UV快速入门
1 toml 配置语言
可以看这个视频快速入门视频,下面的内容将是对视频的解析和补充。
1.1 基本用法
简单来说,toml中的信息会被转化为一个字典,每一项就是一个键值对,等号左边将默认为字符串,将下面的信息写入一个名为 info.tmol 的文件中:
# 可以使用python中的类型,如字符串、整数、浮点数、列表、字典等
name = 'jim'
age = 30
school = ['ahu', 'zsu']
addr = "\"Guangzhou" # 转义字符只能在双引号中使用
time = 2020-01-01 # 时间将自动解析成 datetime.date 类型对象
salary = {2022=16000, 2023=19000}
然后我们写一段 python 代码解析toml文件:
import tomllib
from pprint import ppwith open("info.toml", "rb") as f:config = tomllib.load(f)print(type(config))
pp(config)
输出
<class 'dict'>
{'name': 'jim','age': 30,'school': ['ahu', 'zsu'],'addr': '"Guangzhou','time': datetime.date(2020, 1, 1),'salary': {'2022': 16000, '2023': 19000}}
如果在 toml 文件中出现方括号[xxx] 则为表格,方括号中的内容将是字典的一个键(设为A),后续的内容将作为一个字典,这个字典作为A的值,直到出现下一个表格[yyy],也就是说,表格被解析成了字典,嵌套在外层字典里面。如下所示:
name = 'jim'
age = 30
school = ['ahu', 'zsu']
addr = "\"Guangzhou" # 转义字符只能在双引号中使用# 使用表格定义字典
[info]
id = 100[plus]
action = 'jumpy'
解析的结果为:
{'name': 'jim','age': 30,'school': ['ahu', 'zsu'],'addr': '"Guangzhou','info': {'id': 100},'plus': {'action': 'jumpy'}}
也可以使用 . 来实现表格
name = 'jim'
age = 30
info.id = 100
info.salary = 50000
解析结果为:
{'name': 'jim', 'age': 30, 'info': {'id': 100, 'salary': 50000}}
方括号 [ ] 和点 . 可以配合使用,实现表格嵌套,如:
id = 100[info]# 表格嵌套1:
detail.usrname = 'jim'
detail.pwd = '<PASSWORD>'# 表格嵌套2:
[info.oranization]
company = 'google'
school = 'ahu'# 表格嵌套3:
[info.oranization.addr]
factory = 'Guangzhou'
office = 'Shenzhen'
解析结果:
{'id': 100,'info': {'detail': {'usrname': 'jim', 'pwd': '<PASSWORD>'},'oranization': {'company': 'google','school': 'ahu','addr': {'factory': 'Guangzhou','office': 'Shenzhen'}}}}
如果出现连续两个方括号,如[[xxx]],则 xxx 对应的是一个列表,列表中的元素都是字典,[[xxx]] 出现多少次,就说明列表有多少个元素:
id = 100[info]
detail.usrname = 'jim'
detail.pwd = '<PASSWORD>'# table group
# 如果字典的某一项是列表,那么列表中的每一个元素都用两个方括号括起来
[[classmate]]
name = 'yuan'
id = 101[[classmate]]
name = 'yang'
id = 102
解析结果:
{'id': 100,'info': {'detail': {'usrname': 'jim', 'pwd': '<PASSWORD>'}},'classmate': [{'name': 'yuan', 'id': 101}, {'name': 'yang', 'id': 102}]}
1.2 总结
(1)toml中的信息会被转化为一个字典,每一项就是一个键值对,它的键默认是字符串,不需要加引号,值可以是 python 中的类型,如字符串、整数、浮点数、列表、字典等;
(2)如果在 toml 文件中出现方括号[xxx] 则为表格,后续内容将自动解析为一个字典,实现字典的嵌套,直到出现下一对方括号 [yyy];
(3)方括号 [ ] 和点 . 可以配合使用,实现表格嵌套,既表格嵌套表格,然后包裹在字典中,解析出来将有三层字典;
(4)如果出现连续两个方括号,如[[xxx]],则 xxx 对应的是一个列表,列表中的元素都是字典,[[xxx]] 出现多少次,就说明列表有多少个元素。
我个人觉得 toml 文件麻烦很多,并不比 JSON 格式的文件方面,但 uv 工具和 toml 格式的配置文件高度绑定,要想学 uv,必须先能看懂 toml 文件内容。
2 关于 python 虚拟环境
简单来讲,虚拟环境就是一个独立的房间,一个项目安装一个虚拟环境,在这个环境中安装的第三方依赖包只有这个项目能用,这样可以使得项目的依赖包相互隔离。如果能看这篇文章的同学,肯定是对虚拟环境有所了解的,但未必大家都直到虚拟环境存放在哪里。
关于虚拟环境,我们需要直到三样东西:python解释器,激活脚本,第三方包。刚刚说了,虚拟环境是一个独立的房间,python解释器则是在这个房间里工作的工人,它负责解释代码;而激活脚本则相当于房间钥匙,只有运行激活脚本,才能激活这个虚拟环境;第三包则是独属于这个房间的工具箱,在这个环境下安装或者删除第三方包,都不会对其他环境造成影响。
python有内置的虚拟环境管理工具 venv,我们可以在项目目录(假设为 my_project )下,使用 venv 创建虚拟环境:python -m venv jim_env,这里 jim_env 是环境名,此时项目目录下将增加一个名为 jim_env 的目录,虚拟环境就存放在这里,具体内容如下:
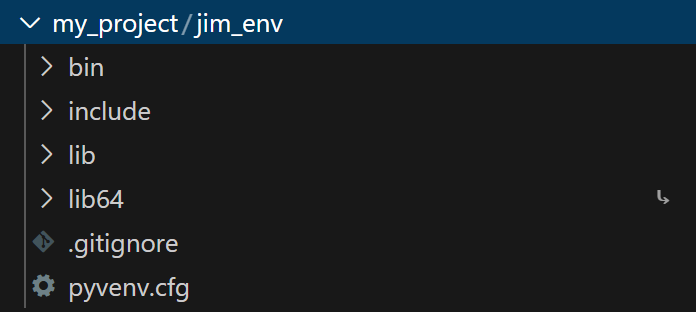
1.1 python 解释器
python解释器放在 jim_env/bin 中,具体位置如下图红框所示:
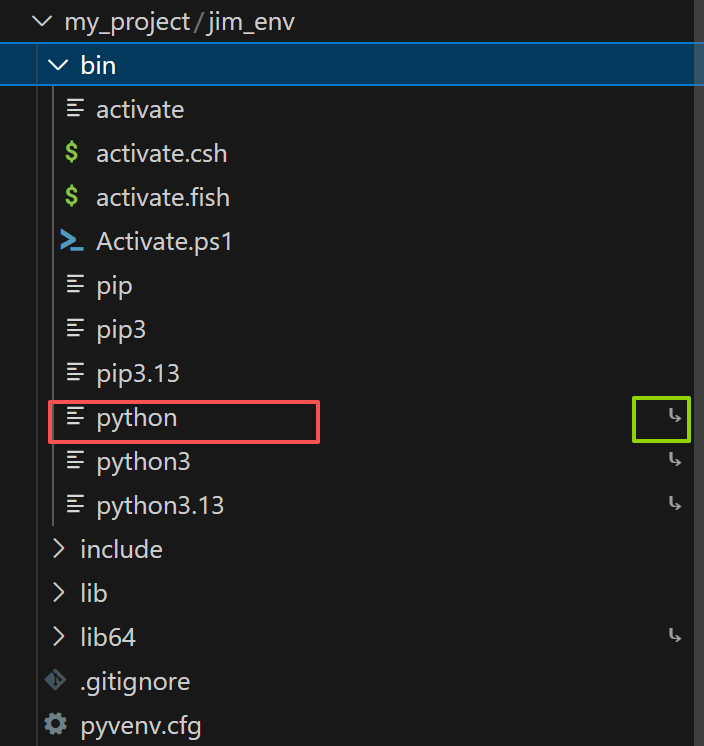
python右边有个转折箭头(绿框所示),表示引用,我们在输入命令 python -m venv jim_env 前,窗口已经切换为了 conda base 环境,所以这里的转折箭头表示引用的的解释器为 base 环境中的 python 解释器,当然,如果在新建虚拟环境前切换为了 conda 的其他环境,那么引用的也将是其他环境下的解释器。引用不同于副本,如果 base 环境中的解释器删除,则这里的引用也会消失。(有点类似于python的赋值,a = object,b = a,a指向的对象如果释放,则 b 也无从引用)
1.2 激活脚本
bin目录下的 activate 则是激活环境脚本,截图右边的部分则是脚本的内容(看不懂不要紧,只需要知道 activate 是激活环境脚本就行):
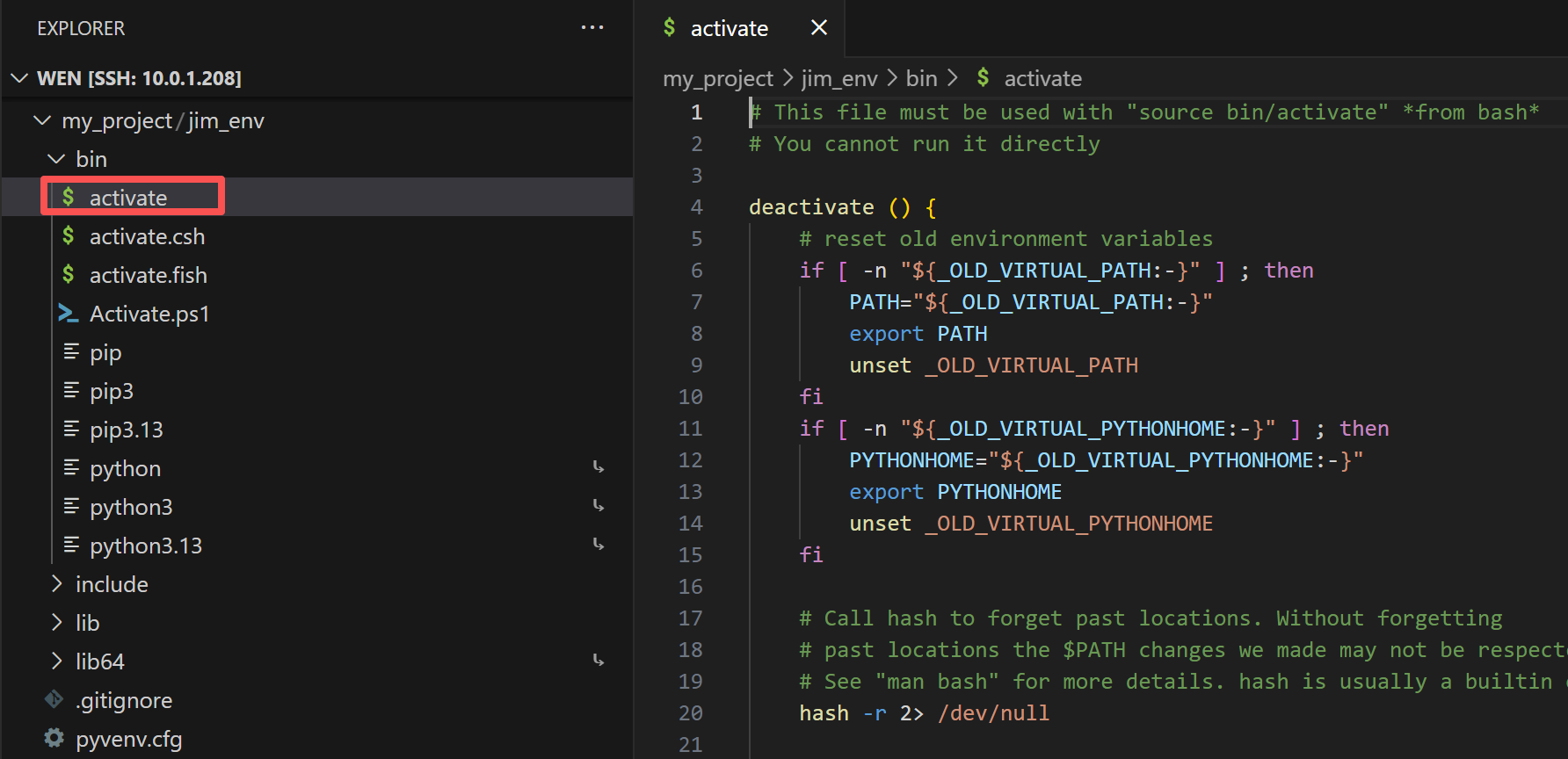
激活虚拟环境 jim_env 只需要运行激活脚本就可以了,激活命令为:source jim_env/bin/activate,如果要退出激活环境,命令为:deactivate
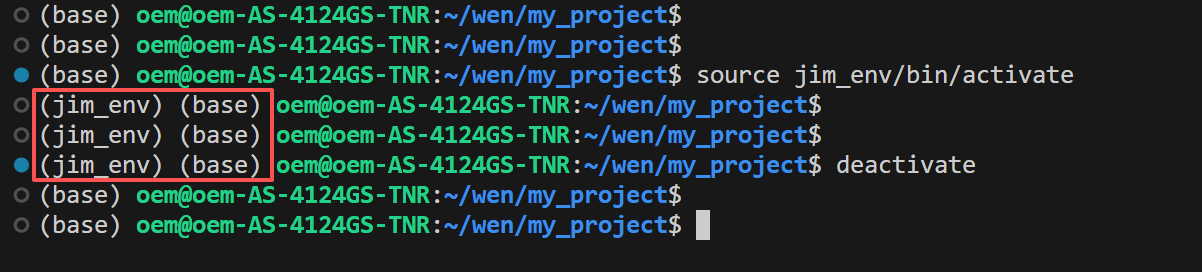
从上面的截图可以看到,虚拟环境激活后,在命令提示符前面出现了虚拟环境的名称,表示我们正在 jim_env 这个虚拟环境,退出后,虚拟环境名称消失,只能看到conda的环境名。
1.3 第三方包
我们在虚拟环境下安装的第三方包,在 lib/python3.13/site-packages 这个目录下,这里之所以是 python 3.13,是因为 conda base 的 python 解释器是 3.13 版本的。

从上面的截图可以看到,因为现在什么包都还没装,所以 lib/python3.13/site-packages 目录下只有两个关于 pip 的文件夹,使用 pip list 命令也只能看到只有一个pip工具包。
用 pip 安装 numpy,命令为 pip install numpy,随后可以看到在 lib/python3.13/site-packages 目录下多出几个关于 numpy 的文件夹:
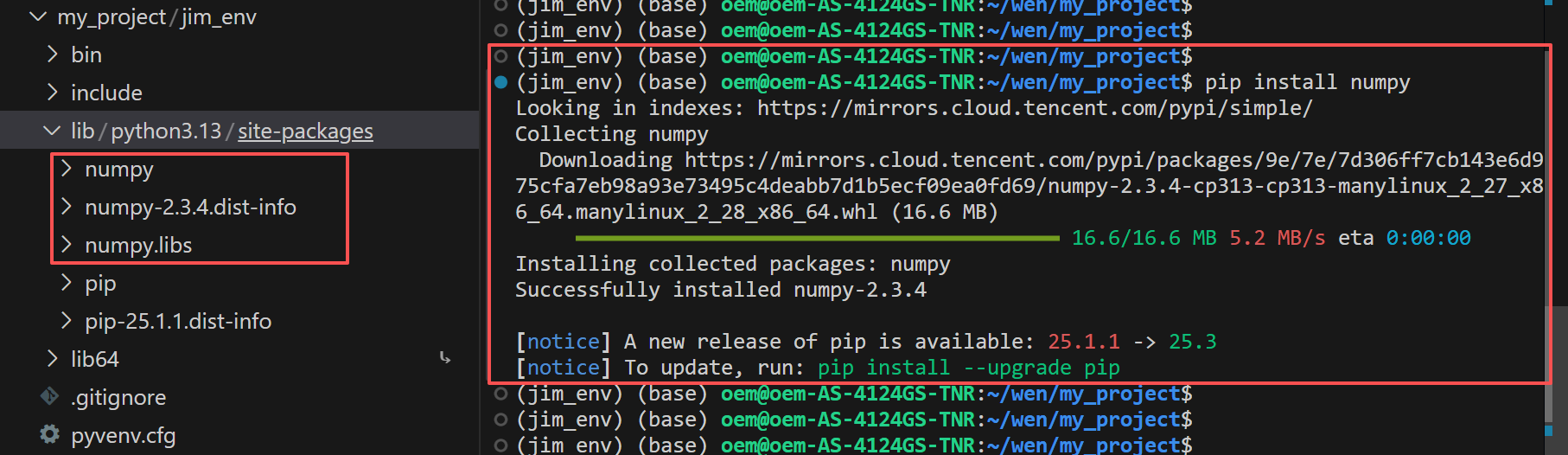
我们使用 pip install 安装的任何包,都会安装在 lib/python3.13/site-packages 目录下,在写程序时,使用 import 就可以导入。
1.4 不同虚拟环境管理工具的比较
python的虚拟环境管理工具,除了刚刚介绍的 python 自带的 venv,还有 conda、uv 等,它们的本质都是相同的,都是在某个路径下放刚刚提到的三个东西。
venv 和 uv 是在项目下创建虚拟环境目录,这样可以根据项目区分环境,而conda是在自己的目录下创建目录。下面是conda创建的虚拟环境所在目录:
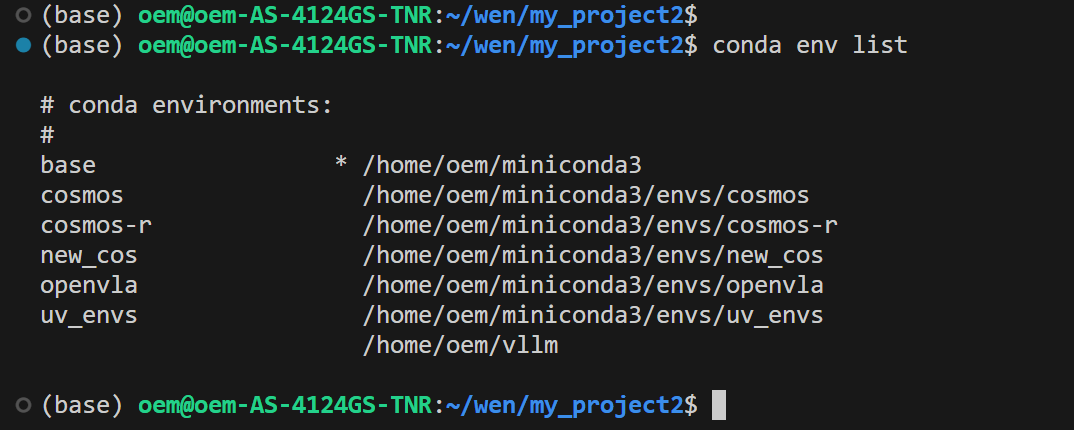
在 python 解释器方面,venv 和 uv 都是引用你已经安装好的 python 解释器,而 conda 的每个环境中的 python 解释器,则不是引用,而是独立的解释器。说简单点,venv 和 uv 建立虚拟环境,必须和已有的环境有相同的python版本,如果你的机器上只有 python 3.13,但你想新建一个python 3.14 版的虚拟环境,那么只能用 conda。
在激活虚拟环境时,venv 和 uv 都是 source + 激活脚本,而 conda 则是 conda activate 环境名。
3 关于uv
快速入门视频,下面的内容将是对视频的内容的解析和补充。
uv 号称是目前最好的项目管理工具和环境管理工具,但我觉得有待商榷。
3.1 用 uv 创建项目
假设我们要新建一个python项目,那么在开始写代码之前,需要在python目录里新建三个东西:管理版本的git仓库(名为 .git 的文件夹),配套的 .gitignore,以及介绍项目的 readme 文档,这是比较繁琐的。
使用 uv 只需要一个命令就可以完成所有操作:
uv init new_project
执行上述命令后,项目被初始化,包括创建名为 new_project 的文件夹,以及git仓库(名为 .git 的文件夹)、配套的 .gitignore、README.md 三个文件,如下图所示:
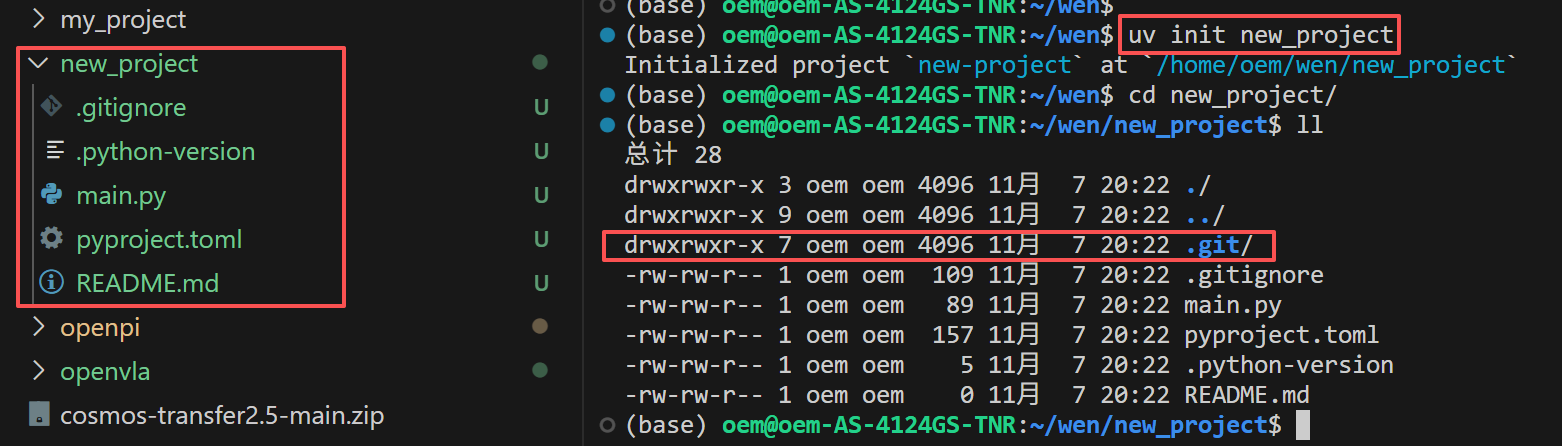
左边的项目结构中没有现实 git 仓库目录,但使用 ll 命令查看是能看到的。
除了刚刚说的三项,这里还有几个刚刚没提到的文件,其中 main.py 是程序入口,而 .python-version 和 pyproject.toml 是 uv 用来管理虚拟环境的文件。
.python-version 用来指定该项目使用的 python 版本,内容如下:
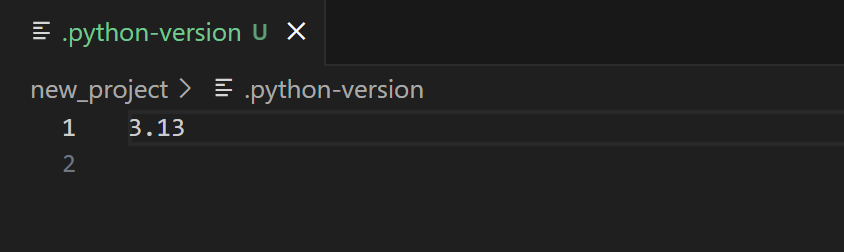
pyproject.toml 则是项目说明书,它包含了项目的元数据,例如项目的名称、版本、描述、python版本、依赖(即用到的第三方工具包)等,相当于 setup.py 或 requirements.txt 的升级版。pyproject.toml 的初始内容如下:
3.2 用 uv 管理环境
uv 使用 pyproject.toml 来管理项目的依赖,uv安装、更新、删除依赖,都会自动修改 pyproject.toml。
使用 uv 安装依赖,只需要 uv add 依赖名,例如:
uv add numpy
也可以指定版本号:
uv add numpy==2.2
安装时,会自动检查当前项目下是否有虚拟环境,如果没有,则会自动创建。
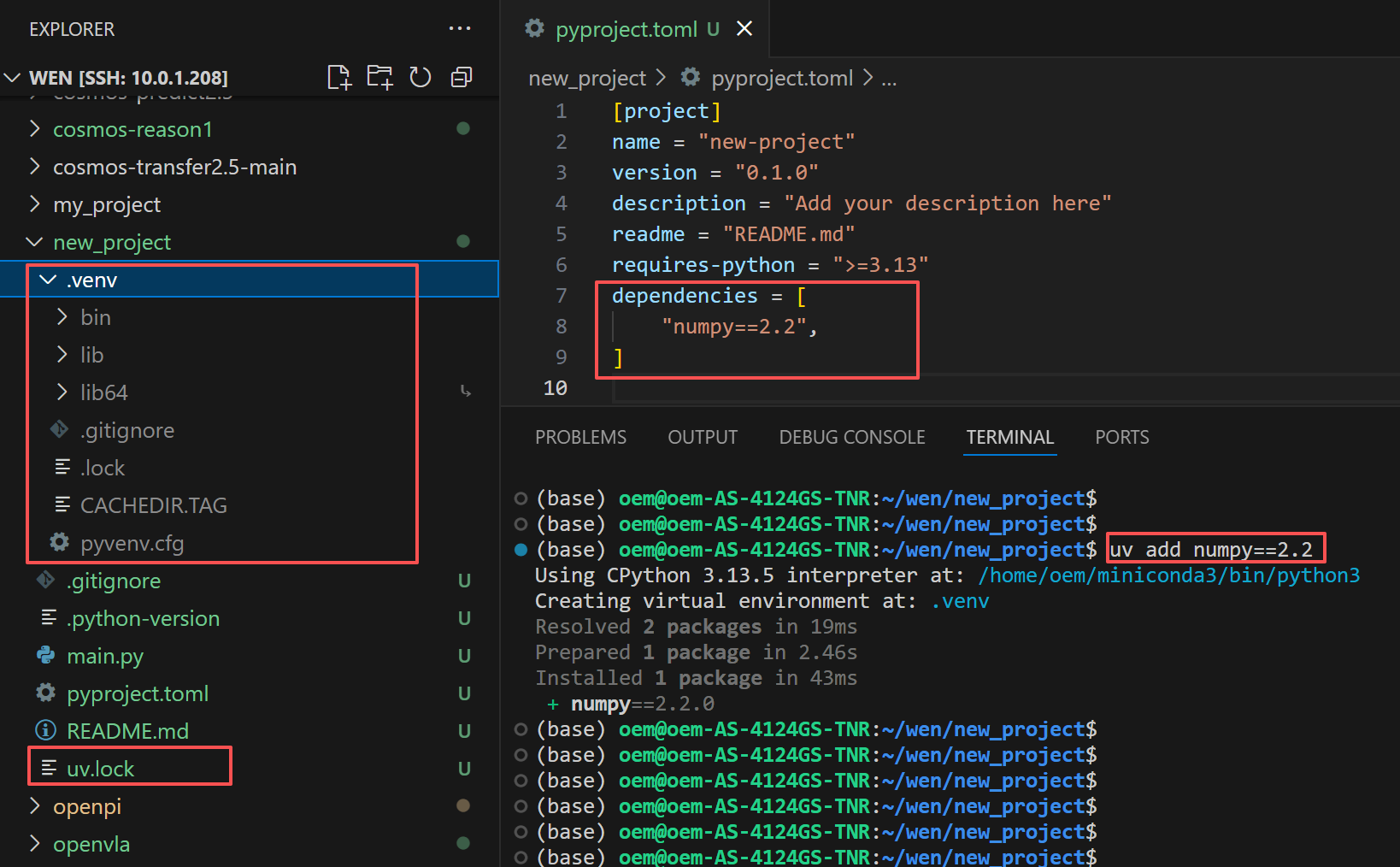
从上面的截图可以看到,执行安装依赖的命令后,项目下多了一个名为 .venv 的目录,它是虚拟环境目录,说明在安装依赖之前,先创建了一个虚拟环境,同时在项目下还多了一个名为 uv.lock 的文件,此外,pyproject.toml 也更新了, dependencies 中增加了一条关于 numpy 的版本信息。
当我们复现别人的项目的环境时,只需要拿到对方的 pyproject.toml 就行了,然后使用:
uv sync
就行了,我们可以把 .venv 目录删了,然后运行上述命令,就能把环境重装。
3.3 uv 执行程序
若用 uv 运行程序,则不需要激活虚拟环境,系统会自动匹配本项目的虚拟环境,例如我们修改 main.py 如下:
import numpy as np
def main():a = np.array([1, 2, 3])print(a)print(np.__version__)if __name__ == "__main__":main()命令行执行一下命令:
uv run main.py
输出:
[1 2 3]
2.2.0
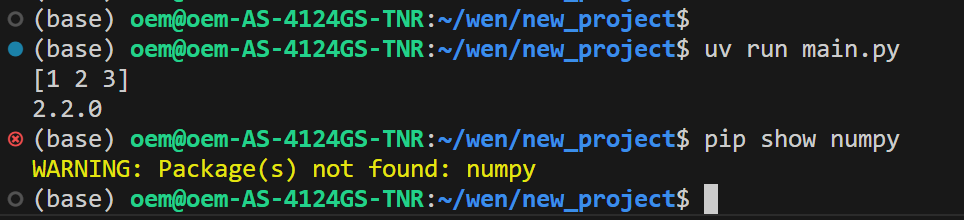
从下面的截图可以看到,命令行提示符前,并没有本项目虚拟环境的名称,如果有的话,应该是 (.venv) :

有人觉得,这个可能使用的是 conda base 环境,但我在 base 环境中并没有安装 numpy,所以这里必然是用虚拟环境来运行的。
可以用 pip show numpy 来检验一下 base 环境是否安装 numpy,如果安装,则会现实版本号:
*3.3 用 uv 管理命令行工具(做算法不需要掌握)
python 有些命令行工具,比如用于测试的 pytest,用于查看显存的 nvitop等,这些命令可以直接在命令行使用,不需要在前面加 python。这种工具可能会在多个项目中都用到,因此需要全局安装,而不是每个项目的虚拟环境单独安装。
安装命令行工具只需要执行如下命令:
uv tool install pytest
卸载只需要执行下面命令:
uv tool uninstall pytest
3.4 临时运行命令
待补充