制作网站公司网址开发公司公司简介
提示:高并发内存池完整项目代码,在主页专栏项目中
文章目录
提示:高并发内存池完整项目代码,在主页专栏项目中
高并发内存池整体框架设计
一、thread cache 完整代码实现
Common.h - 公共头文件
ThreadCache.h - 线程缓存头文件
ThreadCache.cpp - 线程缓存实现
ConcurrentAlloc.h - 并发分配接口
二、核心代码解析
1. ThreadCache类定义
2. 线程本地存储(TLS)
3. 内存分配过程
4. 内存释放过程
5. 大小对齐策略
6. 自由链表操作
设计精髓
性能优势


高并发内存池整体框架设计
现代很多的开发环境都是多核多线程,在申请内存的场景下,必然存在激烈的锁竞争问题。malloc本 ⾝其实已经很优秀,那么我们项⽬的原型tcmalloc就是在多线程⾼并发的场景下更胜⼀筹,所以这次 我们实现的内存池需要考虑以下⼏⽅⾯的问题。
1.性能问题。
2. 多线程环境下,锁竞争问题。
3. 内存碎⽚问题。
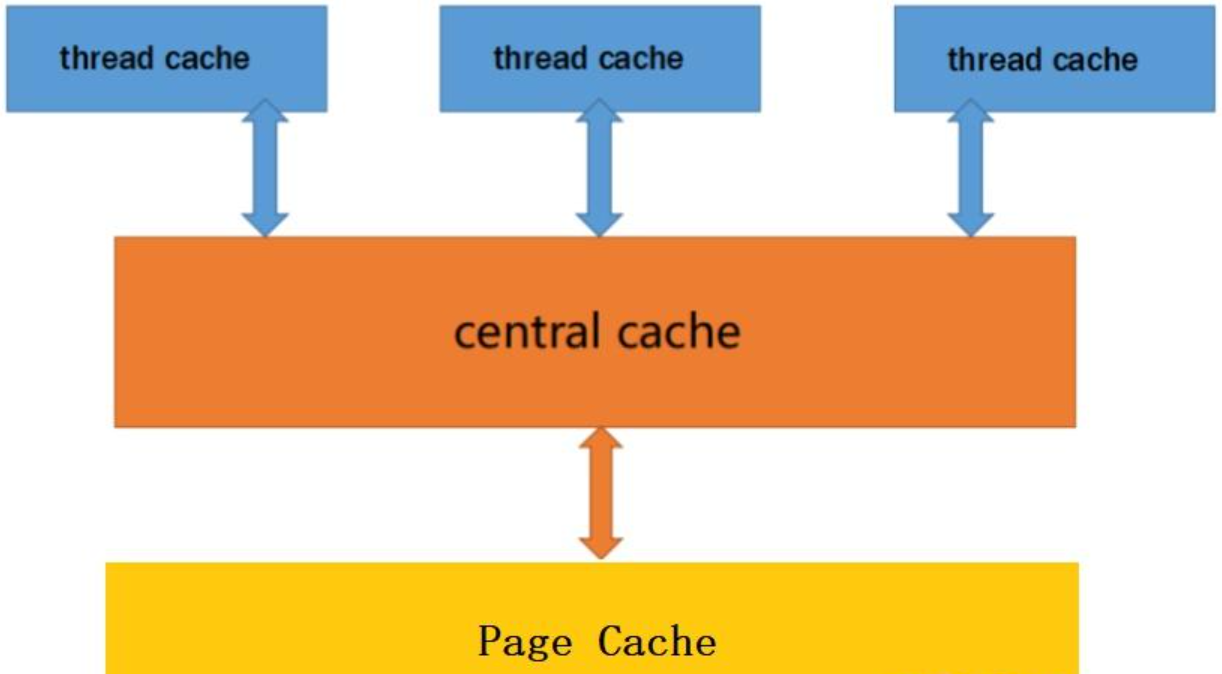
concurrent memorypool主要由以下3个部分构成:
1. threadcache:线程缓存是每个线程独有的,⽤于⼩于256KB的内存的分配,线程从这⾥申请内存 不需要加锁,每个线程独享⼀个cache,这也就是这个并发线程池⾼效的地⽅。
2. central cache:中⼼缓存是所有线程所共享,threadcache是按需从centralcache中获取的对 象。centralcache合适的时机回收threadcache中的对象,避免⼀个线程占⽤了太多的内存,⽽其 他线程的内存吃紧,达到内存分配在多个线程中更均衡的按需调度的⽬的。centralcache是存在竞 争的,所以从这⾥取内存对象是需要加锁,⾸先这⾥⽤的是桶锁,其次只有threadcache的没有内 存对象时才会找centralcache,所以这⾥竞争不会很激烈。
3. pagecache:⻚缓存是在centralcache缓存上⾯的⼀层缓存,存储的内存是以⻚为单位存储及分 配的,centralcache没有内存对象时,从pagecache分配出⼀定数量的page,并切割成定⻓⼤⼩ 的⼩块内存,分配给centralcache。当⼀个span的⼏个跨度⻚的对象都回收以后,pagecache会 回收centralcache满⾜条件的span对象,并且合并相邻的⻚,组成更⼤的⻚,缓解内存碎⽚的问 题。
一、thread cache 完整代码实现
Common.h - 公共头文件
#pragma once#include <iostream>
#include <vector>
#include <thread>
#include <time.h>
#include <assert.h>using std::cout;
using std::endl;// 常量定义
static const size_t MAX_BYTES = 256 * 1024; // 最大内存块大小
static const size_t NFREELIST = 208; // 自由链表数量// 获取对象的下一个指针
static void*& NextObj(void* obj)
{return *(void**)obj;
}// 自由链表类
class FreeList
{
public:// 将对象添加到链表头部void Push(void* obj){assert(obj);NextObj(obj) = _freeList;_freeList = obj;}// 从链表头部移除对象void* Pop(){assert(_freeList);void* obj = _freeList;_freeList = NextObj(obj);return obj;}// 检查链表是否为空bool Empty(){return _freeList == nullptr;}private:void* _freeList = nullptr; // 链表头指针
};// 大小分类器
class SizeClass
{
public:// 内存对齐static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}// 根据大小选择对齐方式static inline size_t RoundUp(size_t size){if (size <= 128) return _RoundUp(size, 8);else if (size <= 1024) return _RoundUp(size, 16);else if (size <= 8*1024) return _RoundUp(size, 128);else if (size <= 64*1024) return _RoundUp(size, 1024);else if (size <= 256 * 1024) return _RoundUp(size, 8*1024);else { assert(false); return -1; }}// 计算内存块在自由链表中的索引static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 根据字节数计算对应的自由链表索引static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128) return _Index(bytes, 3);else if (bytes <= 1024) return _Index(bytes - 128, 4) + group_array[0];else if (bytes <= 8 * 1024) return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];else if (bytes <= 64 * 1024) return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];else if (bytes <= 256 * 1024) return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];else { assert(false); }return -1;}
};ThreadCache.h - 线程缓存头文件
#pragma once#include "Common.h"class ThreadCache
{
public:// 申请内存对象void* Allocate(size_t size);// 释放内存对象void Deallocate(void* ptr, size_t size);// 从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);private:FreeList _freeLists[NFREELIST]; // 自由链表数组
};// 线程本地存储指针
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;ThreadCache.cpp - 线程缓存实现
#include "ThreadCache.h"// 从中心缓存获取内存对象
void* ThreadCache::FetchFromCentralCache(size_t index, size_t size)
{// 这里实现从中心缓存批量获取对象的逻辑// 实际实现会涉及与CentralCache的交互return nullptr;
}// 内存分配接口
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}// 内存释放接口
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);
}ConcurrentAlloc.h - 并发分配接口
#pragma once#include "Common.h"
#include "ThreadCache.h"// 并发内存分配函数
static void* ConcurrentAlloc(size_t size)
{// 通过TLS获取每个线程的专属ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);
}// 并发内存释放函数
static void ConcurrentFree(void* ptr, size_t size)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}二、核心代码解析
threadcache整体设计
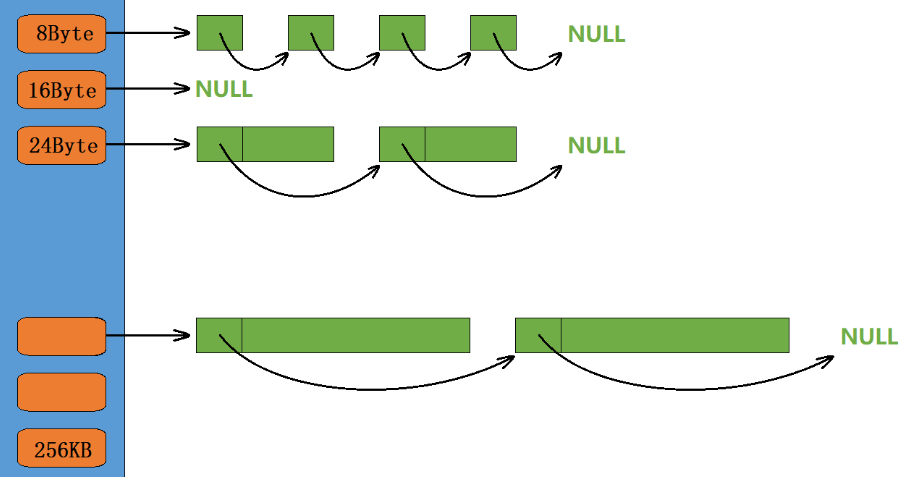
定长内存池只支持固定大小内存块的申请释放,因此定长内存池中只需要一个自由链表管理释放回来的内存块。现在我们要支持申请和释放不同大小的内存块,那么我们就需要多个自由链表来管理释放回来的内存块,因此thread cache实际上一个哈希桶结构,每个桶中存放的都是一个自由链表。
thread cache支持小于等于256KB内存的申请,如果我们将每种字节数的内存块都用一个自由链表进行管理的话,那么此时我们就需要20多万个自由链表,光是存储这些自由链表的头指针就需要消耗大量内存,这显然是得不偿失的。
1. ThreadCache类定义
class ThreadCache
{
public:// 申请和释放内存对象void* Allocate(size_t size);void Deallocate(void* ptr, size_t size);// 从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);
private:FreeList _freeLists[NFREELIST]; // 自由链表数组
};ThreadCache的核心是一个自由链表数组_freeLists,包含208个桶(NFREELIST),每个桶管理不同大小的内存块。这种设计类似于"超市",各种规格的内存块分门别类放置,申请时快速匹配。
2. 线程本地存储(TLS)
// TLS thread local storage
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;这里使用了线程本地存储(TLS)技术,每个线程都有自己独立的pTLSThreadCache指针。这意味着:
-
无锁操作:线程访问自己的ThreadCache不需要加锁
-
快速访问:直接通过线程本地变量获取,速度极快
-
线程隔离:各线程的内存操作互不干扰
3. 内存分配过程
void* ThreadCache::Allocate(size_t size)
{assert(size <= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size); // 大小对齐size_t index = SizeClass::Index(size); // 计算索引if (!_freeLists[index].Empty()) // 对应自由链表不为空{return _freeLists[index].Pop(); // 直接弹出对象}else // 自由链表为空{return FetchFromCentralCache(index, alignSize); // 从中心缓存获取}
}分配过程分为三步:
-
大小对齐:将请求大小调整为预设的规格
-
计算索引:找到对应的自由链表桶
-
分配判断:如果链表有对象直接返回,否则向中心缓存申请
4. 内存释放过程
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);// 找对映射的自由链表桶,对象插入进入size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr); // 将对象插回链表
}释放过程非常简单,直接计算对象应该回到哪个自由链表,然后执行头插法插入。这种设计使得释放操作几乎是常数时间复杂度。
5. 大小对齐策略
// 整体控制在最多10%左右的内碎片浪费 // [1,128] 8byte对齐 freelist[0,16) // [128+1,1024] 16byte对齐 freelist[16,72) // [1024+1,8*1024] 128byte对齐 freelist[72,128) // [8*1024+1,64*1024] 1024byte对齐 freelist[128,184) // [64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208)
SizeClass类负责大小对齐和索引计算,采用分段策略平衡内碎片和管理效率。这种设计将内碎片浪费控制在10%左右,是一个很好的权衡。
6. 自由链表操作
class FreeList
{
public:void Push(void* obj) // 头插法{assert(obj);NextObj(obj) = _freeList;_freeList = obj;}void* Pop() // 头删法{assert(_freeList);void* obj = _freeList;_freeList = NextObj(obj);return obj;}// ...
};自由链表采用经典的LIFO(后进先出)策略,使用头插法和头删法实现Push和Pop操作,这两种操作都是O(1)时间复杂度,极其高效。
设计精髓
-
无锁设计:通过TLS实现线程本地缓存,避免锁竞争
-
分段管理:不同大小内存块使用不同对齐策略,平衡内碎片和管理效率
-
懒加载:只有在需要时才向中心缓存申请内存,减少一次性开销
-
局部性原理:最近释放的内存很可能很快被再次分配,LIFO策略充分利用这一点
性能优势
这种设计在高并发场景下具有显著优势:
-
分配速度快:大部分情况下直接操作自由链表,不需要系统调用
-
锁竞争少:只有线程本地缓存不足时才访问中心缓存,且中心缓存有自己的锁策略
-
缓存友好:连续分配的内存很可能在CPU缓存中,提高访问速度