TinyTroupe:微软开源的轻量级多智能体“人格”模拟库(一)

文章目录
- 1. 项目概览 (Overview)
- 1.1 介绍
- 1.2 关键特性和能力
- 1.2.1. 编程式智能体定义
- 1.2.2. 多智能体模拟
- 1.2.3. 商业用例
- 1.2.4. 分析能力
- 2. 快速上手 (Quick Start)
- 2.1. 环境准备与安装
- 2.1.1. 环境要求
- 2.1.2. 安装
- 2.1.3 配置选项
- 2.2. 快速入门
- 2.3 demo
- 2.3.1 **步骤 1:导入所需模块**
- 2.3.2 **步骤 2:加载智能体规范**
- 2.3.3 步骤 3:创建模拟世界
- 2.3.4 步骤 4:运行模拟
- 2.3.5 步骤 5:理解输出
- 2.3.6 自定义你的模拟
- 2.3.7 创建自定义场景
- 3. 核心模块深度解析 (Deep Dive into Core Modules)
- 3.1. 模块一:`TinyPerson` - 智能体核心
- 3.1.1. 使用场景
- 3.1.2. 代码案例
- 案例 1: 通过 JSON 文件定义人格
- 案例 2: 通过编程方式定义人格
- 3.2. 模块二:`TinyPersonFactory` - 智能体工厂
- 3.2.1. 使用场景
- 3.2.2. 代码案例
- 案例 1: 从自然语言描述生成智能体
- 案例 2: 从人口统计数据批量生成
- 3.3. 模块三:`TinyWorld` - 模拟环境
- 3.3.1. 使用场景
- 3.3.2. 代码案例
- 4 Agent使用教程
- 4.1 创建基础 agent
- 4.1.1 **基础 Agent 创建**
- 4.1.2 **使用 TinyPersonFactory 创建丰富 Persona**
- 4.1.3 自定义 Agent 行为:定义 Persona 属性
- 4.1.4 使用 + 运算符提高便利性
- 4.1.5 设置关系
- 4.2 Agent 认知状态管理
- 4.2.1 更新认知状态
- 4.3 Agent 交互方法
- 4.3.1 刺激响应循环
- 4.3.2 刺激输入
- 4.3.3 关键交互方法
- 4.4 Agent 记忆系统
- 4.4.1 情景记忆
- 4.4.2 语义记忆
- 4.5 Agent 行为生成
- 4.5.1 行为方法
- 4.5.2 行为类型
- 4.6 创建 Agent 的最佳实践
- 4.7 常见陷阱和解决方案
- 5 使用 Fragments 实现角色复用
- 5.1 Fragments的作用
- 5.2 内置 Fragment 示例
- 5.3 Fragment 集成方法
- 5.3.1 方法 1:使用 + 运算符
- 5.3.2 方法 2:直接导入方法
- 5.3.3 方法 3:字典集成
- 5.4 Fragment 加载和发现
- 5.4.1 加载 Fragments
- 5.4.2 发现可用 Fragments
- 5.4.3 Fragment 处理和合并
- 5.4.4 实际实现示例
- 5.5 自定义 Fragment 创建
- 5.6 Fragment 链式组合
- 6 使用 TinyPersonFactory 生成群体
- 6.1 TinyPersonFactory作用
- 6.2 基于人口统计的工厂创建
- 6.3 单个角色生成
- 7 记忆系统与认知建模
- 7.1 情景记忆
- 7.2 语义记忆
- 7.3 记忆整合与处理
- 7.4 反思机制
- 7.5 认知状态集成
- 8 统计分析与实验设计
- 8.1 随机化与控制
- 8.2 基于命题的假设检验
- 8.3 统计测试框架
- 8.4 假设验证
- 8.5 案例:市场研究验证
- 9 实际案例解析
- 9.1 市场调研模拟
- 10 资源损耗预估:模拟
- 10.1. Token 消耗分析
- 10.2. 成本估算公式
- 20.3. 案例:500人模拟的成本预估
- 11 总结
1. 项目概览 (Overview)
1.1 介绍
TinyTroupe 是一个由 LLM 驱动的实验性 Python 库,专为多智能体“人格”模拟而设计。它并非要打造一个 AI 助手,而是旨在成为一个强大的“想象力增强工具”,通过模拟具有特定个性、兴趣和目标的人(TinyPerson),在可控的虚拟环境(TinyWorld)中进行互动,从而为商业和生产力场景提供深刻的洞察。
- 程序化与可定制: 通过 Python 和 JSON 文件以编程方式定义智能体和环境,提供了极高的灵活性。
- 面向分析与洞察: 专为理解人类行为而设计,强调通过实验获取洞察,而非简单的任务执行。
- 深度人格模拟: 鼓励对智能体进行详细的“人格”画像,包括年龄、职业、技能、品味、观点等,以实现更逼真的模拟。
- 实验导向: 提供丰富的工具集来支持迭代式的实验流程:定义、运行、分析和优化。
- 商业场景驱动: 与游戏类模拟不同,
TinyTroupe专注于解决实际的商业问题,如广告评估、产品测试等。
典型应用场景
-
场景一:广告效果评估 - 在投入实际预算前,通过模拟观众群体来离线评估数字广告(如 Bing Ads)的效果。
-
场景二:软件与产品测试 - 模拟不同类型的用户与系统(如搜索引擎、聊天机器人)互动,提供测试输入并评估结果。
-
场景三:焦点小组与头脑风暴 - 以极低的成本模拟一个焦点小组,围绕新产品或新功能进行头脑风暴,并收集反馈。
-
场景四:合成数据生成 - 生成可用于模型训练或市场机会分析的逼真合成数据。
-
GitHub 仓库:
https://github.com/microsoft/TinyTroupe -
官方文档: 主要通过
README.md和examples/目录提供 -
相关论文:
https://arxiv.org/abs/2507.09788
1.2 关键特性和能力
1.2.1. 编程式智能体定义
TinyTroupe 允许你使用 Python 或 JSON 规范以编程方式定义智能体。智能体可以具有详细的角色设定,包括:
- 人口统计信息(年龄、职业、教育背景)
- 性格特征和偏好
- 信念和观点
- 技能和专业知识
- 背景历史
1.2.2. 多智能体模拟
系统支持在定义环境中的复杂多智能体交互,具备以下特性:
- 具有真实时间感的时序模拟
- 为提升性能而进行的并发智能体执行
- 环境约束和规则
- 用于场景控制的干预机制
1.2.3. 商业用例
TinyTroupe 专为业务和生产力场景而设计:
- 广告测试:在部署前使用模拟受众评估数字广告
- 软件测试:生成测试输入并评估系统响应
- 产品头脑风暴:模拟焦点小组以获取产品反馈
- 市场研究:进行合成用户访谈和调查
- 训练数据:为模型训练生成逼真的合成数据
1.2.4. 分析能力
系统提供广泛的分析和验证工具:
- 自动化行为提取和降维
- 基于命题的验证框架
- 统计实验支持
- 质量控制和角色一致性监控
2. 快速上手 (Quick Start)
2.1. 环境准备与安装
2.1.1. 环境要求
- Python 3.10 或更高版本。
- Azure OpenAI 或 OpenAI 的 API 访问权限。你需要设置相应的环境变量:
- Azure OpenAI: 设置
AZURE_OPENAI_KEY和AZURE_OPENAI_ENDPOINT。 - OpenAI: 设置
OPENAI_API_KEY。
- Azure OpenAI: 设置
- 项目默认使用 OpenAI 的
gpt-4o-mini模型,你可以在项目根目录创建config.ini文件来覆盖默认配置。
TinyTroupe 包含这些基本依赖 pyproject.toml:
| 类别 | 依赖项 | 用途 |
|---|---|---|
| LLM 集成 | openai >= 1.65, tiktoken, msal | 与 LLM 服务进行 API 通信 |
| 数据处理 | pandas, scipy, textdistance | 数据操作和分析 |
| 文档处理 | llama-index, pypandoc, docx, markdown | 文档处理和索引 |
| 可视化 | matplotlib, rich | 输出格式化和图表 |
| 测试 | pytest, pytest-cov | 单元测试和覆盖率 |
| 验证 | pydantic | 数据验证和类型检查 |
2.1.2. 安装
官方推荐直接从 GitHub 仓库安装:
# 建议在一个新的虚拟环境中安装
# conda create -n tinytroupe python=3.10
# conda activate tinytroupepip install git+https://github.com/microsoft/TinyTroupe.git@main
2.1.3 配置选项
TinyTroupe 使用 config.ini 文件来控制模拟行为。关键设置包括:
[OpenAI]
MODEL=gpt-4.1-mini
MAX_TOKENS=32000
TEMPERATURE=1.5[Simulation]
PARALLEL_AGENT_ACTIONS=True
RAI_HARMFUL_CONTENT_PREVENTION=True[Logging]
LOGLEVEL=ERROR
重要配置参数:
| 设置 | 默认值 | 影响 |
|---|---|---|
| MODEL | gpt-4.1-mini | 决定响应质量和成本 |
| TEMPERATURE | 1.5 | 控制创造力与一致性 |
| PARALLEL_AGENT_ACTIONS | True | 提高多智能体性能 |
| RAI_HARMFUL_CONTENT_PREVENTION | True | 启用内容过滤 |
从默认配置开始,然后根据你的需求调整 TEMPERATURE 和 MODEL。较低的温度(0.7-1.0)用于更一致的行为,较高的温度(1.0-1.5)用于更多的创造力。
2.2. 快速入门
要开始使用 TinyTroupe,你通常遵循以下工作流程:
- 定义角色:使用 Python 类或 JSON 文件创建详细的智能体规范
- 创建环境:使用你的智能体设置一个 TinyWorld
- 运行模拟:执行交互,让智能体根据其角色设定行事
- 提取结果:使用提取框架分析模拟结果
- 验证行为:使用命题确保智能体的行为符合预期
核心智能体组件:
| 组件 | 描述 | 示例 |
|---|---|---|
| 人格 | 基本身份信息 | 姓名:“Lisa Carter”,年龄:28,职业:数据科学家 |
| 个性 | 行为特质和大五人格得分 | “好奇、分析型、友好” |
| 目标 | 长期和短期目标 | “推进 AI 技术、保持工作与生活平衡” |
| 风格 | 沟通偏好 | “专业但平易近人” |
| 教育 | 背景和专业知识 | “数据科学硕士、科技初创公司实习经历” |
2.3 demo

| 组件 | 用途 | 主要特性 |
|---|---|---|
| TinyPerson | 代表具有类人行为的个体模拟智能体 | 丰富的人格规范、认知建模、记忆系统 |
| TinyWorld | 提供智能体交互的环境 | 管理智能体可访问性、通信渠道 |
| Simulation Control | 编排整个模拟生命周期 | 事务管理、缓存、并行执行 |
在运行你的第一个模拟之前,请确保你已经:
- 安装了 TinyTroupe(参见安装指南)
- 为你的 LLM 提供商配置了 API 密钥
- 对 Python 和 JSON 有基本了解
TinyTroupe 会自动从 tinytroupe/config.ini 加载配置,但你可以在工作目录中创建本地的 config.ini 文件来覆盖设置。
2.3.1 步骤 1:导入所需模块
每个模拟都从导入必要的 TinyTroupe 组件开始:
import tinytroupe
from tinytroupe.agent import TinyPerson
from tinytroupe.environment import TinyWorld
from tinytroupe.examples import *
这导入了:
tinytroupe:主框架初始化和配置TinyPerson:用于创建模拟个体的智能体类TinyWorld:用于管理智能体交互的环境类tinytroupe.examples:预构建的示例资源
2.3.2 步骤 2:加载智能体规范
TinyTroupe 智能体通过详细的 JSON 人格规范来定义。这些文件包含每个智能体的背景、个性、技能和行为等全面信息。
lisa = TinyPerson.load_specification("./agents/Lisa.agent.json") # 数据科学家
oscar = TinyPerson.load_specification("./agents/Oscar.agent.json") # 建筑师
理解智能体结构
每个智能体规范包括:
| 类别 | 描述 | 示例 |
|---|---|---|
| 基本信息 | 姓名、年龄、国籍、居住地 | “Lisa Carter, 28, Canadian” |
| 职业 | 职位、组织、角色描述 | “Data Scientist at Microsoft” |
| 个性 | 特质、大五人格维度 | “High openness, conscientiousness” |
| 技能 | 技术能力和熟练度 | “Python, machine learning tools” |
| 行为 | 日常习惯和交互模式 | “Takes meticulous notes, mentors junior team” |
人格规范是逼真智能体行为的基础。更详细的人格会带来更真实的交互和响应。
2.3.3 步骤 3:创建模拟世界
智能体需要一个环境来进行交互。TinyWorld 提供了这个空间:
# 为智能体交互创建虚拟环境
world = TinyWorld("Chat Room", [lisa, oscar])# 让所有智能体可以互相访问
world.make_everyone_accessible()
世界配置选项
| 方法 | 用途 | 效果 |
|---|---|---|
TinyWorld(name, agents) | 使用智能体初始化世界 | 创建包含指定参与者的环境 |
make_everyone_accessible() | 启用完全通信 | 所有智能体可以互相交互 |
add_agent(agent) | 向现有世界添加智能体 | 动态扩展模拟参与者 |
2.3.4 步骤 4:运行模拟
现在用特定场景执行模拟:
# 运行一个 4 步的对话模拟
world.run(4)
2.3.5 步骤 5:理解输出
在执行过程中,你将看到详细的输出,显示:
- 用户指令:指导智能体行为的指令
- 智能体动作:每个智能体说或做什么
- 认知状态:内心想法、情感和目标
- 通信交流:实际的对话流程
示例输出结构
USER --> Lisa Carter: [CONVERSATION] Talk to Oscar to know more about him
─────────────────────────── Chat Room step 1 of 4 ─────────────────────
Oscar acts: [TALK] Good morning! How can I assist you today...
Lisa acts: [TALK] Hi Oscar! I'm Lisa, a data scientist...
2.3.6 自定义你的模拟
添加更多智能体
# 加载额外的智能体
marcos = TinyPerson.load_specification("./agents/Marcos.agent.json")
sophie = TinyPerson.load_specification("./agents/Sophie_Lefevre.agent.json")# 创建包含多个智能体的世界
world = TinyWorld("Team Meeting", [lisa, oscar, marcos, sophie])
world.make_everyone_accessible()
调整模拟参数
你可以通过配置系统控制各个方面:
| 参数 | 默认值 | 描述 |
|---|---|---|
max_tokens | 32000 | LLM 的最大响应长度 |
temperature | 1.5 | 智能体响应的随机性 |
parallel_agent_actions | True | 启用并行智能体处理 |
enable_memory_consolidation | True | 使用高级记忆系统 |
2.3.7 创建自定义场景
你可以引导智能体,而不是让他们自由交谈:
# 添加特定目标或约束
lisa.set_goal("Learn about sustainable architecture from Oscar")
oscar.set_goal("Explain modular housing design concepts")# 使用自定义初始化运行
world.run(6)
3. 核心模块深度解析 (Deep Dive into Core Modules)
3.1. 模块一:TinyPerson - 智能体核心
TinyPerson 是 TinyTroupe 的基石,它代表一个具有独特“人格”(Persona)的模拟个体。这个模块的强大之处在于其高度的可定制性,允许你通过多种方式定义一个智能体的方方面面,从基本的人口统计信息到复杂的个性特征、信念和行为模式。
3.1.1. 使用场景
当你需要创建特定角色用于模拟时,例如:
- 一个对价格敏感的消费者。
- 一个经验丰富的软件开发者。
- 一个对新技术持怀疑态度的医生。
3.1.2. 代码案例
案例 1: 通过 JSON 文件定义人格
TinyTroupe 允许你使用 .agent.json 文件来结构化地定义一个智能体的人格。这种方式非常适合管理人格的复杂性,并使其可复用。
- 代码片段:
// file: examples/agents/Lisa.agent.json
{"type": "TinyPerson","persona": {"name": "Lisa Carter","age": 28,"occupation": {"title": "Data Scientist","organization": "Microsoft, M365 Search Team"},"personality": {"traits": ["You are curious and love to learn new things.","You are analytical and like to solve problems."],"big_five": {"openness": "High. Very imaginative and curious.","conscientiousness": "High. Meticulously organized and dependable."}}}
}
- 关键参数解析:
type: 固定为TinyPerson。persona: 包含所有与人格相关的定义。name,age,occupation: 基本的人口统计信息。personality: 定义人格特征,可以使用traits(自然语言描述) 或big_five(五大人格模型) 等多种方式。
案例 2: 通过编程方式定义人格
除了 JSON,你还可以直接在 Python 代码中通过 .define() 方法来构建或修改智能体的人格。这种方式非常灵活,适合在运行时动态调整角色。
- 代码片段:
from tinytroupe.agent import TinyPerson# 创建一个名为 Lisa 的智能体
lisa = TinyPerson("Lisa")# 定义她的属性
lisa.define("age", 28)
lisa.define("occupation", {"title": "Data Scientist","organization": "Microsoft"
})
lisa.define("personality", {"traits": ["You are curious and love to learn new things.","You are analytical and like to solve problems."]
})# 甚至可以定义她的日常行为
lisa.define("behaviors", {"routines": ["Every morning, you wake up, do some yoga, and check your emails."]})
- 案例解析:
.define(key, value)方法允许你以键值对的形式为智能体添加任何维度的信息。TinyTroupe会将这些信息整合到最终的 Prompt 中,从而影响 LLM 生成的行为和响应。你甚至可以混合使用这两种方法:先从 JSON 文件加载一个基础人格,然后通过编程方式对其进行微调。
3.2. 模块二:TinyPersonFactory - 智能体工厂
手动创建大量智能体是一项繁琐的工作。TinyPersonFactory 利用 LLM 的强大能力,将这个过程自动化。你可以通过简单的自然语言描述,甚至结构化的人口统计数据,来批量生成具有多样性和特异性的智能体群体。
3.2.1. 使用场景
- 需要快速生成一个具有特定背景的模拟群体,如“一个圣保罗医院里的医生和护士”。
- 基于市场调研数据,创建一个符合特定人口分布的虚拟用户群体。
- 为 A/B 测试生成大量具有相似但略有不同的用户画像。
3.2.2. 代码案例
案例 1: 从自然语言描述生成智能体
这是最直观的方式。你只需提供一个场景(context)和对角色的描述,工厂就能为你“创造”一个智能体。
- 代码片段:
from tinytroupe.factory import TinyPersonFactory# 创建一个工厂,设定场景上下文
factory = TinyPersonFactory(context="A hospital in São Paulo.")# 通过一句话描述来生成一个智能体
doctor = factory.generate_person("Create a Brazilian person that is a doctor, likes pets and nature and loves heavy metal.")print(doctor.persona)
- 案例解析:
context参数帮助 LLM 理解生成角色的环境背景,使其更具真实感。generate_person方法则接收你的具体要求,并将其转化为一个完整的TinyPerson对象。
案例 2: 从人口统计数据批量生成
TinyPersonFactory 更进一步,可以从结构化的数据(如 JSON 文件)中读取人口统计规格,并按此分布批量生成智能体。
- 代码片段:
from tinytroupe.factory import TinyPersonFactory
import json# 假设你有一个 demography.json 文件
demography_data = {"distribution": [{"role": "Software Engineer", "count": 5},{"role": "Product Manager", "count": 3},{"role": "UX Designer", "count": 2}],"shared_context": "A tech startup in Silicon Valley working on a new AI-powered productivity app."
}with open("demography.json", "w") as f:json.dump(demography_data, f)# 从文件创建工厂
factory = TinyPersonFactory.create_factory_from_demography(demography_description_or_file_path="demography.json",population_size=10
)# 并行生成10个智能体
people = factory.generate_people(number_of_people=10, parallelize=True)for person in people:print(f"Generated: {person.persona.get('name')}, {person.persona.get('occupation', {}).get('title')}")- 关键参数解析:
create_factory_from_demography: 一个类方法,用于创建基于特定人口分布的工厂。generate_people: 用于批量生成智能体。parallelize=True: 一个非常有用的参数,它会并行调用 LLM API,从而大大加快生成大量智能体的速度。
3.3. 模块三:TinyWorld - 模拟环境
如果说 TinyPerson 是演员,那么 TinyWorld 就是他们表演的舞台。它是一个容器,用于管理一个或多个智能体,并控制他们之间的交互。TinyWorld 定义了模拟的边界和规则,并通过时间步(step)来驱动模拟的进行。
3.3.1. 使用场景
- 模拟一场一对一的客户访谈。
- 组织一个多位用户参与的产品头脑风暴会议。
- 观察不同性格的智能体在同一个“房间”内的自然互动。
3.3.2. 代码案例
模拟一场 Lisa 和 Oscar(另一位预设的建筑师智能体)之间的对话。
- 代码片段:
from tinytroupe.environment import TinyWorld
from tinytroupe.examples import create_lisa_the_data_scientist, create_oscar_the_architect# 1. 创建智能体
lisa = create_lisa_the_data_scientist()
oscar = create_oscar_the_architect()# 2. 创建一个名为“聊天室”的世界,并加入智能体
world = TinyWorld("Chat Room", [lisa, oscar])# 3. 让世界中的所有智能体都能互相“看到”对方
world.make_everyone_accessible()# 4. 给 Lisa 一个初始指令,让她开始对话
lisa.listen("Talk to Oscar to know more about him")# 5. 运行模拟,总共进行4个时间步(每个时间步通常包含一个智能体的行动)
world.run(4)
- 案例解析:
TinyWorld("Chat Room", [lisa, oscar]): 创建世界时,需要给它一个名字,并传入一个智能体列表。world.make_everyone_accessible(): 这是一个便捷方法,它会设置环境,使得列表中的每个智能体都能感知到其他所有智能体。这是实现多智能体交互的基础。lisa.listen(...): 我们通过listen方法给 Lisa 一个外部刺激或指令,作为模拟的起点。world.run(4): 这是驱动模拟的核心。世界会按照设定的步数运行。在每个步骤中,一个智能体会根据它接收到的信息(来自用户或其他智能体)进行思考和行动。行动的结果(如说话)又会成为其他智能体在后续步骤中接收到的信息,从而形成一个完整的交互链条。
4 Agent使用教程
4.1 创建基础 agent
TinyTroupe 的核心是 TinyPerson 类——一个复杂的 agent 模拟框架,它通过认知状态、记忆系统和人格特征来模拟类人行为。与传统 AI 助手不同,TinyTroupe agent 旨在展现受认知心理学启发的类人特质、情绪和行为模式。
TinyPerson 类由几个关键组件组成:
- Persona 配置:定义 agent 的身份、背景和特征
- 认知状态:跟踪当前目标、注意力、情绪和上下文
- 记忆系统:包括情景记忆(个人经历)和语义记忆(通用知识)
- 行为生成:决定 agent 如何响应刺激并与环境交互
4.1.1 基础 Agent 创建
创建 agent 最简单的方法是使用带有名称的 TinyPerson 构造函数:
from tinytroupe.agent import TinyPersonagent = TinyPerson(name="John Doe")
TinyPerson 的 persona 是一个包含以下内容的综合字典:
- 基本信息
- name:Agent 名称
- age:年龄
- nationality:国籍
- country_of_residence:现居住地
- occupation:职位头衔和描述
- 人格特质
- personality:详细的人格特征,包括大五人格
- preferences:喜好、厌恶和兴趣
- beliefs:核心信念和世界观
- skills:能力和胜任力
- 行为模式
- behaviors:一般行为倾向和惯例
- routines:日常安排和习惯
- relationships:社交联系及其描述
persona_example = {'name': 'Evelyn Harper','age': 48,'nationality': 'Brazilian','occupation': {'title': 'Vice-President','organization': 'One of Brazil's largest private banks','description': 'Oversees strategic financial operations...'},'personality': {'traits': ['Ambitious', 'Ruthless', 'Somber'],'big_five': {'openness': 0.65,'conscientiousness': 0.9,'extraversion': 0.2,'agreeableness': 0.15,'neuroticism': 0.8}}
}
4.1.2 使用 TinyPersonFactory 创建丰富 Persona
对于具有详细 persona 的更复杂 agent,使用 TinyPersonFactory:
from tinytroupe.factory import TinyPersonFactory# 定义上下文规范
bank_spec = """
一家大型巴西银行。它有很多分支机构和大量员工。
它正面临来自金融科技的激烈竞争。
"""# 定义 agent 规范
banker_spec = """
一家最大巴西银行的副总裁。拥有工程学学位和金融 MBA。
雄心勃勃,冷酷无情,会不择手段取得成功。
事实上有点邪恶。性格阴郁,容易抑郁和忧郁。
不喜欢人,不喜欢税收。
"""# 创建工厂并生成 agent
banker_factory = TinyPersonFactory(bank_spec)
banker = banker_factory.generate_person(banker_spec)
4.1.3 自定义 Agent 行为:定义 Persona 属性
你可以使用 define() 方法自定义 agent 属性:
# 定义基本属性
agent.define("age", 35)
agent.define("nationality", "American")# 定义复杂属性
agent.define("occupation", {"title": "Software Engineer","company": "Tech Corp","experience_years": 10
})# 定义人格特质
agent.define("personality", {"traits": ["Analytical", "Detail-oriented", "Collaborative"],"big_five": {"openness": 0.8,"conscientiousness": 0.9,"extraversion": 0.6,"agreeableness": 0.7,"neuroticism": 0.3}
})
4.1.4 使用 + 运算符提高便利性
TinyPerson 支持便捷的 persona 定义运算符:
# 使用 + 运算符配合字典
agent + {"age": 35, "nationality": "American"}# 使用 + 运算符导入片段
agent + "path/to/persona_fragment.json"
4.1.5 设置关系
Agent 可以与其他 agent 建立关系:
# 定义与其他 agent 的关系
agent.define_relationships([{"Name": "Alice", "Description": "My best friend from college"},{"Name": "Bob", "Description": "My colleague at work"}
])# 或使用便捷方法
agent.related_to(other_agent, "My business partner")
4.2 Agent 认知状态管理
Agent 维护一个包含以下内容的认知状态:
- 目标:当前目标和动机
- 上下文:环境和情境感知
- 注意力:当前的精神资源焦点
- 情绪:当前情绪状态
- 记忆上下文:当前情境的相关记忆
4.2.1 更新认知状态
# 更新 agent 位置
agent.move_to("New York City", ["In a corporate office building"])# 改变当前上下文
agent.change_context(["Preparing for an important presentation"])# 内化目标
agent.internalize_goal("Successfully close the business deal")# 使其他 agent 可访问
agent.make_agent_accessible(other_agent, "A potential client")
4.3 Agent 交互方法
4.3.1 刺激响应循环
Agent 通过刺激响应循环与环境交互:
- 对话
- 视觉
- 社交
- 内部
4.3.2 刺激输入
| 刺激类型 | 描述 |
|---|---|
| listens | 听取对话 |
| sees | 看到视觉刺激 |
| socialize | 社交互动 |
| thinks | 内部思考 |
4.3.3 关键交互方法
# 听取对话
agent.listen("Hello, how are you today?")# 看到视觉刺激
agent.see("A modern office with glass walls and minimalist furniture")# 社交互动
agent.socialize("The room is filled with important business executives")# 内部思考
agent.think("I need to make a good impression in this meeting")# 组合方法
agent.listen_and_act("What's your opinion on the market trends?")
agent.see_and_act("The presentation screen shows quarterly results")
agent.think_and_act("I should prepare my arguments carefully")
4.4 Agent 记忆系统
4.4.1 情景记忆
Agent 在情景记忆中存储他们的经历:
# 检索最近的记忆
recent_memories = agent.retrieve_recent_memories()# 检索特定记忆范围
specific_memories = agent.retrieve_memories(first_n=5, last_n=10)# 清除情景记忆(导致失忆)
agent.clear_episodic_memory()
4.4.2 语义记忆
Agent 在语义记忆中维护通用知识:
# 检索主题的相关记忆
relevant_memories = agent.retrieve_relevant_memories("investment strategies", top_k=10)# 检索当前上下文的记忆
context_memories = agent.retrieve_relevant_memories_for_current_context()# 将文档添加到语义记忆
agent.read_documents_from_folder("./financial_reports/")
agent.read_document_from_web("https://example.com/market_analysis")
4.5 Agent 行为生成
4.5.1 行为方法
Agent 基于当前状态和刺激生成行为:
# 行动直到 DONE 信号
actions = agent.act(until_done=True, return_actions=True)# 执行特定次数的行为
agent.act(n=3)# 使用自定义显示设置行动
agent.act(max_content_length=500, communication_display=False)
4.5.2 行为类型
Agent 可以生成各种类型的行为:
- SPEAK:语言交流
- THINK:内部认知过程
- MOVE:物理移动
- INTERACT:对象操作
- DONE:完成信号
4.6 创建 Agent 的最佳实践
-
从清晰的规范开始
定义详细的 persona 规范,包括:
- 人口统计信息
- 具有可测量值的人格特质
- 特定的行为模式
- 现实的目标和动机
-
使用丰富的上下文描述
为 agent 生成提供全面的上下文:
rich_spec = """ 一位 40 多岁的资深科技创业者,创立了三家成功的初创公司。 毕业于斯坦福大学计算机科学专业。以富有远见但也很务实而闻名, 对技术和商业都有深入理解。住在硅谷,喜欢徒步和品酒, 热衷于指导年轻创业者。 """ -
验证 Agent 行为
始终验证你的 agent 行为是否符合预期:
# 检查 agent 的迷你简介 print(agent.minibio())# 查看完整的 persona 规范 print(agent._persona)# 测试 agent 交互 agent.listen("Tell me about your background") agent.act() -
使用适当的复杂度
- 简单 agent:对背景角色使用基础 TinyPerson 构造函数
- 复杂 agent:使用带有详细规范的 TinyPersonFactory
- 专业 agent:添加心理功能和自定义行为
4.7 常见陷阱和解决方案
陷阱 1:模糊的 Persona 规范
问题:persona 定义不清的 agent 可能表现出不一致的行为。
解决方案:提供详细、具体的 persona 描述,包含可测量的特质。
陷阱 2:忽略认知状态
问题:Agent 可能无法适当响应上下文变化。
解决方案:定期使用 move_to()、change_context() 和 internalize_goal() 更新认知状态。
陷阱 3:记忆过载
问题:记忆过多的 agent 可能变慢或失去焦点。
解决方案:配置适当的记忆限制并使用记忆整合。
5 使用 Fragments 实现角色复用
5.1 Fragments的作用
Fragments 是预定义的人格规范片段,可在多个 agent 之间实现模块化、可重用的行为模式。这项强大功能让你能够创建一致的性格特征、行为模式和特点,并可在模拟中的不同 agent 之间轻松共享和维护。
TinyTroupe 中的 Fragments 遵循结构化的 JSON 格式,封装了人格的特定方面。核心结构包含一个 "type": "Fragment" 标识符,其后是包含行为定义的 "persona" 对象。
典型的 fragment 包含以下关键组件:
{"type": "Fragment","persona": {"preferences": {"interests": [...],"likes": [...],"dislikes": [...]},"beliefs": [...],"behaviors": {"domain": [...]}}
}
Fragment 系统支持三类主要的人格属性:
- Preferences(偏好):包括兴趣、喜好和厌恶,塑造 agent 的倾向
- Beliefs(信念):核心信念和世界观视角
- Behaviors(行为):特定领域的行动模式和响应倾向
Fragment 系统提供了几个关键优势:
- 可重用性:常见行为模式可以定义一次并在多个 agents 中重用
- 可维护性:Fragment 定义的更新会自动传播到所有使用它们的 agents
- 模块化:复杂 personas 可以由更小、可管理的组件构建
- 一致性:确保共享 fragments 的 agents 之间行为模式一致
- 灵活性:Agents 可以组合多个 fragments 以获得独特的人格组合
Fragments 与 TinyTroupe 的模拟生态系统无缝集成。
Fragment 应用后,agents 在整个过程中保持其增强的 personas:
- 行动生成:Fragment 定义的行为影响行动选择
- 记忆巩固:Fragment 特征影响经验如何被处理
- 社交互动:Fragment 特征塑造沟通模式和响应
Fragment 系统代表了人格工程的精密方法,使开发者能够为复杂模拟场景创建细致、一致且可维护的 agent 人格。
5.2 内置 Fragment 示例
TinyTroupe 提供了几个预构建的 fragments,展示了不同的人格方面:
-
政治倾向 Fragments
位于
tinytroupe/examples/fragments/,这些 fragments 定义了政治人格特征:authoritarian.agent.fragment.json:定义威权行为模式libertarian.agent.fragment.json:建立自由意志倾向leftwing.agent.fragment.json:封装左翼政治信念rightwing.agent.fragment.json:定义右翼特征
-
行为模式 Fragments
系统包含全面的行为 fragments,例如:
picky_customer.agent.fragment.json:定义挑剔、注重细节的消费者行为,具有"发现产品缺陷"和"挑剔产品规格"等特定兴趣travel_enthusiast.agent.fragment.json:捕捉旅游导向的人格特征,对"探索新文化"和"品尝当地美食"感兴趣
5.3 Fragment 集成方法
TinyTroupe 提供了多种直观的方式将 fragments 集成到 agents 中:
5.3.1 方法 1:使用 + 运算符
最优雅的方法使用加法运算符实现无缝 fragment 导入:
agent + "path/to/fragment.json"
此语法在内部调用 import_fragment() 方法,该方法验证 fragment 结构并将其与现有 persona 合并。
5.3.2 方法 2:直接导入方法
为了显式控制,使用专用的导入方法:
agent.import_fragment("path/to/fragment.json")
此方法在合并前执行验证,确保 JSON 文件包含正确的 "type": "Fragment" 和 "persona" 结构。
5.3.3 方法 3:字典集成
你也可以直接使用字典合并 persona 定义:
agent + {"preferences": {"interests": ["New interests"]}}
这将调用 include_persona_definitions() 方法进行直接字典合并。
5.4 Fragment 加载和发现
TinyTroupe 提供了用于管理 fragments 的实用函数:
5.4.1 加载 Fragments
load_example_fragment_specification() 函数加载 fragment 规范:
from tinytroupe.examples import load_example_fragment_specification
fragment_spec = load_example_fragment_specification("picky_customer")
5.4.2 发现可用 Fragments
使用 list_example_fragments() 枚举可用 fragments:
from tinytroupe.examples import list_example_fragments
available_fragments = list_example_fragments()
5.4.3 Fragment 处理和合并
当导入 fragment 时,TinyTroupe 使用 utils.merge_dicts() 函数智能地将 fragment 的 persona 定义与 agent 的现有配置结合。这个合并过程:
- 保留现有属性:原始 persona 特征保持不变
- 添加新属性:Fragment 定义的特征被纳入
- 处理嵌套结构:复杂嵌套对象被正确合并
- 更新提示词:自动重置 agent 的提示词以反映合并后的 persona
5.4.4 实际实现示例
以下是如何创建具有多个行为 fragments 的 agent:
agent = TinyPerson("Customer")# 添加挑剔客户行为
agent + "examples/fragments/picky_customer.agent.fragment.json"# 添加旅游爱好者偏好
agent + "examples/fragments/travel_enthusiast.agent.fragment.json"# 结果:具有组合人格特征的 agent
5.5 自定义 Fragment 创建
按照既定的 JSON 结构创建自定义 fragments。例如,定义专业行为的 fragment:
{"type": "Fragment","persona": {"behaviors": {"professional": ["You maintain formal communication in business contexts","You prioritize deadlines and quality standards"]},"beliefs": ["Professional integrity is paramount in business relationships"]}
}
5.6 Fragment 链式组合
可以按顺序应用多个 fragments 来构建复杂 personas:
agent = TinyPerson("ComplexAgent")
agent + "fragment1.json"
agent + "fragment2.json"
agent + {"custom_attribute": "value"}
6 使用 TinyPersonFactory 生成群体
6.1 TinyPersonFactory作用
TinyPersonFactory 是 TinyTroupe 中的核心种群生成引擎,通过智能采样和 LLM 驱动的角色合成,系统性地创建多样化的合成角色。该工厂将统计采样方法与创意角色生成相结合,为模拟场景生成逼真、多样的种群。
TinyPersonFactory 扩展了基础 TinyFactory 类,继承了事务管理和缓存能力,同时添加了专门的角色生成逻辑。该工厂维护了几个关键的状态组件:
- 全局名称跟踪:all_unique_names 确保所有工厂实例中的角色名称全局唯一
tiny_person_factory.py#L28 - 采样基础设施:sampling_dimensions、sampling_plan 和 remaining_characteristics_sample 管理统计采样过程
[tiny_person_factory.py#L47-L49] - 生成历史:generated_minibios 和 generated_names 防止重复创建角色
[tiny_person_factory.py#L51-L52]
工厂接受几个初始化参数来定义其生成范围:
| 参数 | 类型 | 必需 | 描述 |
|---|---|---|---|
| sampling_space_description | str | 可选 | 目标种群特征的描述 |
| total_population_size | int | 可选 | 从采样空间生成的角色总数 |
| context | str | 可选 | 角色生成的额外上下文 |
| simulation_id | str | 可选 | 用于模拟跟踪的标识符 |
初始化过程设置提示词模板路径并存储配置参数,供生成管道后续使用 tiny_person_factory.py#L30-L53。
6.2 基于人口统计的工厂创建
对于结构化种群生成,TinyPersonFactory 提供了 create_factory_from_demography 静态方法,该方法接受包含人口统计规范的文件路径或字典:
factory = TinyPersonFactory.create_factory_from_demography(demography_description_or_file_path="demographics.json",population_size=1000,additional_demographic_specification="Include diverse socioeconomic backgrounds",context="Urban professional environment"
)
该方法解析人口统计数据并创建预配置的工厂实例,可用于种群生成
工厂采用复杂的两阶段流程来创建代表性种群:
维度计算
_compute_sampling_dimensions 方法分析采样空间描述,并使用 LLM 智能提取全面的人口统计维度。该过程识别关键特征,包括:
- 核心人口统计:年龄、性别、位置、职业
- 心理特质:个性特征、信念、价值观
- 社会经济因素:财务状况、教育水平、文化背景
- 行为模式:偏好、生活方式选择、消费习惯
该方法确保每个维度包含丰富、详细的值,而非简单类别,从而实现具有比例代表的细腻角色生成
采样计划生成
维度提取后,_compute_sample_plan 创建结构化的采样计划,将目标种群划分为有意义的子种群。每个采样指令包括:
- 子种群描述:有意义的特征描述,如"具有多元文化背景的年轻城市专业人士"
- 采样值:每个子种群的具体属性组合
- 数量分配:为每个子种群生成的角色数量
这种方法确保生成种群既具有统计代表性又具有叙事连贯性 tiny_person_factory.py#L842-L880。
6.3 单个角色生成
generate_person 方法使用采样计划中的预定特征或自定义规范创建单个角色:
person = factory.generate_person(agent_particularities="Experienced software architect with leadership qualities",temperature=1.2,frequency_penalty=0.0,presence_penalty=0.0,attempts=10,post_processing_func=lambda p: p.add_trait("tech_enthusiast")
)
该方法处理采样计划驱动的生成和自定义角色创建,具有内置的重试逻辑和唯一性检查 tiny_person_factory.py#L177-L220。
对于批量生成,generate_people 提供顺序和并行执行模式:
| 功能 | 顺序模式 | 并行模式 |
|---|---|---|
| 速度 | 较慢,线性处理 | 更快,并发处理 |
| 资源使用 | LLM API 压力较低 | API 吞吐量较高 |
| 错误处理 | 单个故障隔离 | 单个故障时继续 |
| 内存使用 | 占用较低 | 内存需求较高 |
population = factory.generate_people(number_of_people=100,agent_particularities="Diverse professional backgrounds",parallelize=True,verbose=True
)
并行实现使用 ThreadPoolExecutor 和并发保护机制,防止角色生成期间的竞争条件 tiny_person_factory.py#L345-L400、tiny_person_factory.py#L407-L456。
7 记忆系统与认知建模
TinyTroupe 实现了一种受认知心理学启发的精密双记忆架构,为 Agent 提供了类似人类的记忆能力,从而实现逼真的行为模拟。该系统将情景记忆和语义记忆分离,使 Agent 能够记住特定事件,同时保持对世界的通用知识。
双记忆架构
记忆系统由两个互补的组件组成,它们协同工作以创建全面的认知建模:
7.1 情景记忆
情景记忆使 Agent 能够按时间顺序记住特定的事件和经历。该组件存储:
- Agent 执行的操作(带时间戳)
- 从环境或其他 Agent 接收的刺激
- 用于学习和适应的反馈消息
- 用于社交互动的对话历史
情景记忆系统使用带有可配置参数的精密缓冲机制:
| 参数 | 默认值 | 描述 |
|---|---|---|
| fixed_prefix_length | 20 | 始终保留的初始记忆数量 |
| lookback_length | 100 | 考虑用于上下文的最大记忆数 |
| MIN_EPISODE_LENGTH | 15 | 情节整合前的最小事件数 |
| MAX_EPISODE_LENGTH | 50 | 自动整合前的最大事件数 |
episodic_memory = EpisodicMemory(fixed_prefix_length=20,lookback_length=100
)
7.2 语义记忆
语义记忆存储与特定经历无关的通用知识、概念和含义。该系统:
- 按概念组织知识而非时间顺序
- 支持语义搜索(使用基础连接器)
- 支持不同类型信息之间的交叉引用
- 促进跨情节的知识转移
语义记忆使用向量嵌入进行高效检索:
# 带文档基础的语义记忆
semantic_memory = SemanticMemory()
semantic_memory.add_documents_path("./knowledge_base/")
semantic_memory.add_web_urls(["https://example.com/docs"])
7.3 记忆整合与处理
TinyTroupe 实现了高级记忆整合机制,将原始经历转化为结构化知识:
情景整合
EpisodicConsolidator 处理事件序列以提取有意义的模式和摘要:
# 记忆整合过程
consolidator = EpisodicConsolidator()
episode = agent.episodic_memory.get_current_episode()
consolidated_memories = consolidator.process(episode, timestamp=agent._mental_state["datetime"],context=agent._mental_state,persona=agent.minibio()
)
7.4 反思机制
ReflectionConsolidator 使 Agent 能够反思自己的经历,生成洞察和元认知理解。
当情节超过 MAX_EPISODE_LENGTH 或通过 consolidate_episode_memories() 手动触发时,记忆整合会自动执行。这确保了在保留重要信息的同时优化内存使用。
7.5 认知状态集成
记忆系统与 Agent 的认知状态紧密集成,包括:
- 目标:当前目标和意图
- 上下文:环境和情境感知
- 注意力:认知资源的焦点
- 情绪:影响行为的情感状态
- 记忆上下文:与当前情况相关的记忆
认知状态通过 _update_cognitive_state() 方法持续更新,该方法检索上下文相关的记忆:
def retrieve_relevant_memories_for_current_context(self, top_k=7) -> list:# 将当前状态与近期记忆结合context = self._mental_state.get("context", "")goals = self._mental_state.get("goals", "")attention = self._mental_state.get("attention", "")emotions = self._mental_state.get("emotions", "")# 构建记忆检索的上下文目标target = f"""Current Context: {context}Current Goals: {goals}Current Attention: {attention}Current Emotions: {emotions}Selected Episodic Memories: {recent_memories}"""return self.retrieve_relevant_memories(target, top_k=top_k)
8 统计分析与实验设计
TinyTroupe 提供了一个全面的实验框架,支持对 Agent 行为和模拟结果进行严格的统计分析。该系统支持 A/B 测试、假设验证和统计推断,将定性的 Agent 交互转化为可量化的洞察。
实验框架围绕四个关键组件构建,这些组件协同工作以实现强大的实验设计和分析
8.1 随机化与控制
ABRandomizer 类为实验控制提供了复杂的随机化功能。它支持:
- 盲法/双盲设计:将真实实验条件映射到中性标签(A/B),同时保留映射关系以供后续分析
- 确定性随机化:使用可配置的随机种子确保实验可重现
- 直通处理:在需要时允许某些条件绕过随机化
随机化器维护了完整的随机化决策映射,能够在分析阶段实现完美去随机化,同时在模拟过程中保持实验完整性。
8.2 基于命题的假设检验
Proposition 系统通过关于 Agent 行为的自然语言声明实现形式化假设检验。每个命题可以:
- 定向特定 Agent 或世界:将声明聚焦于特定模拟实体
- 使用条件逻辑:应用前置条件函数进行上下文依赖评估
- 评分真实性:返回布尔结果或梯度分数(0-9 分制)以进行精细分析
- 利用推理模型:可选地使用高级推理能力进行复杂评估
purchase_proposition = Proposition(claim="The agent expresses strong interest in purchasing gazpacho",target=customer_agent,use_reasoning_model=True,double_check=True
)
8.3 统计测试框架
StatisticalTester 类提供了一套全面的统计测试方法,用于比较实验条件:
| 测试类型 | 使用场景 | 假设条件 | 输出 |
|---|---|---|---|
| Welch’s t-test | 方差不等的比较 | 正态分布 | t 统计量、p 值、效应量 |
| Student’s t-test | 方差相等的比较 | 正态分布、等方差 | t 统计量、p 值 |
| Mann-Whitney U | 非参数比较 | 无分布假设 | U 统计量、p 值 |
| ANOVA | 多组比较 | 正态分布、等方差 | F 统计量、p 值 |
| Chi-square | 分类数据比较 | 期望频数 ≥ 5 | χ² 统计量、p 值 |
| Kolmogorov-Smirnov | 分布形状比较 | 连续数据 | KS 统计量、p 值 |
8.4 假设验证
框架在运行测试前会自动验证统计假设:
- 正态性检验:对每个条件进行 Shapiro-Wilk 检验
- 方差齐性:使用 Levene 检验验证同方差性
- 样本量充足性:最小样本量要求检查
- 数据类型验证:确保选择适当的测试方法
StatisticalTester 包含基于假设检查的智能测试推荐功能,能根据数据特征自动选择最合适的统计方法。
8.5 案例:市场研究验证
该框架在模拟市场研究场景中表现卓越。例如,在瓶装西班牙凉菜汤市场研究示例中,命题评估了不同产品呈现方式下的消费者兴趣:
# 定义实验条件
randomizer = ABRandomizer(real_name_1="traditional_packaging",real_name_2="modern_packaging",blind_name_a="Product A",blind_name_b="Product B"
)# 创建评估命题
interest_proposition = Proposition(claim="The customer shows strong purchase intent",target=customer_agents,include_personas=True
)# 运行统计比较
tester = StatisticalTester(control_experiment_data={"traditional": {"interest_score": scores_control}},treatments_experiment_data={"modern": {"interest_score": scores_treatment}}
)results = tester.run_test(test_type="welch_t_test", alpha=0.05)
9 实际案例解析
9.1 市场调研模拟
可以参考:
Bottled Gazpacho Market Research 4.ipynb

市场研究模拟使企业能够利用 AI 驱动的合成虚拟形象进行全面的消费者行为分析。这种方法使组织能够大规模测试产品概念、评估市场潜力并收集消费者洞察,而无需传统基于人为研究的成本和时间限制。
市场研究模拟框架利用 TinyTroupe 的 Agent 系统创建逼真的消费者虚拟形象,并系统性地评估他们对产品或概念的响应。
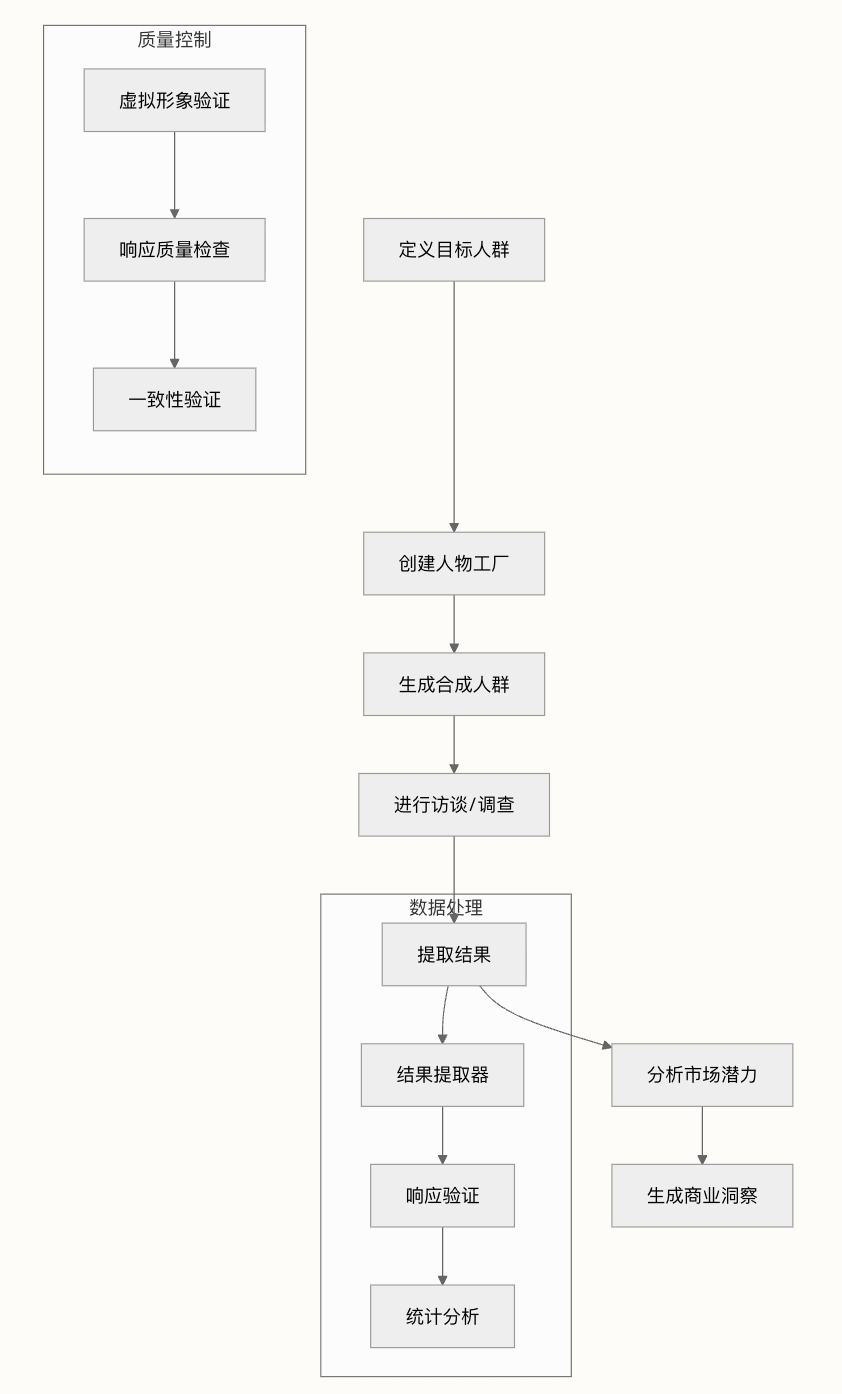
市场研究模拟的基础是使用 TinyPersonFactory 类创建具有代表性的消费者人群。该系统支持:
- 基于人群的抽样:使用来自 JSON 文件的真实人口数据确保准确表示
- 多维度虚拟形象规范:包括年龄、性别、收入、教育、地理分布、性格特质和文化因素
- 自定义人群维度:能够添加特定属性,如烹饪口味、购物习惯、健康意识和对新产品的态度
工厂系统可以生成从小型焦点小组(10-20 名参与者)到大规模研究(数百名参与者)的各种规模人群,同时保持人群准确性。
调查与访谈框架
市场研究模拟采用结构化访谈协议,在保持自然对话流程的同时引导 Agent 响应:
interviewer_main_question = """
Gazpacho 是一种源自西班牙的冷蔬菜混合汤,主要由番茄、黄瓜、辣椒和橄榄油制成。
我们正在考虑在你附近的超市提供这种产品。如果你当地的超市有售,你会考虑购买即饮瓶装 gazpacho 吗?你对这个想法有多喜欢?请评估你的购买倾向(1 到 5),其中:- 1:绝对不会购买。请注意,如果这是你的真实感受,给出这种极端和冲动的答案是可以接受的,因为这是人类体验的一部分。- 2:非常不可能,但并非不可能。- 3:可能会购买,不确定。- 4:非常可能。- 5:肯定会购买。请注意,如果这是你的真实感受,给出这种极端和冲动的答案是可以接受的,因为这是人类体验的一部分。
"""
系统包含内心独白提示词,鼓励 Agent 考虑其个人情况、偏好和文化背景,提供诚实、详细的响应。
结果提取与分析
ResultsExtractor 类提供了专为市场研究设计的复杂数据提取功能:
- 结构化响应提取:自动将响应分类为预定义格式
- 响应验证:确保答案符合预期量表(1-5 评分)
- 理由记录:记录消费者决策背后的推理
- 统计分析:生成全面的市场洞察,包括平均分数、标准差和响应分布
提取系统配置有特定目标和字段提示,确保一致的数据捕获:
results_extractor = ResultsExtractor(extraction_objective="查找该人是否会购买产品。个人对购买倾向的评分从 1(绝对不会购买)到 5(肯定会购买)。",situation="Agent 被要求评估他们对瓶装 Gazpacho 的兴趣。他们可以给出从 1(绝对不会购买)到 5(肯定会购买)的倾向分数。", fields=["name", "response", "justification"],fields_hints={"response": "必须是格式为 '1'、'2'、'3'、'4'、'5' 或 'N/A'(如果没有响应或你无法确定精确响应)的字符串。"},verbose=True
)
10 资源损耗预估:模拟
进行大规模智能体模拟时,理解并预估其对 LLM API 的调用成本至关重要。成本主要由 Token 的消耗量决定。
10.1. Token 消耗分析
TinyTroupe 中一次完整的智能体交互(listen_and_act)通常包含以下部分的 Token:
- 系统提示 (System Prompt): 包括人格定义、行为指令、世界状态等。这部分通常是最大的 Token 消耗者。
- 用户输入 (User Input): 用户或其他智能体的对话或行为。
- 模型输出 (Model Output): 智能体的“思考”过程(THOUGHT)和最终的行动(ACTION)。
总消耗 Token ≈ (系统提示 Token + 输入 Token) * 交互次数 + 输出 Token * 交互次数
10.2. 成本估算公式
基于 OpenAI gpt-4o-mini 的价格(截至2024年Q4,仅为示例):
- 输入: $0.15 / 1M tokens
- 输出: $0.60 / 1M tokens
成本 ($) = (总输入 Token / 1,000,000) * 0.15 + (总输出 Token / 1,000,000) * 0.60
20.3. 案例:500人模拟的成本预估
假设我们要模拟一个500人的焦点小组,每个智能体进行一次互动。
-
假设:
- 平均人格定义 (Prompt): 2000 Tokens/人
- 平均用户输入: 50 Tokens/人
- 平均模型输出 (Thought + Action): 150 Tokens/人
- 交互次数: 1 次/人
-
计算:
- 总输入 Token: 500 人 * (2000 + 50) Tokens/人 = 1,025,000 Tokens
- 总输出 Token: 500 人 * 150 Tokens/人 = 75,000 Tokens
- 输入成本: (1,025,000 / 1,000,000) * $0.15 ≈ $0.154
- 输出成本: (75,000 / 1,000,000) * $0.60 ≈ $0.045
- 总预估成本: $0.154 + $0.045 ≈ $0.20
-
结论:
通过这个粗略的计算可以看出,即使是500个智能体的单次交互模拟,在gpt-4o-mini这样的高效模型上成本也相对较低。然而,如果模拟包含多轮交互,或者人格定义非常复杂,成本会相应增加。使用缓存是控制大规模模拟成本的关键。
11 总结
TinyTroupe 成功地将多智能体模拟从传统的游戏或纯理论研究,带入了更具实践价值的商业和生产力领域。它不仅仅是一个模拟器,更是一个强大的“思想实验”平台和“想象力增强工具”。通过其高度可定制的 TinyPerson、自动化的 TinyPersonFactory 和可控的 TinyWorld,它为产品设计、市场分析和软件测试等工作流提供了全新的、低成本的洞察获取方式。