【ElasticSearch实用篇-05】基于脚本script打分
ElasticSearch实用篇整体栏目
| 内容 | 链接地址 |
|---|---|
| 【一】需求分析和数据制造 | https://zhenghuisheng.blog.csdn.net/article/details/149178534 |
| 【二】基本增删改查 | https://zhenghuisheng.blog.csdn.net/article/details/149202330 |
| 【三】QueryDsl高阶用法以及缓存机制 | https://zhenghuisheng.blog.csdn.net/article/details/150560441 |
| 【四】Boost权重底层原理和基本使用 | https://zhenghuisheng.blog.csdn.net/article/details/151071140 |
| 【五】基于脚本script打分 | https://zhenghuisheng.blog.csdn.net/article/details/154619702 |
基于脚本script打分
- 一、基于脚本script打分
- 1,需求提出
- 2,分数设计
- 3,代码实现
- 3.1,mapping映射
- 3.1,脚本实现
- 3.2,java代码实现
- 3.3,kibana执行
- 3.4,数据验证
- 4,总结
如需转载,请附上链接:https://blog.csdn.net/zhenghuishengq/article/details/154619702
一、基于脚本script打分
本文是ElasticSearch实用篇的第五篇,前面几篇已经准备好了数据,设置好了索引、mapping,以及讲解了es的基本使用,包括上一篇讲解了es底层的boost权重打分机制,接下来本文就是讲解第一个设置权重并打分的方式,基于脚本的方式进行打分,并且获取想要的返回数据。
在学习使用脚本打分之前,依旧需要先看一下官网的案例和使用:https://www.elastic.co/guide/cn/elasticsearch/guide/current/script-score.html
script_score 会完全覆盖 BM25 原生评分 ,因此能通过filter走索引的尽量用这个filter,实现不行就通过must缩小范围。
1,需求提出
在前面几篇文章中,我们社交系统已经有了10几万的用户,此时每个用户都有以下数据存于我们的表中,昵称、性别、生日、身高、体重、学历、老家、工作城市
| 字段 | 含义 |
|---|---|
| nickName | 昵称 |
| sex | 性别 1=男,0=女 |
| birthYear/birthMonth/birthDay | 出生年/月/日 |
| height/weight | 身高/体重 |
| eduLevel | 学历: 3=大专以下,4=大专,5=大学本科,6=硕士,7=博士 |
| liveProvince/liveCity | 居住省份/居住城市 |
| regProvince/regCity | 老家省份/老家城市 |
比如需要给会员一个优质用户提供的服务,那么就需要在我们的用户系统中对这些用户进行匹配和筛选,给会员提供优质用户服务。接下来有以下需求(具体需求根据产品去定义),由于是社交系统,匹配的直接是用户,所以呢必须得是异性,其他的需求具体如下,优先级逐级递减
- 优先匹配同城的异性,生活城市或者工作城市同城
- 其次优先匹配老家是同城的用户
- 其次优先匹配学历,学历越高越优先
- 其次匹配身高和体重:
- 如果用户是男,那么匹配女生的身高低于0-10cm优先匹配,体重在100-120优先匹配
- 如果用户是女,那么匹配男生的身高高于0-10cm优先,体重在120-140的优先
除了上面的条件之外,也有几个固定条件,如下
- 必须是异性
- 用户账号必须没被注销(是否删除,0=未删除,1=已删除)
- 匹配的用户年龄可以在正负10岁左右(通过出生年判断即可)
2,分数设计
由于在es中匹配时非常快的,比如基于倒排索引等等,可以快速的匹配和定位用户信息,将优质用户推荐给会员。那么就需要对这个需求进行分数设计,给每一个条件一定的分数。
由于社交系统,最优先的一定是异性,所以可以强制过滤掉异性,其他的同城体重身高等分数可以根据产品进行设计,其分数设计思路如下:
| 条件 | 分数 |
|---|---|
| 同城异性(生活或者工作) | 1200 |
| 老家(老家在一个城市) | 500 |
| 学历 | 博士=200 硕士=160 本科120 专科=20 |
| 身高 | 100 |
| 体重 | 100 |
由于同城异性一定是需要排在前面,所以给同城的分数最高,即使下面所有的条件符合,加起来的分数也不能超过同城;其实优先级是老家,那么也同理,学历+身高+体重的累计分也不能超过老家的分数,因此同城给1200,老家给500。
站在产品的角度,如果不是同城,那么推荐的用户其实符合几个条件也无所谓了,如果是同城,那么就会根据所有符合条件的分数进行累加,最高分数的优先排在前面。 ES 的 score 只是排序权重,不是概率,也不是百分比
当然分数也能动态调整,根据产品的实际情况以及用户反馈进行动态调整
3,代码实现
3.1,mapping映射
虽然前面几篇文章已经写过了mapping映射,但是这里再写一次,方便知道什么字段对应着什么类型,什么时候需要用keyword进行不分词查找
GET /user/_mapping
其映射如下
{"user" : {"mappings" : {"properties" : {"_class" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"birthDay" : {"type" : "long"},"birthMonth" : {"type" : "long"},"birthYear" : {"type" : "long"},"delFlag" : {"type" : "long"},"eduLevel" : {"type" : "long"},"height" : {"type" : "long"},"id" : {"type" : "long"},"liveCity" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"liveProvince" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"nickName" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"regCity" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"regProvince" : {"type" : "text","fields" : {"keyword" : {"type" : "keyword","ignore_above" : 256}}},"sex" : {"type" : "long"},"weight" : {"type" : "long"}}}}
}3.1,脚本实现
类似于这种复杂的业务,我们可以直接通过es中的script脚本实现,在java的api中也实现了这种Script脚本,那么其脚本如下,可以写在一个txt文件中,这个文件一般放在resource下,我将他放在resource下的es_script目录下,取名为user.txt,其脚本实现如下,需要注意的事项如下:
- 通过外部传进来的参数和es文档中的参数进行匹配,当然也可以不传,那么可能返回0分数据,即随机数据
- 需要通过mapping获取es中的字段类型,如果是text文本类型需要通过.keyword来获取完整的字符串值,否则会进行分词,甚至报错
- 注意区分文档中的值和外部传进来的参数,不要将两个字段混淆
// 文档中的学历
def eduLevel = doc['eduLevel'].value;
// 文档中的居住城市
def liveCity = doc['liveCity.keyword'].value;
// 文档中的老家城市
def regCity = doc['regCity.keyword'].value;
// 文档中的身高
def height = doc['height'].value;
// 文档中的体重
def weight = doc['weight'].value;// 外部匹配用户传进来的生活城市
def paramLiveCity = params.liveCity;
// 外部匹配用户传进来的老家城市
def paramRegCity = params.regCity;
// 外部匹配用户传进来的身高
def paramHeight = params.height;
// 外部匹配用户传进来的体重
def paramWeight = params.weight;
// 外部匹配用户传进来的性别
def sex = params.sex;int score = 0;
// 同城分 同城异性优先
if(liveCity == paramLiveCity){score = score + 1200;
}
// 老家分
if(regCity == paramRegCity){score = score + 500;
}// 身高分
// 如果外部匹配用户是男性 那么比该外部用户低0-10cm的加分
// 如果外部匹配用户是女性 那么比该外部用户高0-10cm的加分
if(sex == 1 && paramHeight - 10L <= height && height <= paramHeight){// 如果外部用户是男性,那么需要找的女用户是 height=[paramHeight - 10L, paramHeight]score = score + 100;
}else if(sex == 0 && paramHeight <= height && height <= paramHeight + 10L){// 如果外部用户是女性,那么需要找的男用户是 height=[paramHeight, paramHeight + 10]score = score + 100;
}// 体重分
// 如果外部匹配用户是男性 那么需要找100-120的女性
// 如果外部匹配用户是女性 那么需要找120-140的男性
if(sex == 1 && weight >= 100L && weight <= 120L){// 如果外部用户是男性,那么需要找的女用户是 weight=[100, 120]score = score + 100;
}else if(sex == 0 && weight >= 120L && weight <= 140L){// 如果外部用户是女性,那么需要找的男用户是 weight=[120, 140]score = score + 100;
}// 学历分:eduLevel:3=大专以下,4=大专,5=大学本科,6=硕士,7=博士
if(eduLevel == 7){score = score + 200;
}else if (eduLevel == 6){score = score + 160;
}else if (eduLevel == 5){score = score + 120;
}else if (eduLevel == 4){score = score + 20;
}// 返回打分
return score;
根据这段脚本,那么最符合的优质用户返回的分数可能就是生活同城+老家同城+博士+身高符合+体重符合,那么累计分就是1200+500+100+100+200=2100分
3.2,java代码实现
首先是需要定义一个加载Es脚本的根据类,其EsScriptUtils类如下
/*** es加载脚本工具类* @Author zhenghuisheng* @Date 2025/11/09 17:01*/
public class EsScriptUtils {private static final Map<String, String> SCRIPT_CACHE = new ConcurrentHashMap<>();private static String getCacheScript(String name) {return SCRIPT_CACHE.computeIfAbsent(name, key -> {try {return IOUtils.toString(Objects.requireNonNull(EsScriptUtils.class.getResourceAsStream("/es_script/" + name)), StandardCharsets.UTF_8);} catch (IOException e) {e.printStackTrace();return null;}});}public static Script buildScript(String name, Map<String, Object> params) {String cacheScript = getCacheScript(name);return new Script(ScriptType.INLINE, Script.DEFAULT_SCRIPT_LANG, cacheScript, params);}
}
定义一个枚举ScriptNameConstant.ScriptName,用于记录脚本文件名称
public interface ScriptNameConstant {@Getterenum ScriptName implements ScriptNameConstant {USER_SCRIPT("user.txt", "优质用户匹配脚本");private final String name;private final String description;ScriptName(String name, String description) {this.name = name;this.description = description;}}
}
其代码service实现如下,这里面直接模拟一个用户,比如当前用户是男性,在北京市上班,老家是北京户口,要匹配优质用户 身高175 体重125,那么就会将这个参数传进脚本中作为匹配的参数
package com.zhs.elasticsearch.es.impl;import cn.hutool.json.JSONArray;
import cn.hutool.json.JSONObject;
import cn.hutool.json.JSONUtil;
import com.zhs.elasticsearch.basic.AjaxResult;
import com.zhs.elasticsearch.constant.ScriptNameConstant;
import com.zhs.elasticsearch.es.UserTermSearchService;
import com.zhs.elasticsearch.match.eo.UserEO;
import com.zhs.elasticsearch.util.EsScriptUtils;
import lombok.extern.slf4j.Slf4j;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.script.Script;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.springframework.stereotype.Service;import javax.annotation.Resource;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;/**** @Author zhenghuisheng* @Date:2025/6/26 11:40*/
@Service
@Slf4j
public class UserTermSearchServiceImpl implements UserTermSearchService {@Resourceprivate RestHighLevelClient restHighLevelClient;@Overridepublic AjaxResult scriptSearch() {// 比如当前用户是男性,在北京市上班,老家是北京户口,要匹配优质用户 身高175 体重125UserEO userEO = new UserEO();userEO.setLiveCity("北京市");userEO.setRegCity("北京市");userEO.setSex(1);userEO.setHeight(175);userEO.setWeight(125);// 传给脚本内部的参数Map<String, Object> params = new HashMap<>();// 当前用户信息params.put("liveCity", userEO.getLiveCity());params.put("regCity", userEO.getRegCity());params.put("height", userEO.getHeight());params.put("weight", userEO.getWeight());params.put("sex", userEO.getSex());// 构建基本查询BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();// 因为当前用户是男性,那么匹配的用户一定得是异性boolQueryBuilder.filter(QueryBuilders.termQuery("sex", 0));// 用户必须没被注销或者删除boolQueryBuilder.filter(QueryBuilders.termQuery("delFlag", 0));// 年龄必须在+-10岁boolQueryBuilder.filter(QueryBuilders.rangeQuery("birthYear").gte(userEO.getBirthYear() - 10).lte(userEO.getBirthYear() + 10));// 获取脚本内容Script script = EsScriptUtils.buildScript(ScriptNameConstant.ScriptName.USER_SCRIPT.getName(), params);// script_score 查询SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();sourceBuilder.size(10);sourceBuilder.query(QueryBuilders.scriptScoreQuery(boolQueryBuilder, script));log.info("构建script条件为:{}", sourceBuilder);// 3. 构建请求SearchRequest searchRequest = new SearchRequest("user");searchRequest.source(sourceBuilder);List<UserEO> userMatchList = new ArrayList<>();try {SearchResponse response = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);SearchHit[] hits = response.getHits().getHits();log.info("匹配返回条数:{}", hits.length);userMatchList = convertToUserEoList(hits);} catch (Exception e) {log.error("matchSearch error:", e);}return AjaxResult.success(userMatchList);}public List<UserEO> convertToUserEoList(SearchHit[] hits) {if (hits.length == 0) {return new ArrayList<>();}JSONArray jsonArray = new JSONArray();for (SearchHit hit : hits) {JSONObject jsonObject = JSONUtil.parseObj(hit.getSourceAsMap());jsonArray.add(jsonObject);}return JSONUtil.toList(jsonArray, UserEO.class);}
}
并且需要过滤掉异性,当然其他被删,黑名单等等条件这里暂时不考虑,因此只需要找和上面那个异性的用户,即女性即可。
boolQueryBuilder.filter(QueryBuilders.termQuery("sex", 0));
在执行完成看结果,此时结果返回成功,其图片如下
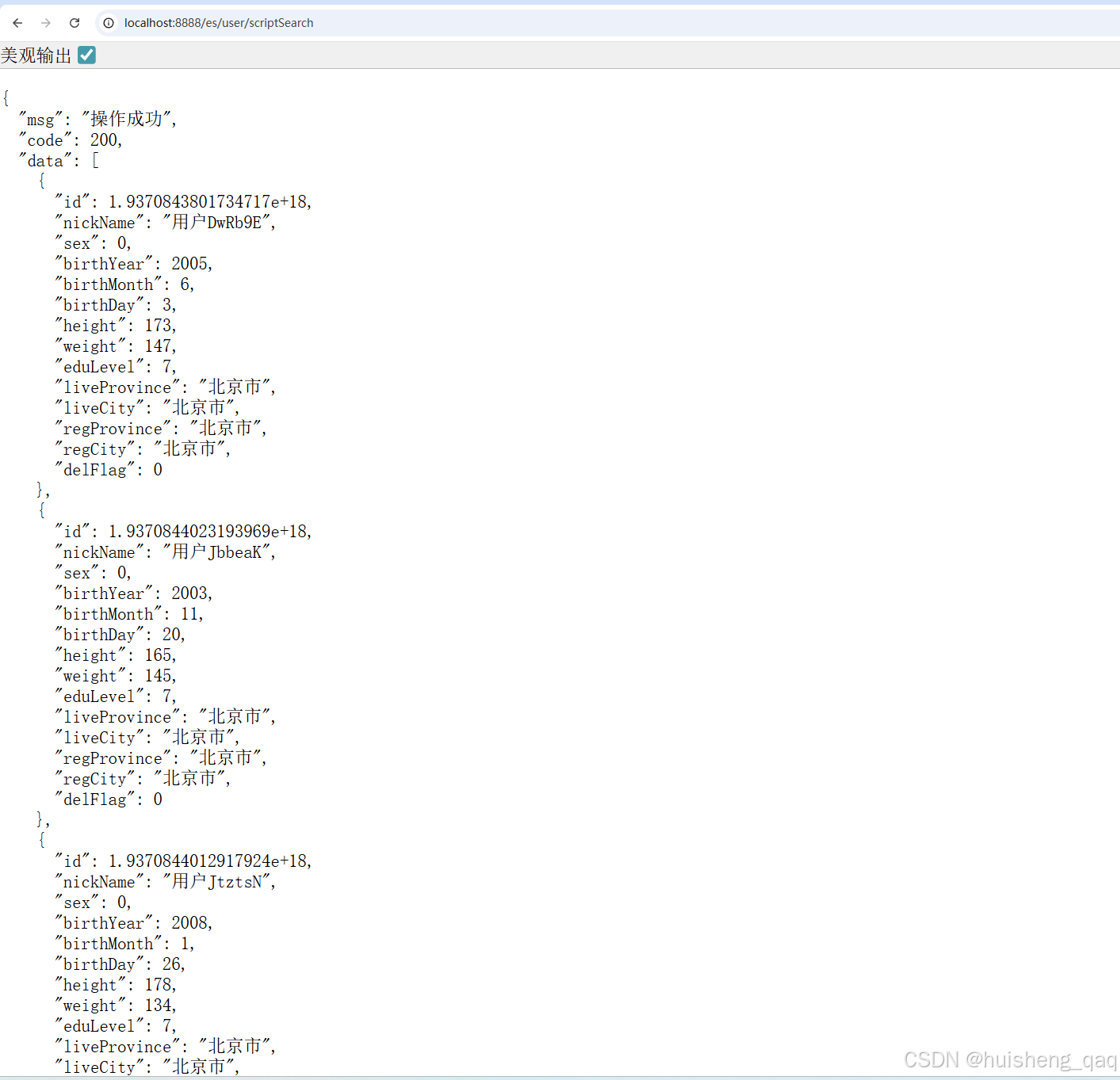
3.3,kibana执行
在上面执行代码中,打印了一个日志sourceBuilder,那么可以在日志中去拿这个sourceBuilder,可以直接在kibana上执行
log.info("构建script条件为:{}", sourceBuilder);
日志内容如下
{"size": 10,"query": {"script_score": {"query": {"bool": {"filter": [{"term": {"sex": {"value": 0,"boost": 1.0}}}],"adjust_pure_negative": true,"boost": 1.0}},"script": {"source": "// 文档中的学历\r\ndef eduLevel = doc['eduLevel'].value;\r\n// 文档中的居住城市\r\ndef liveCity = doc['liveCity.keyword'].value;\r\n// 文档中的老家城市\r\ndef regCity = doc['regCity.keyword'].value;\r\n// 文档中的身高\r\ndef height = doc['height'].value;\r\n// 文档中的体重\r\ndef weight = doc['weight'].value;\r\n\r\n// 外部匹配用户传进来的生活城市\r\ndef paramLiveCity = params.liveCity;\r\n// 外部匹配用户传进来的老家城市\r\ndef paramRegCity = params.regCity;\r\n// 外部匹配用户传进来的身高\r\ndef paramHeight = params.height;\r\n// 外部匹配用户传进来的体重\r\ndef paramWeight = params.weight;\r\n// 外部匹配用户传进来的性别\r\ndef sex = params.sex;\r\n\r\nint score = 0;\r\n// 同城分 同城异性优先\r\nif(liveCity == paramLiveCity){\r\n score = score + 1200;\r\n}\r\n// 老家分\r\nif(regCity == paramRegCity){\r\n score = score + 500;\r\n}\r\n\r\n// 身高分\r\n// 如果外部匹配用户是男性 那么比该外部用户低0-10cm的加分\r\n// 如果外部匹配用户是女性 那么比该外部用户高0-10cm的加分\r\nif(sex == 1 && paramHeight - 10L <= height && height <= paramHeight){\r\n // 如果外部用户是男性,那么需要找的女用户是 height=[paramHeight - 10L, paramHeight]\r\n score = score + 100;\r\n}else if(sex == 0 && paramHeight <= height && height <= paramHeight + 10L){\r\n // 如果外部用户是女性,那么需要找的男用户是 height=[paramHeight, paramHeight + 10]\r\n score = score + 100;\r\n}\r\n\r\n// 体重分\r\n// 如果外部匹配用户是男性 那么需要找100-120的女性\r\n// 如果外部匹配用户是女性 那么需要找120-140的男性\r\nif(sex == 1 && weight >= 100L && weight <= 120L){\r\n // 如果外部用户是男性,那么需要找的女用户是 weight=[100, 120]\r\n score = score + 100;\r\n}else if(sex == 0 && 120L <= weight && weight <= 140L){\r\n // 如果外部用户是女性,那么需要找的男用户是 weight=[120, 140]\r\n score = score + 100;\r\n}\r\n\r\n// 学历分:eduLevel:3=大专以下,4=大专,5=大学本科,6=硕,7=博士\r\nif(eduLevel == 7){\r\n score = score + 200;\r\n}else if (eduLevel == 6){\r\n score = score + 160;\r\n}else if (eduLevel == 5){\r\n score = score + 120;\r\n}else if (eduLevel == 4){\r\n score = score + 20;\r\n}\r\n\r\n// 返回打分\r\nreturn score;\r\n\r\n","lang": "painless","params": {"regCity": "北京市","liveCity": "北京市","height": 175,"weight": 125,"sex": 1}},"boost": 1.0}}
}
那么直接将脚本在kibana上执行,执行结果如下,和接口返回的用户数据是一样的
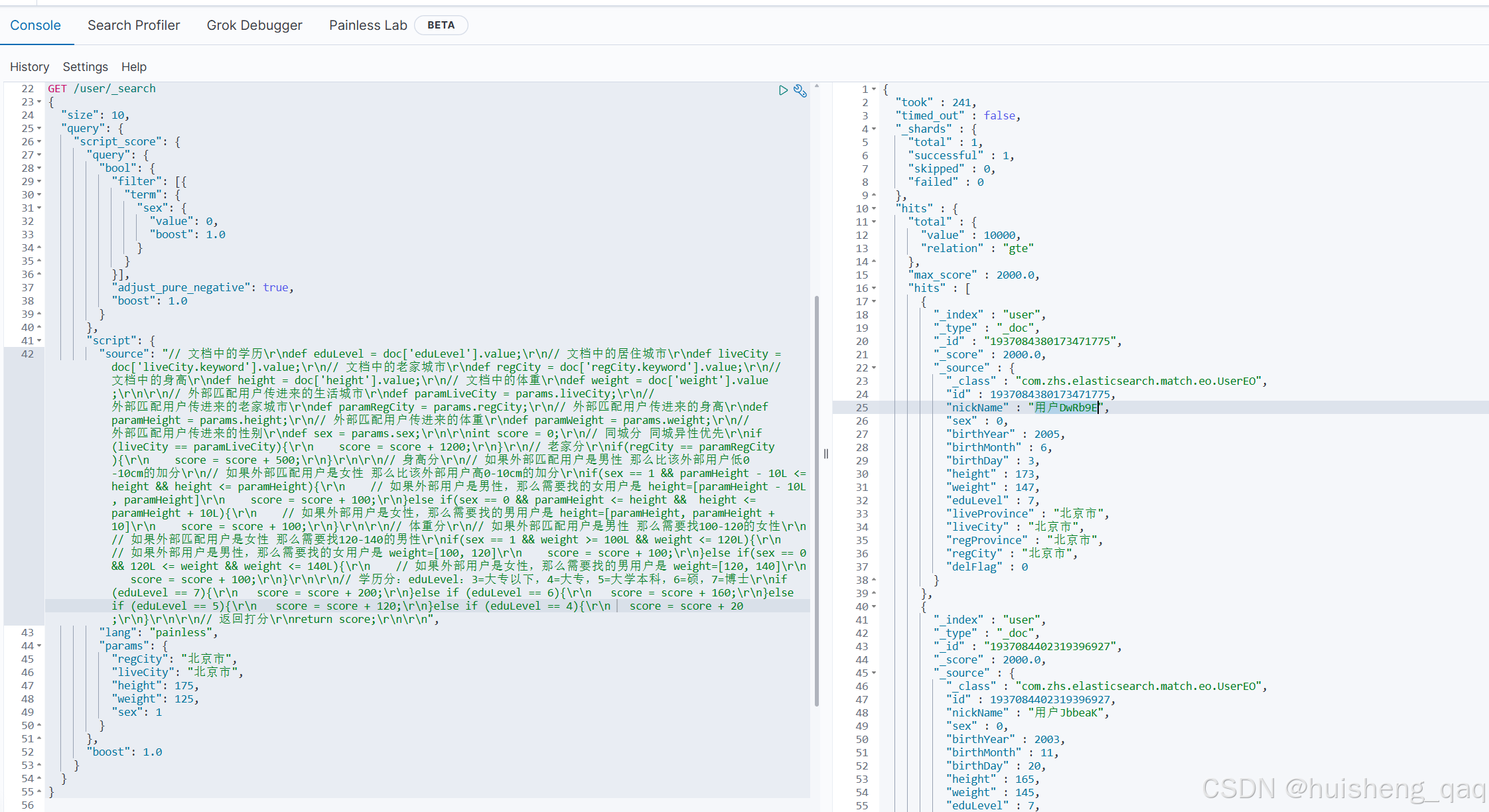
3.4,数据验证
那么再次看一下分数,最高分是1900分,在查一下这个用户的信息,看一下是不是符合我们这个需求
以这个第一名nickName为用户DwRb9E为例,接下单独的分析一下他的用户信息
GET /user/_search
{"query": {"term": {"nickName.keyword": "用户DwRb9E"}}
}
返回结果如下,首先居住城市和老家都是北京市,然后学历是博士,身高173,体重147,那么只有体重不符合,其他的都符合,那么总分就是1200+500+200+100=2000,那么打分也符合
{"_index": "user","_type": "_doc","_id": "1937084380173471775","_source": {"_class": "com.zhs.elasticsearch.match.eo.UserEO","id": 1937084380173471775,"nickName": "用户DwRb9E","sex": 0,"birthYear": 2005,"birthMonth": 6,"birthDay": 3,"height": 173,"weight": 147,"eduLevel": 7,"liveProvince": "北京市","liveCity": "北京市","regProvince": "北京市","regCity": "北京市","delFlag": 0}
}
4,总结
通过脚本打分的方式查询es,可以将很多代码难以实现的逻辑在脚本中实现,比如有更复杂的一些计算,根据条件给一些惩罚系数分等等,都可以通过脚本的方式去实现