建筑公司网站起名什么是网站死链
selenium库是一种用于Web应用程序测试的工具,它可以驱动浏览器执行特定操作,自动按照脚本代码做出单击、输入,打开,验证等操作,支持的浏览器包括IE、Firefox、Safari、Chrome、Opera等。而在办公领照下的城中如果经常需要使用浏览器操作某些内容,就可以使用selenium库来实现,与requests库不同的是,selenium库是基于浏览器的驱动程序来驱动浏览器执行操作的。且浏览器可以实现网页源代码的渲染,因此通过selenium库还可以轻松获取网页中渲染后的数据信息。
一.了解selenium库驱动浏览器的原理
浏览器是在浏览器内核基础之上开发而成的,浏览器内核主要负责对网页语法进行解释并渲染(显示)网页,例如360浏览器和Chrome浏览器都使用Chrome内核;而QQ浏览器使用IE内核,Safari浏览器使用Webkit内核。
虽然浏览器内核可以被selenium库驱动,但还是需要安装对应版本的浏览器内核驱动程序,以便于控制 Web浏览器的行为。每个浏览器都有一个特定的用于支持浏览器运行的WebDriver,被称为驱动程序(可以进 Aselenium库的官网进行下载,如果下载失败或无法匹配版本,还可以尝试下面介绍的相关方法)。下面以Microsoft Edge浏览器为例讲解:
1.安装驱动器

在这个网站上下载驱动:https://developer.microsoft.com/zh-cn/microsoft-edge/tools/webdriver/。
 找到自己浏览器所对应的驱动器
找到自己浏览器所对应的驱动器
将下载好的压缩包进行解压,并把下面这个文件放到所用的python文件夹下,并将一份复制到python-Script文件夹下
![]()
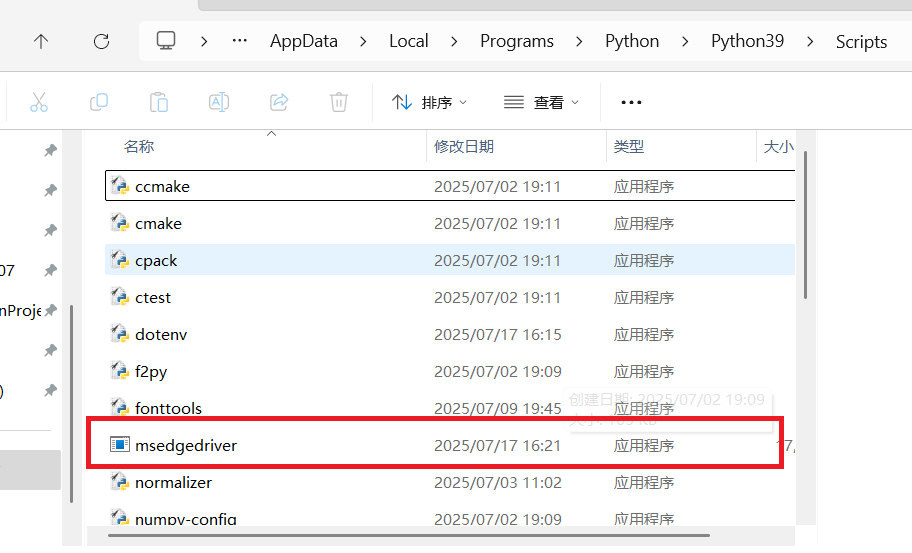
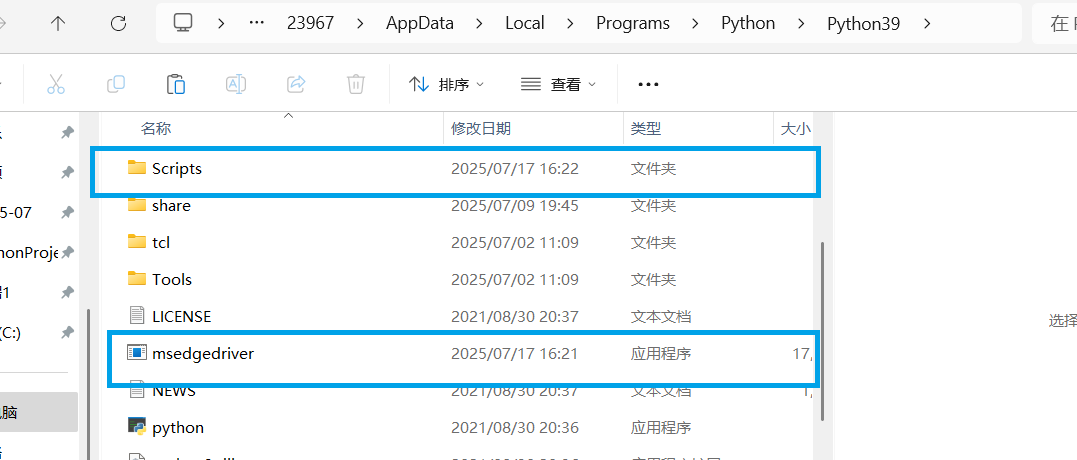
至此就完成了驱动器的配置。
2.安装selenium库
在命令提示符下输入命令:
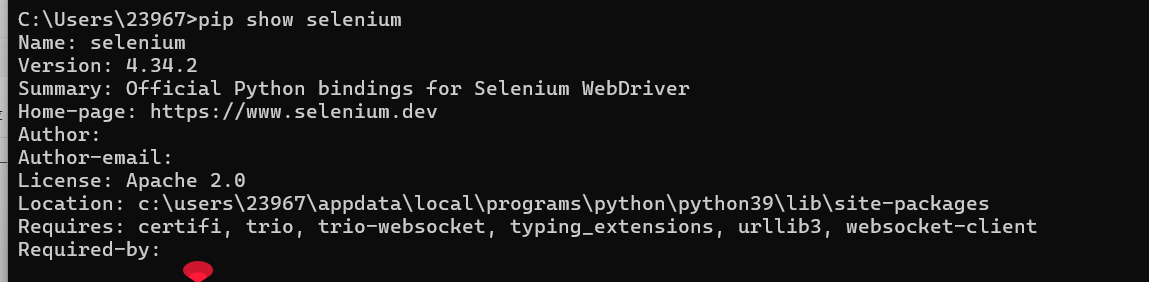
pip install selenium安装完后可以使用以下命令查看库的信息:
pip show selenium
二.驱动浏览器
1.驱动打开浏览器
在selenium库源代码文件下的webdriver中可查看所有支持的浏览器类型webdriver的使用形式如下:
webdriver.浏览器类型名() 例如驱动Chrome浏览器的使用方法動
webdriver.Chrome(),驱动Opera浏览器的使用方法为webdriver.opera()。webdriver.Chrome()的使用形式如下:
webdriver.Chrome(executable_path='chromedriver',port=0,options=None)功能:创建一个新的Chrome浏览器驱动程序。
参数executable_path:表示浏览器的驱动路径,默认为环境变量中的path,通常计算机中可能存在多个浏览器软件,当没有在环境变量中设置浏览器path时,可以使用参数options。
参数port: 表明希望服务运行的端口,如果保留为0,驱动程序将会找到一个空闲端口。
参数options:表示由类Options(位于selenium\webdriver\chrome\options.py)创建的对象,用于实现浏览器的绑定。
示例代码:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
a=input()第3、4行代码使用类Options创建了一个对象Edge_options,使用binary_location()方法绑定了浏览器。
第5行代码使用webdriver.Edge()设置options参数值为绑定Edge浏览器的对象Edge_options.执行代码后将会自动打开Edge浏览器,实现驱动浏览器的第一步。
2.加载网页
第1种get()方法。get()方法用于打开指定的网页。其使用形式如下:
get(url)功能:在当前浏览器会话中加载url指向的网页。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.douyin.com/')
a=input()第6行代码使用get()方法加载抖音,执行代码后将会自动启动 Edge浏览器并加载出相应网页,
 第2种,execute_script()方法。execute_ script()方法用于打开多个标签页,即在同一浏览器中打开多个网页。其使用形式如下:
第2种,execute_script()方法。execute_ script()方法用于打开多个标签页,即在同一浏览器中打开多个网页。其使用形式如下:
execute_script(script, *args) 功能:打开标签页,同步执行当前页面中的JavaScript脚本。JavaScript是网页中的一种编程语言。
参数script:表示将要执行的脚本内容,数据类型为字符串类型。使用JavaScript语言实现打开一个新标签页的使用形式为"window.open('网站url','_blank');"
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.douyin.com/')
driver.execute_script("window.open('https://www.shuyishe.com/','_blank');")
driver.execute_script("window.open('https://www.shuyishe.com/course','_blank');")
a=input()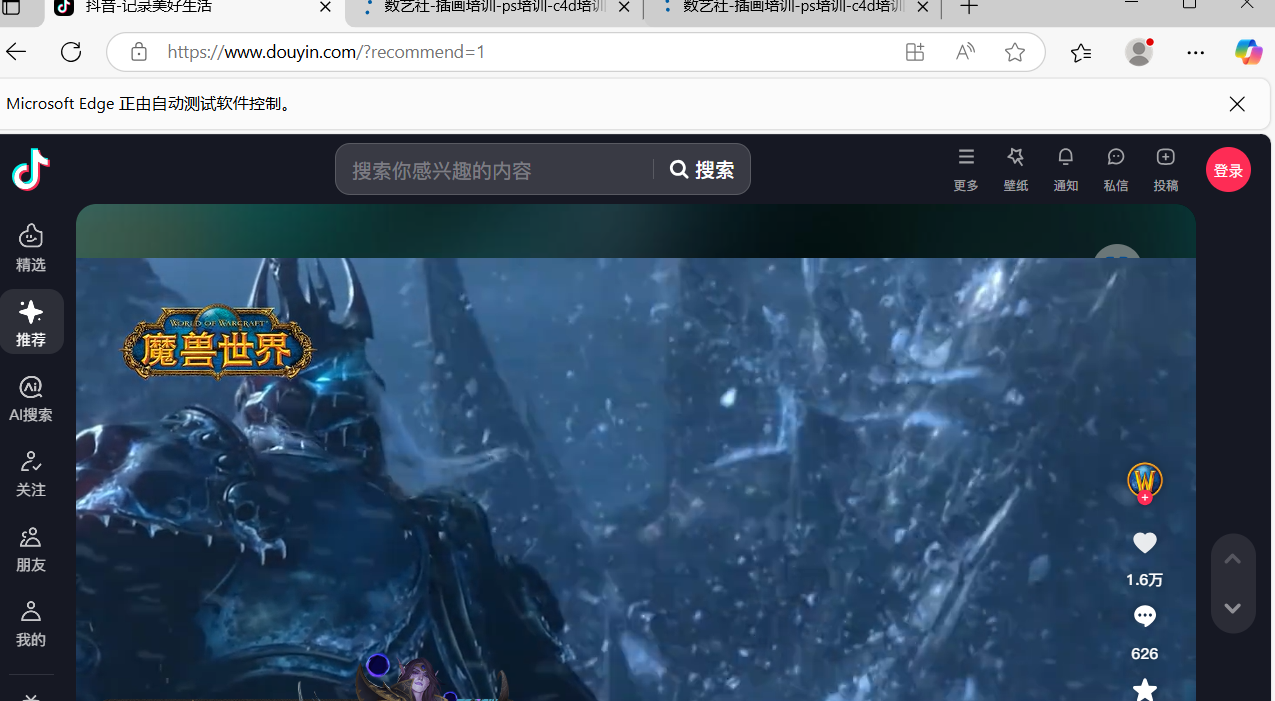
第7~9行代码使用execute_script()方法 执行括号中的JavaScript脚本,打开的新标签页分别为抖音页面,数艺设的主页和数艺设的课程页面。
3.获取渲染后的网页代码
通过get()方法获取浏览器中的网页资源后,浏览器将自动渲染网页源代码内容,并生成渲染后的 内容,这时使用page_source()方法可以获取需渲染后的网页代码。
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.douyin.com/')
print(driver.page_source)
a=input()
第7行代码使用driver对象中的page_source()方法获取到的渲染后的源代码。
三小项目案例:实现批量下载网页中的资源
项目任务:实现批量下载人民邮电出版社官网中与Python相关的图书封面图片
项目实现步骤:
步骤1:获取人民邮电出版社官网中与Python相关的图书封面图片url。使用get()方法即可获取关键前在获取“python”的图书封面图片url。
步骤2,使用selenium库驱动浏览器渲染网页,并获取渲染后的网页代码。
步骤3:使用正则表达式过滤出图片的url
步骤4:将对应的url的图片下载到本地。
import re
import requests
from selenium import webdriver
from selenium.webdriver.edge.options import Options
edge_options = Options()
edge_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/search?keyword=python')
a= re.findall('<img src="(.+?jpg)"></div>',driver.page_source)
i = 1
for url in a:r = requests.get(url)f2 = open('Python图书\\'+str(i)+'.jpg','wb')i += 1f2.write(r.content)f2.close()
a=input()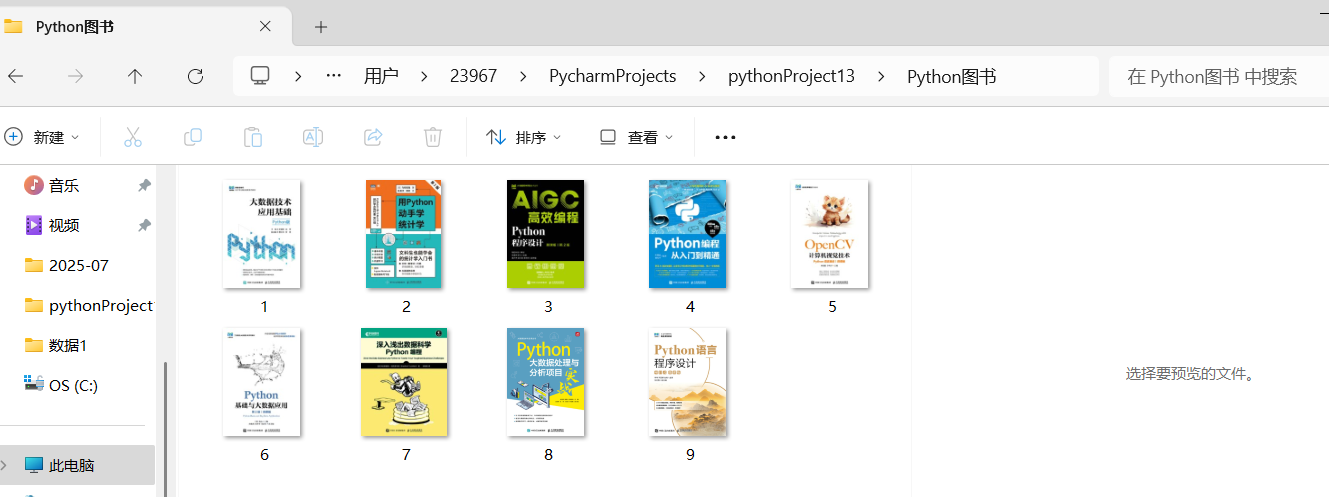
第4-6行代码绑定了Edge浏览器,并驱动浏览器。
第7行代码使用get()方法打开Python类图书的网页,
第8行代码使用正则表达式过滤driver.page_source(渲染后的网页代码)中的图片url。可以观察到所有图书封面图片的标签为<img>,图片格式为.jpg,且下一个标签为</div>。因此使用正则表达式设计的过滤规则为'< img src=*(.+?jpg)"></div>'。过滤规则不是统一的,可以自行设计过滤规则。
9~15行代码使用requests库中的get()方法将过滤出来的url分别保存到相对路径“\Python图书”下。执行代码后将会自动下载网页中的图书封面图片到本地文件夹“\Python图书”中,