简单网站制作教程怎么做网站数据分析
推荐阅读
AIGCmagic社区介绍:
2025年《AIGCmagic社区知识星球》五大AIGC方向全新升级!
AI多模态核心架构五部曲:
AI多模态模型架构之模态编码器:图像编码、音频编码、视频编码
AI多模态模型架构之输入投影器:LP、MLP和Cross-Attention
AI多模态模型架构之LLM主干(1):ChatGLM系列
AI多模态模型架构之LLM主干(2):Qwen系列
AI多模态模型架构之LLM主干(3):LLAMA系列
AI多模态模型架构之模态生成器:Modality Generator
一、Projector的基本定义与核心功能
在多模态大模型(Multimodal Large Language Models, MLLMs)中, Projector(投影器) 是连接不同模态特征空间的关键模块。其核心功能是实现跨模态特征的语义对齐与转换,具体分为两类:
-
输入投影器(Input Projector) :将图像、音频等非文本模态的编码特征映射到与文本特征兼容的共享空间(如LLM的输入空间)。
-
输出投影器(Output Projector) :将语言模型(LLM)输出的文本特征映射到目标模态(如图像、视频)的生成空间,支持多模态生成任务。
以经典的MLLM架构为例,Projector通常位于模态编码器与LLM之间,或LLM与模态生成器之间,承担特征维度对齐和语义融合的角色。
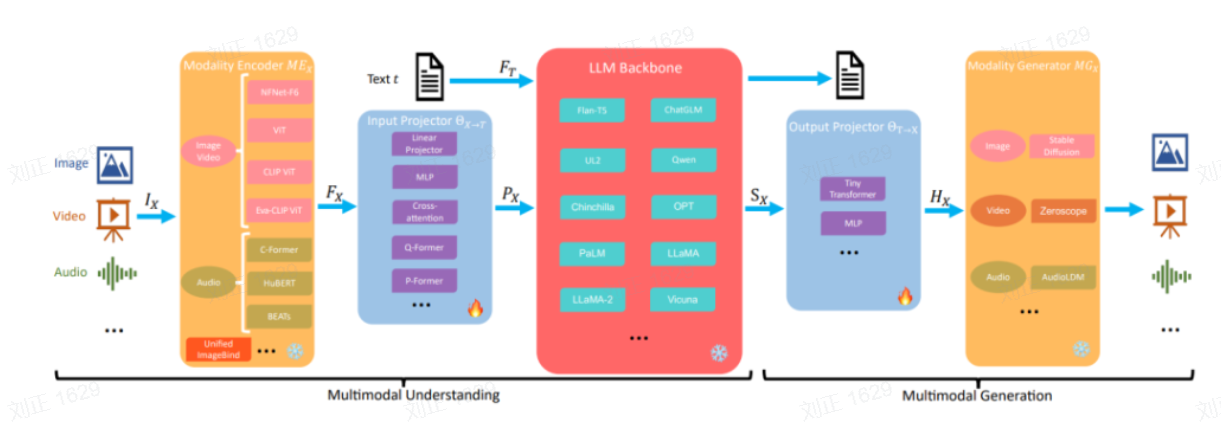
二、Output Projector的类别与特点
根据映射方式的不同,Output Projector可分为以下三类:
| 类别 | 实现方式 | 优点 | 缺点 | 代表模型 |
| Text Tokens | LLM输出纯文本指令,调用外部工具生成多模态内容 | 无需微调、计算高效 | 无法端到端优化,生成能力受限 | Visual-ChatGPT |
| Continuous Embedding | 通过嵌入向量(Embeddings)传递LLM输出至下游解码器 | 支持端到端训练,信息密度高 | 需设计复杂交互机制 | LLaVA、MiniGPT-4 |
| Codebooks | LLM生成特殊Token ID序列,驱动多模态解码器(如扩散模型)自回归生成内容 | 支持细粒度控制,生成质量高 | 训练复杂度高,依赖高质量Token化 | Unified-IO 2 |
Continuous Embedding是当前主流方向(43个主流模型中8个采用),因其平衡了效率与生成能力的优势。
三、Projector在特征对齐中的作用机制
Projector通过以下方式实现跨模态语义对齐:
-
特征空间映射:使用线性层、MLP或小型Transformer,将不同模态特征投影到统一空间。例如,LLaVA通过线性层将图像特征对齐到文本嵌入空间。
-
注意力引导:如LVP模型引入语言指导的跨模态注意力,根据文本特征动态筛选重要视觉令牌,减少冗余计算(压缩75%视觉令牌)。
-
对抗学习:ACMR模型通过特征投影器生成模态不变表示,混淆模态分类器,增强跨模态一致性。
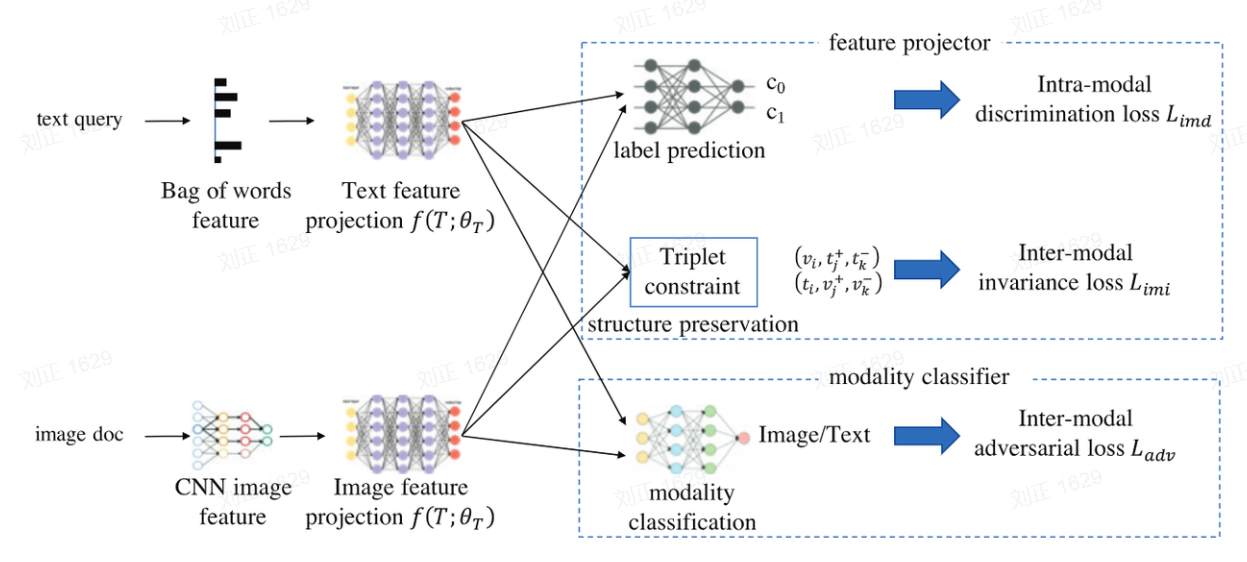
-
多空间协同对齐:CDRA算法同时在图像空间和高斯分布空间对齐特征,提升判别能力。
这些机制共同解决了模态异构性(如图像像素与文本符号的差异)和语义鸿沟(如“红色”在文本与图像中的多义性)问题。
四、Projector与编码器/解码器的交互方式
-
输入侧交互:
-
图像编码器(如ViT)输出特征 → **线性投影层**调整维度 → 与文本Token拼接后输入LLM。
-
高级方法如Q-Former(BLIP-2)通过可学习查询向量压缩视觉特征,并与LLM交互。
-
-
输出侧交互:
-
LLM生成文本特征 → Tiny Transformer或MLP投影 → 扩散模型生成图像(如Stable Diffusion)。
-
复杂结构如Flamingo的Perceiver Resampler压缩视觉特征后,通过GATED XATTN-DENSE层与语言模型融合。
-
五、主流模型的Projector实现差异
| 模型 | Projector设计 | 特点 |
| CLIP | 双投影矩阵:图像编码器(ViT)和文本编码器(GPT-2变体)分别投影至共享嵌入空间 | 简单高效,依赖对比学习实现对齐;生成能力有限 |
| Flamingo | Perceiver Resampler(压缩视觉特征) + GATED XATTN-DENSE(跨模态注意力门控) | 支持长序列处理,动态融合视觉与文本特征;计算复杂度较高 |
| PaLI | Encoder-Decoder架构集成投影器,直接生成多模态输出 | 端到端优化,适合多语言任务;灵活性较低 |
| LVP | 语言引导的跨模态特征增强 + 可变形注意力 | 显著减少计算量(FLOPs降低75%),保持高精度 |
CLIP的投影设计以对称性著称,而**Flamingo**通过引入重采样机制优化了长上下文处理能力,体现了从静态对齐到动态交互的技术演进。
六、Projector设计对模型性能的影响
-
计算效率(FLOPs):
-
MoDA Projection在低FLOPs时优于Full Attention,适合边缘设备。
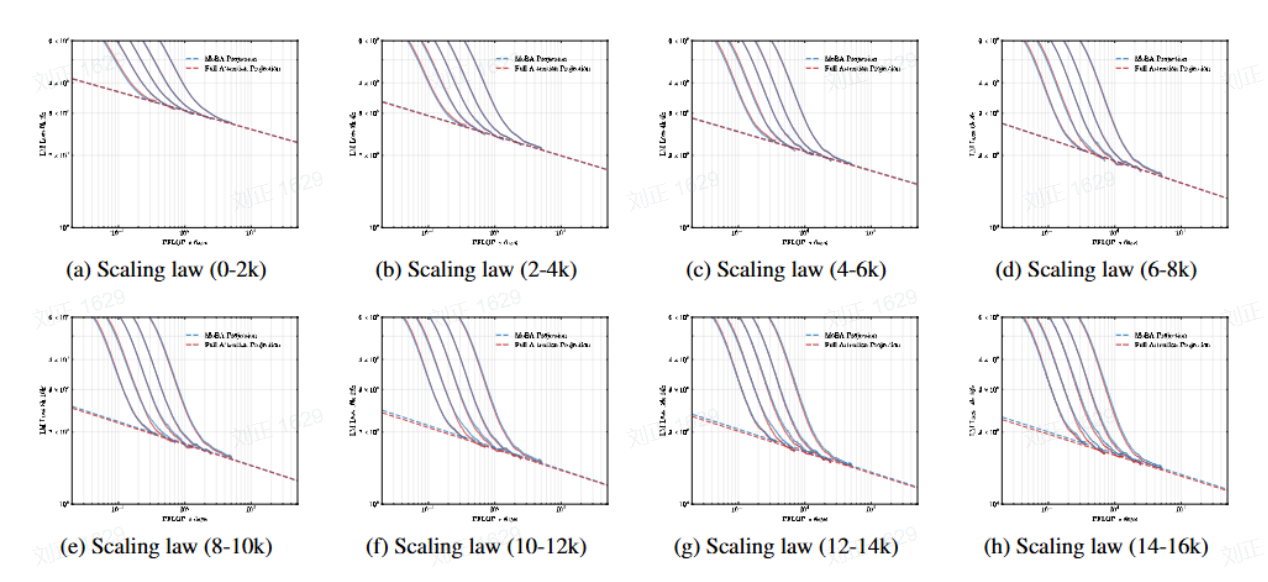
-
-
STViT通过语义令牌稀疏化,将DeiT-B的FLOPs从17.58G降至12.13G,精度仅损失0.1%。
-
生成质量(准确率):
-
使用加权平均聚合的投影器比平均池化提升0.5% Top-1准确率。
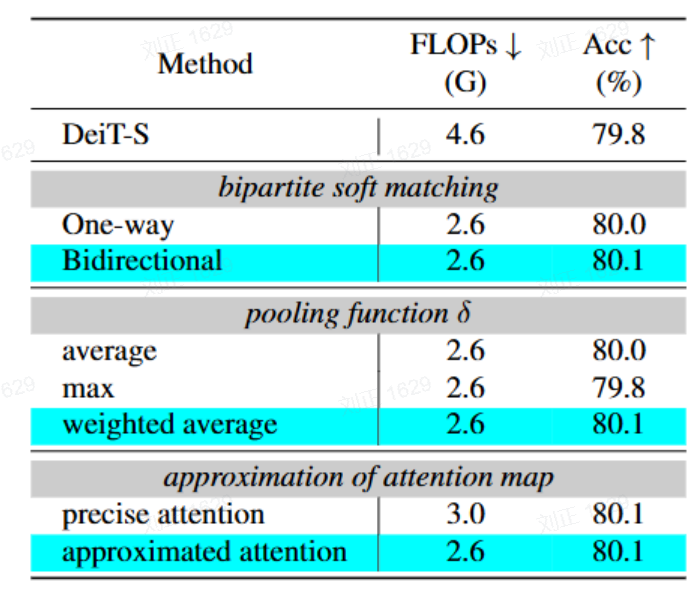
-
-
MicroNet在12M FLOPs约束下,ImageNet准确率达59.4%,超越MobileNetV3 9.6%。
-
训练-推理权衡:
-
Text Tokens类Projector推理快但训练受限,Codebooks类反之,需根据任务需求平衡。
-
七、未来研究方向
-
动态投影机制:根据输入内容自适应调整投影策略,如LVP的多级语言引导。
-
轻量化设计:探索低秩分解、知识蒸馏等技术,进一步降低FLOPs。
-
跨模态因果性建模:在投影过程中引入因果注意力,提升生成内容的逻辑一致性。
-
多任务统一架构:设计通用Projector支持图像生成、语音合成等多种任务,降低部署复杂度。