第三章 数据结构基础
目录
- 第三章 数据结构基础
- 1、链表
- 2、栈和队列
- 栈
- 队列
- 3、递归在程序中运行的原理
- 4、集合与哈希
第三章 数据结构基础
1、链表
⭐️单链表
单链表是一种基本的数据结构,用于存储一系列数据元素。与数组相比,单链表在内存中不需要连续的存储空间,并且能够动态地增加或减少元素。
单链表由多个节点(Node)组成,每个节点包含两部分:
- 数据域(Data):存储数据元素。
- 指针域(Next):指向下一个节点的引用(或指针)。
其插入与删除时间复杂度为O(1),访问遍历顺序中第i个元素时间复杂度为O(i)。
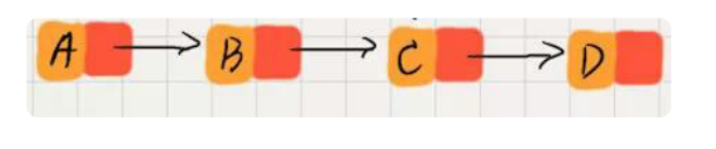
一般我们用数组模拟链表。
用e数组表示数据域,r数组表示每个结点的下一个结点的位置。
e[1] = A;e[2] = B;e[3] = C;e[4] = D;
r[1] = 2;r[2] = 3;r[3] = 4;r[4] = 0;
我们会用head变量记录链表第一个变量的位置。
遍历链表的代码为:
for(int i=head;i!=0;i=r[i]){
e[i] //
}
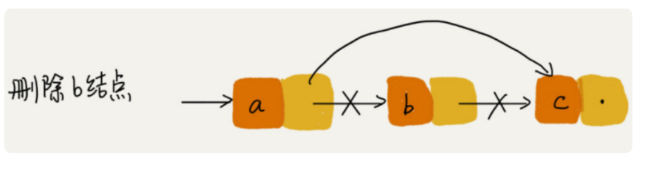
删除单链表的第b个结点:
假设第b个结点的前一个节点为p。直接修改r[a]=r[b]即可。如果是删除第一个节点则直接令head=r[head]即可。
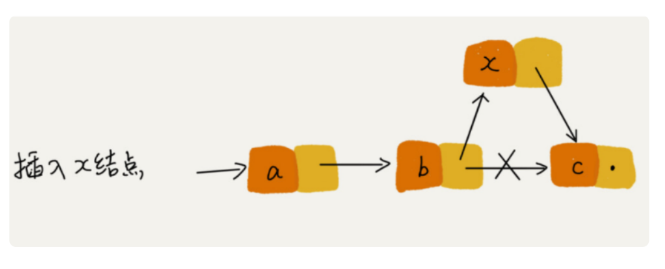
插入单链表的第i个结点;
如果插入一个节点为头节点,新节点下标为x,则r[x]=head。若为第b个结点之后,则
r[x]=r[b],r[b]=x。
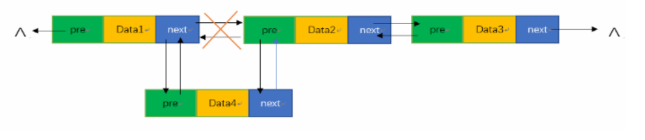
⭐️双链表
双链表是一种比单链表更复杂的数据结构。它由多个节点组成,每个节点不仅包含指向下一个节点的指针,还包含指向前一个节点的指针。这使得在双链表中可以更方便地进行插入和删除操作。
双链表中的每个节点包含三部分:
- 数据域(Data):存储数据元素。
- 前指针(Prev):指向前一个节点的引用(或指针)。
- 后指针(Next):指向下一个节点的引用(或指针)。

其插入与删除时间复杂度为O(1),访问第i个元素时间复杂度为O()。
一般我们用数组模拟双链表。
用e数组表示数据域,r数组表示每个结点的下一个结点的位置,1数组表示每个数组的上一个节点的位置。

e[1] = A;e[2] = B;e[3] = C;e[4] = D;
r[1] = 2;r[2] = 3;r[3] = 4;r[4] = 0;
l[1] = 0,[²2] = 1;/[3] = 2;/[4] = 3
一般,我们会用head变量记录链表第一个变量的位置。tail记录最后一个变量的位置。
遍历链表的代码为:
for(int i=head;i!=0;i=r[i]){
e[i] //
}
逆序遍历为:
for(int i=tail;i!=0;i=l[i]){
e[i] //
}
删除操作
假设我们要删除χ号结点。
则代码为r[l[x]]=r[x],l[r[x]]=l[x]。
注意,如果∞为头结点,我们要提前修改head=r[x]。如果是尾结点则要修改成tail=l[x]。

:插入操作:
如果我们要把下标为idx的结点插入到p结点后。
l[idx]=p,r[idx]=r[p],l[r[p]]=idx,r[p]=idx;
如果是成为头节点需要写l[head]=idx,l[idx]=0,r[idx]=head,head=idx;
尾结点需要写r[tail]=x,r[idx]=0,l[idx]=tail,tail=idx。
🍎笔记
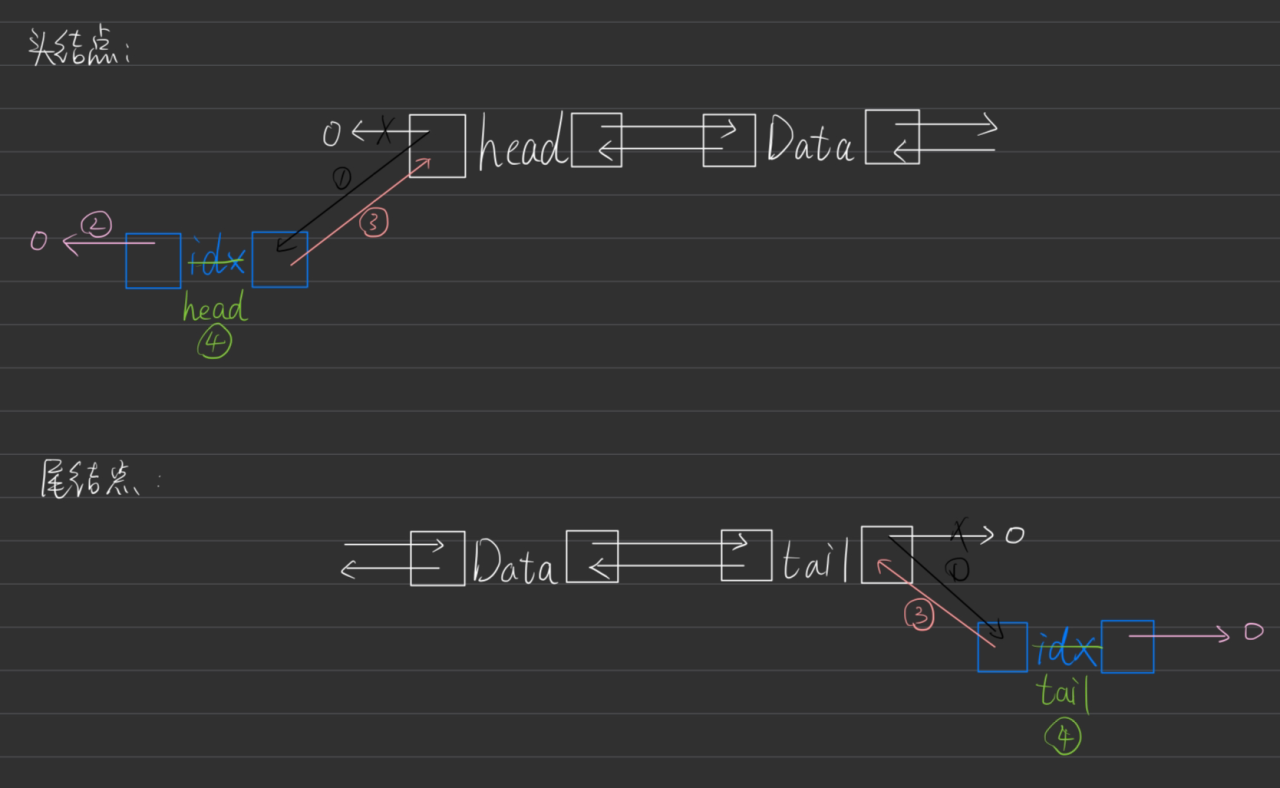
例题:2219左移右移
2、栈和队列
栈
栈(Stack)是一种后进先出(LIFO,Last In First Out)的数据结构,意味着最后插入的元素最先被移除。
栈的基本操作
- 压入(Push):将一个元素添加到栈的顶部。
- 弹出(Pop):从栈的顶部移除一个元素,并返回该元素。
- 查看顶部元素(Peek):返回栈顶元素但不移除它。
- 检查栈是否为空(isEmpty):判断栈中是否有元素。
- 获取栈的大小(size):返回栈中元素的数量。
模拟栈
我们可以用数组stk模拟栈,用一个top变量来维护栈顶指针。
入栈
stk[++top]=x
出栈
top--
判空
top==0
获取栈的大小
return top
static int stk[] = new int[100010];
static int top=0;
static void push(int x){
stk[++top]=x;
}
static void pop(){
if(isEmpty()) return;
top--;
}
static boolean isEmpty(){
return top==0;
}
static void query(){
if(isEmpty(){
out.println("empty");
}else{
out.println(stk[top]);
}
}
队列
队列(Queue)是一种常见的线性数据结构,遵循 先进先出(FIFO,FirstInFirst Out) 的原则。即最先进入队列的元素会最先被移出队列。
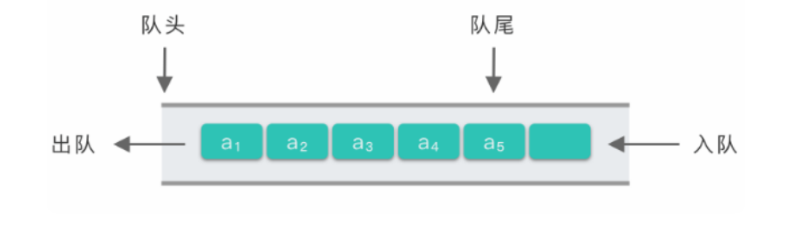
队列基本操作
- 压入(Push):将一个元素插入队尾。
- 弹出(Pop):返回队首元素并删除。
- 查看队首元素(Peek):返回队首元素但不移除它。
- 检查队列是否为空(isEmpty):判断队列中是否有元素。
- 获取队列的大小(size):返回队列中元素的数量。
模拟队列
我们可以用数组模拟队列。用head表示头指针,tail表示尾指针。
初始head=tail=0;
我们插入元素时,可以写h[tail++]=x;
删除元素可以写head--;
判空则判断head==tail;
📖

📚
import javax.sound.sampled.Line;
import java.math.BigInteger;
import java.util.Arrays;
import java.util.Scanner;
public class Main {
static int N = 100010;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int m = sc.nextInt();
int[] a = new int[N];
int head = 0;
int tail = 0;
while(m-->0){
String str = sc.next();
if(str.equals("push")){
int x = sc.nextInt();
a[tail] = x;
tail ++;
} else if (str.equals("pop")) {
if(tail == head){
continue;
}else{
a[head] = 0;
head ++;
}
} else if (str.equals("empty")) {
if(tail == head){
System.out.println("YES");
}else {
System.out.println("NO");
}
} else if (str.equals("query")) {
if(tail == head){
System.out.println("empty");
}else{
System.out.println(a[head]);
}
}
}
}
}
3、递归在程序中运行的原理
递归,即函数自己调用自己的一种程序。
递归(Recursion)是计算机编程中的一种重要概念,指的是一个函数直接或间接调用自身的编程技术。通过将复杂问题分解为更小的子问题来解决。
递归函数通常包含两个关键部分:
1.基准条件(BaseCase):当问题被简化到某种程度时,直接返回结果,不再调用自身,以避免无限循环。
2.递归条件(RecursiveCase):在没有达到基准条件时,函数调用自身,并逐步向基准条件靠近。
int fun(int x){
if(x==O) return 1;
return x*fun(x-1);
}
...
System.out.print(fun(4);
...
递归是借助栈结构进行回溯的。每当递归函数调用自身时,系统会将当前的函数调用状态(包括局部变量、参数、返回地址等)压入栈中。当递归达到基准条件(basecase)时,函数开始从栈中弹出,逐个返回调用状态,完成整个递归过程。开始时我们将fun(4),fun(3),…,fun(0)压入栈中,fun(0)是递归函数的边界,然后开始依次回溯fun(1),fun(2),…,fun(4)。

4、集合与哈希
什么是集合?
给定一个序列,你需要从中判断出一个元素是否存在。
暴力做法时间为O(n)。
排序后二分做法的时间复杂度为O(log)
如果将元素当作下标来存储,也就是cnt[a[司]=1表示a[]存在,时间复杂度为O(1),空间复杂度会很高。
集合便是查找某个元素的复杂度为O(1)的数据结构。其通过一个特殊的哈希函数,将数字映射到某一个位置。查找时通过该哈希函数我们就可以快速找到,一般计算出的哈希函数值不会超过元素个数。
cnt[hash(a[il])] = 1。
⭐️开放寻址法:
定义一个hash函数结果为x&prime,prime是大于元素个数的第一个素数。
计算出哈希函数后,我们直接令mp[hash(∞)]=c,询问一个数是否存在时,我们直接查找
mp[hash(a)]是否是x即可。
但有一种特殊的情况,即两个数字‰prime的结果是一样的,则就会在mp数组的位置产生冲突。
我们有一种方式是如果产生冲突了,就向后继续查找第一个空,直到第一个没有被占的位置。这就是开放寻址法。
⭐️哈希表的实现
find函数的实现
static int find(int x){
int k=getHash(x);
while(h[k]!=-1&&h[k]!=x) k++;
return k;
}
static void solve(){
int n=in.nextInt();
Arrays.fill(h,-1);
for(int i=1;i<=n;i++){
String op=in.next();
if(op.equals("I")){
int x=in.nextInt();
int k=find(x);
h[k]=X;
}else[
int x=in.nextInt();
int k=find(x);
if(h[k]==x){
out.println("Yes");
}else{
out.println("No");
}
}
}
}
⭐️Java提供的Set集合
1️⃣HashSet
HashSet是基于哈希表(HashTable)实现的集合。它使用哈希函数来存储元素,并不保证元素的顺序。
特点:
- 不允许有重复的元素。
- 插入、删除和查找操作的时间复杂度平均为O(1)。
- 元素的存储顺序与插入顺序无关。
常用函数:
- add(E e):向集合中添加元素,如果元素已存在,返回false。
- remove(Object o):从集合中移除元素,成功返回true。
- contains(Object o):判断集合中是否包含指定元素。
- size():返回集合中元素的数量。
- clear():清空集合中的所有元素。
- isEmpty():判断集合是否为空。
import java.util.HashSet;
public class HashSetExample{
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
//添加元素
set.add("apple" );
set.add("banana");
set.add("cherry");
//检查是否包含元素
System.out.println(set.contains("banana"); // 输出 true
// 移除元素
set.remove("banana");
//集合大小
System.out.println(set.size()); // 输出 2
}
}
2️⃣LinkedHashSet
LinkedHashSet是HashSet的子类,它基于哈希表实现,同时使用链表来维护元素的插入顺序。因此,它既具备HashSet的哈希表特性,又能保证元素按照插入顺序排列。
特点
- 不允许有重复的元素。
- 保证元素的插入顺序。
- 插入、删除和查找操作的时间复杂度平均为(O(1))。
- 适用于既希望利用哈希表的高效性能,又需要保留元素插入顺序的场景。
常用函数
- add(E e):添加元素。
- remove(object o):移除元素。
- contains(object o):检查是否包含某元素。
- size():返回元素个数。
- clear():清空集合。
- isEmpty():判断集合是否为空。
import java.util.LinkedHashSet;
public class LinkedHashSetExample {
public static void main(String[] args){
LinkedHashSet<String> set = new LinkedHashSet<>();
// 添加元素
set.add("apple" );
set.add("banana");
set.add("cherry");
//输出集合,按插入顺序
for (String s : set) {
System.out.println(s); //输出顺序为:apple,banana,cherry
}
// 检查是否包含元素
System.out.println(set.contains("banana")); // 输出 true
}
}
3️⃣TreeSet
TreeSet是基于红黑树(Red-Black Tree)实现的集合。与HashSet和LinkedHashSet不同,TreeSet会自动对元素进行排序。它实现了SortedSet接口,因此可以保证集合中的元素处于自然顺序(或者是用户自定义的排序规则)。
特点
- 不允许有重复的元素。
- 元素按照自然顺序(或自定义顺序)排序。
- 插入、删除和查找操作的时间复杂度为O(logn)。
- 适用于需要保持元素有序的场景。
常用函数:
- add(E e):添加元素。
- remove(Object o):移除元素。
- contains(Object o):检查是否包含某元素。
- size():返回集合中元素的数量。
- isEmpty():判断集合是否为空。
- first():返回集合中的第一个元素(最小的元素)。
- last():返回集合中的最后一个元素(最大的元素)。
import java.util.TreeSet;
public class TreeSetExample{
public static void main(String[] args) {
TreeSet<Integer> set = new TreeSet<>();
//添加元素
set.add(30);
set.add(10);
set.add(20);
set.add(40);
//自动排序
System.out.println(set); // 输出 [10,20, 30,40]
//获取第一个和最后一个元素
System.out.println("最小值:"+ set.first()); // 输出10
System.out.println("最大值:"+ set.last(); // 输出40
//获取子集
System.out.println("小于 30 的元素: " + set.headSet(30)); // 输出 [10,20]
System.out.println("大于等于20的元素:"+ set.tailSet(20));// 输出[20, 30,40]
}
}
⭐️Java提供的Map哈希表
在Java中,Map是一种用于存储键值对<key,value>的数据结构,每个键都唯一对应一个值,允许通过键来快速查找、更新和删除值。Java的Map接口有多种常见实现,如HashMap、LinkedHashMap和TreeMap。
1️⃣HashMap
HashMap是基于哈希表实现的Map,键值对存储无序。
特点
- 基于哈希表实现,键通过哈希函数映射到哈希表中的位置。
- 查找、插入、删除操作的平均时间复杂度为O(1)。
- 无序存储,元素的顺序不保证与插入顺序一致。
常用函数:
- put(K key,Vvalue):向Map中添加键值对,如果键已存在,更新对应的值。
- get(Object key):根据键查找对应的值。
- remove(Object key):移除指定键对应的键值对。
- getOrDefault(Object key,0):根据键查找对应的值,不存在返回0。
- containsKey(Object key):判断是否包含指定的键。
- size():返回Map中的键值对数量。
- clear():清空所有键值对。
- keySet():返回所有键的集合。
import java.util.HashMap;
public class HashMapExample {
public static void main(String[] args) {
//创建一个HashMap
HashMap<String, Integer> map = new HashMap<>();
//添加键值对
map.put("apple",1);
map.put("banana",2);
map.put("cherry", 3);
11获取值
System.out.println("apple 的值: " + map.get("apple"); // 输出 1
//判断是否包含键
System.out.println("是否包含cherry:"+ map.containsKey("cherry");// 输出 true
//移除键值对
map.remove("banana" );
1//获取键的集合
System.out.println("键的集合: " + map.keySet()); // 输出[apple,cherry]
//获取值的集合
System.out.println("值的集合:" + map.values(); // 输出[1,3]
// 获取 Map 大小
System.out.println("Map 大小:" + map.size()); // 输出 2
}
}
遍历哈希表
HashMap<String, Integer> map = new HashMap<>();
for(String key:map.keySet()){
//key和map.get(key);
}
2️⃣LinkedHashMap
LinkedHashMap是HashMap的子类,除了具有HashMap的所有特性外,还维护了一个双向链表,记录元素的
插入顺序或访问顺序。
- 特点:
- 元素按插入顺序(或访问顺序)排列。
- 性能与HashMap类似,但由于维护链表,性能略微降低。
- 适用于既希望保持键值对有序,又需要快速查找的场景。
import java.util.LinkedHashMap;
public class LinkedHashMapForEachExample{
public static void main(String[] args) {
//创建一个LinkedHashMap,默认按插入顺序排列
LinkedHashMap<String, Integer> linkedHashMap = new LinkedHashMap<>();
//添加键值对
linkedHashMap.put("apple",1);
linkedHashMap.put("banana", 2);
linkedHashMap.put("cherry",3);
//使用forEach遍历键值对
System.out.printIn(“使用forEach遍历LinkedHashMap(按插入顺序):");
linkedHashMap.forEach((key, value) -> {
System.out.println(key + ": " + value);
});
}
}
3️⃣TreeMap
TreeMap是基于红黑树实现的有序Map,键值对按照键的自然顺序或自定义比较器排序。
- 特点:
- 元素按键的自然顺序(或自定义顺序)排序。
- 查找、插入和删除的时间复杂度为O(1ogn)。
- 不允许存储null键(会抛出NullPointerException)。
- 适用于需要对键进行排序的场景。
import java.util.TreeMap;
public class TreeMapExample {
public static void main(String[] args) {
//创建一个TreeMap
TreeMap<String, Integer> map = new TreeMap<>();
/添加键值对
map.put("banana", 2);
map.put("apple", 1);1
map.put("cherry",3);
//按照键的自然顺序排序
System.out.println("TreeMap 键值对:"+ map); // 输出 {apple=1,banana=2,cherry=3}
//获取第一个和最后一个键
System.out.println("第一个键:"+ map.firstkey());//输出apple
System.out.println("最后一个键:"+ map.lastKey());//输出cherry
}
}