技能补全之Python AES GCM 加密存储
Python AES GCM 加密存储
- 〇、前言
- 一、加密算法的选型(AES GCM)
- 1、密码学的四大支柱
- 2、为何选择 AES
- 3、什么是 AES GCM
- 二、压缩算法的选型(GZIP)
- 1、背景
- 2、技术原理
- 3、常见的文本数据压缩算法
- 4、选择 GZIP
- 三、序列化方式的选型(protobuf)
- 1、何谓序列化
- 2、为什么要序列化
- 3、常见的序列化方式
- 4、选择 PB 序列化
- 四、编程实践(Python)
- 1、准备
- 1.1、定义 person.proto
- 1.2、编译生成 person_pb2.py 文件
- 2、实现业务功能
- 2.1、文件的写与读
- 2.2、gzip 压缩与解压
- 2.3、AES GCM 加解密
- 2.4、随机生成密钥
- 2.5、体验
〇、前言
在这个用户对个人隐私信息越发看重的时代,如何实现数据的加密存储,是应用服务端开发过程中所必须考虑的事情。一般而言,在服务端实现加密存储,需要考虑如下几种技术细节:
- 加密算法的选型
- 压缩算法的选型
- 序列化方式的选型
下面的内容,将围绕这三个方面进行叙述展开,并给出对应的实践案例代码。
一、加密算法的选型(AES GCM)
加密算法是否合适,影响着数据加密存储这一目的的完成度,选择不当则意味着目的没有达成、或者没有百分百达成。
作为数据存储使用的加密算法,必须具备双向过程,也就是既要能够将明文数据加密成密文数据,也要能够将密文数据还原为明文数据。说到这里,可能会有许多经验不多的开发者,会将 MD5 误以为是一种加密算法,实际上 MD5 只是一种编码方式,虽然是不可逆的编码方式,然而,近些年它的不安全性已经被技术证明了。
提一嘴 MD5,是为了告诫,告诫每一个开发者都不应该偷工减料,企图用编码算法去替代加密算法。言归正传,加密算法的选择,需要考虑算法本身是否具备足够的安全性能。
1、密码学的四大支柱
要判断一种加密算法是否具备足够的安全性能,需要从它的实现过程去判断。在众多加密算法的实现过程中,有一些处理步骤是共有的,而汇聚这些共有的步骤,就出现了如下表:
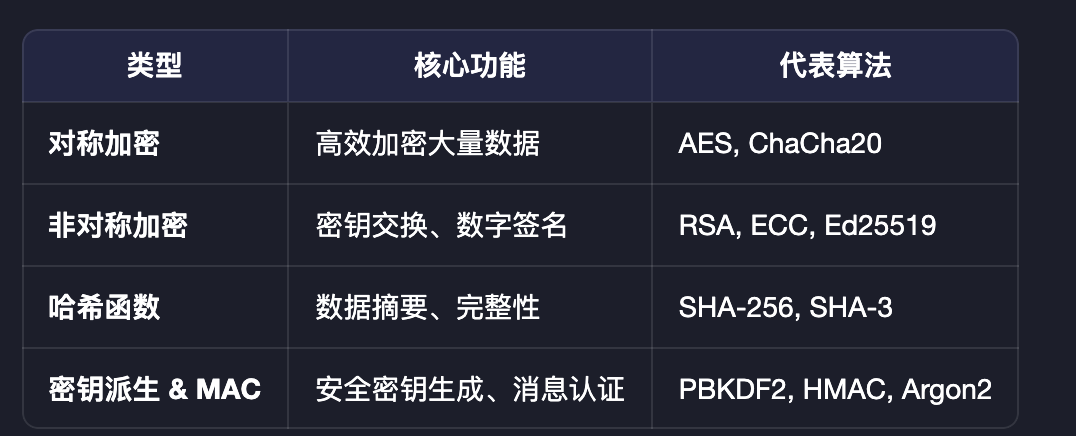
2、为何选择 AES
看了上面的表格,屏幕前的你应该不难理解本文案例为什么会选择 AES 算法,但为了避免思考的差异,我还是将我的选择依据给陈述一下。
首先,只用到哈希函数的加密算法,不适合用来加密数据,因为哈希可以通过撞库来破解。
其次,非对称加密算法,虽然在安全方面有足够的保障,但它存在着两个硬伤,使得它无法胜任数据加密场景。非对称加密有严格的铭文长度上限,通常由密钥决定。非对称加密算法基本上都是借助复杂的数学运算,如大数模幂、椭圆曲线点乘等,去实现加密过程的,而复杂的数学运算过程意味着计算开销的庞大、换言之就是算法性能极低,加密同等规模的数据,要比对称加密算法花费更多的时间。
最后,PBKDF2、HMAC 和 Argon2 等算法,之所以不能用来加密数据,是因为它们都违背了加密数据场景的原则需求:必须有可逆过程,也就是说,它们都像 MD5 一样都是单向的、不可逆的,数据被加密之后就再也无法还原为明文状态。
现在,屏幕前的你,应该彻底知道为什么选择用 AES 作为加密数据的目标算法了吧?
3、什么是 AES GCM
AES(Advanced Encryption Standard,高级加密标准)本质上是一类对称加密算法的统称,但它有非常明确和严格的定义。
AES 是由 美国国家标准与技术研究院(NIST) 在 2001 年 正式发布的联邦信息处理标准(FIPS PUB 197),用于替代老旧的 DES 算法。
- 它不是一个算法家族,而是一个具体的分组密码标准
- 基于 Rijndael 算法的一个子集
比利时密码学家 Joan Daemen 和 Vincent Rijmen 设计了 Rijndael 算法。
NIST 在其基础上选定了固定参数,命名为 AES。
AES 具有如下的具体规格:
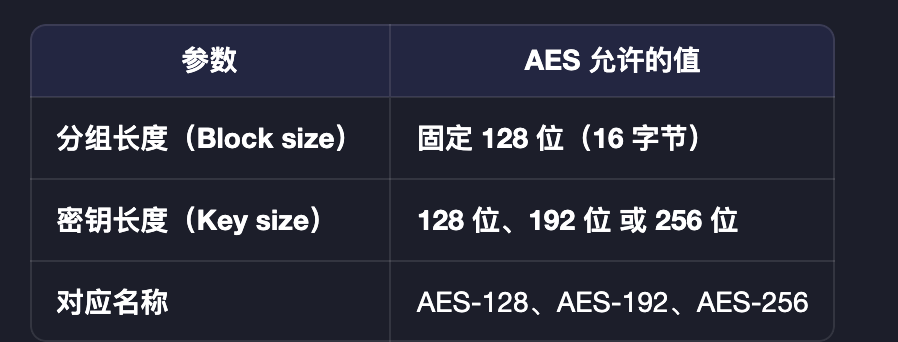
所有符合 FIPS-197 的实现都叫 AES,然而 AES 本身只是“分组密码”,需配合“工作模式”才能加密任意数据。AES 原生只能加密 恰好 16 字节(128 位) 的数据块。要加密长消息,必须使用分组密码工作模式(Mode of Operation),例如:
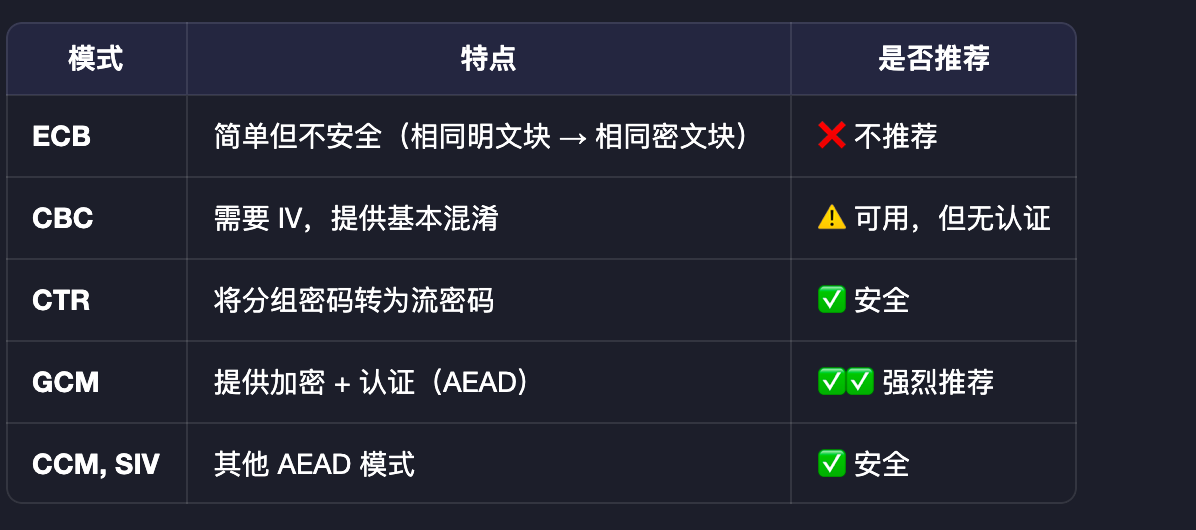
所以,AES GCM 的含义,就是:使用了 GCM 这种工作模式的 AES 算法
二、压缩算法的选型(GZIP)
在进行数据加密前,通常需要进行一次数据压缩操作,这是为什么呢?下面就为你解答疑惑。
1、背景
数据存储,需要将数据写入到外存如磁盘等掉电不丢数据的媒介中,才算完成了数据的持久化,而仅仅只是存在于内存中,是算不上做到数据的持久化,因为内存会随着断电而清空所有数据。
而磁盘的容量,通常都是有限的,磁盘被数据撑爆的一天是必然会出现的,如何延迟这一天的到来,是每个服务端开发者所必须考虑的事情。
2、技术原理
我们都知道,计算机的世界里只有 0 和 1,但是,你可能不知道的是,数据的基本存储单位,不是比特(bit),一个二进制位就是1比特,而是8比特长的字节(byte),于是,就会出现这种情况:虽然,数值 1 用一个比特就能表示,但是,为了符合基本存储单元的要求,不得不另外凑7个永远也用不上比特位。像这种情况,在计算机的数据存储场景中,比比皆是。
所以,当数据处理的视角,下沉到二进制位这一层次时,就会看到待处理的数据中,存在着大量的冗余空间,就像是一个个没有存放任何物品的仓库,这明显就是一种空间浪费。于是,为了尽可能地减少二进制位的冗余,数据压缩算法便应运而生了。
简单点,数据压缩的技术原理就是使用具备低冗余特性的编码,对原本的数据进行再次编码。
如何用一串 0 和 1 去表达数据,称之为编码。
3、常见的文本数据压缩算法
不考虑音视频等数据,只考虑文本数据,常见的数据压缩算法有:
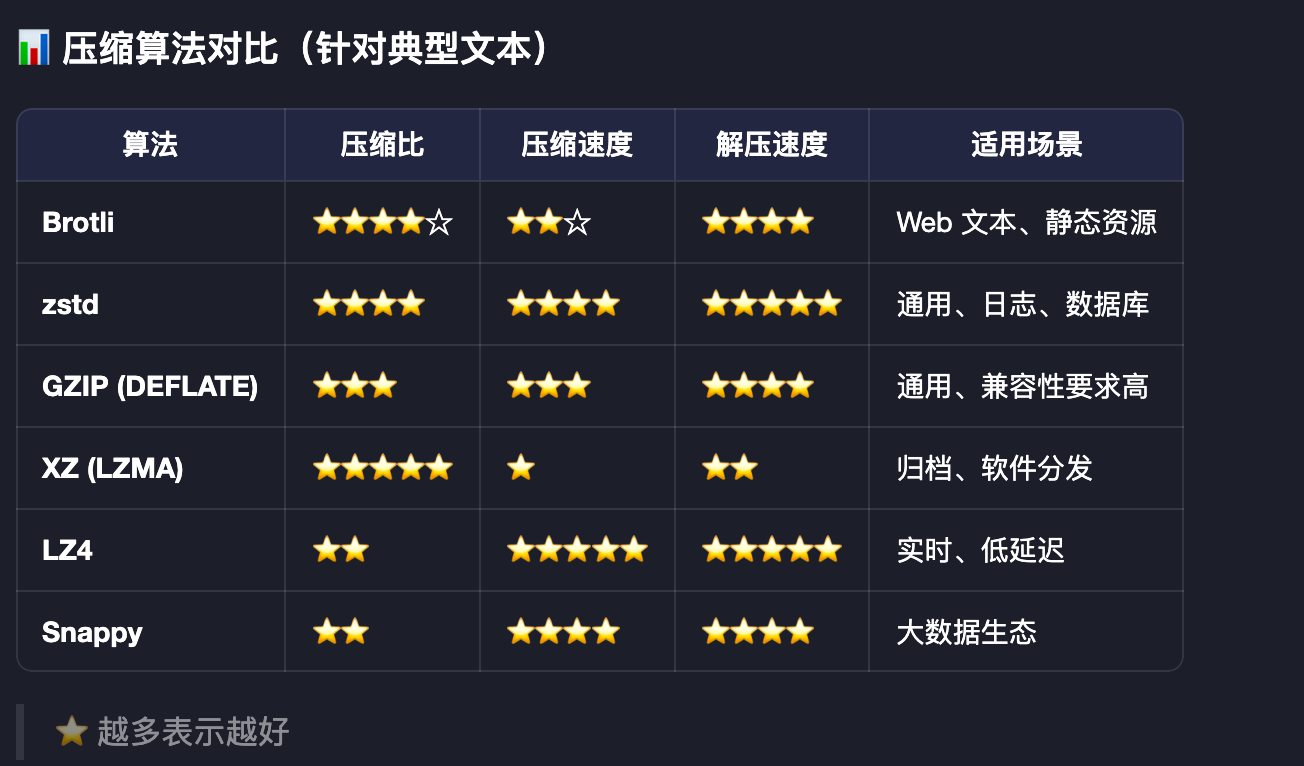
4、选择 GZIP
从上面的表格看,明显 Brotli 算法的得分更高,那么为什么不选择呢?这主要是因为序列化方式的选择,并且,gzip 算法具有极其优秀的兼容性,可以说是目前兼容性最好的通用无损压缩算法之一。这种广泛支持使其成为跨平台、跨语言、跨系统数据交换的“事实标准”。
服务端通常要面对来自不同系统平台的客户端的请求,兼容性一直是不可忽略的,所以,选择一个具备优秀的兼容性特点的 gzip 算法,也是理所当然的。
三、序列化方式的选型(protobuf)
1、何谓序列化
也许,序列化这一术语,屏幕前的你,已经听过无数次了,但是,你是否有深入了解过,何谓数据序列化?
数据序列化,指的是将内存中的数据结构或对象转换为一种可以存储(如写入文件)或传输(如通过网络发送)的格式的过程。
2、为什么要序列化
为了方便程序的运行,各种数据在计算机程序中,会被抽象成一个个具有特定结构的对象,而这些结构化的数据,可以在内存中存在,却无法直接写入外存文件中,想要将对象数据写入外存文件,就必须将其转换成一种能够写入到外存文件中的格式,比如字符串或者字节码。
在数据加密存储场景中,字节码通常更适合作为序列化后的数据格式。
3、常见的序列化方式
按照序列化后的表现形式来划分,所有序列化方式可以分为文本型序列化和二进制型序列化。
常见的文本型序列化,有如下:
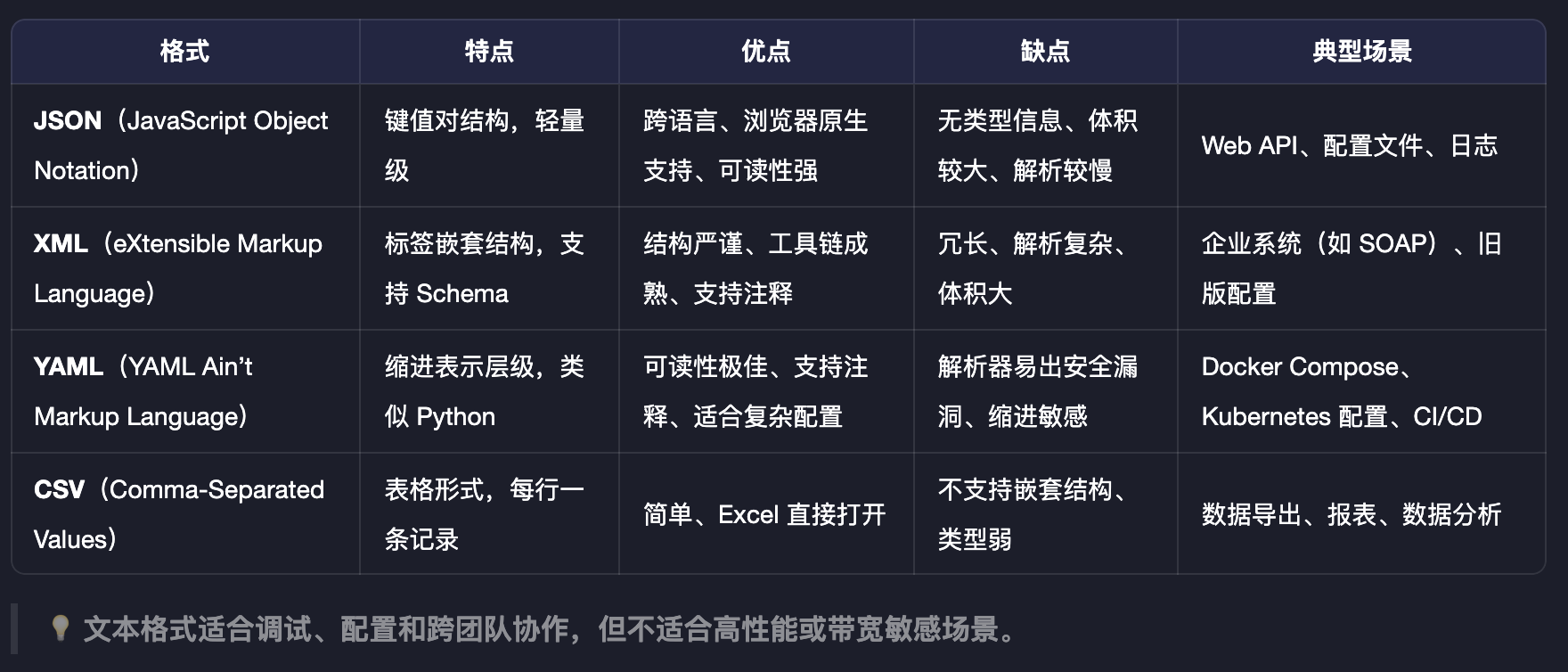
二进制型序列化方式,则有如下:
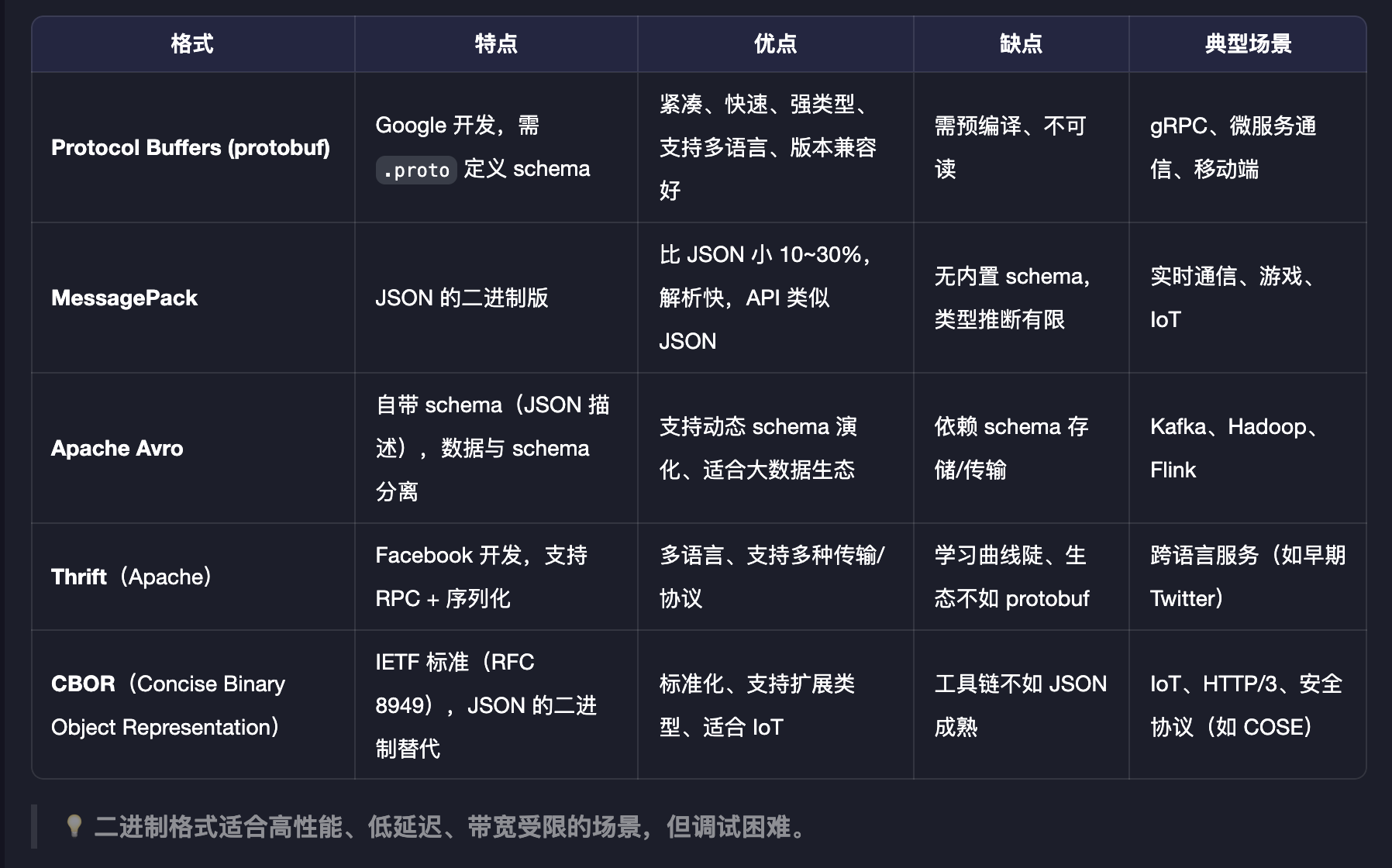
4、选择 PB 序列化
由于是要应用于数据加密存储场景,机器高效且具有良好兼容性的 Protocol Buffers 也即 PB 序列化,成为最终选择。而且,本来就是为了数据安全的,使用人类不能直接阅读的序列化方式,才能不违背初衷。
四、编程实践(Python)
基于以上的理论,现在,可以开始用 Python 去实践数据的加密存储了。
1、准备
在开始编写代码之前,你需要准备如下必须的东西:
- protoc 命令行:为了能够根据
.proto生成对应 Python 脚本,你需要在你的计算机上安装一个 protoc 命令行。 - 安装三方 Python 库:为了能够实现数据的序列化和加密,你需要在你的 Python 环境中,安装 protobuf 库和 pycryptodome 库
1.1、定义 person.proto
基于 protobuf 序列化的需要,准备一个 .proto 文件,比如 person.proto 文件,在其中,按照 proto 文件的语法,编写类似如下的内容:
// person.proto
syntax = "proto3";package tutorial;// 定义一个 Person 消息
message Person {int32 id = 1;string name = 2;string email = 3;repeated string phones = 4;
}// 可选:定义一个包含多个 Person 的 AddressBook
message AddressBook {repeated Person people = 1;
}
1.2、编译生成 person_pb2.py 文件
proto 文件,并不能直接在 Python 代码中 使用,必须借助 protoc 命令行去生成一个 xxx_pb2.py 脚本才能进行使用。
proto 文件通过 protoc 命令,可以编译成 Java 和 Python 等语言对应的代码文件,对应到 Python 代码,相应的命令为:
protoc --python_out=. person.proto
这个命令,需要将命令行切换到 proto 文件所在的目录下,才能成功执行。执行结束之后,proto 文件所在的目录,就会生成一个 person_pb2.py 文件;如果是 Java,则是生成 person_pb2.java 文件。
person_pb2.py 文件中的内容,通常类似如下:

请记住,person_pb2.py 文件生成之后,不要去动它、修改它。
2、实现业务功能
这里的业务功能,就是将数据加密存储到文件中,其中数据保存过程,可以分解为如下步骤:
- 将数据用 pb 对象进行描述
- 进行 pb 序列化
- 对 pb 序列化后的数据,进行 gzip 压缩输出 gzip 格式的字节码
- 对 gzip 格式的字节码进行 AES GCM 加密,同样输出字节码
- 将加密后的字节码,写入到文件中
而数据读取过程,便是反过来:
- 从文件中中读取字节码
- 对字节码进行解密,输出的字节码要符合 gzip 格式,否则就是解密算法存在错误过程
- 对gzip 格式的字节码进行解压缩操作,输出的是 pb 序列化数据
- 使用 protobuf 的相关 API,进行 pb 反序列化得到一个 pb 对象
当然了,在实际的开发场景中,pb 对象并不是数据加密存储功能的开始和结束。
梳理数据的加密存储和读取解密这两个流程,需要封装实现如下 Python 方法:
- 将字节码保存到文件中的 write_bytes_to_file 方法,和从文件中读取字节码的 read_bytes_from_file 方法。
- 进行 gzip 压缩操作的 gzip_compress 方法,和进行 gzip 解压缩操作的 gzip_decompress 方法
- 实现 AES GCM 加密的 aes_encrypt_by_gcm 方法,和实现 AES GCM 解密的 aes_decrypt_by_gcm 方法
- 以及专门用来生成密钥的 generate_random_key 方法和 generate_base64_key 方法
2.1、文件的写与读
首先,先来实现文件的写与读。
def write_bytes_to_file(data: bytes, filepath: str, mode: str = 'wb') -> None:"""将字节数据写入指定文件。参数:data (bytes): 要写入的字节数据。filepath (str): 目标文件路径。mode (str): 文件打开模式,默认为 'wb'(二进制写入)。通常应保持为 'wb',除非有特殊需求(如追加 'ab')。异常:TypeError: 如果 data 不是 bytes 类型。OSError: 如果文件无法创建或写入(如权限不足、磁盘满等)。"""if not isinstance(data, bytes):raise TypeError(f"Expected data of type 'bytes', got {type(data).__name__}")try:with open(filepath, mode) as f:f.write(data)except OSError as e:raise OSError(f"Failed to write bytes to file '{filepath}': {e}") from edef read_bytes_from_file(filepath: str, mode: str = 'rb') -> bytes:"""从指定文件中读取全部内容并返回为字节数据。参数:filepath (str): 要读取的文件路径。mode (str): 文件打开模式,默认为 'rb'(二进制读取)。通常应保持为 'rb',除非有特殊需求(如文本模式,但不推荐用于字节码)。返回:bytes: 文件的原始字节内容。异常:FileNotFoundError: 如果文件不存在。OSError: 如果文件无法打开或读取(如权限不足、设备错误等)。IsADirectoryError: 如果路径指向一个目录而非文件。"""try:with open(filepath, mode) as f:return f.read()except FileNotFoundError:raise FileNotFoundError(f"File not found: '{filepath}'")except IsADirectoryError:raise IsADirectoryError(f"Path is a directory, not a file: '{filepath}'")except OSError as e:raise OSError(f"Failed to read bytes from file '{filepath}': {e}") from e
IO 操作往往容易引发异常,所以,功能方法里面包含异常捕获语句是必要的。
2.2、gzip 压缩与解压
接着,把 gzip 的压缩与解压给实现:
def gzip_compress(data):"""将字节数据按照gzip格式压缩Args:data (bytes): 待压缩的字节数据Returns:bytes: gzip压缩后的数据"""try:compressed_data = gzip.compress(data)return compressed_dataexcept Exception as e:print(f"gzip压缩失败: {e}")return Nonedef gzip_decompress(compressed_data):"""对gzip格式的字节码进行解压缩Args:compressed_data (bytes): gzip格式的压缩数据Returns:bytes: 解压缩后的原始数据"""try:decompressed_data = gzip.decompress(compressed_data)return decompressed_dataexcept Exception as e:print(f"gzip解压缩失败: {e}")return None
压缩与解压操作,也是很容易就出现异常,所以也要有异常捕获语句。
2.3、AES GCM 加解密
最关键的加解密实现来了:
def aes_decrypt_by_gcm(password, input_data, iv_length=16, tag_length=16):"""AES-GCM解密函数Args:password (bytes): 解密密钥input_data (bytes): 输入数据(IV + 密文 + 认证标签)iv_length (int): IV长度tag_length (int): 认证标签长度,默认为16字节Returns:bytes: 解密后的原始数据,符合gzip格式"""try:# 分离IV、密文和认证标签iv = input_data[:iv_length]ciphertext_with_tag = input_data[iv_length:]# 分离密文和认证标签ciphertext = ciphertext_with_tag[:-tag_length]received_tag = ciphertext_with_tag[-tag_length:]# 创建AES-GCM解密器cipher = AES.new(password, AES.MODE_GCM, nonce=iv)# 解密并验证认证标签decrypted_data = cipher.decrypt_and_verify(ciphertext, received_tag)return decrypted_dataexcept ValueError as e:print(f"认证失败: {e}")return Noneexcept Exception as e:print(f"解密错误: {e}")return Nonedef aes_encrypt_by_gcm(password, plaintext_data, iv_length=16):"""AES-GCM加密函数,与aes_decrypt_by_gcm方法配套使用Args:password (bytes): 加密密钥plaintext_data (bytes): 待加密的明文数据iv_length (int): IV长度,默认为12字节(GCM推荐长度)tag_length (int): 认证标签长度,默认为16字节Returns:bytes: 加密后的数据(IV + 密文 + 认证标签)"""try:# 生成随机IVfrom Crypto.Random import get_random_bytesiv = get_random_bytes(iv_length)# 创建AES-GCM加密器cipher = AES.new(password, AES.MODE_GCM, nonce=iv)# 加密数据并生成认证标签ciphertext, auth_tag = cipher.encrypt_and_digest(plaintext_data)# 组合返回数据:IV + 密文 + 认证标签encrypted_data = iv + ciphertext + auth_tagreturn encrypted_dataexcept Exception as e:print(f"加密错误: {e}")return None
在加密算法 aes_encrypt_by_gcm 方法的 cipher = AES.new(password, AES.MODE_GCM, nonce=iv) 中,nonce 的作用是:用于确保相同明文每次加密都产生不同的密文,从而保障语义安全(semantic security)的随机值,结合方法体的实现,就是加密数据的时候默认使用 16字节即 128 比特的数据进行填充,从而确保同样密钥、同样的明文每次都能有不同的加密输出结果。
2.4、随机生成密钥
现在,只剩下一组随机生成密钥的方法,便可以开始体验整个业务功能了。
def generate_random_key(key_length=16):"""生成随机加密密钥Args:key_length (int): 密钥长度,可选值为16、24、32字节,分别对应AES-128、AES-192、AES-256Returns:bytes: 随机生成的密钥Raises:ValueError: 当key_length不是16、24、32时抛出异常"""from Crypto.Random import get_random_bytes# 验证密钥长度是否有效if key_length not in [16, 24, 32]:raise ValueError("密钥长度必须为16、24或32字节")# 生成指定长度的随机密钥return get_random_bytes(key_length)def generate_base64_key(key_length=16):"""生成按base64编码的加密密钥Args:key_length (int): 密钥长度,可选值为16、24、32字节Returns:str: base64编码的密钥字符串"""# 生成随机密钥key = generate_random_key(key_length)# 将密钥转换为base64编码的字符串return base64.b64encode(key).decode('utf-8')
这两个方法所实现的功能,基本上是一样的,只不过 generate_base64_key 方法,多了一步将生成的密钥用 base64 进行编码的操作,而这也是实际应用场景中常用的方式。在数据的加密存储功能中,服务端为了不丢失某批数据加密过程中使用的密钥,就会将密钥从字节码格式,转化成能够保存到数据库中的字符串格式。
在本文案例中,由于不涉及用数据库去记录数据加密操作过程,所以,直接用第一个密钥生成方法就行了。
2.5、体验
下面,用上述实现的方法,去体验一次数据的 PB 序列化、gzip 压缩、AES GCM 加密、文件保存,以及反过来的文件读取、AES GCM 解密、gzip 解压、PB 反序列化。
if __name__ == '__main__':person = person_pb2.Person()person.id = 1234person.name = "张三"person.email = "zhangsan@example.com"person.phones.extend(["13800138000", "010-12345678"])pb_bytes = person.SerializeToString()gzip_bytes = gzip_compress(pb_bytes)aes_key = generate_random_key()print(f"AES密钥: {aes_key.hex()}")encrypted_data = aes_encrypt_by_gcm(aes_key, gzip_bytes)file_name = "person.pcbe"write_bytes_to_file(encrypted_data, file_name)data_from_file = read_bytes_from_file(file_name)decrypted_data = aes_decrypt_by_gcm(aes_key, data_from_file)gzip_data = gzip_decompress(decrypted_data)new_person = person_pb2.Person()new_person.ParseFromString(gzip_data)print("\n反序列化后的对象:")print(f"ID: {new_person.id}")print(f"Name: {new_person.name}")print(f"Email: {new_person.email}")print(f"Phones: {list(new_person.phones)}")当上述代码执行顺利,那么,在运行窗口可以看到如下输出:
