【数据集+完整源码】马数据集,马行为状态识别数据集 3006 张,yolov8目标检测牧场草原马识别算法实战训推教程
一、数据集介绍
【数据集】马识别数据集 3006 张,目标检测,包含YOLO/VOC格式标注。
数据集中包含1种分类:names: ['Horse'],代表马。
数据集来自国内网站、视频抽帧;
可用于无人机马识别,监控马行为状态检测等。
检测场景为草原、牧场、饲养场、马厩、马术赛场等场景,可用于马场养殖健康管理、马术运动训练辅助、野外马群保护监测、牧区道路安全预警等。
文章底部或主页私信获取数据集~
1、数据概述
马识别的重要性
马在畜牧业养殖、马术运动、野生动物保护及部分牧区生产中具有重要价值,但其传统管理与监测存在明显痛点:在规模化马场,人工巡查需逐栏观察马的采食、活动状态,耗时耗力且易漏判早期健康异常;野外马群(如草原野马、保护区马种)多活动于偏远、复杂地形,人工统计种群数量、追踪活动轨迹难度大;马术训练中,人工记录马匹动作细节易出现偏差,影响训练精度;此外,牧区道路偶有马群闯入,人工预警滞后易引发交通安全事故。
YOLO 算法凭借 “实时动态检测 + 精准目标定位” 破解上述问题:其一,可通过马场监控、无人机航拍或移动设备,快速识别画面中的马,无需人工密集巡查,大幅覆盖监测范围;其二,能精准区分马的状态(如站立、躺卧、奔跑)与环境(如马群聚集、单独离群),甚至捕捉细微异常(如跛行、精神萎靡);其三,检测结果可实时同步至管理端,缩短信息传递周期,为及时干预、决策提供支撑,推动马相关场景从 “人工经验管理” 向 “智能精准管控” 转型。
基于YOLO的马行为识别算法
-
马场养殖健康管理:规模化马场中,YOLO 可 24 小时监测马的日常状态:若发现马匹长时间躺卧不起、拒绝采食,或出现跛行、频繁蹭痒等异常,立即触发预警通知饲养员,避免人工巡查的漏检与滞后。同时,算法能辅助统计马匹数量,核对存栏情况,减少人工计数的错漏,尤其适合万头以上规模的马场,降低管理成本,保障马匹健康生长。
-
马术运动训练辅助:在马术训练或比赛中,YOLO 可实时检测马匹的肢体动作(如跳跃高度、奔跑步幅、姿态协调性),并记录动作细节。教练无需反复回看视频逐帧分析,通过算法输出的动作数据,能更精准判断马匹动作是否规范、发力是否合理,针对性调整训练方案,提升训练效率与比赛成绩,减少人工主观判断的偏差。
-
野外马群保护监测:针对草原、保护区等偏远区域的野生马群,YOLO 结合无人机航拍实现大范围检测:无需人员深入复杂地形,即可统计马群数量、幼马比例,判断种群规模变化;同时,追踪马群活动轨迹,识别是否有马单独离群、受困(如陷入沼泽、被异物缠绕),辅助保护人员精准定位救援,减少野外巡查的盲区与风险,助力马种资源保护。
-
牧区道路安全预警:在牧区或临近马场的道路,YOLO 可部署于路边监控设备,实时检测马群闯入情况。一旦发现马匹靠近道路,立即通过交通诱导屏、车辆预警系统推送提示,提醒驾驶员减速避让,避免因马群突然闯入导致的车辆碰撞事故,保障人畜与交通出行安全,填补人工巡逻预警的时空空白。
该数据集含有 3006 张图片,包含Pascal VOC XML格式和YOLO TXT格式,用于训练和测试草原、牧场、饲养场、马厩、马术赛场等场景进行马行为状态识别。
图片格式为jpg格式,标注格式分别为:
YOLO:txt
VOC:xml
数据集均为手工标注,保证标注精确度。
2、数据集文件结构
Horse/
——test/
————Annotations/
————images/
————labels/
——train/
————Annotations/
————images/
————labels/
——valid/
————Annotations/
————images/
————labels/
——data.yaml
- 该数据集已划分训练集样本,分别是:test目录(测试集)、train目录(训练集)、valid目录(验证集);
- Annotations文件夹为Pascal VOC格式的XML文件 ;
- images文件夹为jpg格式的数据样本;
- labels文件夹是YOLO格式的TXT文件;
- data.yaml是数据集配置文件,包含马识别的目标分类和加载路径。


Annotations目录下的xml文件内容如下:
<?xml version="1.0" encoding="utf-8"?><annotation><folder>driving_annotation_dataset</folder><filename>img27_jpg.rf.29accfdc39e5c0ecdb468948c7b310c1.jpg</filename><size><width>1333</width><height>800</height><depth>3</depth></size><object><name>Horse</name><pose>Unspecified</pose><truncated>0</truncated><difficult>0</difficult><bndbox><xmin>456</xmin><ymin>197</ymin><xmax>1058</xmax><ymax>566</ymax></bndbox></object></annotation>labels目录下的txt文件内容如下:
0 0.2828207051762941 0.52375 0.4872468117029257 0.79625
0 0.6991747936984246 0.60875 0.2846961740435109 0.63253、数据集适用范围
- 目标检测场景,无人机检测,监控识别
- yolo训练模型或其他模型
- 草原、牧场、饲养场、马厩、马术赛场等场景
- 可用于马场养殖健康管理、马术运动训练辅助、野外马群保护监测、牧区道路安全预警等
4、数据集标注结果




4.1、数据集内容
- 多角度场景:行人视角数据样本,监控视角数据样本;
- 标注内容:names: ['Horse'],总计1个分类;
- 图片总量:3006 张图片数据;
- 标注类型:含有Pascal VOC XML格式和yolo TXT格式;
5、训练过程
5.1、导入训练数据
下载YOLOv8项目压缩包,解压在任意本地workspace文件夹中。
下载YOLOv8预训练模型,导入到ultralytics-main项目根目录下。

在ultralytics-main项目根目录下,创建data文件夹,并在data文件夹下创建子文件夹:Annotations、images、imageSets、labels,其中,将pascal VOC格式的XML文件手动导入到Annotations文件夹中,将JPG格式的图像数据导入到images文件夹中,imageSets和labels两个文件夹不导入数据。
data目录结构如下:
data/
——Annotations/ //存放xml文件
——images/ //存放jpg图像
——imageSets/
——labels/
整体项目结构如下所示:

5.2、数据分割
首先在ultralytics-main目录下创建一个split_train_val.py文件,运行文件之后会在imageSets文件夹下将数据集划分为训练集train.txt、验证集val.txt、测试集test.txt,里面存放的就是用于训练、验证、测试的图片名称。
import os
import randomtrainval_percent = 0.9
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')for i in list:name = total_xml[i][:-4] + '\n'if i in trainval:ftrainval.write(name)if i in train:ftrain.write(name)else:fval.write(name)else:ftest.write(name)ftrainval.close()
ftrain.close()
fval.close()
ftest.close()5.3、数据集格式化处理
在ultralytics-main目录下创建一个voc_label.py文件,用于处理图像标注数据,将其从XML格式(通常用于Pascal VOC数据集)转换为YOLO格式。
convert_annotation函数
-
这个函数读取一个图像的XML标注文件,将其转换为YOLO格式的文本文件。
-
它打开XML文件,解析树结构,提取图像的宽度和高度。
-
然后,它遍历每个目标对象(
object),检查其类别是否在classes列表中,并忽略标注为困难(difficult)的对象。 -
对于每个有效的对象,它提取边界框坐标,进行必要的越界修正,然后调用
convert函数将坐标转换为YOLO格式。 -
最后,它将类别ID和归一化后的边界框坐标写入一个新的文本文件。
import xml.etree.ElementTree as ET
import os
from os import getcwdsets = ['train', 'val', 'test']
classes = ['Horse'] # 根据标签名称填写类别
abs_path = os.getcwd()
print(abs_path)def convert(size, box):dw = 1. / (size[0])dh = 1. / (size[1])x = (box[0] + box[1]) / 2.0 - 1y = (box[2] + box[3]) / 2.0 - 1w = box[1] - box[0]h = box[3] - box[2]x = x * dww = w * dwy = y * dhh = h * dhreturn x, y, w, hdef convert_annotation(image_id):in_file = open('data/Annotations/%s.xml' % (image_id), encoding='UTF-8')out_file = open('data/labels/%s.txt' % (image_id), 'w')tree = ET.parse(in_file)root = tree.getroot()size = root.find('size')w = int(size.find('width').text)h = int(size.find('height').text)for obj in root.iter('object'):difficult = obj.find('difficult').textcls = obj.find('name').textif cls not in classes or int(difficult) == 1:continuecls_id = classes.index(cls)xmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text),float(xmlbox.find('xmax').text),float(xmlbox.find('ymin').text),float(xmlbox.find('ymax').text))b1, b2, b3, b4 = b# 标注越界修正if b2 > w:b2 = wif b4 > h:b4 = hb = (b1, b2, b3, b4)bb = convert((w, h), b)out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')wd = getcwd()
for image_set in sets:if not os.path.exists('data/labels/'):os.makedirs('data/labels/')image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()list_file = open('data/%s.txt' % (image_set), 'w')for image_id in image_ids:list_file.write(abs_path + '/data/images/%s.jpg\n' % (image_id))convert_annotation(image_id)list_file.close()5.4、修改数据集配置文件
在ultralytics-main目录下创建一个data.yaml文件
train: data/train.txt
val: data/val.txt
test: data/test.txtnc: 1
names: ['Horse']5.5、执行命令
执行train.py
model = YOLO('yolov8s.pt')
results = model.train(data='data.yaml', epochs=200, imgsz=640, batch=16, workers=0)也可以在终端执行下述命令:
yolo train data=data.yaml model=yolov8s.pt epochs=200 imgsz=640 batch=16 workers=0 device=05.6、模型预测
你可以选择新建predict.py预测脚本文件,输入视频流或者图像进行预测。
代码如下:
import cv2
from ultralytics import YOLO# Load the YOLOv8 model
model = YOLO("./best.pt") # 自定义预测模型加载路径# Open the video file
video_path = "./demo.mp4" # 自定义预测视频路径
cap = cv2.VideoCapture(video_path) # Get the video properties
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)# Define the codec and create VideoWriter object
fourcc = cv2.VideoWriter_fourcc(*'mp4v') # Be sure to use lower case
out = cv2.VideoWriter('./outputs.mp4', fourcc, fps, (frame_width, frame_height)) # 自定义输出视频路径# Loop through the video frames
while cap.isOpened():# Read a frame from the videosuccess, frame = cap.read()if success:# Run YOLOv8 inference on the frame# results = model(frame)results = model.predict(source=frame, save=True, imgsz=640, conf=0.5)results[0].names[0] = "道路积水"# Visualize the results on the frameannotated_frame = results[0].plot()# Write the annotated frame to the output fileout.write(annotated_frame)# Display the annotated frame (optional)cv2.imshow("YOLOv8 Inference", annotated_frame)# Break the loop if 'q' is pressedif cv2.waitKey(1) & 0xFF == ord("q"):breakelse:# Break the loop if the end of the video is reachedbreak# Release the video capture and writer objects
cap.release()
out.release()
cv2.destroyAllWindows()也可以直接在命令行窗口或者Annoconda终端输入以下命令进行模型预测:
yolo predict model="best.pt" source='demo.jpg'6、获取数据集
文章底部或主页私信获取数据集~
二、YOLO马行为状态检测系统
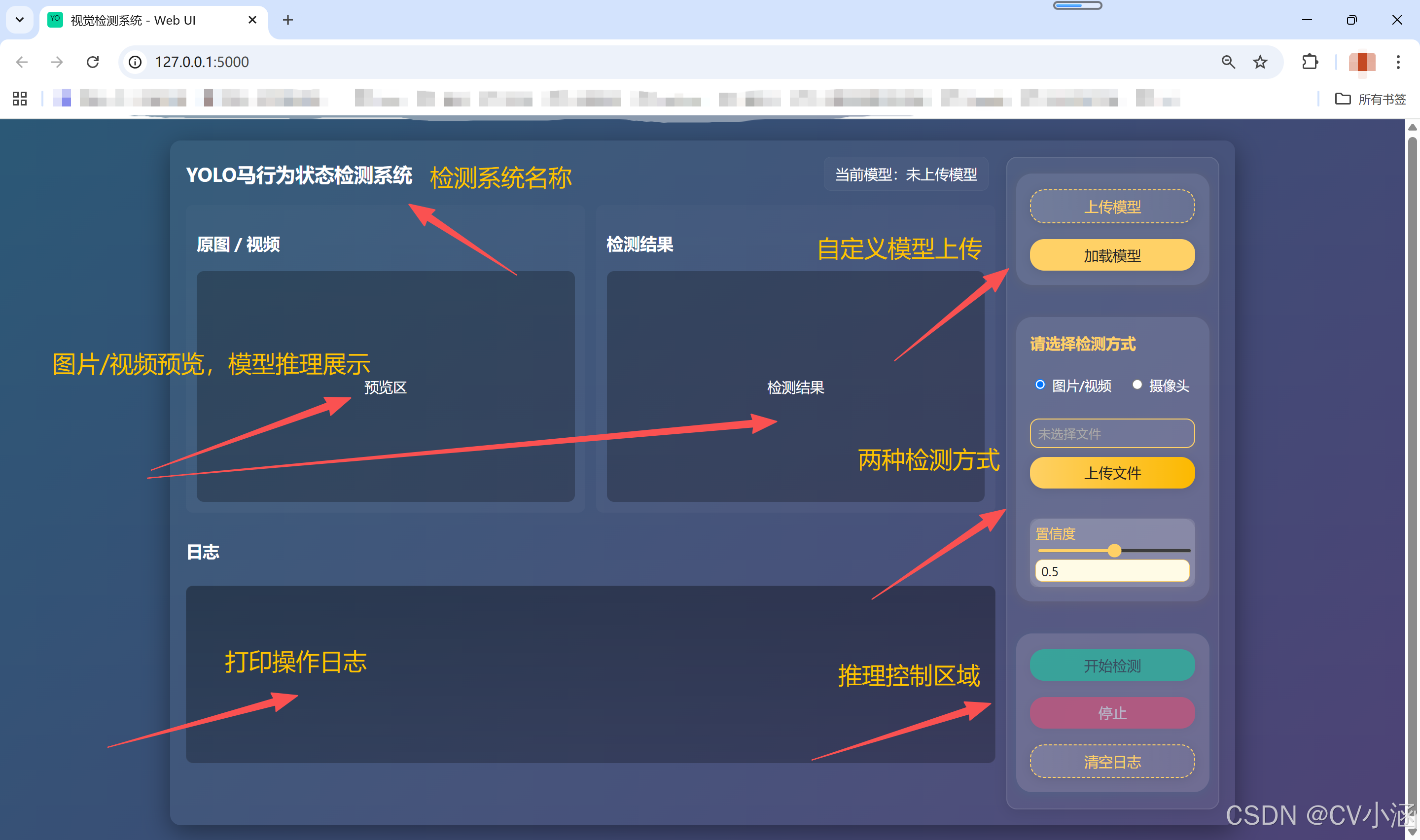
1、功能介绍
1. 模型管理
支持自定义上传模型文件,一键加载所选模型,基于 YOLO 框架进行推理。
2. 图片检测
- 支持上传本地图片文件,自动完成格式校验。
- 对上传图片进行目标检测,检测结果以带有边框和标签的图片形式返回并展示。
- 检测结果可下载保存。
3. 视频检测与实时流
- 支持上传本地视频文件,自动完成格式校验。
- 对视频逐帧检测,检测结果通过 MJPEG 流实时推送到前端页面,用户可边看边等。
- 支持摄像头实时检测(如有接入摄像头)。
4. 置信度阈值调节
- 前端可实时调整检测置信度阈值,动态影响检测结果。
- 阈值调整后,后端推理自动应用新阈值,无需重启。
5. 日志与状态反馈
- 前端集成日志区,实时显示模型加载、推理、文件上传等操作的进度与结果。
- 检测异常、错误信息及时反馈,便于排查。
- 一键清空日志,笔面长期占用内存。
2、创建环境并安装依赖:
conda create -n ultralytics-env python=3.10
conda activate ultralytics-env
pip install -r requirements.txt3、启动项目
python app.py打开浏览器访问:http://localhost:5000
4、效果展示
4.1、推理效果
以共享单车为例,效果如下: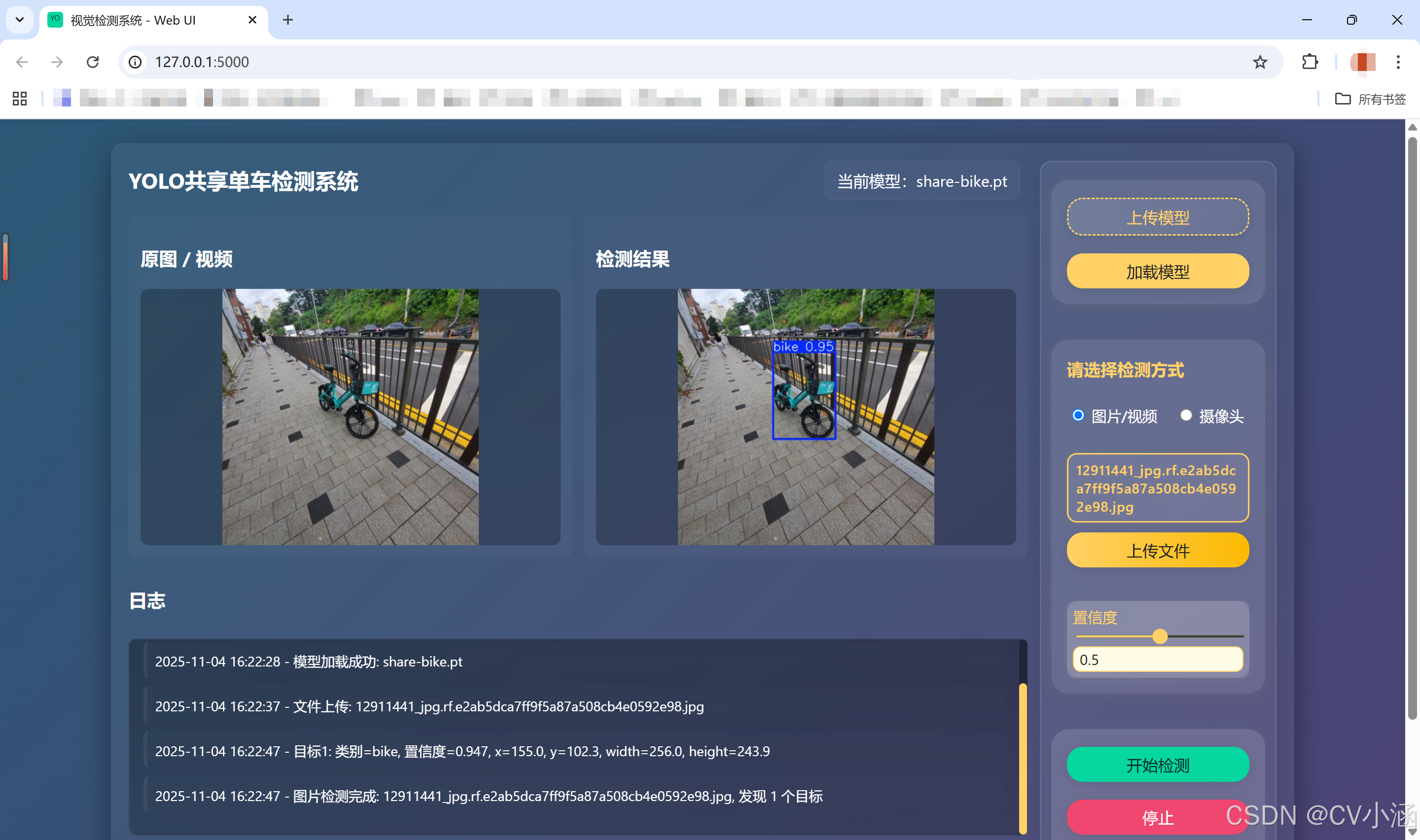
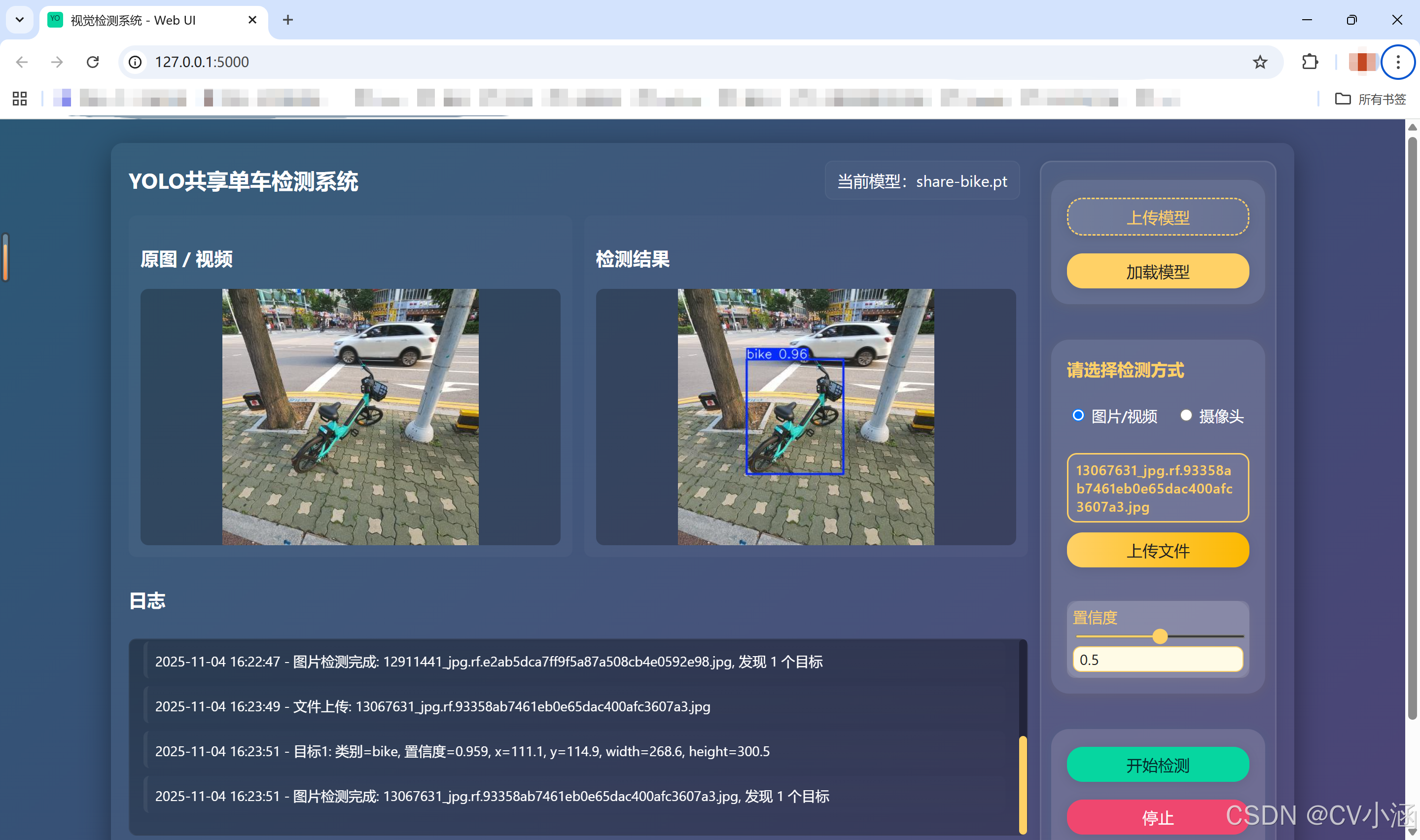
4.2、日志文本框

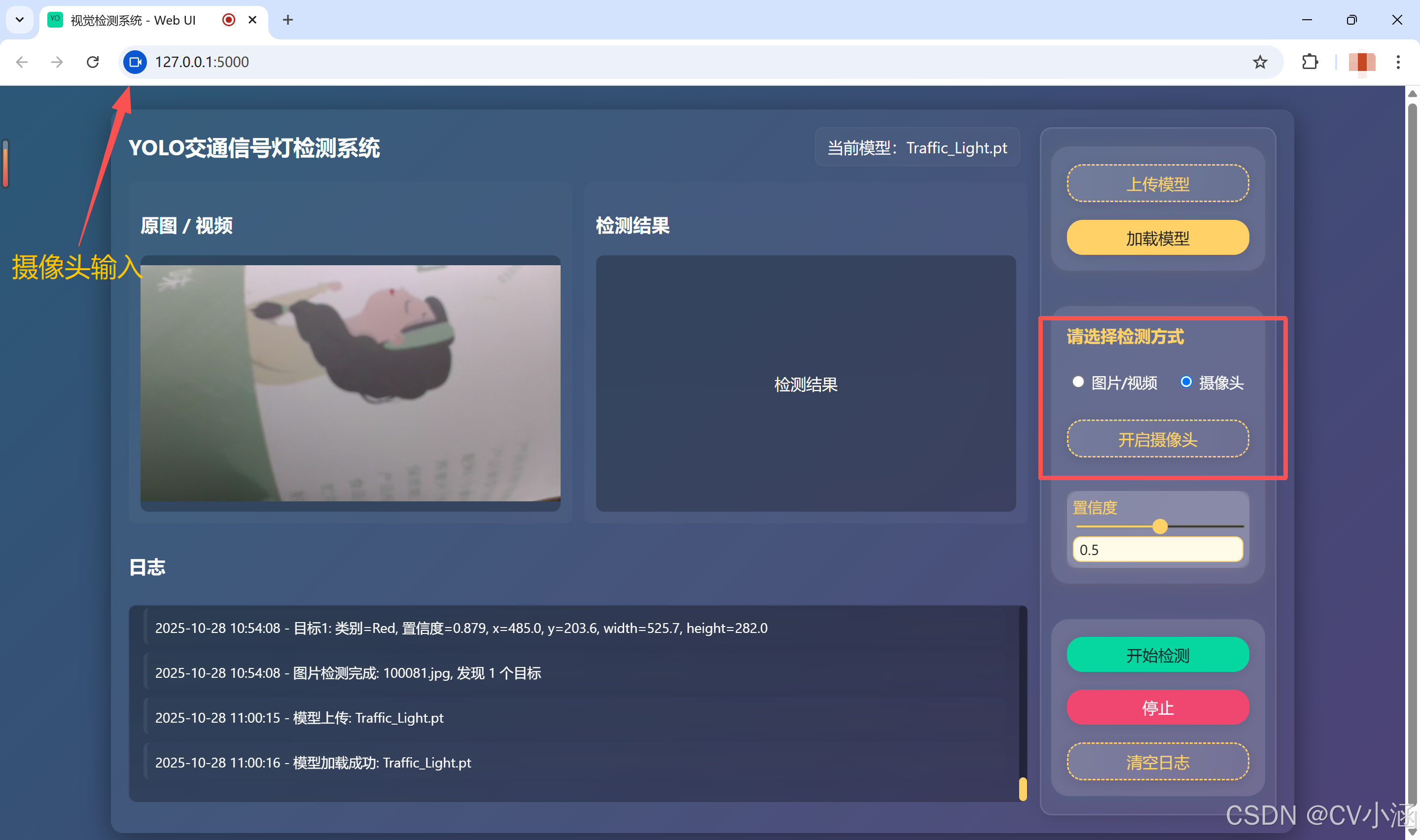
4.3、摄像头检测
以红绿灯检测为例:
5、前端核心页面代码
<!doctype html>
<html lang="zh-CN"><head><meta charset="utf-8"><meta name="viewport" content="width=device-width,initial-scale=1"><title>视觉检测系统 - Web UI</title><link rel="stylesheet" href="/static/style.css"><link rel="icon" href="/favicon.ico">
</head><body><div class="container main-flex"><!-- 左侧内容区 --><div class="left-content"><header><h1>YOLO马行为状态检测系统</h1><div id="currentModelDisplay" class="modelDisplay" title="当前模型">当前模型:未上传模型</div></header><main><div class="videoPanel"><div class="pane"><h3>原图 / 视频</h3><div class="preview" id="srcPreview">预览区</div></div><div class="pane"><h3>检测结果</h3><div class="preview" id="detPreview">检测结果</div></div></div><section class="logArea"><div class="logHeader"><h3>日志</h3></div><div class="logInner"><div id="logs" class="logs"></div></div></section></main></div><!-- 右侧按钮栏 --><aside class="right-bar"><!-- 1. 模型上传/加载区 --><section class="model-section"><button id="uploadModelBtn" class="ghost">上传模型<input id="modelFileInput" type="file" accept=".pt" title="选择 .pt 模型文件"></button><button id="loadModel">加载模型</button></section><!-- 2. 检测方式选择区 --><section class="detect-mode-section"><div class="detect-mode-title">请选择检测方式</div><div class="detect-mode-radio-group"><label><input type="radio" name="detectMode" value="upload" checked> 图片/视频</label><label><input type="radio" name="detectMode" value="camera"> 摄像头</label></div><div id="detectModeUpload" class="detect-mode-panel"><div class="uploaded-file-name"><span id="uploadedFileName" class="placeholder">未选择文件</span></div><div style="height: 22px;"></div><button id="uploadBtn">上传文件<input id="fileInput" type="file" accept="image/*,video/*" title="上传图片或视频" aria-label="上传图片或视频"></button></div><div id="detectModeCamera" class="detect-mode-panel" style="display:none;"><button id="cameraDetectBtn" class="ghost">开启摄像头</button><div id="cameraPreview" class="camera-preview"><video id="localCameraVideo" autoplay muted playsinline></video><div class="camera-controls"><button id="stopCameraBtn" class="ghost">关闭摄像头</button></div></div></div><div class="confWrap"><label class="conf">置信度<input id="confRange" type="range" min="0.01" max="0.99" step="0.01" value="0.5"><input id="confValue" type="number" min="0.01" max="0.99" step="0.01" value="0.5"></label></div></section><!-- 3. 操作按钮区 --><section class="action-btn-section"><button id="startBtn" disabled class="start">开始检测</button><button id="stopBtn" disabled class="stop">停止</button><button id="clearLogs" class="ghost">清空日志</button></section></aside></div><script src="/static/app.js"></script>
</body></html>6、代码获取
文章底部名片或私信获取系统源码和数据集~
更多数据集请查看