linux文件系统和软硬连接
理解文件
- ⽂件在磁盘⾥,磁盘是永久性存储介质,因此⽂件在磁盘上的存储是永久性的
- Linux 下⼀切皆⽂件(键盘、显⽰器、⽹卡、磁盘……)
- 0KB 的空⽂件也是占⽤磁盘空间的
- ⽂件是⽂件属性(元数据)和⽂件内容的集合(⽂件 = 属性(元数据)+ 内容)
- 所有的⽂件操作本质是⽂件内容操作和⽂件属性操作
- 对⽂件的操作本质是进程对⽂件的操作, 磁盘的管理者是操作系统
- ⽂件的读写本质不是通过 C 语⾔ / C++ 的库函数来操作的(这些库函数只是为⽤⼾提供⽅便),⽽是通过⽂件相关的系统调⽤接⼝来实现的
理解硬盘
机械磁盘是计算机中唯⼀的⼀个机械设备
磁盘是外设,特点:慢,容量⼤,价格便宜
磁盘的物理结构:

磁盘的存储结构:

扇区是从磁盘读出和写⼊信息的最⼩单位,通常⼤⼩为 512 字节。
- 磁头(head)数:每个盘⽚⼀般有上下两⾯,分别对应1个磁头,共2个磁头
- 磁道(track)数:磁道是从盘⽚外圈往内圈编号0磁道,1磁道...,靠近主轴的同⼼圆⽤于停靠磁头,不存储数据
- 柱⾯(cylinder)数:磁道构成柱⾯,数量上等同于磁道个数
- 扇区(sector)数:每个磁道都被切分成很多扇形区域,每道的扇区数量相同
- 圆盘(platter)数:就是盘⽚的数量
- 磁盘容量=磁头数 × 磁道(柱面)数 × 每道扇区数 × 每扇区字节数
- 细节:传动臂上的磁头是共进退的
通过柱⾯(cylinder),磁头(head),扇区(sector),就可以定位数据了,这就是数据定位(寻址)⽅式之⼀,CHS寻址⽅式。
磁盘的逻辑结构
磁带逻辑结构
在理解磁盘的逻辑结构之前我们先来了解一下磁带的逻辑结构:

磁带上面存取数据,当我们把磁带拉直就形成了线性结构

虽然磁盘本质上虽然是硬质的,但是逻辑上我们可以把磁盘想象成为卷在⼀起的磁带,那么磁盘的逻辑存储结构我们也可以类似于:

磁盘逻辑结构
机械臂上的磁头是共进退的
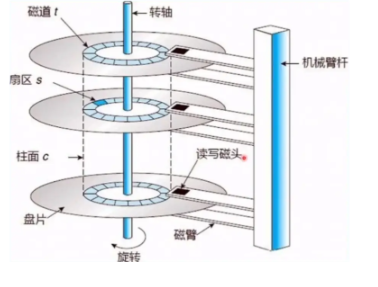
柱⾯是⼀个逻辑上的概念,其实就是每⼀⾯上,相同半径的磁道逻辑上构成柱⾯。所以,磁盘物理上分了很多⾯,但是在我们看来,逻辑上,磁盘整体是由“柱⾯”卷起来的

这样看来一个柱面就是一个二维数组.
整盘
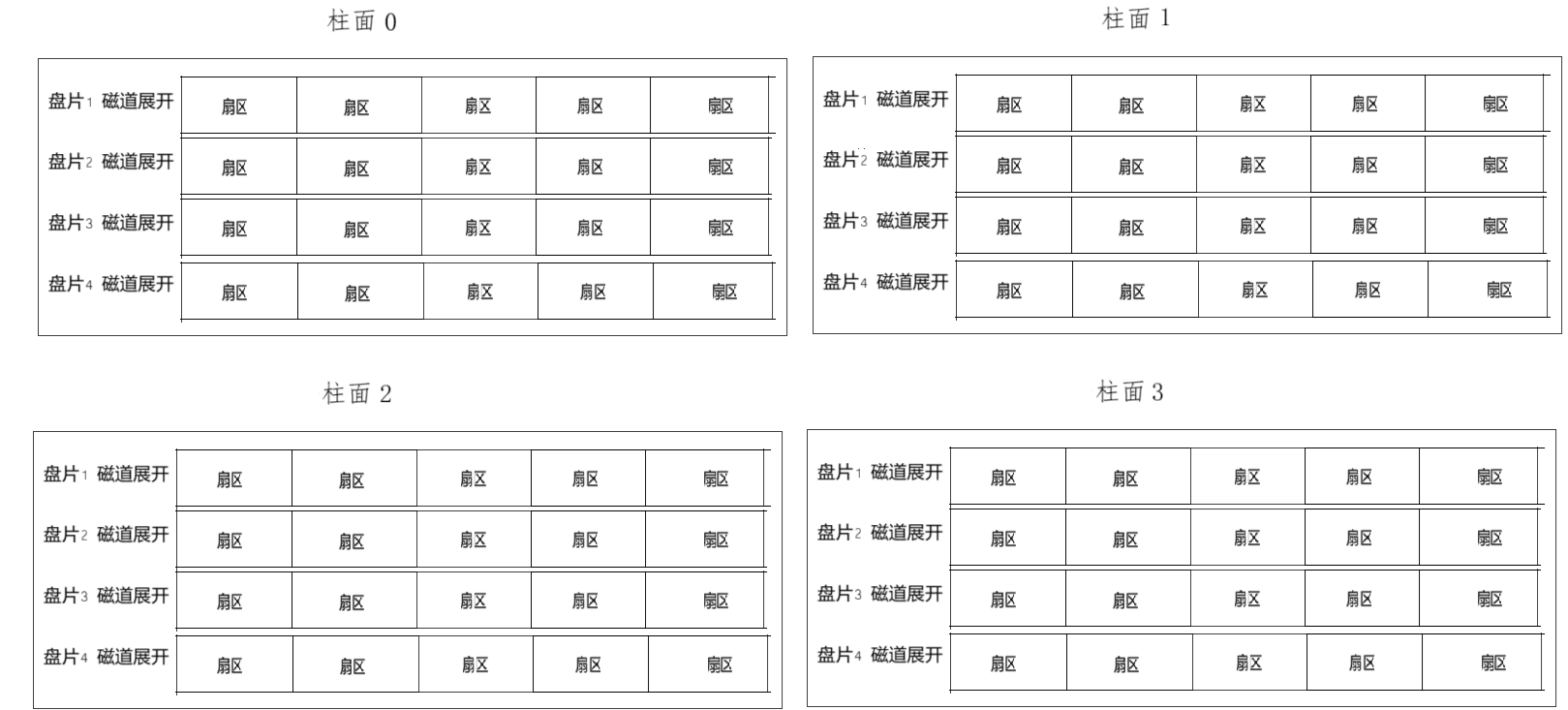
故整盘就是多张二维的扇区数组表 “三维数组” .
这样每⼀个扇区,就有了⼀个线性地址(其实就是数组下标),这种地址叫做 LBA.
CHS && LBA地址
CHS转成LBA:
- 磁头数*每磁道扇区数 = 单个柱⾯的扇区总数
- LBA = 柱⾯号C*单个柱⾯的扇区总数 + 磁头号H*每磁道扇区数 + 扇区号S - 1
- 即:LBA = 柱⾯号C*(磁头数*每磁道扇区数) + 磁头号H*每磁道扇区数 + 扇区号S - 1
LBA转成CHS:
- 柱⾯号C = LBA // (磁头数*每磁道扇区数)【就是单个柱⾯的扇区总数】
- 磁头号H = (LBA % (磁头数*每磁道扇区数)) // 每磁道扇区数
- 扇区号S = (LBA % 每磁道扇区数) + 1
在磁盘使⽤者看来,根本就不关⼼CHS地址,⽽是直接使⽤LBA地址,磁盘内部⾃⼰转换。
故磁盘是⼀个 元素为扇区 的⼀维数组,数组的下标就是每⼀个扇区的LBA地址。OS使⽤磁盘,就可以⽤⼀个数字访问磁盘扇区了。
引入文件系统
“块” 的概念
- 操作系统读取硬盘数据的时候,其实是不会⼀个个扇区地读取,这样效率太低,⽽是⼀次性连续读取多个扇区,即⼀次性读取⼀个”块”(block)
- 硬盘的每个分区是被划分为⼀个个的”块”。⼀个”块”的⼤⼩是由格式化的时候确定的,并且不可以更改,最常⻅的是4KB,即连续⼋个扇区组成⼀个 ”块”。(每个扇区512B)
- 文件系统和存储管理中,“块(Block)” 是磁盘(或其他存储设备)进行数据读写的最小单位,也是文件系统管理存储空间的基础单元。

“分区” 的概念
- 其实磁盘是可以被分成多个分区(partition)的,以Windows观点来看,你可能会有⼀块磁盘并且将它分区成C,D,E盘。那个C,D,E就是分区。分区从实质上说就是对硬盘的⼀种格式化。但是Linux的设备都是以⽂件形式存在,那是怎么分区的呢?
- 柱⾯是分区的最⼩单位,我们可以利⽤参考柱⾯号码的⽅式来进⾏分区,其本质就是设置每个区的起始柱⾯和结束柱⾯号码。
- 柱⾯⼤⼩⼀致,扇区个位⼀致,那么其实只要知道每个分区的起始和结束柱⾯号,知道每⼀个柱⾯多少个扇区,那么该分区多⼤,其实和解释LBA是多少也就清楚了.
inode
我们知道 ⽂件=内容+属性 ,我们使⽤ ls -l 的时候看到的除了看到⽂件名,还能看到⽂件元数据(属性)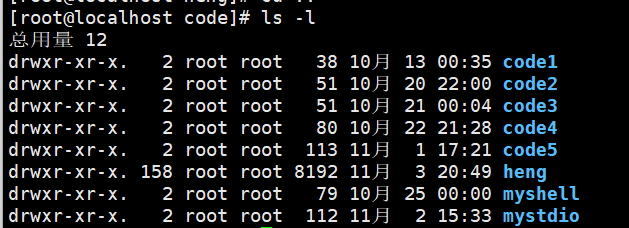
每⾏的7列分别代表:
- 模式
- 硬链接数
- ⽂件所有者
- 组
- ⼤⼩
- 最后修改时间
- ⽂件名
这个信息除了通过ls来读取,还有⼀个stat命令能够看到更多信息。
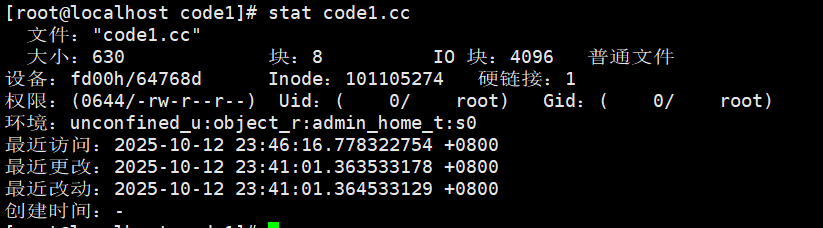
我们知道⽂件数据都储存在”块”中,那么很显然,我们还必须找到⼀个地⽅储存⽂件的元信息(属性信息),⽐如⽂件的创建者、⽂件的创建⽇期、⽂件的⼤⼩等等。这种储存⽂件元信息的区域就叫做inode,中⽂译名为”索引节点”。
每⼀个⽂件都有对应的inode,⾥⾯包含了与该⽂件有关的⼀些信息。为了能解释清楚inode,我们需要是深⼊了解⼀下⽂件系统。
注意:
- Linux下⽂件的存储是属性和内容分离存储的
- Linux下,保存⽂件属性的集合叫做inode,⼀个⽂件,⼀个inode,inode内有⼀个唯⼀的标识符,叫做inode号
- ⽂件名属性并未纳⼊到inode数据结构内部
- inode的⼤⼩⼀般是128字节或者256
- 任何⽂件的内容⼤⼩可以不同,但是属性⼤⼩⼀定是相同的
ext2 ⽂件系统
认识文件系统
所有的准备⼯作都已经做完,是时候认识下⽂件系统了。我们想要在硬盘上储⽂件,必须先把硬盘格式化为某种格式的⽂件系统,才能存储⽂件。⽂件系统的⽬的就是组织和管理硬盘中的⽂件。在 Linux 系统中,最常⻅的是 ext2 系列的⽂件系统。其早期版本为 ext2,后来⼜发展出 ext3 和 ext4。ext3 和 ext4 虽然对 ext2 进⾏了增强,但是其核⼼设计并没有发⽣变化。
ext2⽂件系统将整个分区划分成若⼲个同样⼤⼩的块组 (Block Group),如下图所⽰。只要能管理⼀个分区就能管理所有分区,也就能管理所有磁盘⽂件。
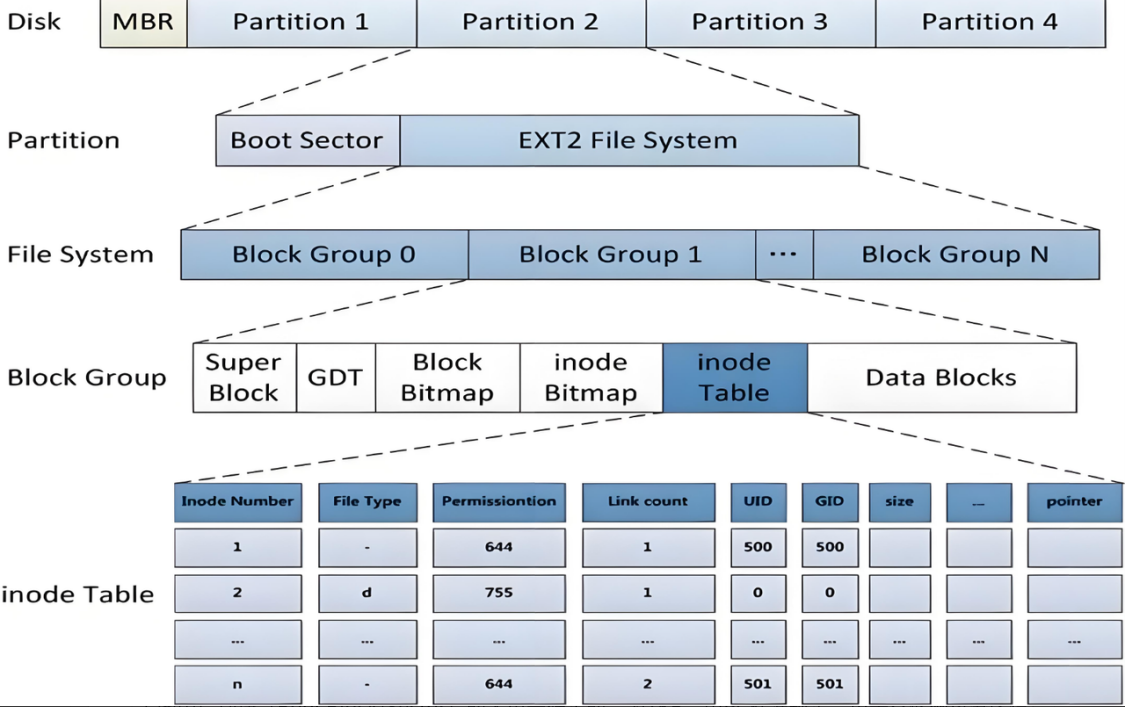
上图中启动块(Boot Sector)的⼤⼩是确定的,为1KB,由PC标准规定,⽤来存储磁盘分区信息和启动信息,任何⽂件系统都不能修改启动块。启动块之后才是ext2⽂件系统的开始。
Block Group
Block Group(块组) 是文件系统管理磁盘空间的核心 “模块化单元”,每ext2⽂件系统会根据分区的⼤⼩划分为数个Block Group。⽽每个Block Group都有着相同的结构组成。每个Block Group自主管理资源,以提升效率和容错性。
块组内部构成
超级块(Super Block)
存放⽂件系统本⾝的结构信息,描述整个分区的⽂件系统信息。记录的信息主要有:bolck 和 inode的总量,未使⽤的block和inode的数量,⼀个block和inode的⼤⼩,最近⼀次挂载的时间,最近⼀次写⼊数据的时间,最近⼀次检验磁盘的时间等其他⽂件系统的相关信息。Super Block的信息被破坏,可以说整个⽂件系统结构就被破坏了。
GDT(Group Descriptor Table)
块组描述符表,描述块组属性信息,整个分区分成多个块组就对应有多少个块组描述符。每个块组描述符存储⼀个块组 的描述信息,如在这个块组中从哪⾥开始是inode Table,从哪⾥开始是Data Blocks,空闲的inode和数据块还有多少个等等。块组描述符在每个块组的开头都有⼀份拷⻉。
块位图(Block Bitmap)
Block Bitmap以位图的形式记录着Data Block中哪个数据块已经被占⽤,哪个数据块没有被占⽤。
inode位图(Inode Bitmap)
每个bit表⽰⼀个inode是否空闲可⽤。(位值为0表示可用,为1不可用)
i节点表(Inode Table)
- 存放⽂件属性 如 ⽂件⼤⼩,所有者,最近修改时间等
- 当前分组所有Inode属性的集合
- inode编号以分区为单位,整体划分,不可跨分区
Data Block
数据区:存放⽂件内容,也就是⼀个⼀个的Block。根据不同的⽂件类型有以下⼏种情况:
- 对于普通⽂件,⽂件的数据存储在数据块中。
- 对于⽬录,该⽬录下的所有⽂件名和⽬录名存储在所在⽬录的数据块中,除了⽂件名外,ls -l命令看到的其它信息保存在该⽂件的inode中。
- Block 号按照分区划分,不可跨分区,只能在自己分区内有效不可跨分区
inode和datablock映射
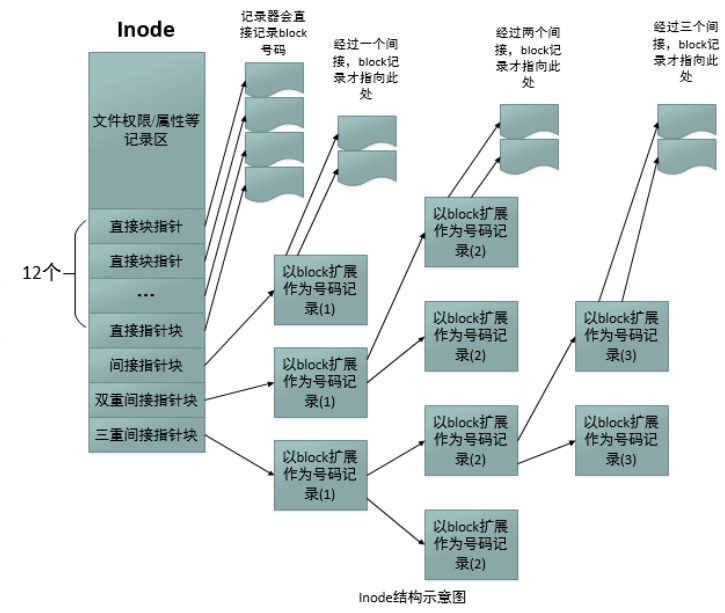
12 个直接块指针(直接翻到章节):直接指向存储文件数据的 “普通数据块”(小文件可通过这些指针直接找到所有数据块,因此小文件存储非常高效)。
间接块索引指针
一级间接块索引指针(“先查目录,再翻章节”):该指针指向了一级数据块索引表(4KB),该索引表中储存了多个普通数据块的编号(每个编号4字节),则索引表中管理了1024个数据块。则可以在直接块的基础上多管理(1024 * 4KB = 4MB)4MB的文件。
二级间接块索引指针(“查目录的目录,再翻章节”):该指针指向了数据块索引表,该数据块索引表又可以指向1024个数据块索引表,每个索引块可以管理1024个数据块。则可以在前面的基础上多管理(1024 * 1024 * 4KB = 4GB)4GB的文件。
三级间接块索引指针(“查目录的目录的目录,再翻章节”):以此类推,则可以在前面的基础上多管理(1024 * 1024 * 1024 * 4KB = 4TB)4TB的文件。
结论:
- 分区之后的格式化操作,就是对分区进⾏分组,在每个分组中写⼊SB、GDT、Block、Bitmap、Inode Bitmap等管理信息,这些管理信息统称: ⽂件系统
- 只要知道⽂件的inode号,就能在指定分区中确定是哪⼀个分组,进⽽在哪⼀个分组确定是哪⼀个inode
- 拿到inode⽂件属性和内容就全部都有了
[root@localhost linux]# touch abc
[root@localhost linux]# ls -i abc
263466 abc
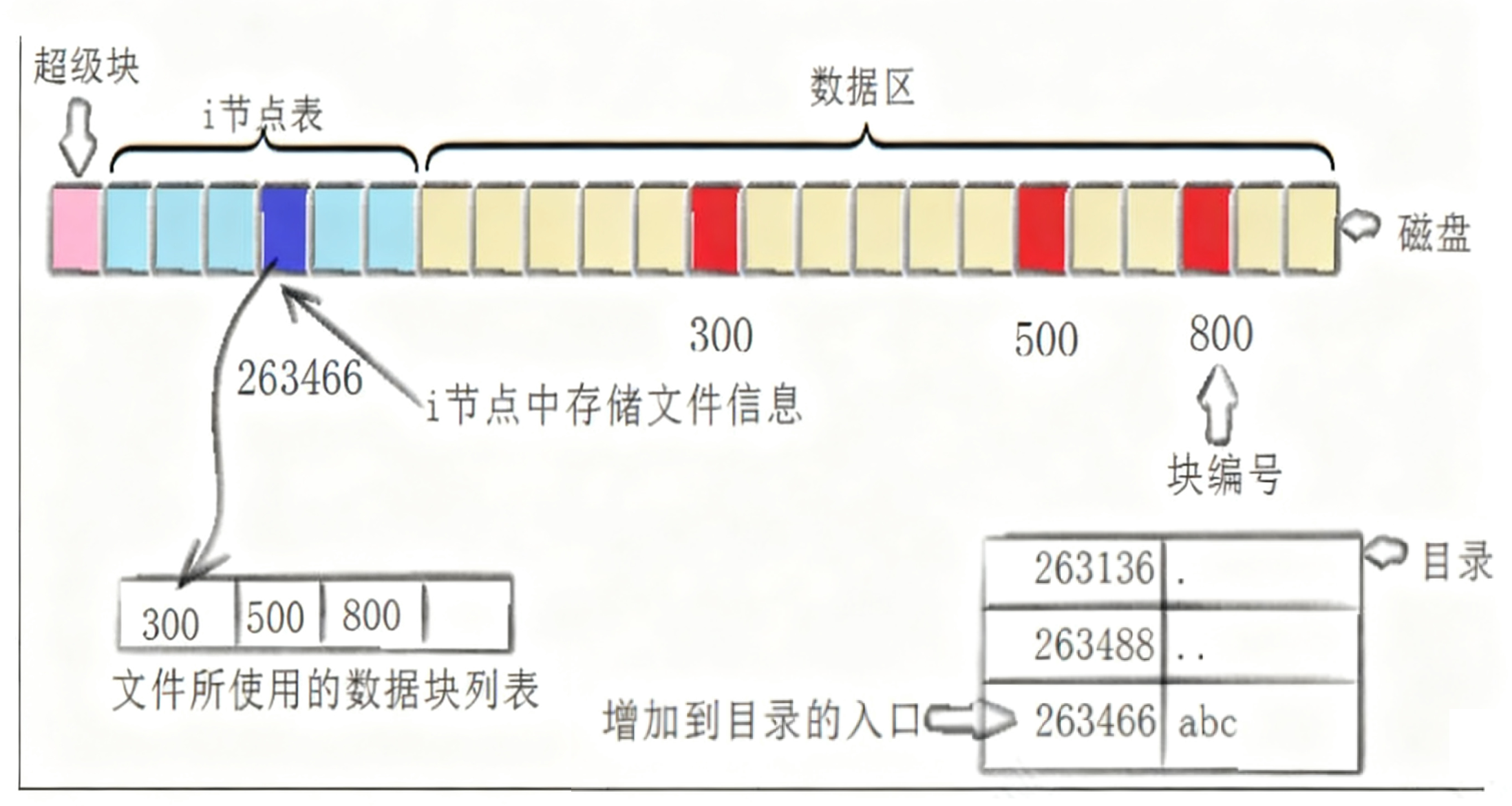
如上图可知创建⼀个新⽂件主要有以下4个操作:
1. 存储属性
内核先找到⼀个空闲的i节点(这⾥是263466)。内核把⽂件信息记录到其中。
2. 存储数据
该⽂件需要存储在三个磁盘块,内核找到了三个空闲块:300 ,500,800。将内核缓冲区的第⼀块数据复制到300,下⼀块复制到500,以此类推。
3. 记录分配情况
⽂件内容按顺序300,500,800存放。内核在inode上的磁盘分布区记录了上述块列表。
4. 添加⽂件名到⽬录
新的⽂件名abc。linux如何在当前的⽬录中记录这个⽂件?内核将⼊⼝(263466,abc)添加到⽬录⽂件。⽂件名和inode之间的对应关系将⽂件名和⽂件的内容及属性连接起来。
目录与文件名
我们发现平常访问⽂件,⽤的是⽂件名,并没⽤inode号,那它是怎么访问的呢?
答:
目录是文件,磁盘上是没有目录这一概念的,目录的内容保存的是当前目录下的文件名和inode的映射关系。
- 所以,访问⽂件,必须打开当前⽬录,根据⽂件名,获得对应的inode号,然后进⾏⽂件访问。
- 所以,访问⽂件必须要知道当前⼯作⽬录,本质是必须能打开当前⼯作⽬录⽂件,查看⽬录⽂件的内容!
路径解析
我们知道访问文件时需要访问目录文件,可是目录我们也只知道文件名,要访问当前目录也要知道他的inode。
故需要一直向上访问上级目录,类似于“递归”,需要把路径中所有的⽬录全部解析,出⼝是"/"根⽬录(根⽬录固定⽂件名,inode号,⽆需查找,系统开机之后就必须知道)。
实际上,任何⽂件,都有路径,访问⽬标⽂件,⽐如: /home/whb/code/test/test/test.c 都要从根⽬录开始,依次打开每⼀个⽬录,根据⽬录名,依次访问每个⽬录下指定的⽬录,直到访问到test.c。这个过程叫做Linux路径解析。
路径谁提供?
- 你访问⽂件,都是指令/⼯具访问,本质是进程访问,进程有CWD!进程提供路径。
- 你open⽂件,提供了路径.
软硬链接
创建软硬连接观察,对比它们的inode:
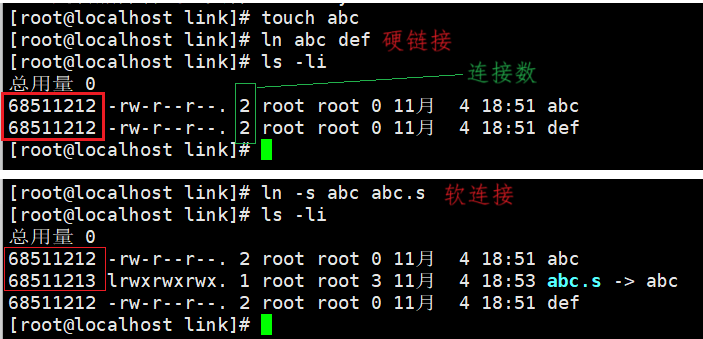
硬链接
abc和def的链接状态完全相同,他们被称为指向⽂件的硬链接。内核记录了这个连接数,inode:68511212 的硬连接数为2。
- 硬连接是新文件名与和目标文件inode编号的映射关系;
- 创建硬连接,就是建立映射关系,并且把inode的链接数增加;
我们在删除⽂件时⼲了两件事情:
- 在⽬录中将对应的记录删除,
- 将硬连接数-1,如果为0,则将对应的磁盘释放。
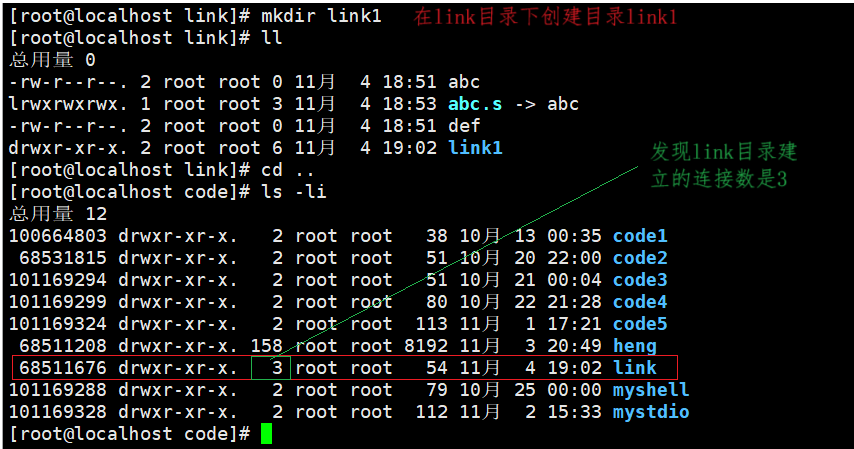
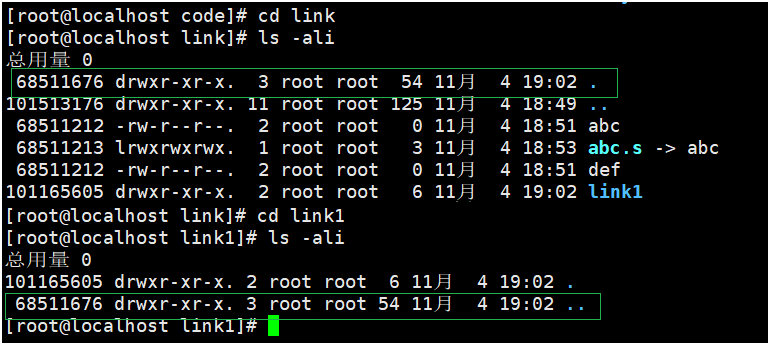
如上图我们可以发现当前目录下的 . 和下级目录下的 .. 都连接着该目录故他的连接数是3
软连接
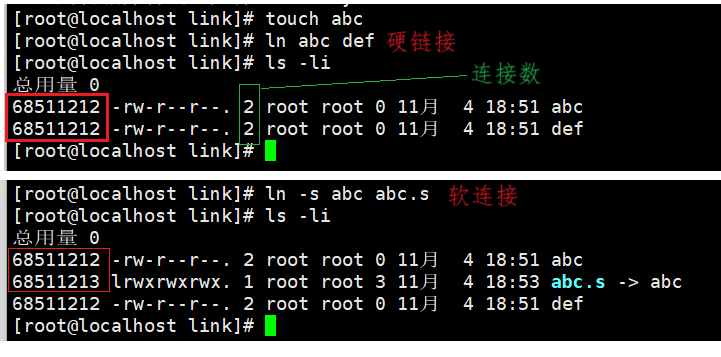
那么软连接是什么?
软连接是一个独立的文件,文件内容是目标文件的路径。有点类似于快捷方式.
一个目录被创建时,会产生三个连接。其中两个“目录名”和"."指向自己,还有一个".."指向上一级目录。
目录可以创建软连接,但是不能创建硬连接!否则会形成环路问题,除非是系统自己建立。