使用streamlit和qwen-agent实现Qwen3-VL模型图文对话应用的思路
参考在ec2上部署qwen3-VL-2B模型一文已经自行部署了模型。之前只做过文本模型的对话实现,由于Qwen3-VL支持图像识别,需要考虑如何将客户端的图片传输给模型。
AI给出的方案有如下
- 通过base64编码的方式将图片数据嵌入到请求中
- 上传文件到文件服务器,将文件url传递给模型
- 使用对象存储(S3或minio)并传递文件url或使用sdk下载
Qwen3-VL 是否会主动下载图片?在调用 Qwen3-VL 的 API(例如通过阿里云百炼平台或 Model Studio)并传入一个 图片 URL 时,服务端会主动从该 URL 下载图片,以便进行后续的视觉理解推理。所以这要求该 URL 是 公开可访问的(无需登录、无防盗链、无 IP 限制等)。如果 URL 无法被服务端访问(如内网地址、私有 OSS 未授权等),则会报错。
- 服务端会在处理请求时将图片 临时下载到内存或临时磁盘 中,仅用于本次推理。推理完成后,图片数据会立即被清除,不会长期保存。
- 最好对文件的大小和内容提前进行限制
此外,如果需要附加安全围栏,Qwen-Guard 目前还无法对图片进行过滤。
通过base64编码方案
这种方式不需要额外写文件上传接口,直接把base64发给后端,图片数据在前端处理,不会暴露原始文件路径
按照如下方式将上传的文件经过base64编码之后直接传给后端即可,但是注意需要分辨mime_type类型
bytes_data = uploaded_file.getvalue()
base64_image = base64.b64encode(bytes_data).decode('utf-8')
content = [{"type": "text", "text": user_input},{"type": "image_url","image_url": {"url": f"data:{mime_type};base64,{base64_image}"}}
]
对于在文本对话框粘贴图片实现处理,需要前端监听监听用户的粘贴事件。
- 在用户粘贴图片时,获取剪贴板中的图片数据,并将其转换为 Base64 编码。
- 将 Base64 图片数据嵌入到文本输入框或隐藏字段中,以便后续处理。
使用对象存储
首先使用docker自建minio对象存储服务
services:minio:image: swr.cn-north-4.myhuaweicloud.com/ddn-k8s/docker.io/minio/minio:latestcontainer_name: minioports:- 9001:9001- 9000:9000restart: alwayscommand: "server /data --console-address :9001 --address :9000"environment:MINIO_ROOT_USER: adminMINIO_ROOT_PASSWORD: passwd123networks:- 1panel-network# volumes:# - ./data:/data# - ./config:/root/.minio/
networks:1panel-network:external: true
创建存储桶和相应的apikey
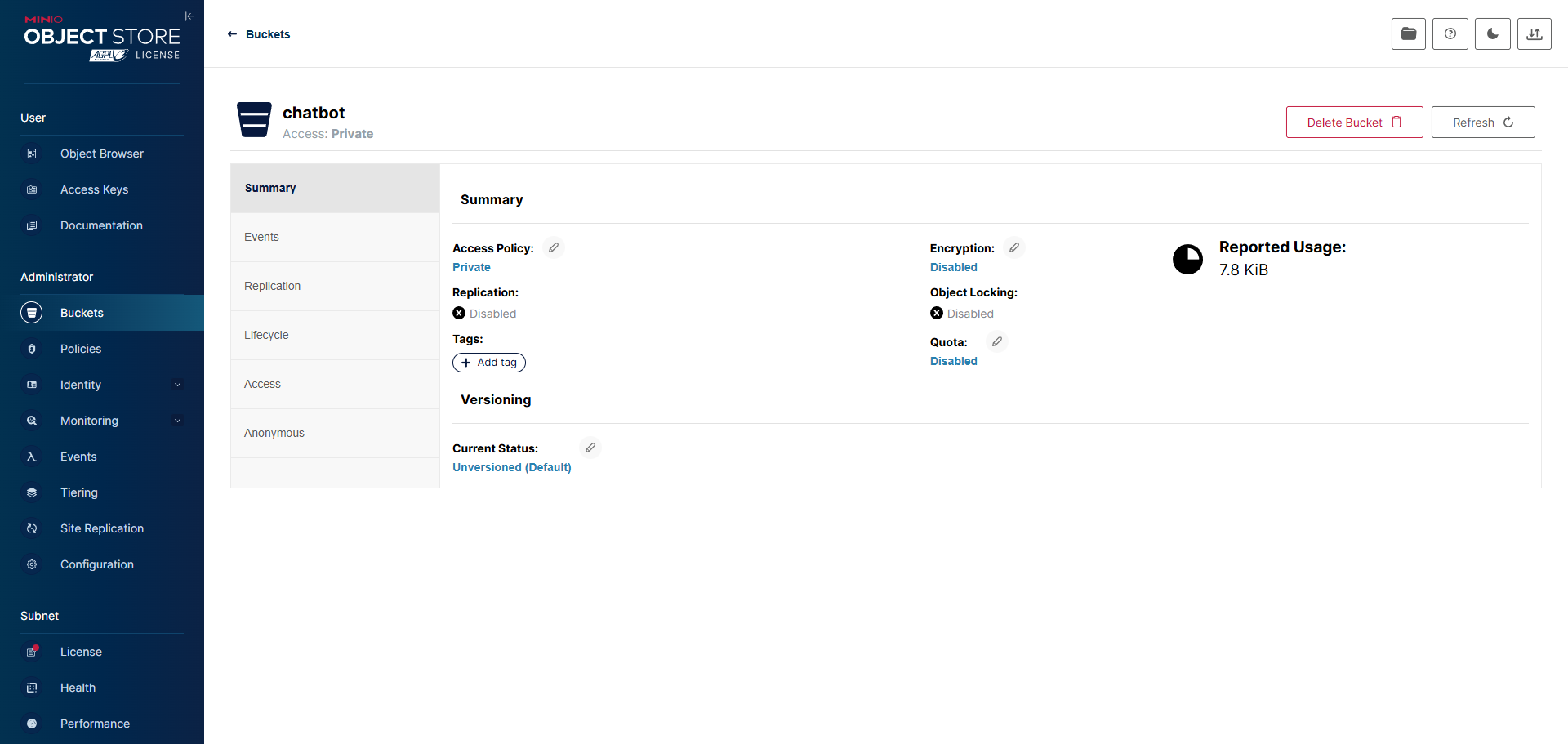
在前端将上传的文件存储到minio中,bucketname为chatbot
# 初始化MinIO客户端
minio_client = Minio("localhost:9000",access_key="lByNXxxxxxxFXaY9J",secret_key="xELxiQtIxxxxxxxxxxxSVCTCnpunM",secure=False
)
...
# 上传文件
bytes_data = uploaded_file.getvalue()minio_client.put_object("chatbot",object_name,BytesIO(bytes_data),len(bytes_data),content_type=uploaded_file.type)
此时如果直接访问图片http://localhost:9000/chatbot/test.png会出现如下报错

可以考虑直接创建presign url传递
# 获取预签名URL (有效期2小时)
presigned_url = minio_client.presigned_get_object("chatbot", object_name, expires=timedelta(hours=2)
)
之后仍旧通过content传递给后端,但是此时传递的是presigned_url,后端会主动下载文件内容
content = [{"type": "text", "text": user_input},{"type": "image_url","image_url": {"url": presigned_url}}
]
传递给模型的payload为
{'model': 'Qwen3-VL', 'messages': [{'role': 'assistant', 'content': '你好!我是Qwen3-VL,可以处理图像和文本信息。请上传一张图片并提出你的问题吧!'}, {'role': 'user', 'content': [{'type': 'text', 'text': '帮我解释这幅图片的内容?'}, {'type': 'image_url', 'image_url': {'url': 'http://localhost:9000/chatbot/d3989f54-a16b-430b-9275-4692d9aff0a2.png?X-Amz-Algorithm=AWS4-HMAC-SHA256&X-Amz-Credential=lByNXv0Atsaq9ZFXaY9J%2F20251114%2Fus-east-1%2Fs3%2Faws4_request&X-Amz-Date=20251114T115420Z&X-Amz-Expires=7200&X-Amz-SignedHeaders=host&X-Amz-Signature=41379bdacdb07674a53c6e7fea443beaa8b4dd0ce597c0a27224b491160df41a'}}]}], 'stream': True, 'top_p': 0.4}
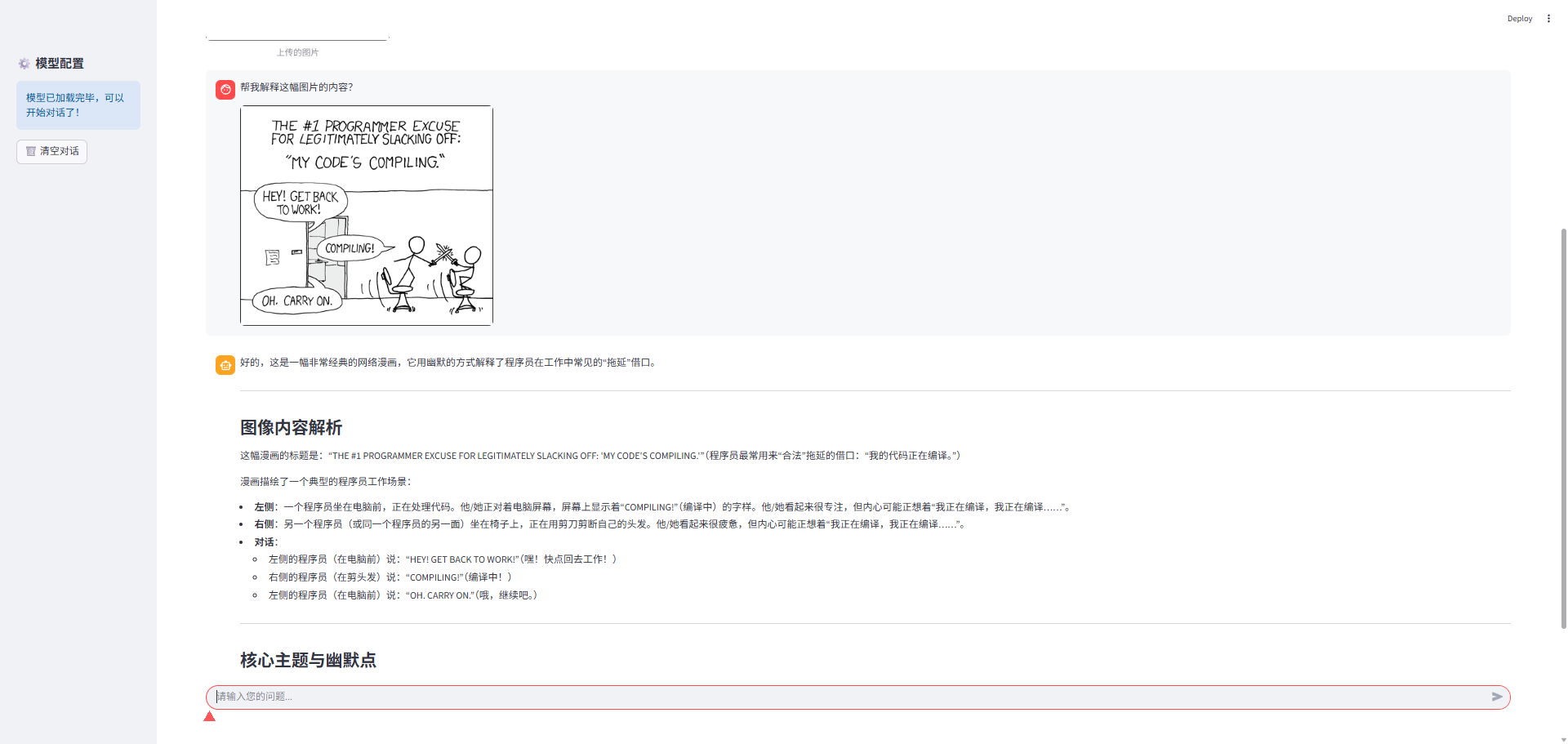
最终streamlit的实现效果如下
如果上传非常多图片会有影响吗?
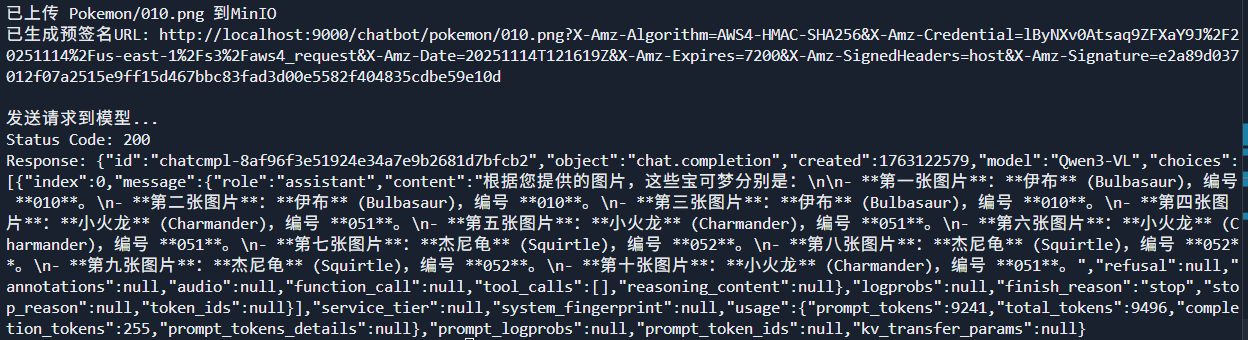
下面的代码测试了多图片的生成结果,没有压力
# 创建Pokemon文件夹
os.makedirs("Pokemon", exist_ok=True)# 下载前10个宝可梦图片
base_url = "https://raw.githubusercontent.com/HybridShivam/Pokemon/master/assets/images/"
for i in range(1, 11):# 格式化编号(三位数,前面补0)pokemon_number = f"{i:03d}"image_url = f"{base_url}{pokemon_number}.png"local_filename = f"Pokemon/{pokemon_number}.png"try:print(f"正在下载 {image_url}...")urllib.request.urlretrieve(image_url, local_filename)print(f"已保存到 {local_filename}")except Exception as e:print(f"下载 {image_url} 失败: {e}")# 初始化MinIO客户端
minio_client = Minio("localhost:9000",access_key="xxxxxx",secret_key="xxxxxxxxx",secure=False
)# 创建chatbot存储桶(如果不存在)
try:if not minio_client.bucket_exists("chatbot"):minio_client.make_bucket("chatbot")print("已创建chatbot存储桶")
except Exception as e:print(f"检查或创建存储桶时出错: {e}")# 上传图片到MinIO并生成预签名URL
presigned_urls = []
for i in range(1, 11):pokemon_number = f"{i:03d}"local_filename = f"Pokemon/{pokemon_number}.png"# 检查文件是否存在if not os.path.exists(local_filename):print(f"文件 {local_filename} 不存在,跳过")continuetry:# 上传到MinIOwith open(local_filename, 'rb') as file_data:file_stat = os.stat(local_filename)minio_client.put_object("chatbot",f"pokemon/{pokemon_number}.png",file_data,file_stat.st_size,content_type="image/png")print(f"已上传 {local_filename} 到MinIO")# 生成预签名URL(有效期2小时)presigned_url = minio_client.presigned_get_object("chatbot",f"pokemon/{pokemon_number}.png",expires=timedelta(hours=2))presigned_urls.append(presigned_url)print(f"已生成预签名URL: {presigned_url}")except Exception as e:print(f"上传 {local_filename} 或生成预签名URL时出错: {e}")# 向模型发送请求
url = "http://localhost:8000/v1/chat/completions"
headers = {"Content-Type": "application/json"
}# 为每个宝可梦图片构建消息内容
content_items = [{"type": "text","text": "这些是哪些宝可梦?请告诉我它们的名称和编号。"}
]# 添加所有图片URL到消息内容
for presigned_url in presigned_urls:content_items.append({"type": "image_url","image_url": {"url": presigned_url}})payload = {"messages": [{"role": "user","content": content_items}]
}print("\n发送请求到模型...")
response = requests.post(url, headers=headers, data=json.dumps(payload))print(f"Status Code: {response.status_code}")
print(f"Response: {response.text}")
与qwen-agent结合
参考资料
- https://github.com/QwenLM/Qwen-Agent
- https://qwen.readthedocs.io/en/latest/framework/qwen_agent.html
关于Qwen-Agent和AWS Strands Agents的对比
| 维度 | Qwen-Agent | AWS Strands Agents |
|---|---|---|
| 主导方 | 阿里云(通义实验室) | 亚马逊云科技(AWS) |
| 开源情况 | 开源(Apache 2.0 或类似协议),但深度绑定阿里生态 | 完全开源(Apache 2.0),强调开放生态与多厂商兼容 |
| 核心理念 | 中文友好、多模态支持、电商/企业场景优化 | 模型驱动、极简开发、生产级可用、全环境兼容 |
| 目标用户 | 中文开发者、阿里云用户、电商/金融等垂直行业 | 全球开发者、企业级用户、多云/混合云环境 |
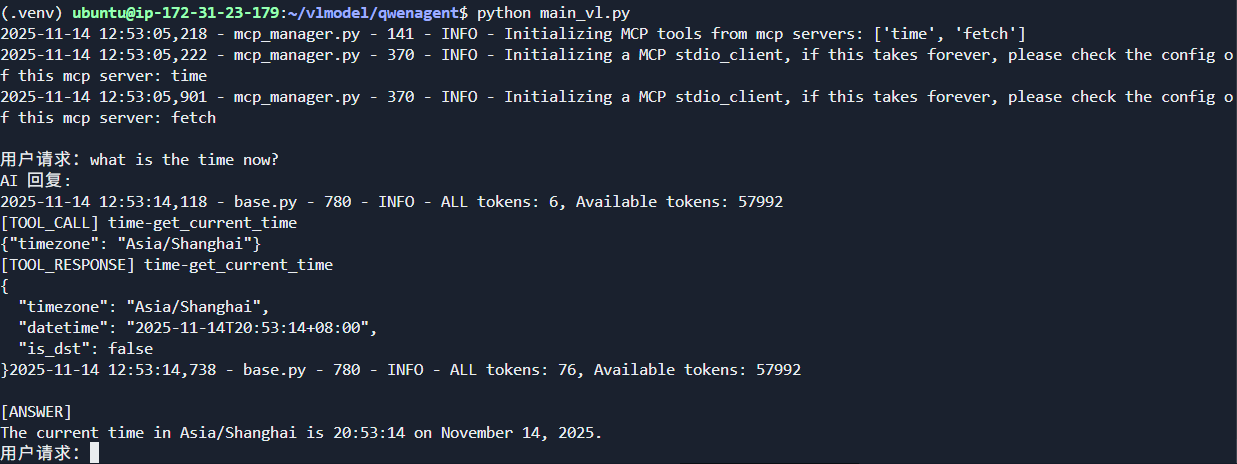
在agent启动时就会按照tool的配置启动相应的mcp服务

实现如下的逻辑来集成mcp服务器,实现文档搜索等功能
from qwen_agent.agents import Assistant
from qwen_agent.utils.output_beautify import typewriter_print
import osllm_cfg = {"model": "Qwen3-VL","model_server": "http://localhost:8000/v1","api_key": os.getenv("API_KEY", "EMPTY"),"generate_cfg": {"top_p": 0.8},
}
tools = [{"mcpServers": {"time": {"command": "docker","args": ["run","-i","--rm","mcp/time","--local-timezone=Asia/Shanghai",],}}},"code_interpreter",
]bot = Assistant(llm=llm_cfg,system_message="你是一位乐于助人的小助理",name="智能助理",function_list=tools,
)messages = [] # 存储历史聊天内容
while True:query = input("\n用户请求:")if query == "quit":breakelse:messages.append({"role": "user", "content": query})response = []response_plain_text = ""print("AI 回复:")for response in bot.run(messages=messages):response_plain_text = typewriter_print(response, response_plain_text)messages.extend(response)