ACL 2025论文分享|一种同时支持文字、语音、草图、艺术图和低分辨率图等多模态内容检索的新框架Uni-Retrieval
本推文介绍的是ACL 2025收录的一篇论文《Uni-Retrieval: A Multi-Style Retrieval Framework for STEM’s Education》。该论文面向AI赋能教育场景,提出了一个多风格检索框架Uni-Retrieval。该框架通过“原型学习模块”和“Prompt Bank提示库”结合,实现对文字、语音、草图、艺术风格和低分辨率图像等多模态输入的统一检索。SER数据集涵盖科学、技术、工程、数学四大领域,共24,000+样本,支持跨风格、多模态的教学内容匹配。实验结果显示,Uni-Retrieval在SER基准上平均R@1得分83.2,相较最强基线模型FreestyleRet提升约10%,相较CLIP提升28.6%,同时仅增加不到5%参数量与约9ms推理开销。在多风格、跨模态检索任务中均表现出显著优势,表明该框架能高效地支持STEM教育中多样化的教学检索与资源匹配需求。
推文作者为黄星宇,审校为许东舟和邱雪。
论文链接:https://aclanthology.org/2025.acl-long.502
项目链接:https://github.com/CuriseJia/ACL25-Uni-Retrieval
一、研究背景
STEM是科学(Science)、技术(Technology)、工程(Engineering)、数学(Mathematics)四个学科英文首字母的缩写,核心是通过跨学科融合培养解决实际问题的能力。强调跨学科融合,不是四个学科的简单叠加,而是通过项目将知识串联起来。注重实践与创新,以解决真实世界的问题为目标,培养动手能力和批判性思维。
人工智能赋能教育(AI4EDU)是当前教育技术的重要趋势,常常用于提升教学设计、学习过程和评估等环节。在STEM教育中,教师与学生经常需要从庞大的多学科知识库中检索教学资源,包括图片、文本、实验图等内容。然而,现有的跨模态检索模型(如CLIP、BLIP)主要针对自然语言与图像匹配场景,缺乏对语音、草图、低分辨率图片等的教学场景中多样化输入形式的适应能力,会导致检索不准确,偏差变大。所以论文提出一个专门为STEM教育设计的多风格、多模态检索任务与框架Uni-Retrieval,来解决上述的问题。
二、方法
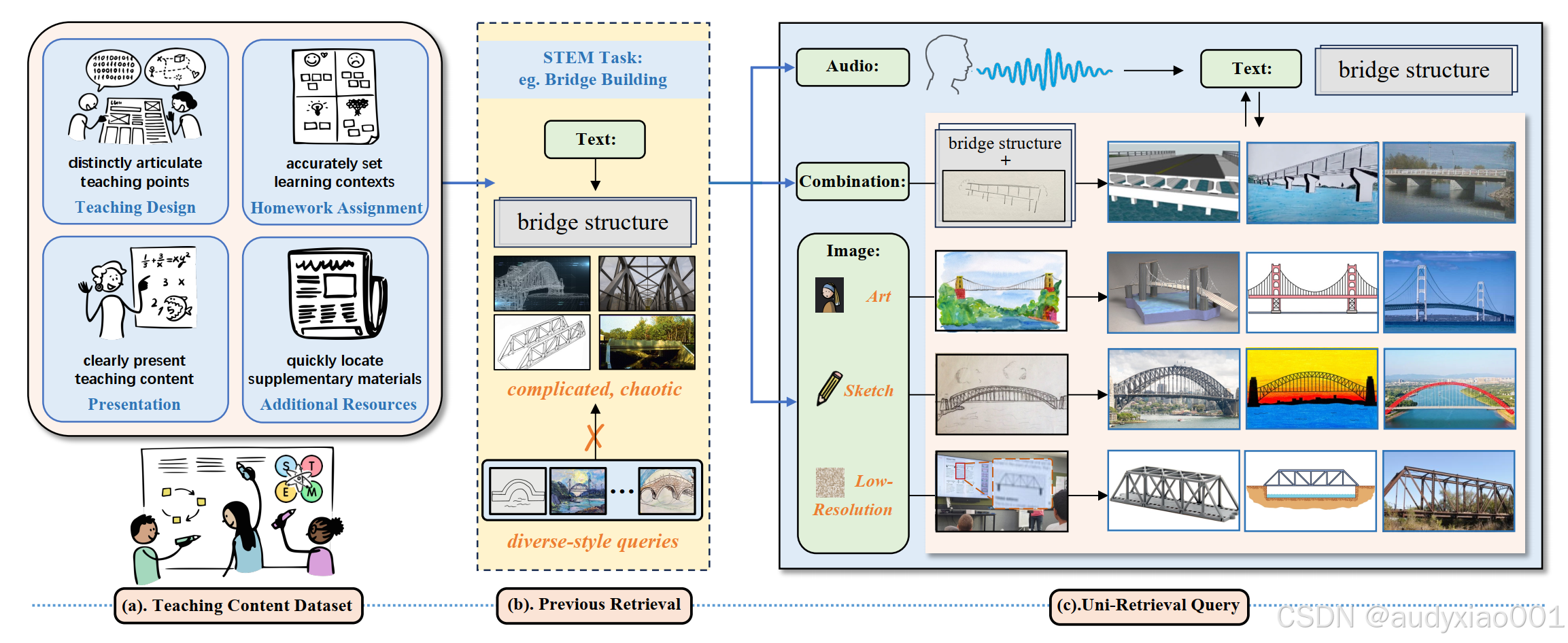
图1 Uni-Retrieval与传统检索模型在STEM教育场景中的区别
图1以“桥梁搭建”为STEM任务示例,清晰展示了STEM教育检索场景下的资源基础与检索方案对比,分为三部分:(a)为教学内容数据集,作为检索的资源支撑,涵盖教学设计、作业布置等与任务相关的教学内容;(b)为以往检索模型的局限,这类模型主要聚焦文本到查询检索,仅能处理单一的文本或音频等查询形式,难以适配教育场景的多样化需求;(c)为Uni-Retrieval的多风格查询设置,突破以往局限,支持文本、音频、草图、艺术风格图、低分辨率图等多种查询风格,还可实现多模态组合查询,能满足清晰呈现教学内容、快速定位补充资源等实际教学需求,为STEM教育提供更贴合教学场景的检索解决方案。
2.1 数据集构建
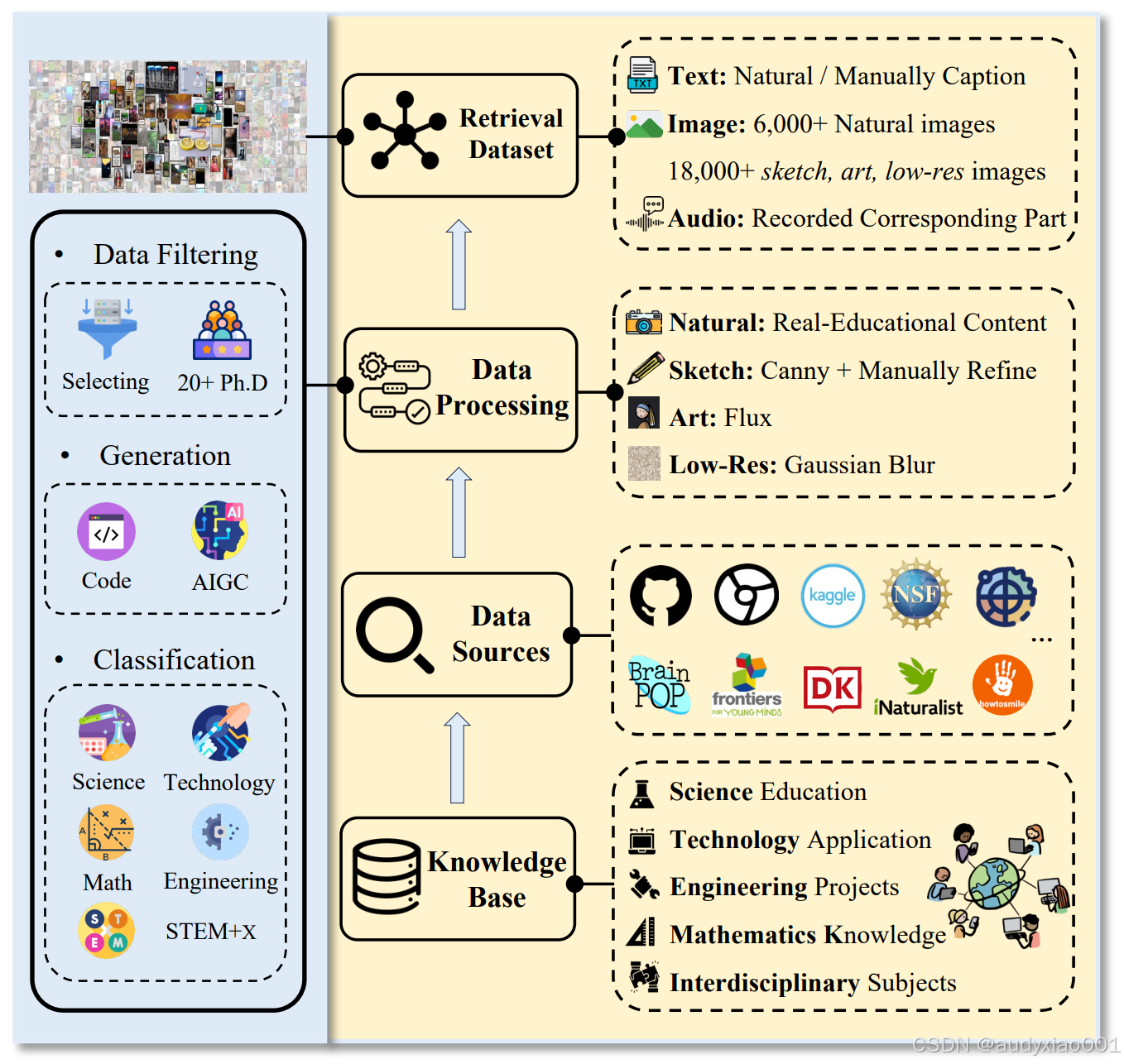
图2 数据构建流程
图2展示了面向STEM教育的多模态检索数据集构建流程:以涵盖科学教育、技术应用、工程项目等的知识库为基础,整合GitHub、Kaggle、NSF等多平台的数据源,通过对自然教育内容、使用Canny算法和人工优化的草图、Flux生成的艺术风格图、高斯模糊处理的低分辨率图等进行数据处理后,形成包含自然/人工标注文本、6000+自然图像与18000+草图、艺术和低分辨率图像、对应音频的检索数据集。同时左侧通过数据过滤(筛选+20余位博士参与)、生成(代码、AIGC技术)、分类(科学、技术、数学、工程、STEM+X跨学科)等环节,保障数据集在STEM教育场景下的多模态、多风格检索能力。
2.2 Uni-Retreival框架
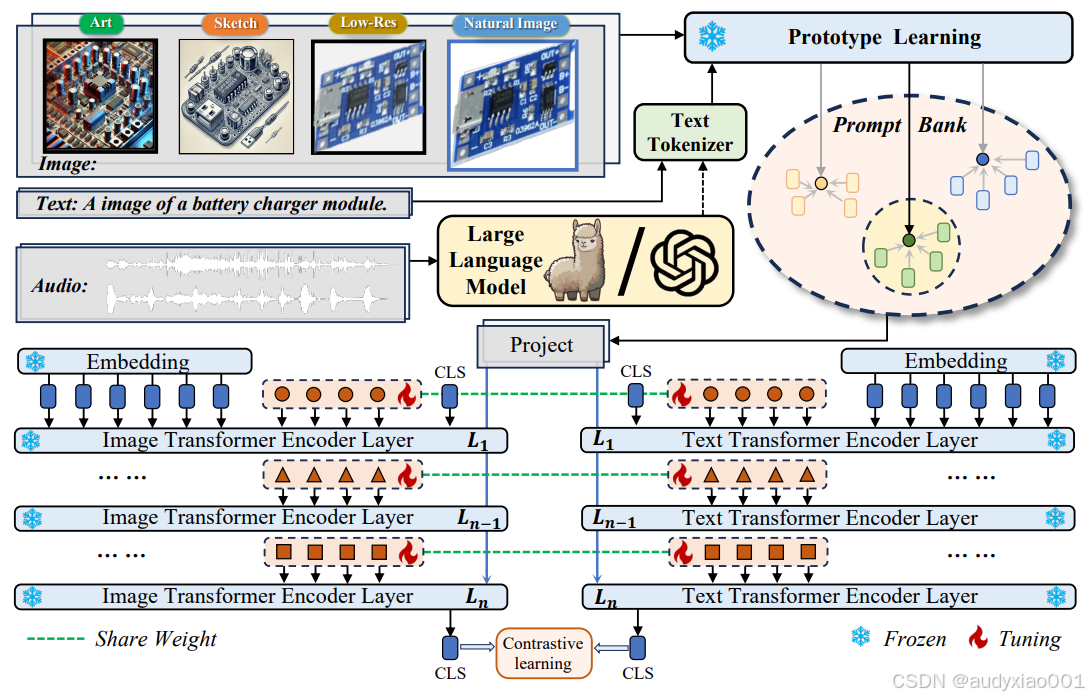
图3 Uni-Retreival模型的框架
图3是面向STEM教育的多风格多模态检索框架图,核心是突破“单一模态、单一风格”的检索局限,实现“草图、低分辨率图、艺术化素材”等教育场景下的精准资源匹配
1. 输入层
多模态多风格覆盖包含4类图像(Art艺术风、Sketch草图、Low-Res低分辨率和Natural Image自然图像)、文本(如“A image of a battery charger module”这类教学指令式描述)、音频(如教师口述的“找风力发电机教学图”语音),全方位适配STEM教学中的多元需求。
2. 预处理模块
Large Language Model:将音频转译为文本,实现“音频→文本”的模态统一,让语音查询能和文本、图像一样参与检索流程。
Text Tokenizer:对文本进行分词、编码,转化为模型可解析的token序列,为后续编码做准备。
原型学习(Prototype Learning):提取不同风格输入的特征并聚合为“风格原型”(例如,所有Sketch的特征会被整合为“草图风格原型”,包含线条密度、结构特征等共性),作为后续检索的“语义锚点”。
Prompt Bank:动态存储可学习的语义标签库。当输入模糊查询(如一张低分辨率的电路实验图)时,它会快速匹配“电路”、“实验图”、“低分辨率”等标签,为查询补充语义信息,大幅提升模型对抽象和模糊查询的理解精度。
3. 编码与对齐层
采用图像Transformer编码器和文本Transformer编码器,通过共享权重(绿色虚线)让“视觉-文本”特征在每一层语义对齐。同时,模型采用“部分层冻结(Frozen,蓝色雪花标记)、部分层微调(Tuning,红色火焰标记)”的策略,仅更新少量参数即可实现性能跃升,兼顾训练效率与检索精度。
4. 优化层
通过对比学习(Contrastive learning)优化特征距离,让“查询-正确资源”的特征尽可能接近,“查询-错误资源”的特征尽可能疏远,最终实现多模态资源的精准匹配。
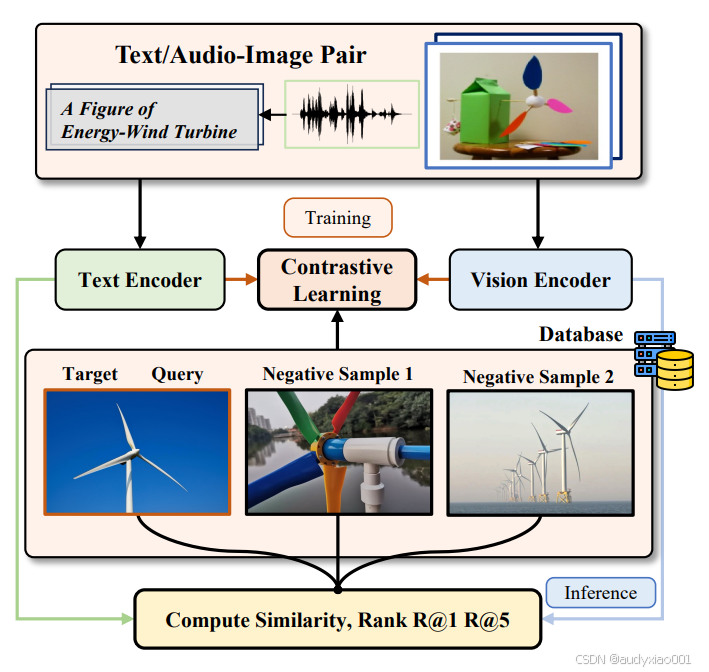
图4 Uni-Retreival框架的执行过程
图4直观展示了从“训练到推理”的完整检索流程,根据此图详细介绍该流程如下。
(1)训练阶段
让模型学会“关联语义”输入为“文本/音频-图像对”。文本编码器:提取文本/音频的语义特征(如“风能”“涡轮机”的概念信息)。视觉编码器:提取图像的视觉特征(如涡轮机的叶片形状、结构布局)。对比学习(Contrastive Learning):让“相关特征”(如“风能涡轮机”文本与对应图像的特征)尽可能靠近,“无关特征”(如文本与“彩色水管装置”图像的特征)尽可能疏远,从而让模型学会“文本-图像”的语义关联。
(2)推理阶段
基于训练好的模型,在数据库中对“目标涡轮机图像”“查询图像”“负样本图像”计算特征相似度,按相似度从高到低排序,输出R@1(Top1匹配)和R@5(Top5匹配)结果。这一流程可快速为教师匹配“风能涡轮机”相关的教学图像、文本资源,解决STEM教学中学科主题资源分散、多模态查询匹配难的痛点。
三、实验结果
为全面验证Uni-Retrieval在STEM教育多模态检索场景的优势,实验从多风格检索精度、模型效率、多任务协同能力、跨数据集泛化性等维度展开,通过六组实验表格对比其与主流模型的表现,具体结果如下。
表1 多风格检索性能对比
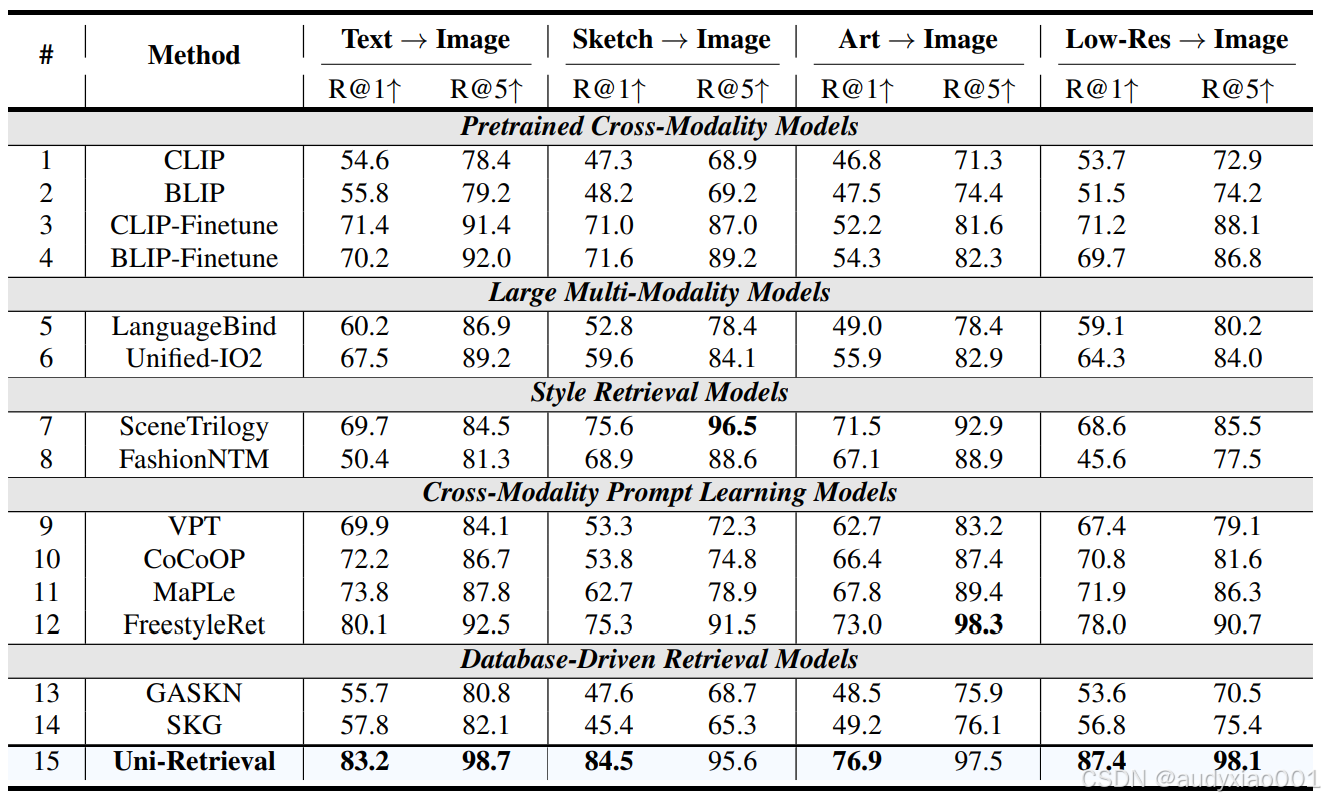
表1在“文本→图像、草图→图像、艺术图→图像、低分辨率图→图像”四类任务中,Uni-Retrieval的R@1/R@5指标均大幅领先其他模型,例如文本→自然图像R@1达83.2,草图→图像R@1达84.5,充分证明其对STEM教育中手绘、模糊图等多风格查询的精准适配能力。
表2 模型效率对比
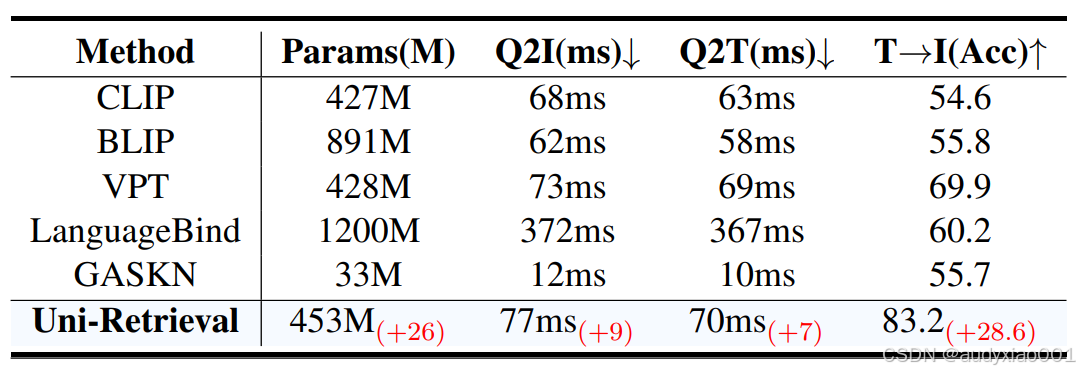
表2比较了模型之间的效率,Uni-Retrieval在仅增加26M参数,推理时间增加10ms的情况下,文本→图像准确率提升28.6,在“高精度”与“低计算开销”间实现平衡,契合教育场景的落地需求。
表3 多任务协同性能比较

表3在“文本→图像、文本+草图→图像、图像→文本、图像+草图→文本”任务中,Uni-Retrieval 融合草图特征后,文本→图像准确率提升4.2,图像→文本准确率提升1.6,展现出多模态特征融合的优势,可强化STEM教学中跨模态资源的联动检索效果。
表4 SER数据集多向检索性能
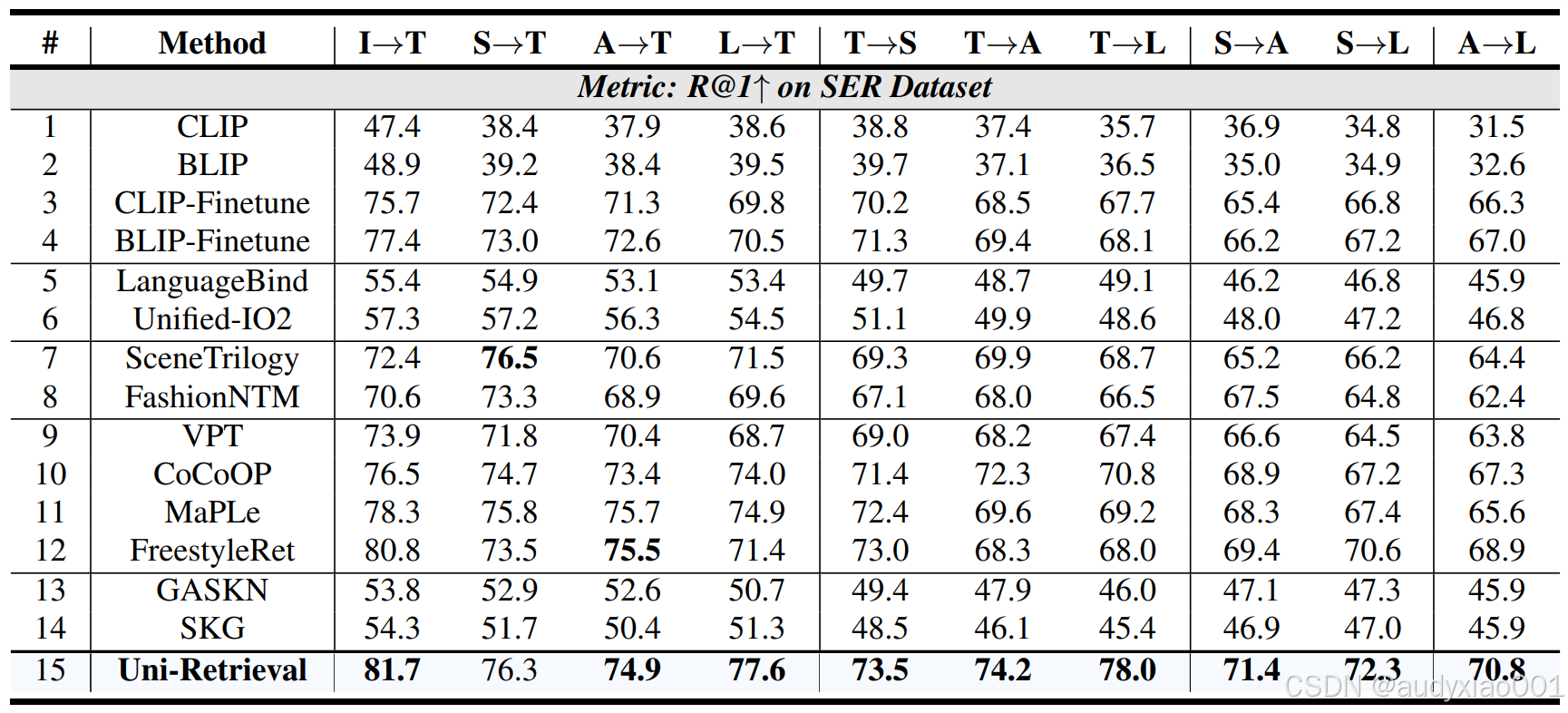
表4在SER数据集的“图像→文本、草图→文本”等10类跨模态任务中,Uni-Retrieval的R@1指标均为最高,如I→T达81.7、S→T达76.3,验证了其在STEM教育多学科、多模态检索任务中的全面优势。
表5 跨数据集泛化性能
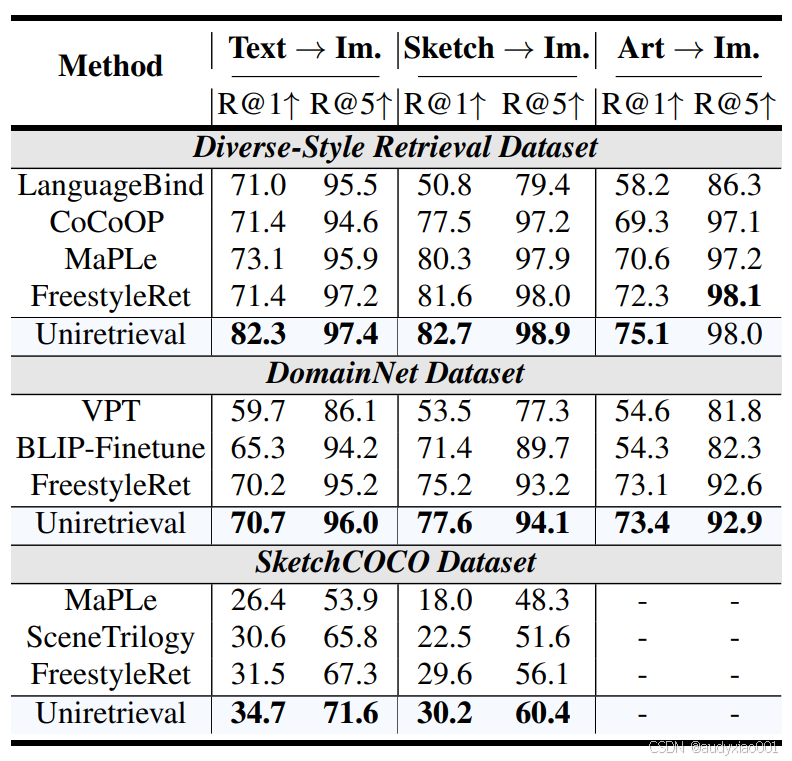
表5在Diverse-Style、DomainNet、SketchCOCO三个数据集上,Uni-Retrieval的检索性能均领先同类模型,例如Diverse-Style文本→图像R@1达82.3,SketchCOCO文本→图像R@1达34.7,展现出在未知数据集、小众风格(如草图)下的强泛化能力,可适配STEM教育资源的多样性。
四.总结
论文提出了Uni-Retrieval多模态检索框架。该框架针对STEM教育中“草图、低分辨率图、艺术化素材”等多风格多模态查询的适配痛点,通过原型学习提炼风格特征、Prompt Bank动态补充语义、共享权重的跨模态编码器实现语义对齐,在“文本→图像、草图→图像”等多风格检索任务中,R@1/R@5指标领先现有模型。同时兼顾参数效率与推理速度,在SER、DomainNet等多数据集上展现出强泛化能力,为STEM教育场景的多模态资源精准检索提供了高效、可落地的技术解决方案。