【LangChain】理论及应用实战(2)
文章目录
- 1. Loader 加载器
- 2. Text Splitter 文本分割
- 3. 文档的总结、精炼、翻译
- 4. 文本向量化
- 5. 嵌入向量缓存
- 6. 向量数据库
- 7. 实战:ChatDoc 文档检索小助手
- 参考资料
本文主要内容:基于Langchian实现RAG
Langchian中 RAG 中的 Retrieve(检索) 流程如下:
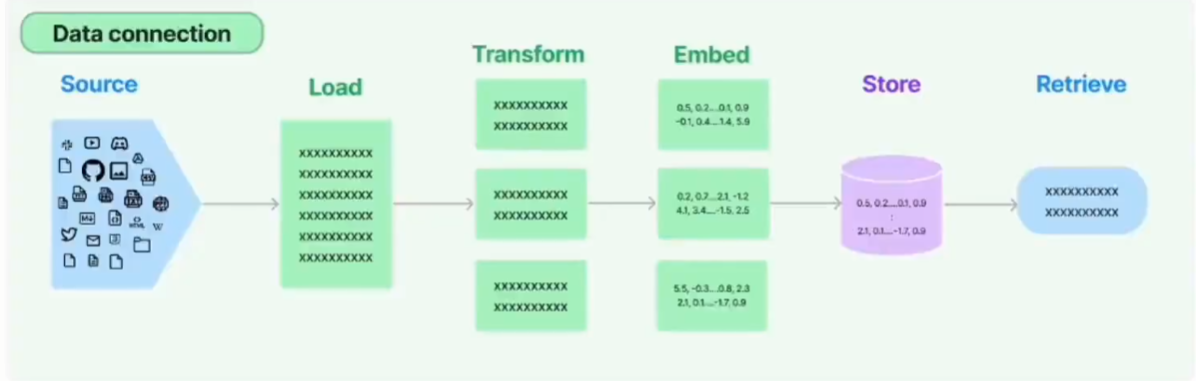
各种文档->各种loader->文本切片->嵌入向量化->向量存储->各种检索链
1. Loader 加载器
loader 就是从指定源进行加载数据,比如:
- Text文件:TextLoader
- 文件夹:DirectoryLoader
- CSV文件:CSVLoader
- Google网盘:GoogleDriveLoader
- 任意的网页:UnstructuredHTMLLoader
- PDF:PyPDFLoader
- Youtube:YoutubeLoader
上面只是简单的进行列举了几个,官方提供了超级的多的加载器供你使用。
这里,我们给出最为常见的几种数据loader的使用方式:
(1) 加载Text文件:TextLoader
from langchain_community.document_loaders import TextLoader
loader = TextLoader("./index.md")
data = loader.load()
(2) 加载CSV文件:CSVLoader
from langchain_community.document_loaders import CSVLoader
loader = CSVLoader("./data/test.csv")
data = loader.load()
(3) 加载JSON文件
# pip install jq
from langchain_community.document_loaders import JSONLoader
loader = JSONLoader(
file_path="./data/student.json", jq_schema=".template", text_content=False
)
data = loader.load()
(4) 加载PDF文件:PyPDFLoader
# pip install pypdf
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/paper.pdf")
data = loader.load()
2. Text Splitter 文本分割
文本分割就是用来分割文本的。为什么需要分割文本?因为我们每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。
比如我们将一份300页的 pdf 发给 openai api,让他进行总结,他肯定会报超过最大 Token 错。所以这里就需要使用文本分割器去分割我们 loader 进来的 Document。
示例如下:
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载需要切分的文档
with open("./data/file.txt") as f:
all_text = f.read()
# 使用递归字符切分器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200, # 切分的文本块大小
chunk_overlap=20, # 切分的文本块重叠大小
length_function=len, # 长度函数
add_start_index=True # 是否添加开始索引
)
split_text = text_splitter.create_documents([all_text])
print(split_text)
输出如下:
[Document(metadata={'start_index': 0}, page_content='LangChain is a framework for developing applications powered by large language models (LLMs).\n\nLangChain simplifies every stage of the LLM application lifecycle:'), Document(metadata={'start_index': 163}, page_content="Development: Build your applications using LangChain's open-source components and third-party integrations. Use LangGraph to build stateful agents with first-class streaming and human-in-the-loop"), Document(metadata={'start_index': 341}, page_content='human-in-the-loop support.'), Document(metadata={'start_index': 368}, page_content='Productionization: Use LangSmith to inspect, monitor and evaluate your applications, so that you can continuously optimize and deploy with confidence.'), Document(metadata={'start_index': 519}, page_content='Deployment: Turn your LangGraph applications into production-ready APIs and Assistants with LangGraph Platform.')]
3. 文档的总结、精炼、翻译
首先安装 doctran 依赖包:
pip install doctran
具体实现如下:
from dotenv import load_dotenv
from doctran import Doctran
import os
# 加载文档
with open("./data/file.txt") as f:
content = f.read()
load_dotenv("openai.env")
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")
OPENAI_API_BASE = os.environ.get("OPENAI_API_BASE")
OPENAI_MODEL = "gpt-3.5-turbo-16k"
OPENAI_TOKEN_LIMIT = 8000
doctrans = Doctran(
openai_api_key=OPENAI_API_KEY,
openai_model=OPENAI_MODEL,
openai_token_limit=OPENAI_TOKEN_LIMIT,
)
documents = doctran.create_documents(content=content)
# (1) 总结文档
summary = documents.summarize(token_limit=100).execute()
print(summary.transformed_content)
# (2) 翻译文档
translation = documents.translate(
language="chinese"
).execute()
print(summary.transformed_content)
# (3) 精炼文档,仅保留与主题相关的内容
refined = documents.refine(
topic=['langchain']
).execute()
print(refined.transformed_content)
4. 文本向量化
Embedding嵌入可以让一组文本或者一段话以向量来表示,从而可以让我们在向量空间中进行语义搜索之类的操作,从而大幅提升学习能力。
# from langchain.embeddings import OpenAIEmbeddings
from langchain_ollama import OllamaEmbeddings
e_model = OllamaEmbeddings(
model="nomic-embed-text"
)
text = "今天天气真好"
single_vector = e_model.embed_query(text)
print("single_vector:", single_vector)
multi_vector = e_model.embed_documents(
[
"你好",
"今天天气真好",
"你叫什么名字",
"我叫小红",
]
)
print("multi_vector:", multi_vector)
输出如下:
single_vector: [0.023803584, 0.019944623, -0.18307257, 0.016884161, 0.013910737, 0.041673694, 0.0119952755, -0.0038184985, -0.0638501, -0.031662196, -0.04351526, 0.025420515, ......]]
multi_vector: [[-0.005196261, 0.01294648, -0.16610104, 0.0030547038, 0.06508742, 0.010399415, -0.03311033, -0.01913366, -0.017523672, -0.054374795, ......]]
参考博客:基于Ollama和LangChain使用embeddings模型进行文档检索
5. 嵌入向量缓存
加载文档,切分文档,将切分文档向量化并存储在缓存中:
首先安装 FAISS 向量数据库:
pip install faiss-cpu
完整代码如下:
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain.document_loaders import TextLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
# 定义embedding模型
u_embeddings = OpenAIEmbeddings()
fs = LocalFileStore("./cache/")
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(
u_embeddings,
fs,
namespace=u_embeddings.model
)
list(fs.yield_keys())
# 加载文档,切分文档
raw_documents = TextLoader("letter.txt").load()
text_splitter = CharacterTextSplitter(chunk_size=600, chunk_overlap=0)
documents = text_splitter.split_documents(raw_documents)
# 将缓存写入向量数据库中
db = FAISS.from_documents(documents, cached_embeddings) # 向量化到FAISS向量数据库中
# 查看缓存中的键
list(fs.yield_keys())
6. 向量数据库
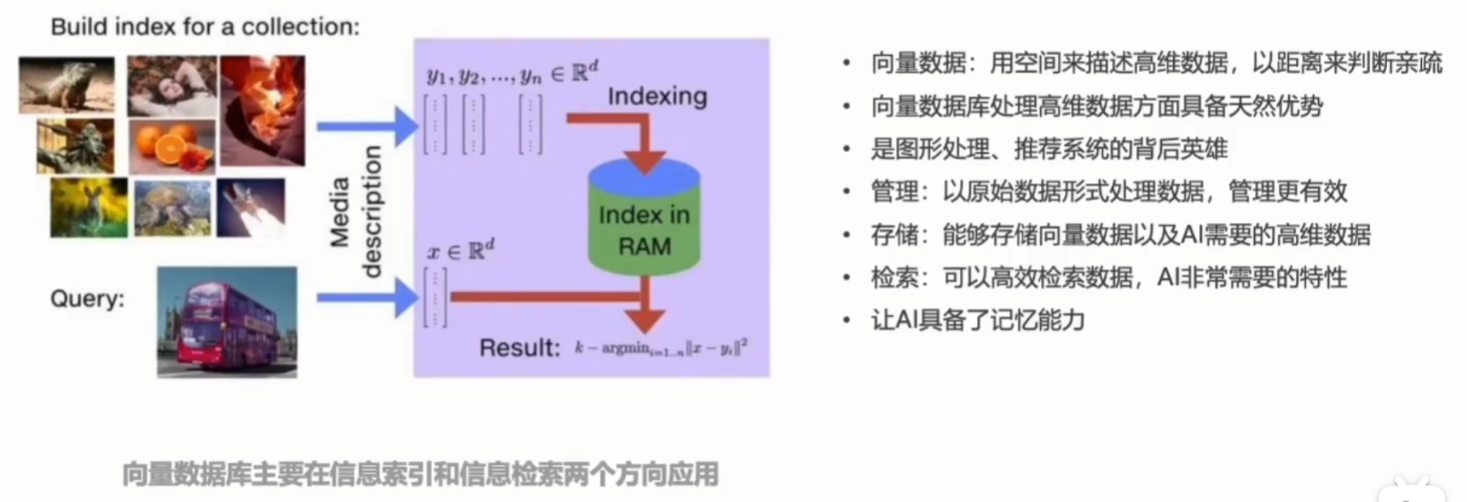
下面简单介绍几种常见的向量数据库:

7. 实战:ChatDoc 文档检索小助手
ChatDoc 文档检索小助手的功能:
- 可以加载pdf或者xls格式文档
- 可以对文档进行适当切分
- 文档进行向量化
- 使用Chroma db实现本地向量存储
- 使用智能检索实现和文档的对话
from langchain_community.document_loaders import Docx2txtLoader, PyPDFLoader, UnstructuredExcelLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain_ollama import OllamaEmbeddings
class ChatDocAuto(object):
def __init__(self, file_path):
self.file_path = file_path
self.doc = None
self.split_text = [] # 分割后的文本
def get_file_content(self):
loaders = {
"docx": Docx2txtLoader,
"pdf": PyPDFLoader,
"xlsx": UnstructuredExcelLoader
}
file_extension = self.file_path.split(".")[-1]
loader_class = loaders.get(file_extension)
if loader_class:
try:
loader = loader_class(self.file_path)
text = loader.load()
return text
except Exception as e:
print("Error loading {}".format(file_extension))
else:
print("Unsupported file extension {}".format(file_extension))
# 文档切割函数
def split_sentence(self):
full_text = self.get_file_content()
if full_text is not None:
text_splitter = CharacterTextSplitter(chunk_size=150, chunk_overlap=20)
texts = text_splitter.split_documents(full_text)
self.split_text = texts
# return texts
# 向量化与存储索引
def embedding_and_vector(self):
embeddings = OllamaEmbeddings(model="nomic-embed-text")
db = Chroma.from_documents(
documents=self.split_text,
embedding=embeddings
)
return db
def ask_and_find_files(self, question):
db = self.embedding_and_vector()
retriever = db.as_retriever()
results = retriever.invoke(question)
return results
if __name__ == "__main__":
file_path = "./data/paper.pdf"
chatDocAuto = ChatDocAuto(file_path)
# 查看文档内容
content = chatDocAuto.get_file_content()
# print(content)
# 对文档进行分割
chatDocAuto.split_sentence()
# print(chatDocAuto.split_text)
# 文档嵌入向量化
chatDocAuto.embedding_and_vector()
# 索引并使用自然语言找出相关的文本块
question = "What is ITRANSFORMER?"
result = chatDocAuto.ask_and_find_files(question)
print(result)
[Document(metadata={'author': '', 'creationdate': '2023-12-04T01:26:30+00:00', 'creator': 'LaTeX with hyperref', 'keywords': '', 'moddate': '2024-06-03T09:01:40+08:00', 'page': 8, 'page_label': '9', 'producer': 'pdfTeX-1.40.25', 'ptex.fullbanner': 'This is pdfTeX, Version 3.141592653-2.6-1.40.25 (TeX Live 2023) kpathsea version 6.3.5', 'source': './data/paper.pdf', 'subject': '', 'title': '', 'total_pages': 24, 'trapped': '/False'}, page_content='Analysis of multivariate correlations By assigning the duty of multivariate correlation to the\nattention mechanism, the learned map enjoys enhanced interpretability. We present the case visual-\nization on series from Solar-Energy in Figure 7, which has distinct correlations in the lookback and\nfuture windows. It can be observed that in the shallow attention layer...
可以看到虽然能检索到相关的结果,但是准确性不佳。这时候如果想优化检索结果,可以引入大模型进行多重查询,关键代码如下:
from langchain.retrievers import MultiQueryRetriever
class ChatDocAuto(object):
......
def ask_and_find_files_by_llm(self, question):
db = self.embedding_and_vector()
# 把问题交给llm进行多角度扩展
llm = OllamaLLM(model="llama3.1:8b")
retriever_from_llm = MultiQueryRetriever(
retriever=db.as_retriever(),
llm=llm
)
results = retriever_from_llm.get_relevant_documents(question)
return results
参考资料
AI Agent智能体开发,一步步教你搭建agent开发环境(需求分析、技术选型、技术分解)