多模态不再缝缝补补:文心 5.0 正在重写大模型的“世界观”
背景
我们的日常使用大模型,就像是在不同模型间打补丁:“这个模型会看图,但不会讲故事;那个模型能生成视频,但不懂视频在表达什么。” 于是乎,大致像这样,想用图像模型,就得跑去找midjourney;想做视频模型,又得等 Sora;想让模型理解视频剧情,还得靠那些半懂不懂的“视觉语言拼接模型”;想让模型读情绪,甚至还得给它加一堆“情绪标签的模板提示词”。
而就在昨天,我看完百度文心 5.0 的发布会,突然有种久违的感觉:——国产大模型的世界观,好像真的变了。

**文心 5.0 :“都别吵,你们其实是同一种 token” **
发展
我饶有兴致的去搜了下文心5.0的相关“实力”,原来在 11 月 8 日的 LMArena 更新中,全新的 ERNIE-5.0-Preview-1022 排在文本榜全球并列第二的位置,在国内模型中排名第一,在创意写作、复杂长问题理解、指令遵循等维度都有较明显的优势,整体分数超过了多款国内外的主流模型。
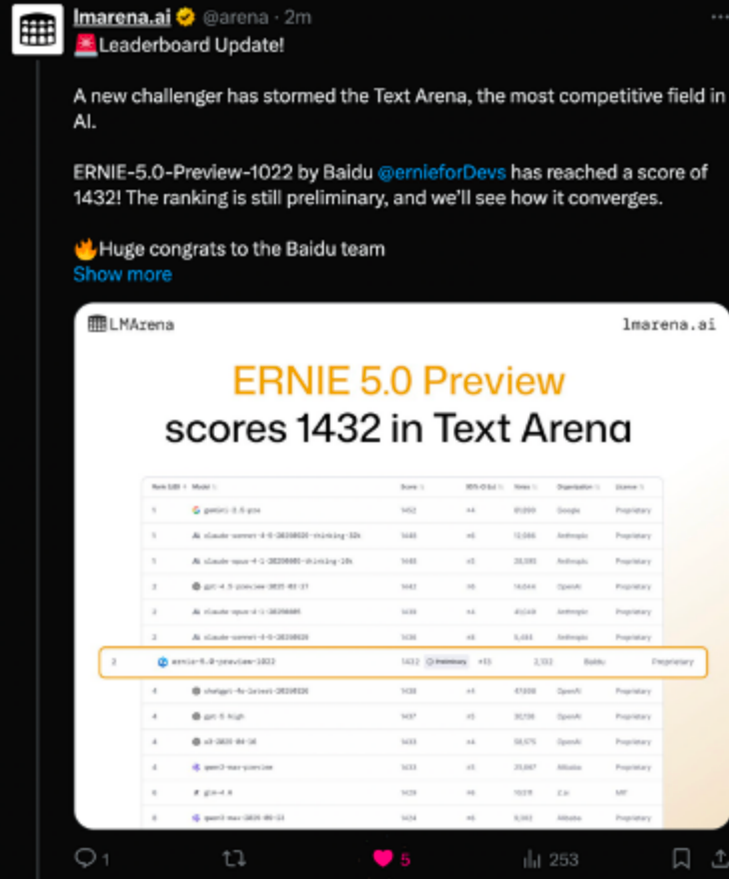
媒体也做了不少实测。11 月 12 日,百度开源了多模态思考模型 ERNIE-4.5-VL-28B-A3B-Thinking,这个模型在 HuggingFace 多模态趋势榜上线 24 小时就升至全球第一。公开基准显示,在多模态理解和复杂推理任务上,其性能在仅 3B 激活参数的情况下已经接近 GPT-5-High 和 Gemini-2.5-Pro。这个模型引入了“图像思考”(Thinking with Images)的方法,使模型能够在图像层面构建更具结构性的推理链路,同时提升场景定位、细节捕捉与指令遵循的稳定性。因此在许多需要多模态统一理解的任务中,它的表现更接近人类的处理方式。
整体来看,从文本到多模态,这一系列数据至少说明:文心 5.0 的能力已经不再停留在发布会描述,而是在公开评测中有相对稳定、可复现的表现。
实测
eg1
我专门让文心 5.0 生成了一张“马斯克和朱迪警官握手”的画面,想看看它在构图和细节上到底理解了多少“人类场面话”。

有意思的是,它并不是随便拼出两个站在一起的人,而是把整个社交场景都一起建出来了:马斯克的微笑是收着的,像是在释放善意;朱迪警官的握手姿态偏正式,身体保持直立,和马斯克之间留出一个刚刚好的社交距离。背景不是杂乱的街景,而是干净、偏官方的布景,灯光集中在两人身上,旁边略微虚化,明显是在强调“公开场合的礼貌互动”这种氛围。
从这张“生成出来的合影”里,你能感觉到的是:文心 5.0 不只是会把“两个人 + 握手”拼在一起,而是对“这应该是什么场合、两个人应当呈现什么状态”有一套自己的判断。它画出来的不是一张静态姿势图,而是一种关系感——这已经超出“我看懂了物体”,更接近“我理解了场面”。
eg2
第二个测试我选了一个更偏“结构推理”的场景:让文心 5.0 去生成一段“太阳系 3D 运行模拟”的小动画,看它能不能不靠死记硬背,而是真正理解轨道、光影、节奏这些物理关系。
结果比我预期的要好:
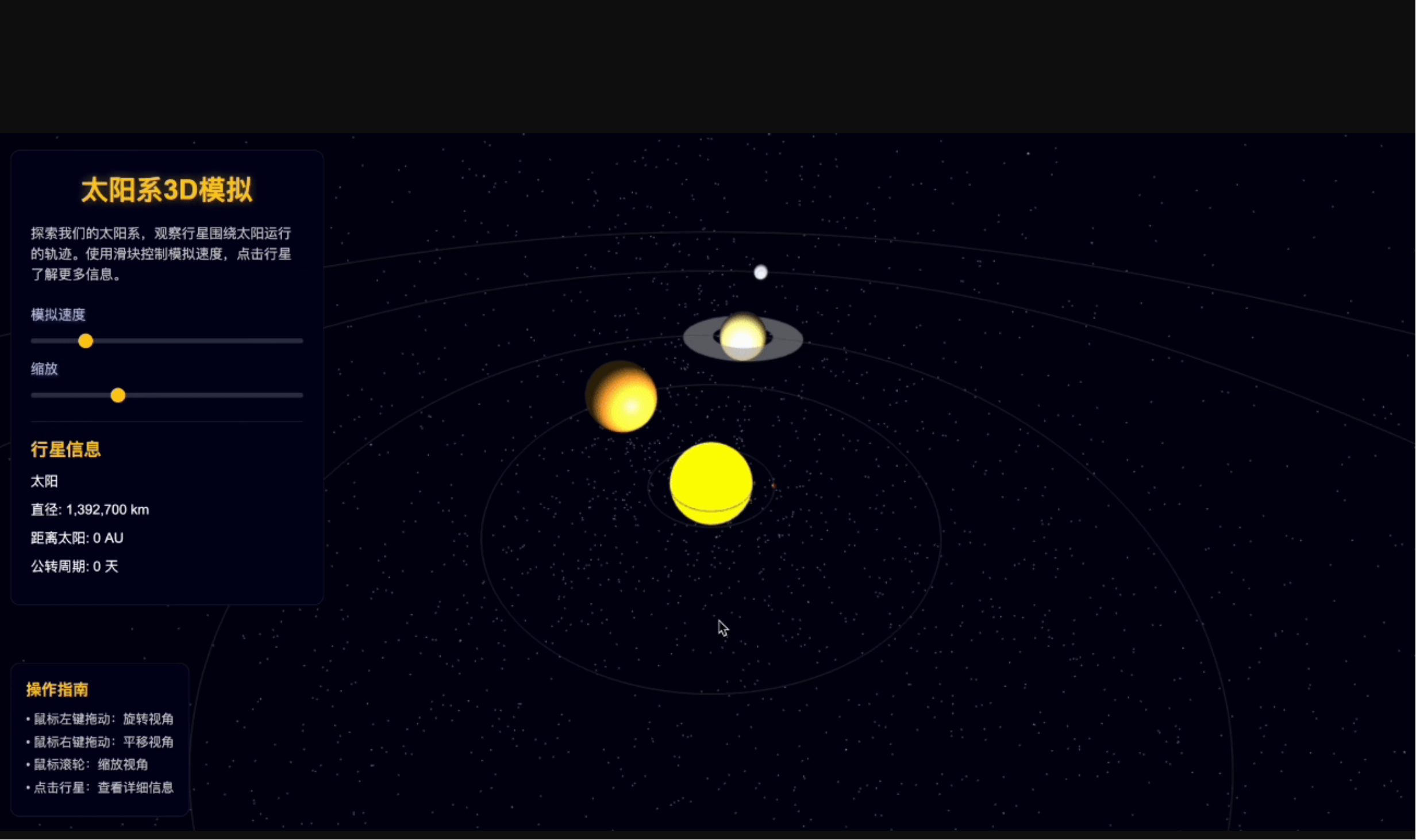
它生成的不是那种“行星绕着太阳转一圈就完事”的廉价演示,而是真的把轨道速度的差异、光照方向的变化、遮挡关系的前后顺序统统兑到了画面里。内行星转得快、外行星转得慢,明暗分界线和光源方向一致,甚至连一些行星的轻微椭圆偏心都表现得挺自然。
更关键的是,它不会把“轨道运动”做成机械循环,而是通过视角变化、光照过渡,让你感觉到这是一套真正的天体运行系统,而不是简单堆模型贴图。这种能力背后依赖的是模型对动态结构 + 物理一致性 + 时序节奏的统一理解。
eg3
后一个测试,是我最想看的——影视剧情节、时序与情绪的综合分析。我直接让它基于无间道“”指定片段重建一个“带叙事理解”的画面,看它的镜头语言、人物关系、节奏把握会不会生硬。
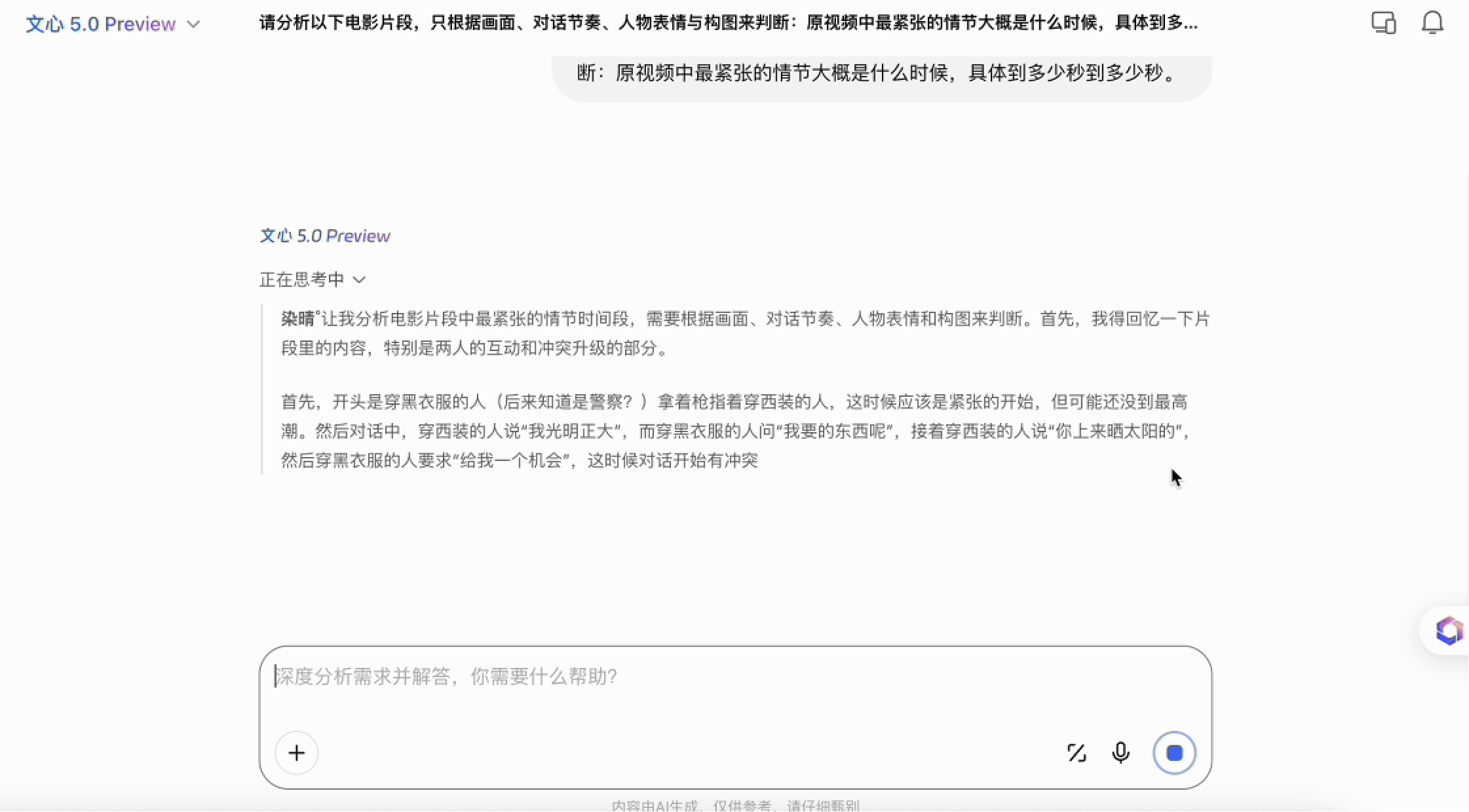
传统模型在这种任务下几乎只会描述动作:谁转头、谁说话、谁沉默。但文心 5.0 的生成结果明显更像是“带着理解在画”。人物的停顿不是被误画成僵直的姿势,而是处理成“犹豫”“压抑”“欲言又止”的身体状态;镜头的远近关系也不是随机挑选,而是和角色当下的心理距离保持一致;背景里的光影变化、色调微差、空间层次也都跟剧情情绪走向对得上。
有意思的地方在于,它并不只是在“复现画面”,而是在试图表达:在这一段情节里,谁比谁更紧张、谁比谁更主动、谁在隐藏情绪、谁在试探对方。这是以前的拼接式多模态模型完全做不到的维度。
那种“不是描述情绪,而是画出情绪”的体验,让我第一次意识到:文心 5.0 的全模态统一推理,已经能触碰到一种接近叙事语言的东西。
小结
所以,我感受到:文心 5.0 的推理链是统一的,它理解世界的方式是一种:token,而不是多种:文字、图片、音视频。不需要补丁、桥接、投影和“你说完我接着说”的拼装逻辑。信息不再丢、推理不再断、情绪不再浅表、叙事不再碎片。
还有,更微妙的变化在于:当模态统一之后,智能体能力会自然变强。因为一个能同时理解场景、动作、情绪、语言的模型,它去执行计划时不会突然“忘记前因后果”。你让它分析剧情,它能分析人物意图;让它生成脚本,它能把动作、表情、语气、镜头逻辑一起规划好。这种“行为一致性”是老式多模态模型无法提供的。
我猜测,如果未来的大模型架构真的会进入 2.0 时代,可能就是文心 5.0 这样的全模态架构。