Linux多线程(一):线程概念
文章目录
- 线程概念
- 何为线程?
- 理解线程
- 重新理解进程
- 重谈进程地址空间(四)
- 深入理解页表
- 线程的优点
- 线程的缺点
- 线程异常
- 线程的用途
- 进程VS线程
- 线程独立的数据
- 进程的多个线程共享
- 进程和线程的关系
- 线程为什么比进程更轻量化?
- 为什么切换进程比切换线程开销大得多?
线程概念
对于线程,很多教材给出了这样的概念:
线程是进程内的一个执行分支。线程的执行粒度比进程要细。
对于初学者,可能对这个概念并不理解。
本文,我将从内核的角度解释线程,探究线程的本质。
何为线程?
- 在一个程序里的一个执行路线(执行流)就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”
- 一切进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行
- 透过进程地址空间,可以看到进程的大部分资源,将进程资源合理分配给每一个执行流,就形成了线程执行流。
理解线程
线程与进程有着密切关系,因此我们先站在进程的角度去理解线程。
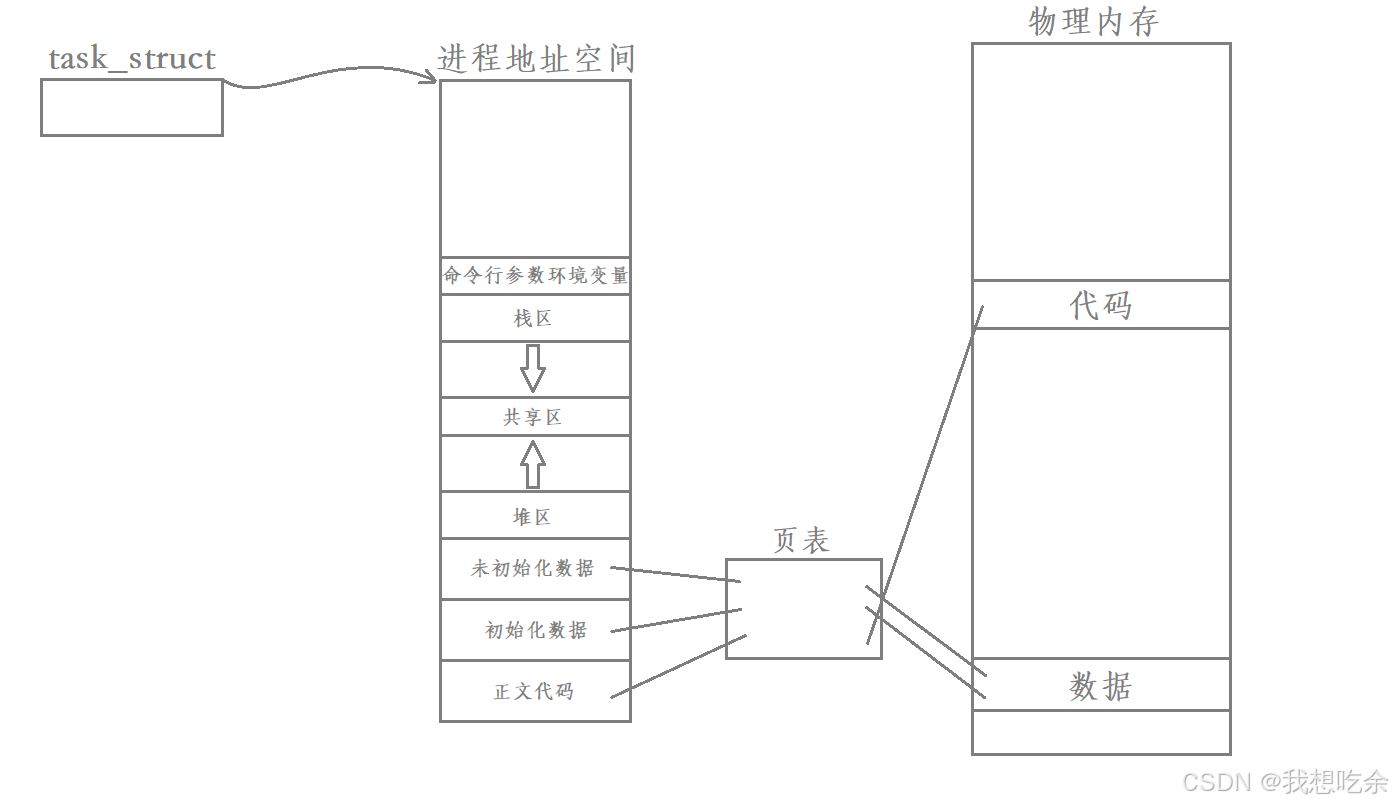
进程:程序运行起来,相关的代码和数据会被load到内存当中,然后操作系统会为其创建对应的PCB、进程地址空间、页表、分配对应资源等等,并通过页表建立好映射关系。
当我们需要多执行流执行我们的任务时,以前我们只能通过多进程来完成(fork创建子进程),然而实际情况下通常需要上千个执行流,也就需要上千个进程,这不是危言耸听,看下图:
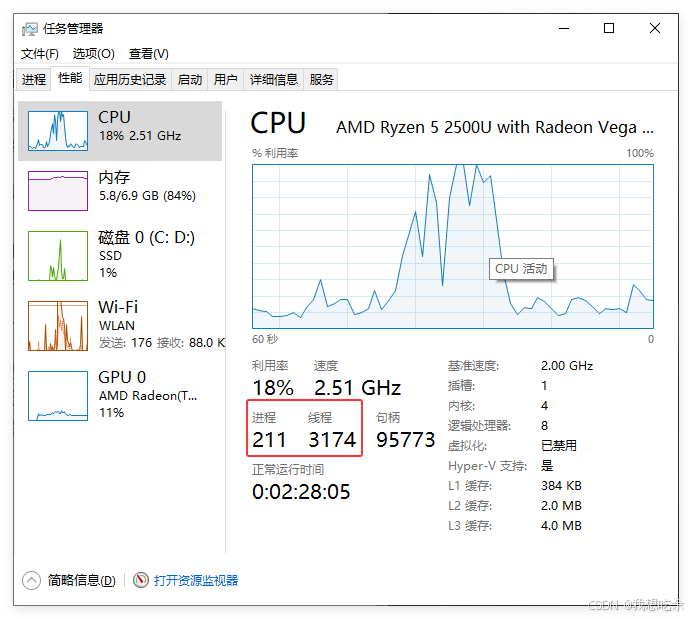
这是我的电脑当前的状态,一个线程可以代表一个执行流。
想象一下:如果只有进程的概念,并且同时存在几千个进程,那么操作系统调度就会变得十分臃肿
因为操作系统在调度进程时,需要频繁的保存上下文数据、创建的虚拟地址以及建立映射关系。
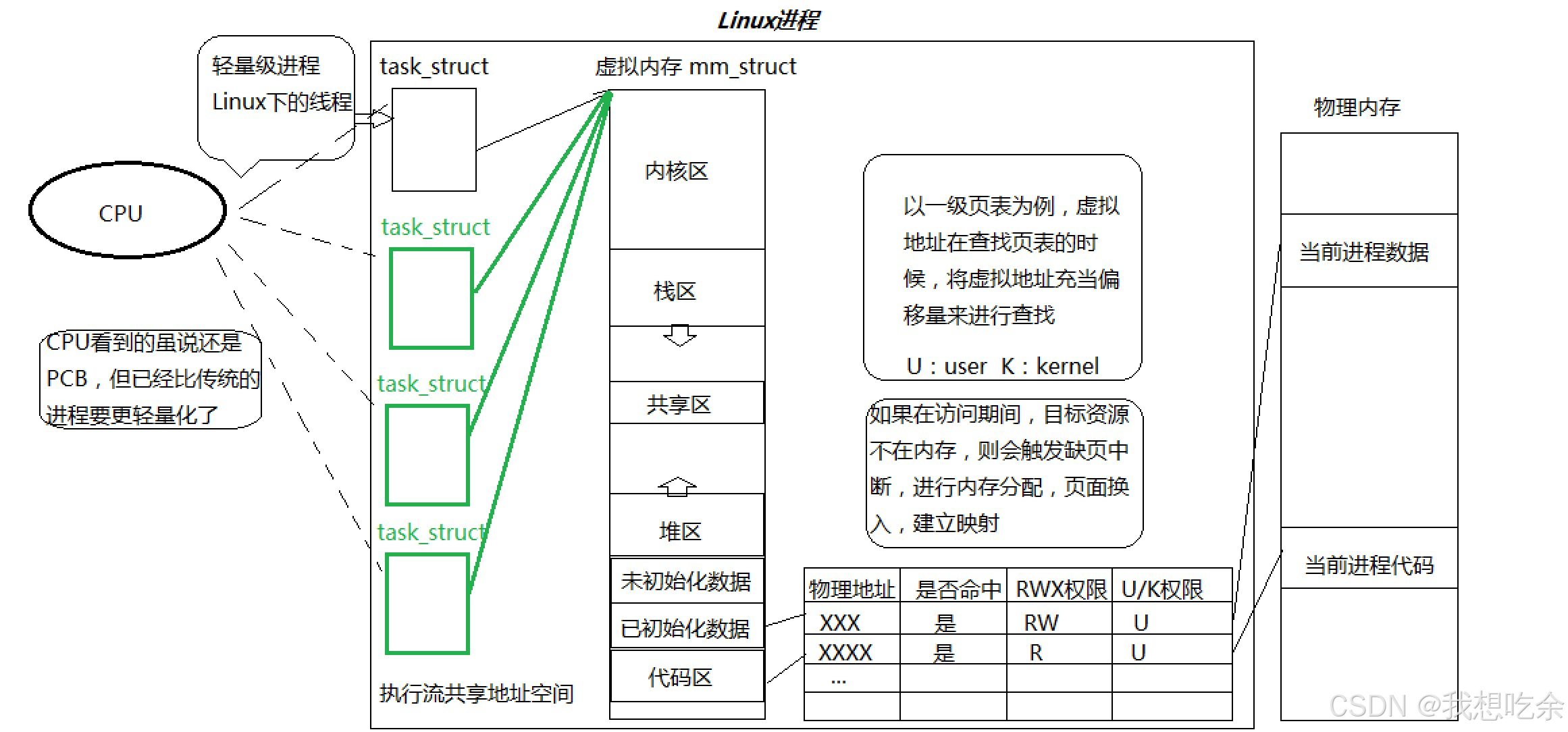
所以操作系统引入了线程的概念,所谓线程:在进程中额外创建一个task_struct结构,该task_struct同样指向该进程的虚拟地址空间,并且使用同一张页表。
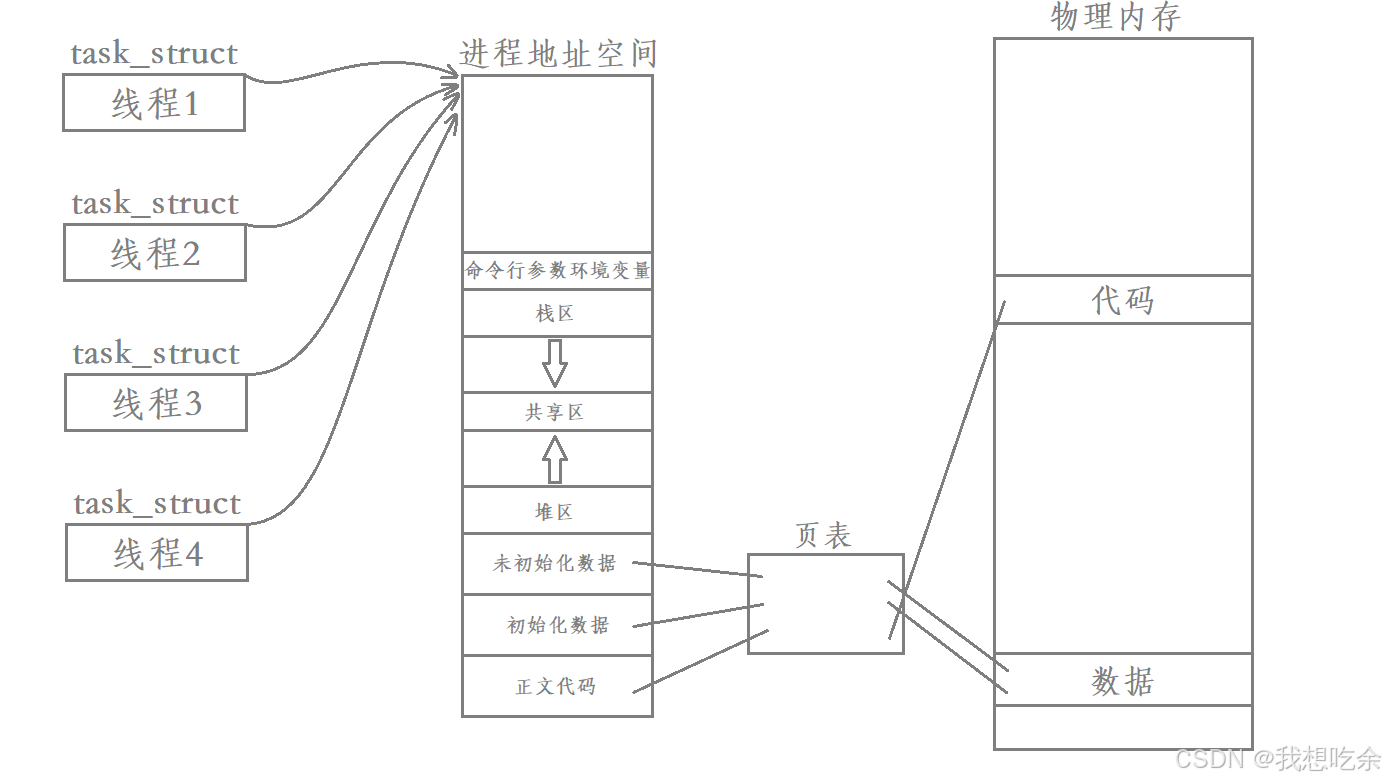
现在我们可以看清进程地址空间的一个本质作用了:进程的资源窗口
如此,操作系统只需要针对一个task_struct结构来完成调度,非常高效。
因此,站在内核角度来理解线程:线程是操作系统调度的基本单位。
重新理解进程
什么?一个进程有多个task_struct?那岂不是一个进程有多个PCB???这样我们以前学的进程概念是啥?OS不是对进程进行管理了吗?不是一个PCB对应一个进程?这不是逻辑大冲突了吗?……😵
不必担心,过去我们学的都是对的。
其实,进程并不是通过task_struct来衡量的,除了task_struct之外,一个进程还要有进程地址空间、文件、信号等等,合起来称之为一个进程。
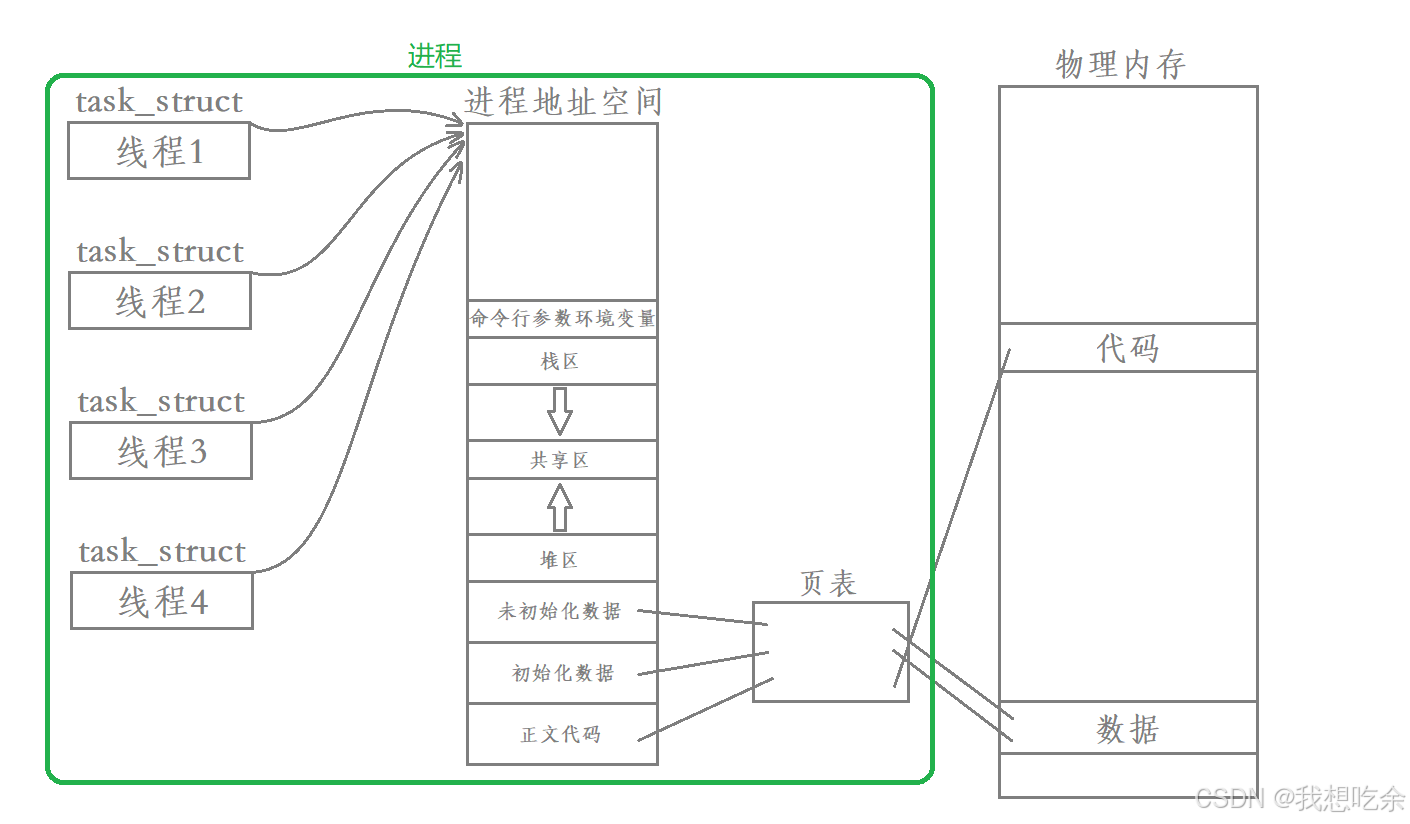
现在我们应该站在内核角度来理解进程:承担分配系统资源的基本实体,叫做进程。
从本质出发,执行流也属于资源
所有的线程就是进程内部的执行流资源,这个资源是由进程来分配的!
那进程的PCB是什么?
主线程的task_struct就是进程的PCB
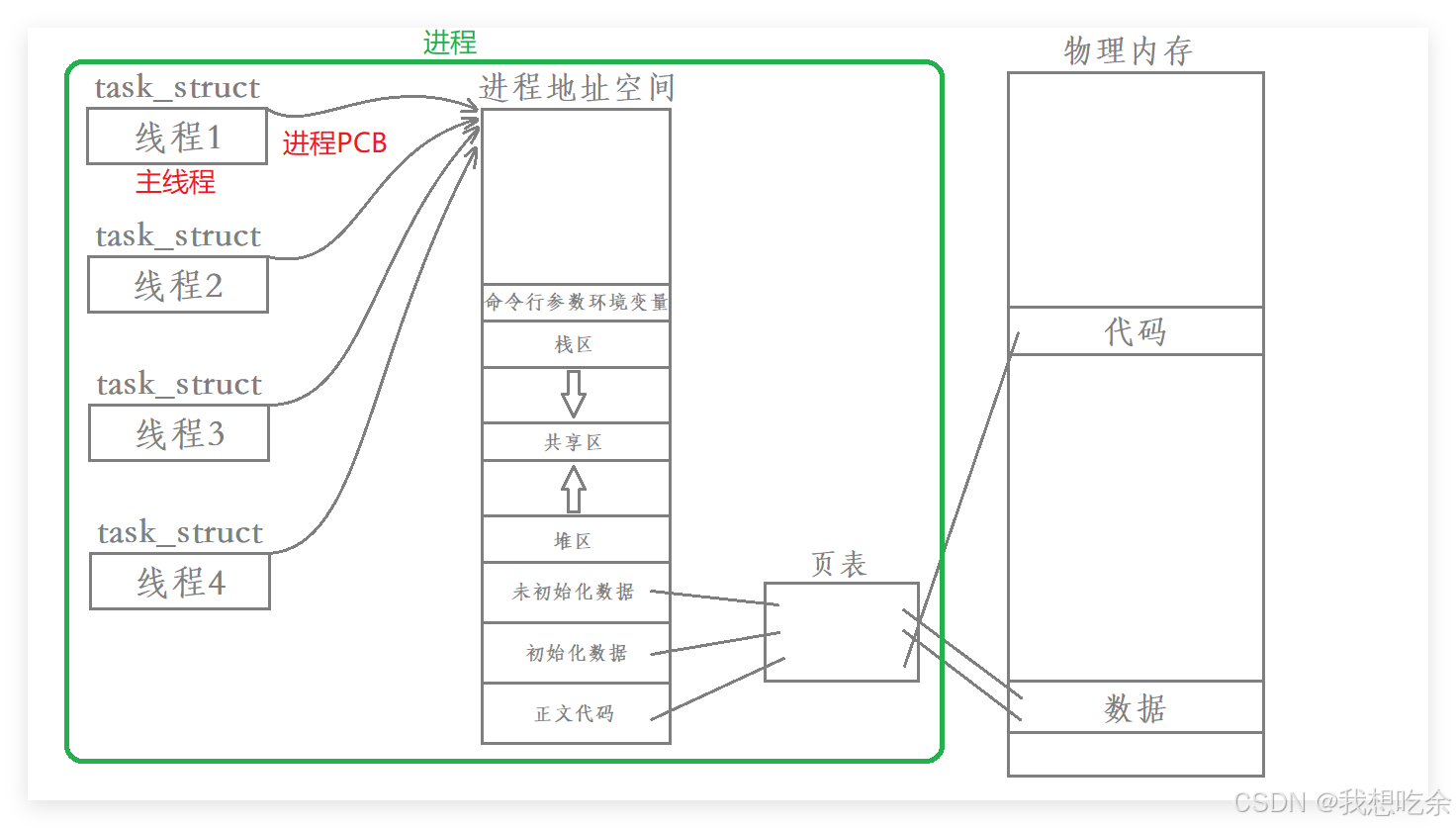
其他线程的task_struct,我们称为TCB(Thread Control Block)
过去的Linux进程概念:进程 = 内核数据结构(task_struct) + 代码和数据
现在再看来,显然是正确的,逻辑自洽。
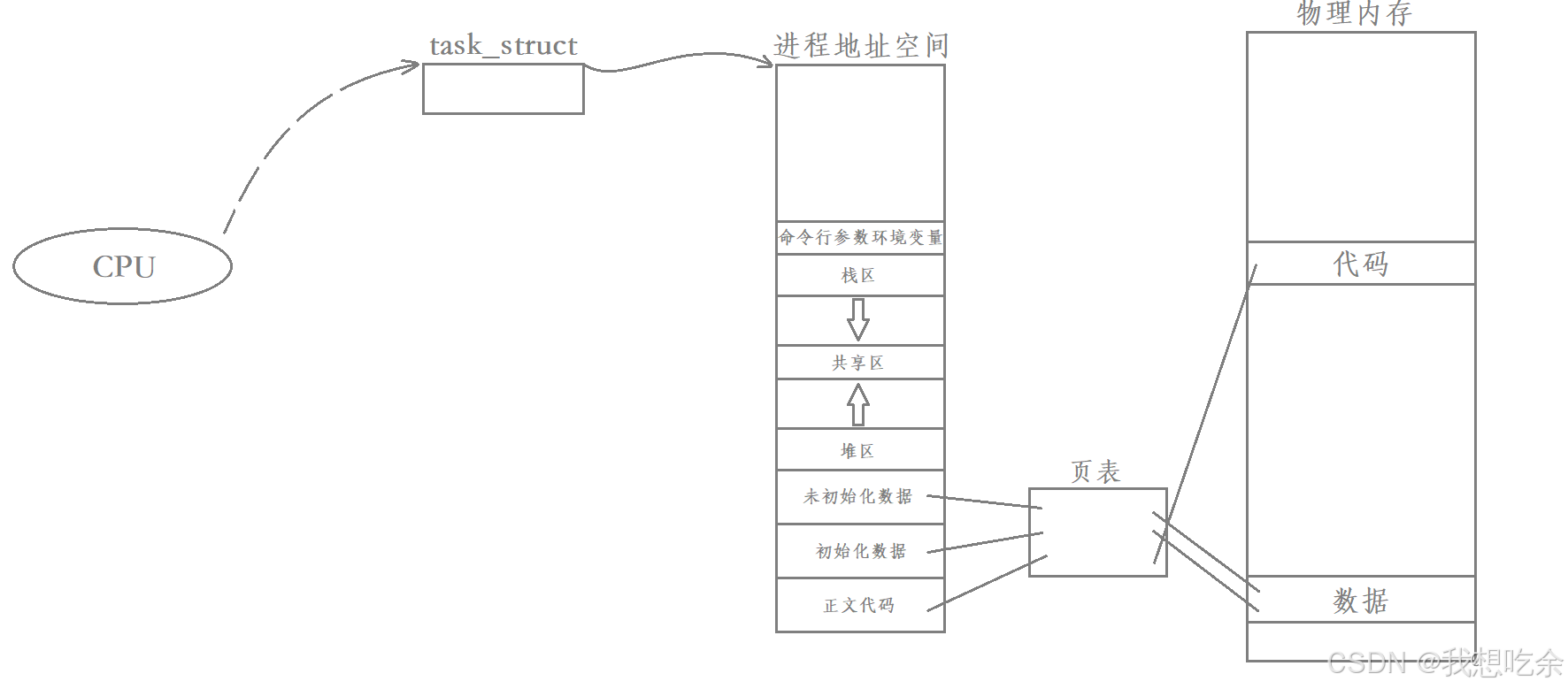
以CPU的视角,需不需要识别当前调度的task_struct是进程还是线程?
答案是不需要,因为CPU只需要关心一个一个的独立执行流,无论进程内部是一个执行流还是多个执行流,CPU都是以task_struct为单位进行调度的。
单执行流进程被调度:
多执行流进程被调度:
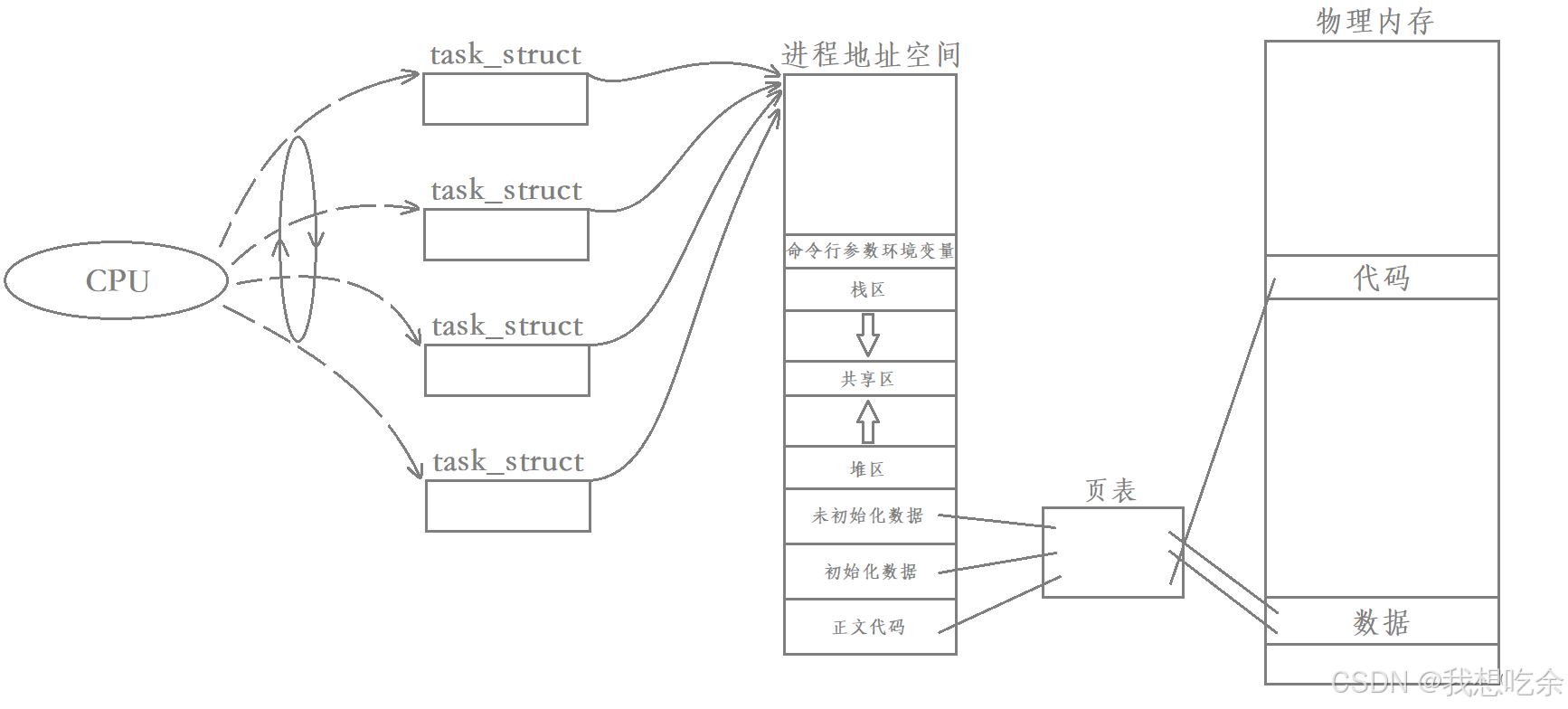
注:CPU看到的虽说还是task_struct,但已经比传统的进程要更轻量化了。
Linux没有真正意义上的线程,而是用“进程(内核数据结构)”去模拟的线程
如果OS中存在大量真的线程,OS势必要对所有线程进行统一的管理。比如说创建线程、终止线程、调度线程、切换线程、给线程分配资源、释放资源以及回收资源等等,所有的这一套相比较进程都需要另起炉灶,搭建一套与进程平行的线程管理模块。
很明显,线程的管理模块与进程的管理模块必然是高度雷同的,因此Linux的设计者并没有真正的去实现一个线程管理模块,而是复用进程管理模块的数据结构和管理算法,用task_struct结构体模拟线程。
在这种设计思想下,线程注定不会过于庞大,因此 Linux 中的线程又可以称为轻量级进程(LWP),轻量级进程 足够简单,且易于维护、效率更高、安全性更强,可以使得Linux系统不间断的运行程序,不会轻易崩溃。这是Linux成为一款卓越的操作系统的关键。
不同操作系统采用方案不同,比如 Windows 使用的是真线程方案,为 TCB 额外设计了一逻辑,这就导致操作系统在同时面临 PCB 和 TCB 时需要进行识别后切换成不同的处理手段,存在不同的逻辑容易增加系统运行不稳定的风险,这就导致 Windows 无法做到长时间运行,需要通过重启来重置风险。
重谈进程地址空间(四)
这是第四次谈进程地址空间:
- 一谈:Linux进程概念(下):进程地址空间
- 二谈:Linux进程地址空间二谈:动态库加载原理揭秘
- 三谈:Linux信号(下):信号保存和信号处理
深入理解页表
以32位平台为例,在32位平台下一共有2322^{32}232个地址,也就意味着有2322^{32}232个地址需要被映射。
假设我们的页表只是单纯的一张表,那么这张表就需要建立2322^{32}232个虚拟地址和物理地址之间的映射关系,即这张表一共有2322^{32}232个映射表项。
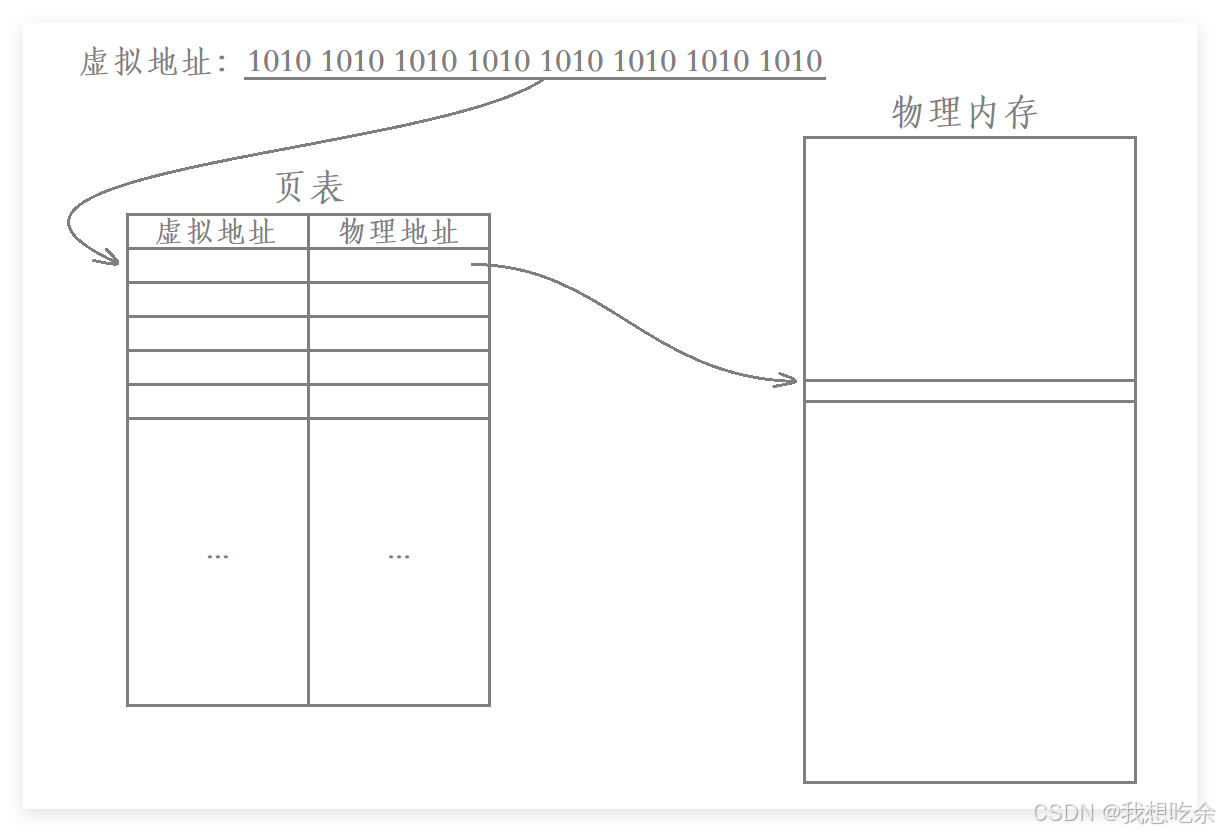
每一个表项中除了要有虚拟地址和与其映射的物理地址以外,实际还需要有一些权限相关的信息
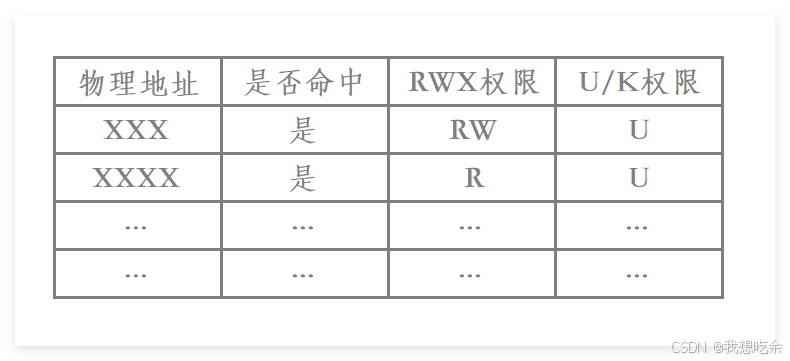
每一个表项除了存储一个物理地址和一个虚拟地址,还要存储一些其他权限相关的信息,一个表项的大小为4字节,我们来粗略计算一下页表的大小:232∗42^{32}*4232∗4个字节,大概要16GB,而现在大多数的计算机内存才16GB,更何况几十年前,也就是说我们根本无法存储这样的一张页表。
因此,页表并不是一个单纯的表。
通常,页表是采用多级页表的方式映射的。
以32位平台为例:
- 选择虚拟地址的前10个比特位在页目录中进行查找,找到对应的二级页表
- 再选择虚拟地址的前10个比特位后面的10个比特位在对应的二级页表中查找,找到物理内存中对应的页框的起始地址
- 最后将虚拟地址中剩下的12个比特位作为偏移量从对应页框的起始地址向后进行偏移,找到物理内存中的某一个对应的字节数据。
也就是说:页框起始地址+虚拟地址后12位 = 物理地址
相关说明:
4. 物理内存实际是被划分为一个一个4kb大小的页框的,磁盘上的程序也是被划分成一个个4KB大小的页帧的,当内存和磁盘进行数据交换时也就是以4KB大小为单位进行加载和保存的。
5. 4kb实际上就是2122^{12}212个字节,也就是说一个页框中有2122^{12}212个字节,而访问内存的基本大小是1字节,因此一个页框中就会有2122^{12}212个地址,因此我们恰好就可以将剩下的12个比特位当做偏移量,从页框的起始地址开始向后偏移,找到物理内存中某一个对应字节的数据
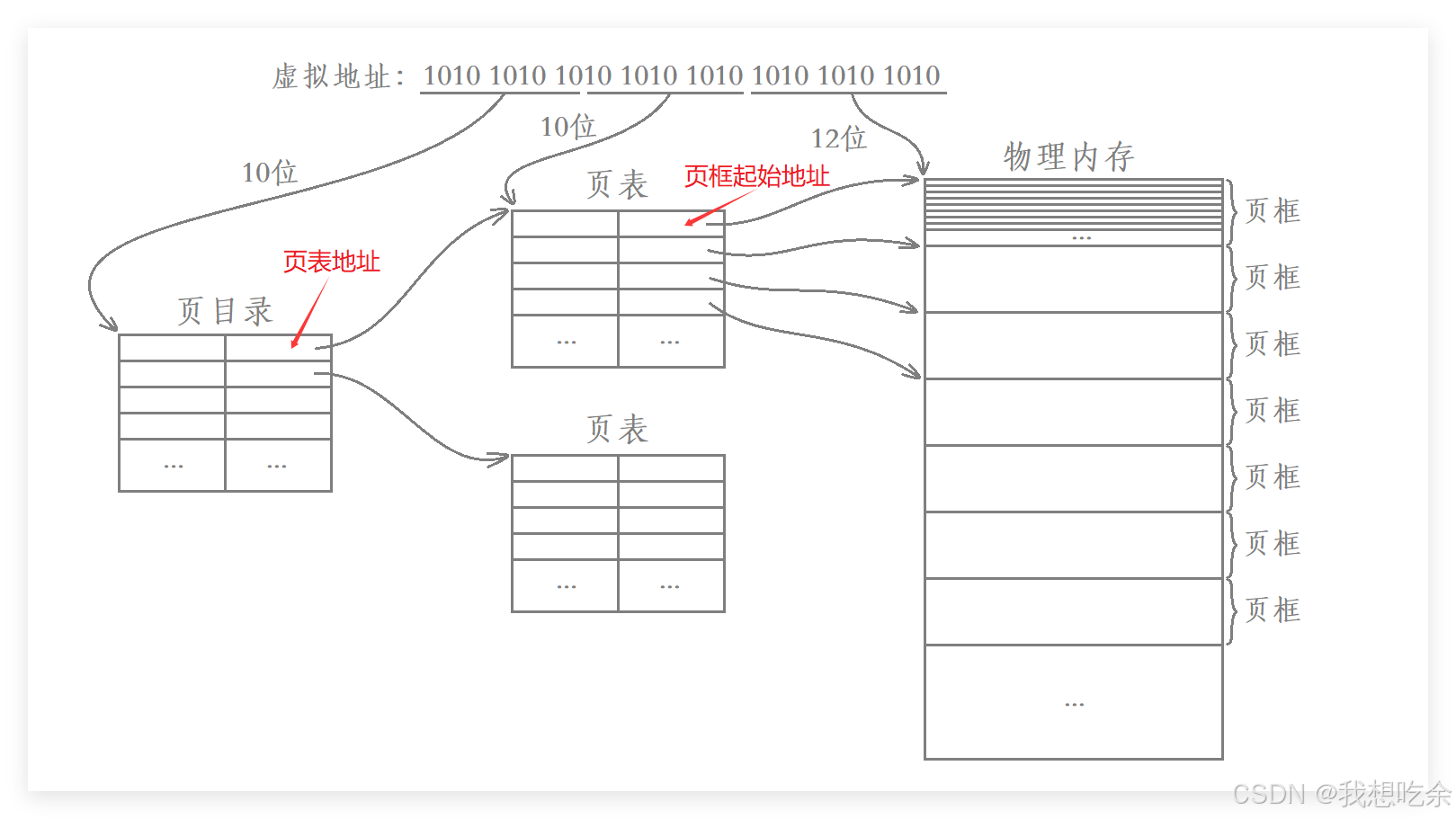
这实际上就是我们所谓的二级页表,其中页目录项是一级页表,页表项是二级页表。
现在,我们再来粗略计算一下页表的大小:
每一个表项大小为4字节,页目录的表项有2102^{10}210个,也就是说有2102^{10}210个二级页表,1个一级页表,页表总大小为:(210∗210+1)∗4(2^{10}*2^{10} + 1)*4(210∗210+1)∗4,约等于4MB。
内存消耗并不高,是可以接受的大小。
上面所说的所有映射过程,都是由MMU(MemoryManagementUnit)这个硬件完成的,该硬件是集成在CPU内的。页表是一种软件映射,MMU是一种硬件映射,所以计算机进行虚拟地址到物理地址的转化采用的是软硬件结合的方式。
像这种页框起始地址+偏移量的方式被称为基地址+偏移量,是一种运用十分广泛的思想,比如所谓的类型(int、double、char……)也是通过变量起始地址+类型的大小来标识一个变量大小的,也就是说我只需要获得变量的起始地址即可自由进行偏移操作(如果便宜过度了,就是越界),这也就解释了为什么取地址只会取到起始地址的现象。
线程的优点
- 创建一个新线程要比创建一个新进程小得多。
- 与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多。
- 线程占用的资源要比进程少得多。
- 能充分利用多处理器的可并行数量。
- 在等待慢速IO操作结束的同时,程序可执行其他的计算任务(比如看剧软件的边看边下)
- 计算密集型应用,为了能在多处理器系统上云霄,将计算分解到多个线程中实现
- IO密集型应用,为了提高性能没见过IO操作重叠,线程可以同时等待不同的IO操作
说明一下
- 计算密集型:执行流的大部分任务,主要以计算为主。比如加密解密、大数据查找等
- IO密集型:执行流的大部分任务,主要以IO为主。比如刷磁盘、访问数据库、访问网络等。
线程的缺点
- 性能损失:一个很少被外部事件阻塞的计算密集型线程往往无法与其他线程共享一个处理器,如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是添加了额外的同步和调度开销,而可用资源不变。
- 健壮度降低:编写多线程需要更全面更深入的考虑,在一个多线程程序中,因时间分配上的细微偏差或因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说,线程之间是缺乏保护的。
- 缺乏访问控制:进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
- 编程的难度提高:编写与调试一个多线程程序比单线程程序困难得多。
线程异常
一个线程如果出现除零、野指针等类似问题导致线程崩溃,进程也会随之崩溃。
因为线程是进程的执行分支,线程出异常,就类似进程出异常,进而触发信号机制,终止进程,进程终止,该进程内的所有线程也就随即退出。
线程的用途
- 合理的使用多线程,能提高CPU密集型程序的执行效率
- 合理的使用多线程,能提高IO密集型程序的用户体验(如生活中我们一边写代码一边下载开发工具,就是多线程运行的一种表现)
进程VS线程
进程是资源分配的基本单位,线程是调度的基本单位。
线程独立的数据
线程与进程共享很多数据,但也拥有自己的一部分数据:
- 线程的上下文(牢记)
- 独立的栈空间(牢记)
- 线程ID
- 一组寄存器
- errno
- 信号屏蔽字(block表)
- 调度优先级
进程的多个线程共享
因为是在同一个地址空间,因此所谓的代码段(Text Segment)、数据段(Data Segment)都是共享的:
- 如果定义一个函数,在各个线程都可以调用。
- 如果定义一个全局变量,在各个线程都可以访问到。
另外,各个线程还共享一下进程资源和环境:
- 文件描述符表:一个线程打开一个文件后,其他线程也可以看到
- 每种信号的处理方式: SIG_IGN、SIG_DFL或者自定义的信号处理函数
- 当前工作目录:cwd
- 用户ID和组ID
进程和线程的关系
关系如图:
过去我们接触到的都是具有一个线程执行流的进程,即单线程进程。
线程为什么比进程更轻量化?
主要有两个原因:
- 线程的创建和释放更加轻量化
- 线程切换更加轻量化
线程的创建和释放无需多言,创建只需新建一个task_struct即可,而进程创建不仅要创建PCB还要建立虚拟地址空间和页表等等,释放也是同理。
为什么切换进程比切换线程开销大得多?
CPU内部包括:运算器、控制器、寄存器、MMU、硬件及缓存(cache)等等,其中cache又称为高速缓存,它遵循计算机的局部性原理,会预加载部分用户可能访问的数据,以提高CPU效率。
可以看到catch中的数据还是挺大的(不同CPU的cache的大小可能有差异),所以要缓存一次cache代价并不小,这个数据被称为缓存的热数据。
- 对于线程的切换,不需要重新缓存cache数据
- 对于进程的切换,需要重新缓存cache数据
原因很简单,因为进程的独立性,你进程不可能直接去访问其他进程的数据。
因此线程切换的开销比进程切换小。