【算法笔记 10】贪心策略五
承接上文,这部分的内容包含划分型贪心、先枚举,再贪心、交换论证法、相邻不同。还有一个反悔贪心,等到后面刷完堆之后给大家补上。这样,我们的贪心策略这一块就结束了,接下来是区间贪心。
五、划分型贪心
把数组/字符串划分成满足要求的若干段,最小化/最大化划分的段数。
思考方法同上篇文章,尝试从左到右/从右到左贪心。
例题1 — 2405.子字符串的最优划分
给你一个字符串 s ,请你将该字符串划分成一个或多个 子字符串 ,并满足每个子字符串中的字符都是 唯一 的。也就是说,在单个子字符串中,字母的出现次数都不超过 一次 。
满足题目要求的情况下,返回 最少 需要划分多少个子字符串。
注意,划分后,原字符串中的每个字符都应该恰好属于一个子字符串。
示例 1:
输入:s = "abacaba"
输出:4
解释:
两种可行的划分方法分别是 ("a","ba","cab","a") 和 ("ab","a","ca","ba") 。
可以证明最少需要划分 4 个子字符串。
示例 2:
输入:s = "ssssss"
输出:6
解释:
只存在一种可行的划分方法 ("s","s","s","s","s","s") 。
提示:
1 <= s.length <= 105s仅由小写英文字母组成
class Solution:def partitionString(self, s: str) -> int:cnt = 1ans = []for i in s:if i not in ans:ans.append(i)else:cnt += 1ans = [i]return cnt#思路
这是一道基础的例题,主要给大家了解一下基本题型,没什么难度。大概的思路就是在遍历数组的同时维护一个始终只有单一元素的子数组即可,在更新的时候计数。但是有几个细节点要注意一下。
细节1:答案计数要从1开始,因为在第一次划分的时候,实际上是有两个数组的,即第一个else时得到的cnt应该要是2才对。
细节2:当进入else时,这时的i进入原本的子数组导致不符合条件,所以这个i不能被算到原子数组,而是要算在新的数组,所以ans不能被更新为[ ].
例题2 — 2522.将字符串分割成值不超过k的子字符串
给你一个字符串 s ,它每一位都是 1 到 9 之间的数字组成,同时给你一个整数 k 。
如果一个字符串 s 的分割满足以下条件,我们称它是一个 好 分割:
s中每个数位 恰好 属于一个子字符串。- 每个子字符串的值都小于等于
k。
请你返回 s 所有的 好 分割中,子字符串的 最少 数目。如果不存在 s 的 好 分割,返回 -1 。
注意:
- 一个字符串的 值 是这个字符串对应的整数。比方说,
"123"的值为123,"1"的值是1。 - 子字符串 是字符串中一段连续的字符序列。
示例 1:
输入:s = "165462", k = 60 输出:4 解释:我们将字符串分割成子字符串 "16" ,"54" ,"6" 和 "2" 。每个子字符串的值都小于等于 k = 60 。 不存在小于 4 个子字符串的好分割。
示例 2:
输入:s = "238182", k = 5 输出:-1 解释:这个字符串不存在好分割。
提示:
1 <= s.length <= 105s[i]是'1'到'9'之间的数字。1 <= k <= 109
class Solution:def minimumPartition(self, s: str, k: int) -> int:n = len(s)arr = []cnt = 1temp = ''for i in range(n):if int(s[i]) > k:return -1temp += s[i]if int(temp) > k:cnt += 1temp = s[i]return cnt#思路
这题没什么难度,也是做个例题给大家看看,增加点手感和信心。只要按照题目的要求,通过记录子字符串来做判断即可。
判断点:如果单个字符的值大于规定值,那就肯定没法分,直接返回-1即可。
例题3 — 3557.不相交子字符串的最大数量
给你一个字符串 word。
返回以 首尾字母相同 且 长度至少为 4 的 不相交子字符串 的最大数量。
子字符串 是字符串中连续的 非空 字符序列。
示例 1:
输入: word = "abcdeafdef"
输出: 2
解释:
两个子字符串是 "abcdea" 和 "fdef"。
示例 2:
输入: word = "bcdaaaab"
输出: 1
解释:
唯一的子字符串是 "aaaa"。注意我们 不能 同时选择 "bcdaaaab",因为它和另一个子字符串有重叠。
提示:
1 <= word.length <= 2 * 105word仅由小写英文字母组成。
错误示范:
class Solution:def maxSubstrings(self, word: str) -> int:n = len(word)ans = ''cnt = 0for i in range(n):if ans == '' or ans[0] != word[i]:ans += word[i]continueif ans[0] == word[i] and len(ans) >= 3:cnt += 1ans = ''elif ans[0] == word[i] and len(ans) <3:ans += word[i]return cnt正确示范:
class Solution:def maxSubstrings(self, word: str) -> int:ans = 0pos = {}for i, ch in enumerate(word):if ch not in pos: # 之前没有遇到pos[ch] = ielif i - pos[ch] > 2: # 再次遇到,且子串长度 >= 4ans += 1# 找下一个子串pos.clear()return ans#思路
这题就和上面两题不一样了,难度不是一个级别的,如果你是按照顺序刷下来可能一下子还反应不过来。这题虽然说条件也很简单,只要首位字母相同并且长度大于4就符合条件。但是会有几个坑导致难度直线上升。
首先,如果你接着用子字符串作为中间量,当原始字符串为aabbbb这样的时候,就会返回0而不是1,因为aa一直占用。如果你想改进一下,用字典来记录,让每类字母都去便利,那也不行,比如abcdeafdef,会返回4而不是2。我还没有想到比较好的解决办法。因为你写到这就会发现,已经不是贪心了,你已经开始找全局最优解了,那这就肯定不对了。(如本题代码一)并且对于这个例子,如果不用贪心的思想,会非常的麻烦,你如果去找全局最优,会发现取d或者e只能得到一个答案,这个时候往往你就懵了,会去想这题怎么这么复杂,有这么多情况,到这里你就已经走远了。
这题是属于贪心的题目,去考虑全局最优解要么解不出来,要么很耗费资源。所以用字典来记录所有字符类别的子串长肯定是不行的。最大的坑就在这,这时候你就会否定用字典这个办法,但是这又恰好就是答案之一。其实我们不需要用字典去记录所有字符的所有位置,并用这些位置去计算求解,我们只要记录所有字符的上一个位置就行。然后在遍历的时候去计算对应的字符,这样就做到一次便利完所有字符的可能子串。
想一想,第一个(最左边的)子串选哪个最好?
贪心地想,这个子串的右端点越小越好,这样后面能选的子串就越多。
选了右端点为 i 的子串后,问题变成从 [i+1,n−1] 中能选多少个子串,这是一个和原问题相似,规模更小的子问题。可以递归/迭代解决。
算法实现:
遍历 word,同时用 pos[ch] 记录字母 ch=word[i] 首次出现的位置。
如果 ch 首次出现,那么记录下标,即 pos[ch]=i。
否则,如果子串长度 ≥4,即 i−pos[ch]+1≥4,即 i−pos[ch]>2,那么找到了一个右端点尽量小的子串,答案加一。然后把 pos 重置,继续寻找下一个子串。
这题强烈建议大家自己写一下,很有意思,有些报错或者坑只有你自己去写才感受的到。(实话实说,作者这题来来回回27次才想明白,一但走远了真的很难把自己的思维扶正,太痛苦了)
六、先枚举再贪心
枚举题目的其中一个变量,将其视作已知条件,然后在此基础上贪心。
也可以枚举答案,检查是否可以满足要求。(类似二分答案)
例题4 — 2171.拿出最少数目的魔法豆
给定一个 正整数 数组 beans ,其中每个整数表示一个袋子里装的魔法豆的数目。
请你从每个袋子中 拿出 一些豆子(也可以 不拿出),使得剩下的 非空 袋子中(即 至少还有一颗 魔法豆的袋子)魔法豆的数目 相等。一旦把魔法豆从袋子中取出,你不能再将它放到任何袋子中。
请返回你需要拿出魔法豆的 最少数目。
示例 1:
输入:beans = [4,1,6,5] 输出:4 解释: - 我们从有 1 个魔法豆的袋子中拿出 1 颗魔法豆。剩下袋子中魔法豆的数目为:[4,0,6,5] - 然后我们从有 6 个魔法豆的袋子中拿出 2 个魔法豆。剩下袋子中魔法豆的数目为:[4,0,4,5] - 然后我们从有 5 个魔法豆的袋子中拿出 1 个魔法豆。剩下袋子中魔法豆的数目为:[4,0,4,4] 总共拿出了 1 + 2 + 1 = 4 个魔法豆,剩下非空袋子中魔法豆的数目相等。 没有比取出 4 个魔法豆更少的方案。
示例 2:
输入:beans = [2,10,3,2] 输出:7 解释: - 我们从有 2 个魔法豆的其中一个袋子中拿出 2 个魔法豆。剩下袋子中魔法豆的数目为:[0,10,3,2] - 然后我们从另一个有 2 个魔法豆的袋子中拿出 2 个魔法豆。剩下袋子中魔法豆的数目为:[0,10,3,0] - 然后我们从有 3 个魔法豆的袋子中拿出 3 个魔法豆。剩下袋子中魔法豆的数目为:[0,10,0,0] 总共拿出了 2 + 2 + 3 = 7 个魔法豆,剩下非空袋子中魔法豆的数目相等。 没有比取出 7 个魔法豆更少的方案。
提示:
1 <= beans.length <= 1051 <= beans[i] <= 105
class Solution:def minimumRemoval(self, beans: List[int]) -> int:cnt = 0arr = sorted(beans)n = len(beans)for i in range(n):if i > 0 and arr[i] == arr[i - 1]:continue #如果有重复的数就跳过不重复计算,小优化,就快一点点temp = arr[i] * (n - i)cnt = max(cnt, temp)return sum(beans) - cnt#思路
这题其实也是一个思路上的转变,如果直接去求解要拿走多少豆子,要两层循环,非常麻烦,并且第48个测试点是过不去的,一定会超时。这个时候往往就要转换一下思路了。我们一起思考,如果我贪心的想要拿走最少的豆子,直接去算这个数,已经走不通,那是不是可以考虑换一种思路。还有什么方式可以变相的算出这个值?可以想到,原本的豆子数 = 拿走的+剩余的。原本的豆子数是固定的,那么我们只要剩余的豆子数最大,那拿走的就最小就好。
我们可以将 beans 从小到大排序后,枚举最终非空袋子中魔法豆的数目 v,将小于 v 的魔法豆全部清空(即前面的数都可以不要考虑),大于 v 的魔法豆减少至 v,这样所有非空袋子中的魔法豆就都相等了。
由于拿出魔法豆 + 剩余魔法豆 = 初始魔法豆之和,我们可以考虑最多能剩下多少个魔法豆,从而计算出最少能拿出多少个魔法豆。
并且我们可以发现,这样去算的话只要便利一次就够了,非常的快速。
例题5 — 3085.成为K特殊字符串需要删除的最少字符数
给你一个字符串 word 和一个整数 k。
如果 |freq(word[i]) - freq(word[j])| <= k 对于字符串中所有下标 i 和 j 都成立,则认为 word 是 k 特殊字符串。
此处,freq(x) 表示字符 x 在 word 中的出现频率,而 |y| 表示 y 的绝对值。
返回使 word 成为 k 特殊字符串 需要删除的字符的最小数量。
示例 1:
输入:word = "aabcaba", k = 0
输出:3
解释:可以删除 2 个 "a" 和 1 个 "c" 使 word 成为 0 特殊字符串。word 变为 "baba",此时 freq('a') == freq('b') == 2。
示例 2:
输入:word = "dabdcbdcdcd", k = 2
输出:2
解释:可以删除 1 个 "a" 和 1 个 "d" 使 word 成为 2 特殊字符串。word 变为 "bdcbdcdcd",此时 freq('b') == 2,freq('c') == 3,freq('d') == 4。
示例 3:
输入:word = "aaabaaa", k = 2
输出:1
解释:可以删除 1 个 "b" 使 word 成为 2特殊字符串。因此,word 变为 "aaaaaa",此时每个字母的频率都是 6。
提示:
1 <= word.length <= 1050 <= k <= 105word仅由小写英文字母组成。
class Solution:def minimumDeletions(self, word: str, k: int) -> int:counts = Counter(word)if len(counts) <= 1:return 0 # 如果只有一种或没有字符,不需要删除freqs = sorted(counts.values())# 正确初始化用于寻找最小值的变量min_deletions = float('inf')# 优化循环。我们不需要测试所有可能的中心点,# 只需要测试以每个现有频率作为“保留区间”的下限即可。for base_freq in freqs:current_deletions = 0# 遍历所有频率,计算将它们调整到 [base_freq, base_freq + k] 区间的成本for freq in freqs:if freq < base_freq:# 这个频率太小了,在保留区间之下,必须全部删除current_deletions += freqelif freq > base_freq + k:# 这个频率太大了,在保留区间之上,删除超出的部分current_deletions += freq - (base_freq + k)# 如果 base_freq <= freq <= base_freq + k,则它在区间内,成本为0# 更新全局的最小删除数min_deletions = min(min_deletions, current_deletions)return min_deletions
#思路
这题和上题有一点像,但又不完全一样。上题是去遍历求最大的剩余,这题可以通过优化循环,求解最小的删除。我们可以先用字典取得每个字符的具体数量,然后再把它们数组化。因为我们并不需要知道具体的字母是什么。然后去在这个数组里面去寻找一个最合适的范围。由题目我们可以得出以下规则:
对于任何一个原始频率 f_j,它对总删除成本的贡献是:
- 如果
f_j < b,成本是f_j。(因为它在区间之下,必须全部删除) - 如果
f_j > b+k,成本是f_j - (b+k)。(因为它在区间之上,删除多余部分) - 如果
b <= f_j <= b+k,成本是0。(它在区间之内)
这些就是循环的判断逻辑。
细节——这里给大家证明一个优化点:即为什么我们不用去遍历所有可能的数从而找到一个最佳的范围。
假设我们找到了一个最优解,它对应的保留区间是 [b, b+k],产生了最小的删除数 D_optimal。
现在,我们考虑将这个最优区间的下界 b 向上移动一点点,得到一个新区间 [b', b'+k],其中 b' = b + ε (ε 是一个很小的正数,确保 b' 仍然小于下一个原始频率)。
让我们看看这个移动对总删除成本 D 的影响:
-
对于
f_j < b的频率:- 在旧区间
[b, b+k]中,成本是f_j。 - 在新区间
[b', b'+k]中,由于f_j < b < b',它仍然在区间之下,成本仍然是f_j。 - 成本变化:0
- 在旧区间
-
对于
b <= f_j <= b+k的频率:- 在旧区间中,成本是
0。 - 在新区间中,由于我们假设了在
(f_i, b]之间没有原始频率,那么对于所有f_j >= b,也必然有f_j >= b'。所以它们仍然在新区间内(或之上)。 - 成本变化:0 (暂时这么认为,我们稍后处理上界)
- 在旧区间中,成本是
-
对于
f_j > b+k的频率:- 在旧区间中,成本是
f_j - (b+k)。 - 在新区间中,成本是
f_j - (b'+k) = f_j - (b+ε+k) = (f_j - (b+k)) - ε。 - 成本变化:-ε。成本减少了!
- 在旧区间中,成本是
初步结论:当我们将 b 稍微向上移动时,对于所有情况,总删除成本 D 要么不变,要么减少。
既然向上移动 b 不会使成本增加,我们可以一直向上移动它,直到它碰到下一个“障碍物”。这个障碍物是什么?
就是下一个原始频率!
我们可以将 b 一直增加到 b = f_{i+1}(其中 f_{i+1} 是 freqs 中大于 f_i 的下一个频率)。在这个过程中,总删除成本 D 一直在减小或保持不变。
当 b 到达 f_{i+1} 时,我们得到了一个新的保留区间 [f_{i+1}, f_{i+1}+k],它的总删除成本 D' 小于或等于 我们最初假设的那个最优成本 D_optimal。
- 我们从一个假设的、下界
b不是原始频率的最优解出发。 - 我们证明了可以将这个下界
b移动到一个原始频率f_{i+1}上,而删除成本不会增加(甚至可能减少)。 - 这意味着,由新区间
[f_{i+1}, f_{i+1}+k]产生的解,至少和我们假设的那个“最优解”一样好,甚至更好。
因此,任何一个可能的最优解,都可以被一个“其保留区间下界是一个原始频率”的解所代替。我们根本不需要去检查那些“悬在空中”的下界 b。
例题6 — 1727.重新排列后的最大子矩阵
给你一个二进制矩阵 matrix ,它的大小为 m x n ,你可以将 matrix 中的 列 按任意顺序重新排列。
请你返回最优方案下将 matrix 重新排列后,全是 1 的子矩阵面积。
示例 1:
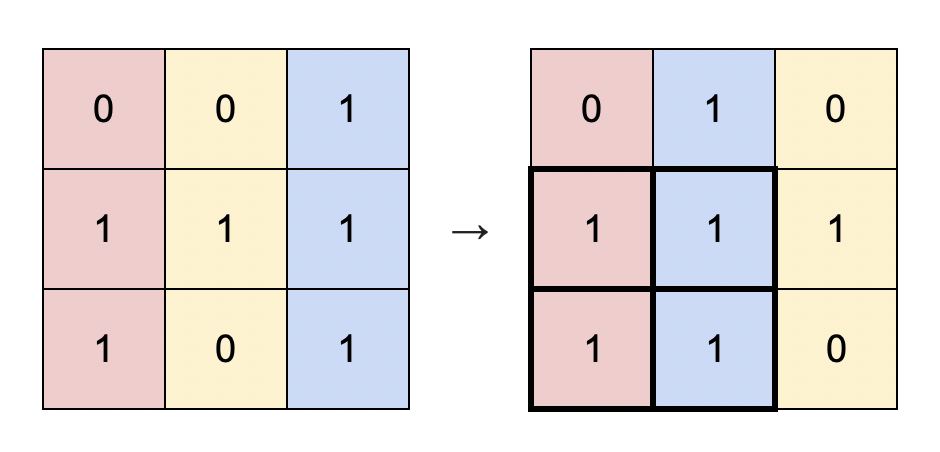
输入:matrix = [[0,0,1],[1,1,1],[1,0,1]] 输出:4 解释:你可以按照上图方式重新排列矩阵的每一列。 最大的全 1 子矩阵是上图中加粗的部分,面积为 4 。
示例 2:

输入:matrix = [[1,0,1,0,1]] 输出:3 解释:你可以按照上图方式重新排列矩阵的每一列。 最大的全 1 子矩阵是上图中加粗的部分,面积为 3 。
示例 3:
输入:matrix = [[1,1,0],[1,0,1]] 输出:2 解释:由于你只能整列整列重新排布,所以没有比面积为 2 更大的全 1 子矩形。
示例 4:
输入:matrix = [[0,0],[0,0]] 输出:0 解释:由于矩阵中没有 1 ,没有任何全 1 的子矩阵,所以面积为 0 。
提示:
m == matrix.lengthn == matrix[i].length1 <= m * n <= 105matrix[i][j]要么是0,要么是1。
class Solution:def largestSubmatrix(self, matrix: List[List[int]]) -> int:m = len(matrix)n = len(matrix[0])res = 0for i in range(1,m):for j in range(n):if(matrix[i][j] == 1):matrix[i][j] += matrix[i-1][j]for i in range(m):matrix[i].sort(reverse=True)for j in range(n):res = max(res,matrix[i][j] * (j+1))return res#思路
这题挺难的,我给大家找了个优质题解讲讲。只能是说多写多练吧,练过了下次就知道要用这个方法了。
- 首先计算每列连续1的前缀和:
- 对于每一行,计算从该行开始向上连续的 1 的个数(也就是计算面积的高度)。
- 以题目给出的矩阵为例子:
| 0 | 0 | 1 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
- 计算每一列的前缀和之后如下:
| 0 | 0 | 1 |
| 1 | 1 | 2 |
| 2 | 0 | 3 |
- 对每一行按照从大到小进行降序排序,目的是让较高的列尽可能靠左,从而最大化全 1 子矩阵的面积。,如下:
| 1 0 0 2 1 1 3 2 0 |
- 最后计算最大面积:
- 对于每一行,遍历排序后的高度数组,计算以当前高度为高的最大矩形面积。
- 面积公式为:面积 = 高度 * 宽度,其中宽度是当前列的索引下标加 1。
细节:
1、这里通过每行的前缀和去排序是可以的。因为一列中只要有一个数排在比如位置x,那其他的数也会在这里,所以其实也是按列移动。如果这列的其他数要在x-1或者x+1的位置,是不可能的,因为每列是累加关系,前面大后面也会大,前面小后面也会小,大家可以尝试一下看看能不能找出反例。
2、由于前缀和的计算是逐步加一,所以如果后面的列有的数前面的列一定会有,所以我们可以直接用索引去乘前缀和。
如果还是有看不懂的可以评论区打出,我看到就会回复。
七、交换论证法
交换论证法(exchange argument)用于证明一类贪心算法的正确性,也可以用来启发思考。做法如下:
对于题目,猜想按照「某种顺序」处理数据,可以得到最优解。
交换顺序中的两个元素 ai和 aj,计算交换后的答案。
对比交换前后的答案。如果交换后,答案没有变得更优,则说明猜想成立。
也可以不用猜想,而是计算「先 a i 后 a j」和「先 a j 后 a i」对应的答案,通过比较两个答案谁更优,来确定按照何种顺序处理数据。
例题7 — 2895.最小处理时间
你有 n 颗处理器,每颗处理器都有 4 个核心。现有 n * 4 个待执行任务,每个核心只执行 一次 任务。
给你一个下标从 0 开始的整数数组 processorTime ,表示每颗处理器最早空闲时间。另给你一个下标从 0 开始的整数数组 tasks ,表示执行每个任务所需的时间。返回所有任务都执行完毕需要的 最小时间 。
注意:每个核心独立执行任务。
示例 1:
输入:processorTime = [8,10], tasks = [2,2,3,1,8,7,4,5] 输出:16 解释: 最优的方案是将下标为 4, 5, 6, 7 的任务分配给第一颗处理器(最早空闲时间 time = 8),下标为 0, 1, 2, 3 的任务分配给第二颗处理器(最早空闲时间 time = 10)。 第一颗处理器执行完所有任务需要花费的时间 = max(8 + 8, 8 + 7, 8 + 4, 8 + 5) = 16 。 第二颗处理器执行完所有任务需要花费的时间 = max(10 + 2, 10 + 2, 10 + 3, 10 + 1) = 13 。 因此,可以证明执行完所有任务需要花费的最小时间是 16 。
示例 2:
输入:processorTime = [10,20], tasks = [2,3,1,2,5,8,4,3] 输出:23 解释: 最优的方案是将下标为 1, 4, 5, 6 的任务分配给第一颗处理器(最早空闲时间 time = 10),下标为 0, 2, 3, 7 的任务分配给第二颗处理器(最早空闲时间 time = 20)。 第一颗处理器执行完所有任务需要花费的时间 = max(10 + 3, 10 + 5, 10 + 8, 10 + 4) = 18 。 第二颗处理器执行完所有任务需要花费的时间 = max(20 + 2, 20 + 1, 20 + 2, 20 + 3) = 23 。 因此,可以证明执行完所有任务需要花费的最小时间是 23 。
提示:
1 <= n == processorTime.length <= 250001 <= tasks.length <= 1050 <= processorTime[i] <= 1091 <= tasks[i] <= 109tasks.length == 4 * n
class Solution:def minProcessingTime(self, processorTime: List[int], tasks: List[int]) -> int:tasks.sort(reverse = True)processorTime.sort()n = len(processorTime)cnt = 0for i in range(n):temp = processorTime[i] + tasks[4 * i]cnt = max(cnt, temp)return cnt#思路
这题也是一道简单的例题,贪心思路就是,最早开始的处理器去处理耗时最长的任务。具体证明如下。
一颗处理器完成它的 4 个任务,完成的时间取决于这 4 个任务中的 tasks 的最大值。
直觉上来说,处理器的空闲时间越早,应当处理 tasks 越大的任务;处理器的空闲时间越晚,应当处理 tasks 越小的任务。
采用交换论证(exchange argument)证明。
对于两个最早空闲时间分别为 p1和 p2的处理器,不妨设 p1≤p2。完成的 4 个任务中的最大值分别为 t1和 t2,不妨设 t1≤t2 。
如果 t1给 p1,t2给 p2,那么最后完成时间max(p1+t1,p2+t2)=p2+t2
如果 t1给 p2,t2给 p1,那么最后完成时间为max(p1+t2,p2+t1)≤max(p2+t2,p2+t2)=p2+t2
上式表明,处理器的空闲时间越早,应当处理 tasks 越大的任务;处理器的空闲时间越晚,应当处理 tasks 越小的任务。
我们可以把 processorTime 从小到大排序,tasks 从大到小排序,那么答案就是processorTime[i]+tasks[4i]的最大值。
细节:注意所有处理器的核心都是独立工作的,所以最后工作时长不是累加而是取最大值!
例题8 — 3457.吃披萨
给你一个长度为 n 的整数数组 pizzas,其中 pizzas[i] 表示第 i 个披萨的重量。每天你会吃 恰好 4 个披萨。由于你的新陈代谢能力惊人,当你吃重量为 W、X、Y 和 Z 的披萨(其中 W <= X <= Y <= Z)时,你只会增加 1 个披萨的重量!体重增加规则如下:
- 在 奇数天(按 1 开始计数)你会增加
Z的重量。 - 在 偶数天,你会增加
Y的重量。
请你设计吃掉 所有 披萨的最优方案,并计算你可以增加的 最大 总重量。
注意:保证 n 是 4 的倍数,并且每个披萨只吃一次。
示例 1:
输入: pizzas = [1,2,3,4,5,6,7,8]
输出: 14
解释:
- 第 1 天,你吃掉下标为
[1, 2, 4, 7] = [2, 3, 5, 8]的披萨。你增加的重量为 8。 - 第 2 天,你吃掉下标为
[0, 3, 5, 6] = [1, 4, 6, 7]的披萨。你增加的重量为 6。
吃掉所有披萨后,你增加的总重量为 8 + 6 = 14。
示例 2:
输入: pizzas = [2,1,1,1,1,1,1,1]
输出: 3
解释:
- 第 1 天,你吃掉下标为
[4, 5, 6, 0] = [1, 1, 1, 2]的披萨。你增加的重量为 2。 - 第 2 天,你吃掉下标为
[1, 2, 3, 7] = [1, 1, 1, 1]的披萨。你增加的重量为 1。
吃掉所有披萨后,你增加的总重量为 2 + 1 = 3。
提示:
4 <= n == pizzas.length <= 2 * 1051 <= pizzas[i] <= 105n是 4 的倍数。
class Solution:def maxWeight(self, pizzas: List[int]) -> int:pizzas.sort(reverse = True)n = len(pizzas) // 4m = 0if n % 2 == 0:m = n // 2else:m = n // 2 + 1left = mcnt = sum(pizzas[:m])i = n - mwhile i > 0:cnt += pizzas[left + 1]left += 2i -= 1return cnt#思路
这披萨其实前面吃过一次哈,这里带着大家再吃一次。因为在1.1 从最小/最大开始贪心那个时候还没有说到交换论证法,所以并没有对我们的思路进行证明。
这里简单说一下思路,我们不需要去考虑怎么选取后面的数,因为数组长度永远是符合条件的。我们需要考虑的只有后两个数,我们要在每天都贪心的取到最大。可能有人看了例子会想,这题很简单啊,只要按顺序照着题意遍历去取值不就好了,但实际上并非如此,大家可以看看‘[5,2,2,4,3,3,1,3,2,5,4,2]’这个例子,如果按照上面这个思路答案是13,而正解是14.
但其实这题也没有这么复杂,你从这个这个例子可以发现,我们只要奇数天都连续取最大,然后再来算偶数天的值即可。像这样:选选选跳选跳选
用交换论证法可以证明这是最优的。比如交换第二个奇数天和最后一个偶数天,也就是按照「奇偶奇偶奇」的方法选,那么选择方案为:选跳选选跳选选
对比可以发现,本质上这个交换把后面的一个跳插入到了前面的某个位置中,于是这两个位置之间的所有「选」的下标都向后移动了一位,所以这个方案的元素和一定不会比交换前的优。
亦或者可以说,按照我们的取法,前面几个最大值都会被取到,但如果交换的话,会取到后面的一个小的值而前面会少一个大的值(因为偶数天只能跳着取)
例题9 — 1665.完成所有任务的最少初始能量(困难)
给你一个任务数组 tasks ,其中 tasks[i] = [actuali, minimumi] :
actuali是完成第i个任务 需要耗费 的实际能量。minimumi是开始第i个任务前需要达到的最低能量。
比方说,如果任务为 [10, 12] 且你当前的能量为 11 ,那么你不能开始这个任务。如果你当前的能量为 13 ,你可以完成这个任务,且完成它后剩余能量为 3 。
你可以按照 任意顺序 完成任务。
请你返回完成所有任务的 最少 初始能量。
示例 1:
输入:tasks = [[1,2],[2,4],[4,8]] 输出:8 解释: 一开始有 8 能量,我们按照如下顺序完成任务:- 完成第 3 个任务,剩余能量为 8 - 4 = 4 。- 完成第 2 个任务,剩余能量为 4 - 2 = 2 。- 完成第 1 个任务,剩余能量为 2 - 1 = 1 。 注意到尽管我们有能量剩余,但是如果一开始只有 7 能量是不能完成所有任务的,因为我们无法开始第 3 个任务。
示例 2:
输入:tasks = [[1,3],[2,4],[10,11],[10,12],[8,9]] 输出:32 解释: 一开始有 32 能量,我们按照如下顺序完成任务:- 完成第 1 个任务,剩余能量为 32 - 1 = 31 。- 完成第 2 个任务,剩余能量为 31 - 2 = 29 。- 完成第 3 个任务,剩余能量为 29 - 10 = 19 。- 完成第 4 个任务,剩余能量为 19 - 10 = 9 。- 完成第 5 个任务,剩余能量为 9 - 8 = 1 。
示例 3:
输入:tasks = [[1,7],[2,8],[3,9],[4,10],[5,11],[6,12]] 输出:27 解释: 一开始有 27 能量,我们按照如下顺序完成任务:- 完成第 5 个任务,剩余能量为 27 - 5 = 22 。- 完成第 2 个任务,剩余能量为 22 - 2 = 20 。- 完成第 3 个任务,剩余能量为 20 - 3 = 17 。- 完成第 1 个任务,剩余能量为 17 - 1 = 16 。- 完成第 4 个任务,剩余能量为 16 - 4 = 12 。- 完成第 6 个任务,剩余能量为 12 - 6 = 6 。
提示:
1 <= tasks.length <= 1051 <= actuali <= minimumi <= 104
class Solution:def minimumEffort(self, tasks: List[List[int]]) -> int:# 正确的逻辑tasks.sort(key=lambda x: x[1] - x[0]) # 按差值升序排序ans = 0for actual, minimum in tasks:ans = max(ans + actual, minimum)return ans
#思路
这题就很有感觉了,好像是在考数学。我们贪心的要最少的初始能量,如何求解呢?由示例1可以看出,最少能量至少要大于最大的要求能量。这个是下限,上线就是要求值的和。这个范围显然很大,那么我们要如何去求解一个最合适的值呢?如果你写过前面我的笔记的题肯定会想到二分,但是这就有个问题,二分是有序的变化答案,即我们知道往左往右的值的变化是什么,这是建立在数组有序的基础上。那原始的数组肯定是无序的,这个时候可能我们还可以反过来想,我们去求解答案下限和最佳值的差值,但这也建立在遍历的基础上,如果我们的排序顺序不知道,那么我们就无法通过这些方法去求解。即如果找不到正确的排序,我们的贪心不一定会是最贪心。所以无论是二分还是正常循环求解,都跑不掉对一个贪心结论的掌握,也就是我们的排序逻辑。
考虑两个任务的能量组合任务1为[a1,m1]与任务2为[a2,m2]
则先做任务1再做任务2的最小初始能量为s12=max(m1,m2+a1),反之则是s21=max(m2,m1+a2)不失一般地设m1−a1>=m2−a2,则有m1+a2>=m2+a1
当m1<=m2时,显然有s12=m2+a1,而s21=max(m2,m1+a2),由上可得m2+a1<=m1+a2,因此有s12<=s21
当m1>m2时,显然有s12=max(m1,m2+a1),而s21=m1+a2,由上可得m2+a1<=m1+a2,因此有s12<=s21
由此可知,贪心地将任务[a,m]当中m−a较大即a−m较小的排在前面进行即可
我在代码中使用的方法是,在知道排序策略后,我从ans=0开始,去逐渐累积需要消耗的值。
把 ans 想象成我们正在不断抬高的“初始能量水位线”。我们从 0 开始,一个一个地考虑任务。
当我们考虑一个新任务 [actual, minimum] 时,我们已经有了一个暂定的 ans,这个 ans 能够保证我们完成之前的所有任务。现在要把这个新任务也加进来。
- 完成之前的任务后,我们会剩下
ans - sum(previous_actuals)的能量。 - 为了启动新任务,我们有两种可能:
- 情况一:剩余能量足够。 即
ans - sum(previous_actuals) >= minimum。我们不需要提高水位线ans。 - 情况二:剩余能量不够。 我们必须从一开始就准备更多的能量。需要把水位线
ans抬高,直到剩余能量刚好够用。
- 情况一:剩余能量足够。 即
我的解法 ans = max(ans + actual, minimum) 正是这个思想的体现:
ans + actual:这代表什么?假设我们当前的ans刚好能完成之前的任务,不多不少。那么完成它们之后,我们的能量会变成ans - (ans - 之前的剩余能量) = 之前的剩余能量。为了完成当前任务,我们需要在这个剩余能量的基础上再消耗actual。所以,ans + actual实际上是把当前任务的消耗累加到总能量需求上。max(..., minimum):但是,累加后的总能量不一定能满足当前任务的minimum门槛。比如ans是 20,actual是 2,但minimum是 30。那么ans + actual是 22,但我们至少需要 30 才能启动。所以,我们必须取minimum作为新的ans。
结语
这次的笔记就到这里了,相较于前面的题型,难度很明显上来了,所以建议大家最好每题都多花点时间好好琢磨一下,会有很大的启发。下篇文章就会结束贪心策略,大概还剩下两个小章节,大家加油!
最近比较忙,如果前面文章有写错的地方大家可以评论区交流一下。