-PAN 模型优化 Neck 网络。 最后,Head 网络采用 Focaler- CIoU 损失函数优化回归定位损 失,提高定位精度。在 VisDrone-2019 数据集上,改进算法平均检测精度达到 51.2%,比 YOLOv8 提高 10.9%, 检测速度为 63.7fps,具有良好的实时性。
二、背景介绍
基于深度学习的YOLO算法采用端到端预测,速度快、检测精度高且易于部署。然而无人机航拍图像中目标分布密集且遮挡严重,导致检测困难。
针对这个问题,也有许多研究人员做出了解决方法,但仍存在目标检测率低、漏检和误检的情况。为了解决这一问题,本文提出了改进的yolov8无人机图像小目标检测算法(UAV Small Object Detection based on YOLOv8,YOLO-UAVSOD)。
三、改进结构介绍
本文改进的网络结构如下:
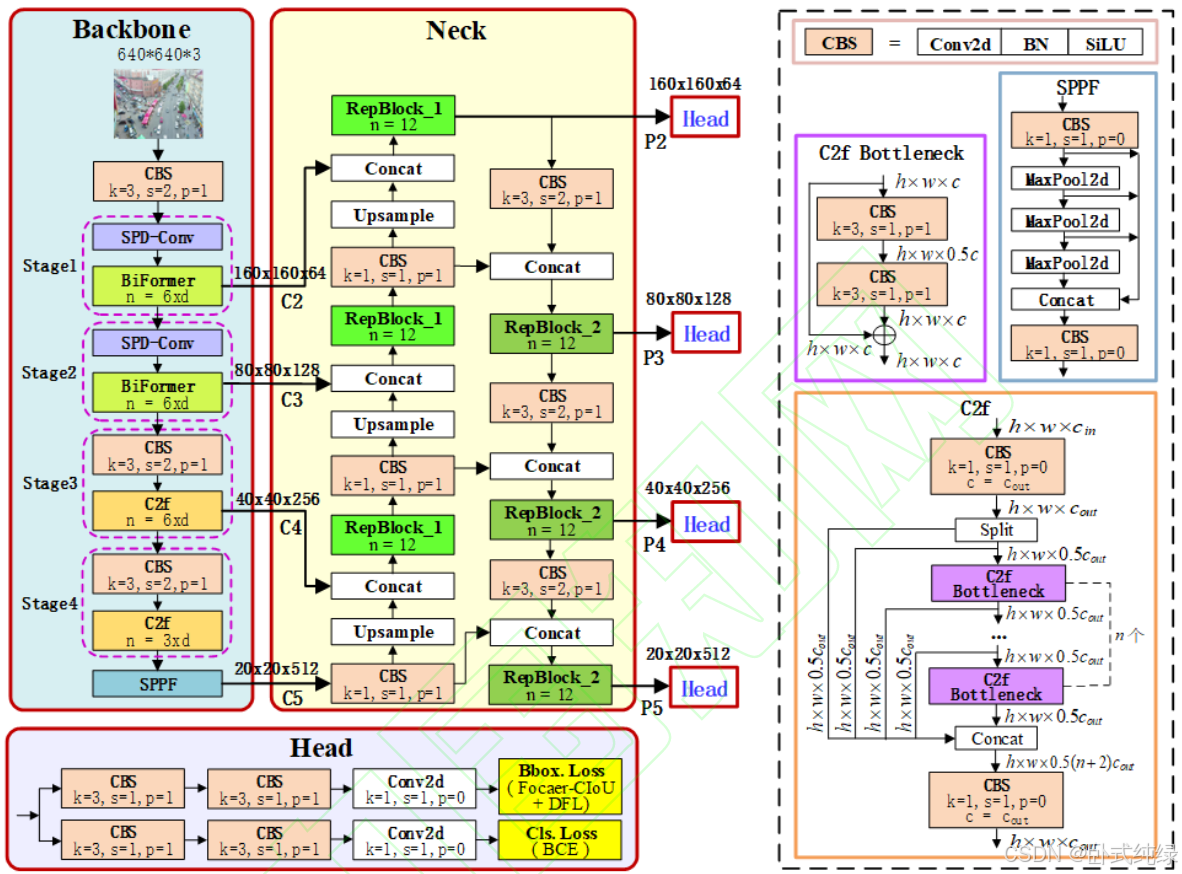
本文做出的改进总结如下:
- 为拥有更小的感受野和更精细的空间信息,采用160×160的小目标检测头获取高分辨率浅层特征。总共采用四个特征提取检测头进行检测,有效降低误检漏检的概率。
- 构造ConvSPD卷积模块和BiFormer注意力增强模块的小目标检测模块组增强小目标浅层细节特征信息捕获能力。
- 采用可重参数化的Rep-PAN模型优化Neck网络。
- Head网络中采用Focaler-CIoU损失函数代替完全交并比损失函数
下面针对各项改进详细介绍。
3.1 小目标检测层
原始yolov8具有三个特征提取检测头:
- C3:检测小目标80×80×128浅层特征信息
- C4:检测中等目标40×40×256中层特征信息
- C5:检测大目标20×20×512深层特征信息
小目标本身缺乏足够纹理和边缘信息,在骨干网络多次下采样过程中绝大部分信息会丢失。而浅层特征信息分辨率高、具有较强空间信息所以在骨干网络(backbone)新增了一个C2浅层特征信息,捕获160×160×64的特征信息图像。同时在neck网络中添加了一个P2小目标检测头,用于检测4×4像素感知区域小目标。骨干网络采用小尺寸3×3非跨步ConvSPD卷积模块检测头,聚焦局部细节提升小目标检测率。最后在neck网络对{C2、C3、C4、C5}四组不同尺度特征信息进行特征融合,实现浅层细粒度信息与深层语义信息互补增强。采用自上而下的方法将深层特征图上采样与浅层特征融合,再自下而上将融合后的浅层特征图下采样与深层特征融合,进一步提升小目标信息。最终将增强后的四组多尺度特征信息用于后续head网络预测。
3.2 改进骨干网络结构
yolov8采用CBS和C2f模块对图像进行特征提取,对小目标检测效果差。本文提出了由ConvSPD和BiFormer注意力增强模块组件的小目标检测模块组用于提取特征。改进的组织结构如上图所示。
主干网络的处理流程如下:
- 输入图像(640×640×3的RGB图像)经过CBS模块进行卷积、批量归一化和SiLu激活函数处理,产生320×320×64×w的特征信息,改进模型中的w设为0.5。
- 经过四个特征学习的阶段(stage1~stage4)网络获得不同分辨率的特征信息。在前两个阶段,ConvSPD和BiFomer模块对特征进行处理。均采用了6个BiFomer模块,提取出160×160×64和80×80×128的浅层特征信息。后两个阶段通过CBS和C2f模块提取出40×40×256和20×20×512 中层、高层特征信息,分别使用6个和3个C2f模块
- 采用空间金字塔池化加速模块(Spatial Pyramid Pooling-Fast,SPPF)增强20×20×512高层特征信息表达能力。本文将前三个阶段和SPPF模块提取到的四个尺度信息整合形成特征金字塔,供颈部网络进行特征增强处理。
3.2.1 改进的ConvSPD模块
传统yolov8采用步长(stride=2)的卷积模块处理图像,虽然能够保留重要空间信息和结构特征,但输出特征图空间分辨率减半,小目标细节特征信息易丢失。故采用改进的ConvSPD替换浅层的CBS卷积模块。模块架构如下所示:
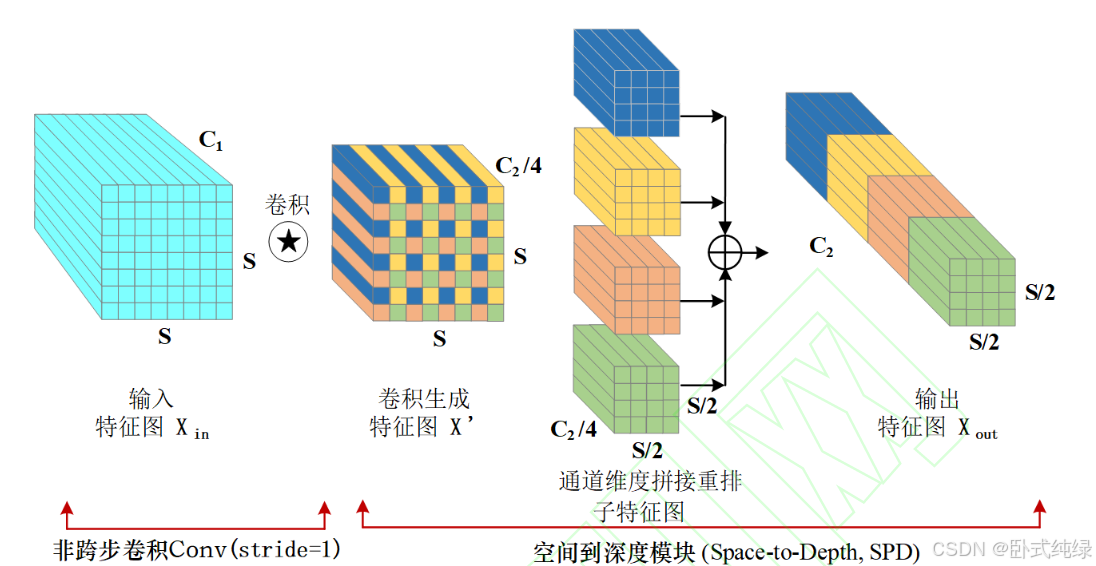
该模块由非跨步卷积模块(Conv)和空间到深度模块(Space-to-Depth,SPD)组合而成。3×3的非跨步卷积能够捕捉更多细粒度空间信息,SPD操作可以将空间特征信息映射到通道维度,降低空间分辨率的同时扩展深度通道数量保留更多空间局部信息,增强对小目标的感知能力。
具体操作过程如下:
- S×S×C1的输入特征图经过3×3(stride=1)的非跨步卷积得到S×S×
的输出特征图
- 对输出特征图采用2倍尺度因子进行隔行隔列的下采样,生成四个尺寸均为
×
- 最终得到一个尺寸为
改进模块的特征提取策略如下:
改进的ConvSPD模块可以在不丢失空间特征信息的同时,获得更多的通道特征,从而增强小目标的检测能力。
对于的输入特征,改进模块通道设置为
,参数量和计算量主要来源于k×k的非跨步卷积模块,计算公式如下:
3.2.2 融合BiFomer注意力模块
本文引进BiFomer注意力模块改进yolov8骨干网络结构,在160×160×64和80×80×128浅层特征提取过程中采用BiFomer替换原C2f。BiFomer网络结构如下:
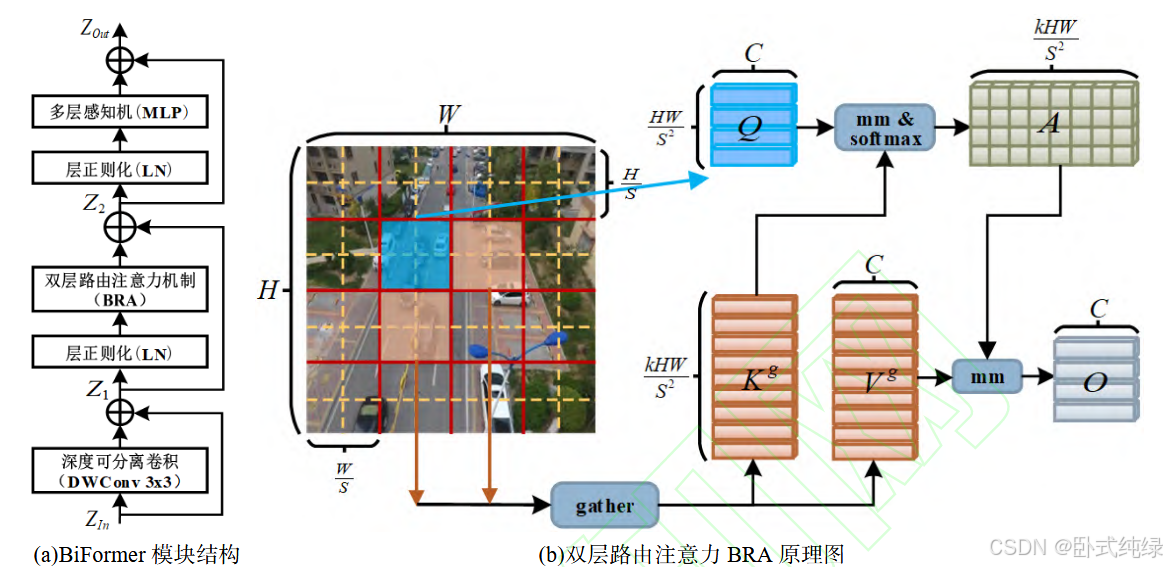
其通过双层路由注意力模块(Bi-Level Routing Attention,BRA)保留细粒度特征的细节信息,提高小目标检测率。BiFomer主要由深度可分离卷积(DepthWise Convolution,DWConv)、层正则化(Layer Normalization,LN)、双层路由注意力机制(BRA)和多层感知机(Multi-Layer Perception,MLP)几部分通过残差运算构成。实现过程有以下三个步骤:
对输入特征图进行区域划分,采用线性投影获取向量参数。将给定二位输入特征图划分成S×S个不重叠的区域块。如上图中红色图像块的划分,每个区域都包含
个特征向量。随后通过整型重组得到特征信息,再通过下面的计算公式线性映射得到查询向量Q、键向量K和值向量V。
其中分别是查询Q、键K和值V的投影权重。
细粒度上构建区域到区域的路由索引矩阵。计算每个划分区域查询向量和键向量的平均值,由此获得区域间相关性零阶矩阵
粗粒度上过滤相关度低的区域块,随后对每个区域块采用topIndex(*)运算,只保留前K个相关性最强的区域块键值对。由下面的公式推导出路由索引矩阵:
其中,第i行参数表示第i个区域块与其最相关的k个路由区域的索引值。
细粒度上获取令牌到令牌的注意力关系。将粗选出k个区域块的K键向量和V值向量通过下面的公式聚集整合运算得到的值:
再由公式计算获得最终的双层路由注意力:
其中,,LCE(*)函数采用5×5深度可分离卷积进行局部增强运算,Attention(*)公式如下所示:
3.3 改进Rep-PAN Neck网络
因为算法需要部署到硬件终端,故采用硬件友好的Rep-PAN模型优化Neck网络。结构如下:
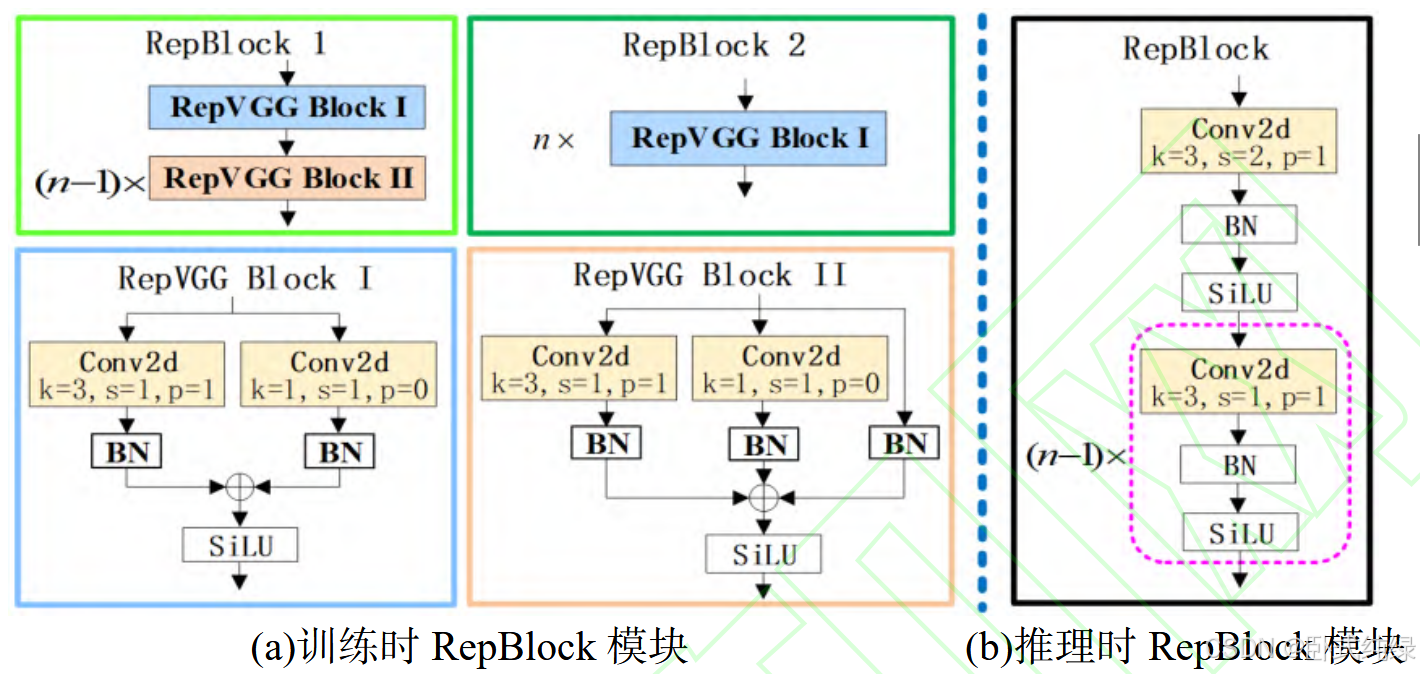
Neck网络模型采用路径聚合特征金字塔网络(PAFPN)方法,将浅层特征细节信息和深层特征语义信息进行双向多尺度融合,显著提升小目标检测效率。特征信息先经过特征金字塔网络(Feature Pyramid Network,FPN)自上而下将深层特征图通过上采样与浅层特征图融合增强语义特征,随后再通过路径聚合网络(Path Aggregation Network,PAN)自底向上将融合后的浅层特征图通过下采样与深层特征图相融合加强定位特征,增加上下文信息。
3.4 改进损失函数
YOLOv8采用的CIoU损失函数因纵横比惩罚项是相对值,造成模糊效应,不能准确反映锚框与目标框之间的真实关系。Focaler-CIoU综合考虑目标几何形状和相对位置,通过线性区间映射可以聚焦不同类型的回归样本。
总损失函数L由三个部分组成:
上述三个λ权重系数分别设置为0.5、1.5和7.5.
通过Task-Aligned Assigner标签分配策略得出前topk个正样本,采用下面的公式得到分类预测损失:
N为正样本个数,N_{cls}表示检测目标类别个数,O_{ij}∈{0,1}表示第i个检测目标框中是否存在第j个类目标,C_{ij}为预测类别,σ(*)表示sigmoid函数。
分布焦点损失函数(Distribution Focal Loss,DFL)通过交叉熵损失函数方法对预测框的回归任务进行优化,使预测坐标逐渐逼近目标框区域,采用以下公式获得回归定位损失:
y表示真实标签,yi和yi+1靠近真实标签y的第i个和第i+1个预测标签。
Focaler-CIoU损失函数结合了Focal-IoU和CIoU损失策略的优点,优化模型提升对难以检测目标的预测能力。具体计算公式如下:
B和分别表示预测框和目标框,w、h和
分别代表预测框和目标框的宽度和高度,分别通过调整位置和重叠度误差参数[d,u]∈[0,1],使之更有效定位小目标。
四、实验结果
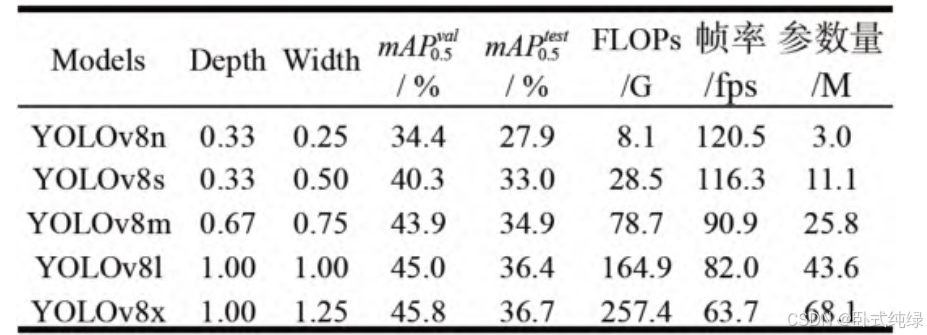
不同yolov8模型下的检测结果
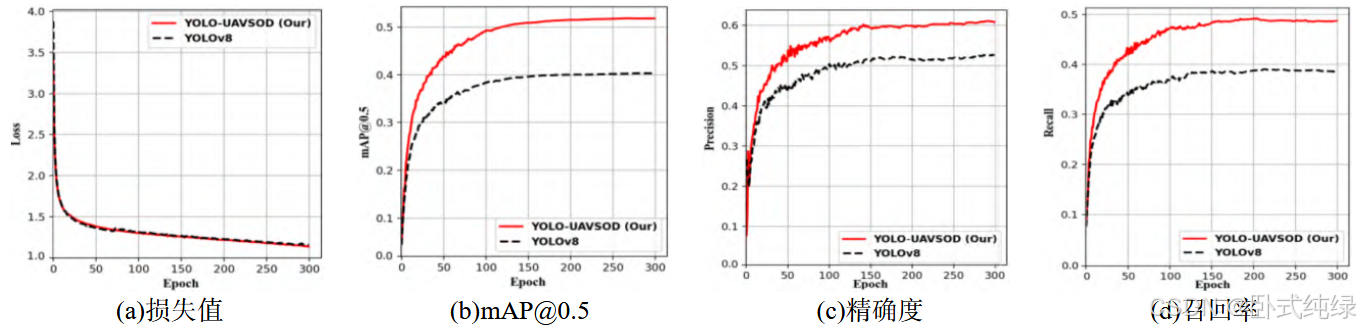
模型评价指标曲线图:
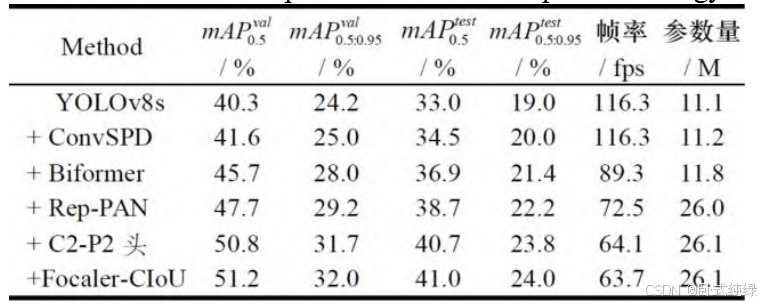
消融实验结果:
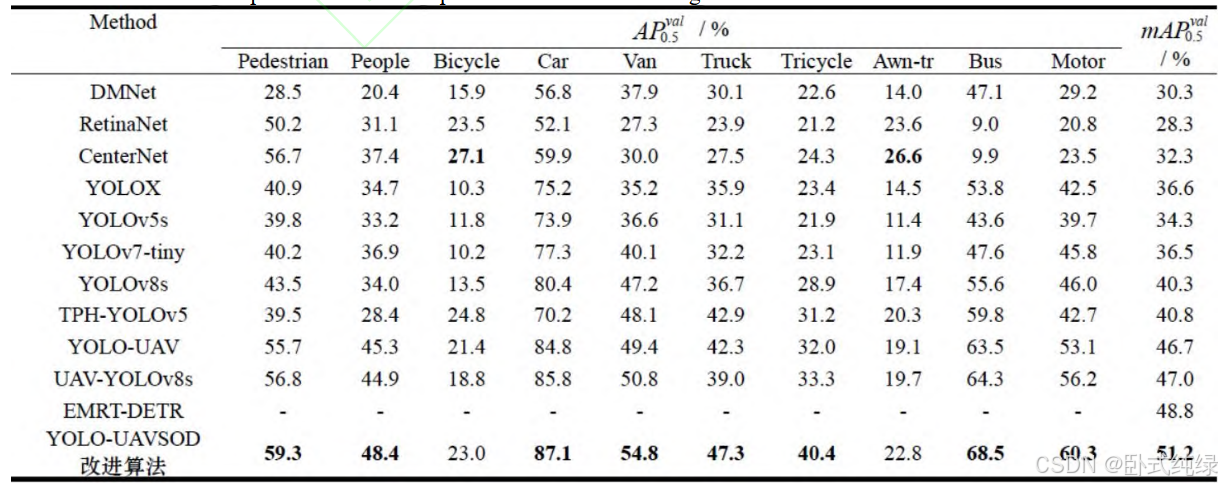
不同算法实验结果:
可视化结果:

