长治招聘网站建设wordpress重定向传递权重
Keras
Python 编写的高级神经网络 API,可以运行在TensorFlow上。
核心特点
- 用户友好:提供直观的 API,适合快速原型设计和实验。
- 模块化:神经网络由可配置的模块(层、优化器、损失函数等)组成,像搭积木一样灵活组合。
- 易扩展:支持自定义层、损失函数和模型结构。
- 多后端支持:默认使用 TensorFlow 作为后端,也可切换至 Theano 或 CNTK(后两者已逐渐淘汰)。
- 跨平台:支持 CPU 和 GPU 加速,可无缝部署到服务器、移动设备等。
核心组件

模型(Model)- 构建方式
- Sequential 模型(顺序模型):Keras中的一种模型构建方式,用于按顺序逐层堆叠神经网络层(如Dense、Conv2D等)。
from keras.models import Sequential
from keras.layers import Dense # 下面介绍model = Sequential()
model.add(Dense(64, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))- 函数式 API:支持复杂模型(如多输入/输出、共享层)。
from keras import Input, Modelinputs = Input(shape=(100,))
x = Dense(64, activation='relu')(inputs) # 输入维度100,输出64维
outputs = Dense(10, activation='softmax')(x) # 输出10维(如分类任务的10个类别)
model = Model(inputs=inputs, outputs=outputs)
层(Layers)
常用层-类型
- Dense(全连接)
- Dense 是全连接层(Fully Connected Layer)的实现,它是神经网络中最基础的层类型之一。
- Dense 层的每个神经元会与前一层的所有神经元相连,通过权重和偏置进行线性变换,并通常接一个非线性激活函数。
keras.layers.Dense(units, # 该层的神经元数量(输出维度)activation=None, # 激活函数(如 'relu', 'sigmoid', 'softmax')use_bias=True, # 是否使用偏置项kernel_initializer='glorot_uniform', # 权重初始化方法bias_initializer='zeros', # 偏置初始化方法kernel_regularizer=None, # 权重的正则化(如L1/L2)bias_regularizer=None # 偏置的正则化
)
作用
- 特征变换:将输入数据映射到更高维或更低维的空间。
- 非线性:通过激活函数引入非线性(如ReLU),使网络能学习复杂模式。
- 输出层:常用于分类任务的输出层(如Softmax)或回归任务(无激活函数)。
- 通过堆叠多个Dense层,可以构建深度全连接网络(如MLP),适用于表格数据、特征提取等任务。
- Conv2D(二维卷积层)
- LSTM(长短期记忆层)
- Dropout
- BatchNormalization
预处理层
- Rescaling
- TextVectorization(可直接嵌入模型)
训练配置
- 编译模型:指定优化器、损失函数和评估指标。
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
- 训练与评估:
model.fit(X_train, y_train, epochs=10, batch_size=32)
loss, accuracy = model.evaluate(X_test, y_test)
应用场景
- 计算机视觉:图像分类(ResNet)、目标检测(YOLO)。
- 自然语言处理:文本分类、机器翻译(Transformer)。
- 时间序列分析:股票预测、异常检测(LSTM)。
优势与局限
优势
- 学习曲线平缓,适合初学者。
- 与 TensorFlow 生态深度集成(如 TF Serving、TF Lite)。
- 丰富的预训练模型(如 keras.applications 中的 VGG16、BERT)。
局限
- 底层灵活性不如原生 TensorFlow/PyTorch(但可通过自定义代码扩展)。
- 部分高级功能需依赖后端框架(如分布式训练)。
使用流程
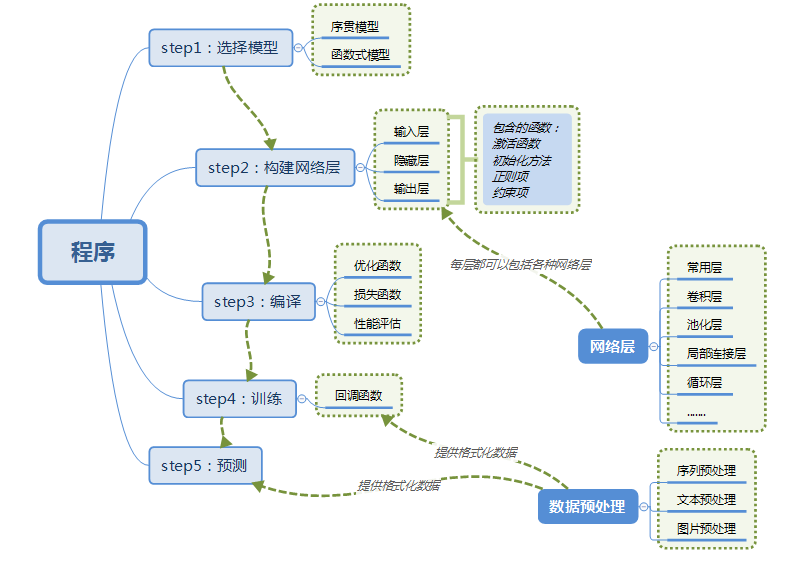
- 选择模型、创建模型(序贯模型、函数式模型)
- 添加层级、构建网络层(基础层、核心层、卷积层、池化层、循环层、融合层)网络配置(激活函数、初始化方法、正则项、约束项)
- 模型编译 compile
- 数据填充、模型训练 fit
- 模型评估 evaluate
- 模型预测 predict
- 模型保存 save
手写数字识别实例
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.optimizers import SGD
from keras.datasets import mnist
import numpy# 选择模型:序贯模型
model = Sequential()# 构建网络层:全连接层
model.add(Dense(500, input_shape(784,))) # 输入层,28*28=784
model.add(Activation('tanh')) # 激活函数是tanh
model.add(Dropout(0.5)) # 采用50%的dropoutmodel.add(Dense(500)) # 隐藏层节点500个
model.add(Activation('tanh'))
model.add(Dropout(0.5))model.add(Dense(10)) # 输出结果是10个类别,所以维度是10
model.add(Activation('softmax')) # 最后一层用softmax作为激活函数# 编译
sgd = SGD(lr=0.01, decay=1e-6, momentum=0.9, nesterov=True) # 优化函数,设定学习率(lr)等参数
model.compile(loss='categorical_crossentropy', optimizer=sgd, class_model='categorical') # 模型编译,使用交叉熵作为loss函数# 训练
(X_train, y_train), (X_test, y_test) = mnist.load_data() # 获取手写数字数据 (num, 28, 28)数据
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1] * X_train.shape[2]) # 将维度拼接为784维
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1] * X_test.shape[2])
# 独热编码:将分类变量转换为易于处理的形式
# 将10个类别与y_train比较形成一个列向量,bool类型转为int
# (样本量,10)
Y_train = (numpy.arange(10) == y_train[:, None]).astype(int)
Y_test = (numpyp.arage(10) == y_test[:, None]).astype(int)# batch_size:批次大小 epochs:轮次 shuffle:是否随机打乱 verbose:日志信息 validation_split:自动切分验证集验证
model.fit(X_train, Y_train, batch_size=200, epochs=50, shuffle=True, verbose=0, validation_split=0.3)
model.evaluate(X_test, Y_test, batch_size=200, verbose=0) # 评估# 输出
print("test set")
scores = model.evaluate(X_test,Y_test,batch_size=200,verbose=0)
print("")
print("The test loss is %f" % scores)
result = model.predict(X_test,batch_size=200,verbose=0)result_max = numpy.argmax(result, axis = 1) # 获得行最大值索引
test_max = numpy.argmax(Y_test, axis = 1)result_bool = numpy.equal(result_max, test_max)
true_num = numpy.sum(result_bool) # 获得正确样本总数
print("")
print("The accuracy of the model is %f" % (true_num/len(result_bool)))