图神经网络的健壮性(五)
本节是对论文《adversarial attacks on graph neural networks via meta learning》的学习,水平有限,欢迎指正错误!
论文地址:1902.08412
研究背景
这篇论文与第三篇所讲的论文都是2019年提出的,研究背景相差不大,这里简单带过。网络同质性为节点分类提供效益也给间接对抗攻击提供了可能(换句话说就是图神经网络依赖于消息传递)。
创新点
- 采用元梯度代替传统梯度用于解决投毒攻击的双层优化问题。
- 将深度学习模型基于梯度的优化过程颠倒过来,把输入数据当作一个待学习的超参数来处理。
元学习
参考博客:通俗讲解元学习(Meta-Learning)-CSDN博客
这篇博客说的很清晰了,简单总结下,元学习较传统机器学习算法的不同之处在于,一个是在学习算法参数,一个不仅学习算法参数、连算法也可以学习。举个例子,我们如果想用全连接神经网络来训练一个模型,我们会设定神经网络的层数、隐藏层单元数、损失函数、学习率等,然后使用训练集得到最优的权重,再将模型应用于测试集;而在元学习中,我们连这些(神经网络的层数、隐藏层单元数、损失函数)都不必指定,直接将其也当做需要训练的参数,让其在训练过程中自行生成。
在这篇论文中,元学习体现在作者将输入(指的是邻接矩阵,这篇论文只关注增加\删除边的操作,因此把特征矩阵当做常量看待)看做超参数,在训练过程中不断更新,最终得到最优的被修改后的邻接矩阵。
攻击目标
属于全局攻击,没有确切目标节点。
在此之前,所有已经提出的图对抗攻击方法都是有目标攻击。该算法旨在进行全局攻击,降低模型的整体分类性能。也就是说,目标是让测试样本被分类到与真实类别不同的任何类别中。
攻击者知识
属于灰盒攻击。
在这篇研究中,我们专注于有限知识攻击,即攻击者对分类模型及其训练后的权重一无所知,但攻击者对数据的了解程度与分类器相同,换句话说,就是攻击者和分类器都能观察到所有节点的属性、图结构以及带标签的节点的标签集。
攻击约束
三个约束条件:
1、总预算不能超过
![]()
2、修改后的图邻接矩阵必须满足度分布的不可察觉性约束,确保攻击者只能对图的度分布进行轻微修改。
3、保证攻击过程中没有节点断开连接。
作者将所有符合条件的扰动后的图集合记作。
图攻击的双层优化问题
双层优化公式解读
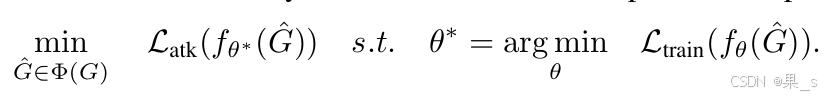
简单来说,就是我用被干扰的样本训练了一个模型,得到了最优参数(内层优化),又拿这个最优参数在众多被干扰图中选出一个干扰效果最强的(外层优化)。
这里我有一个疑惑,在于内外层优化中都使用到了被干扰样本
。
内层优化的目标是找到在被干扰数据
。在实际的攻击场景中,攻击者希望在干扰后的图数据上,让模型按照正常的训练方式去寻找一组最优参数,就如同在正常训练中寻找使模型性能最佳的参数一样。只不过这里的训练数据是被干扰过的,找到的最优参数
外层优化是在众多满足约束条件的被干扰图
最小的那个
这种内外层都使用被干扰样本的设计,完整地模拟了攻击者干扰模型训练数据,进而影响模型性能的过程。内层体现了模型在受干扰数据上的训练过程,外层则是攻击者从众多干扰方案中寻找最优攻击策略的过程,二者结合,最终实现攻击者对模型进行有效攻击,降低其对未标记节点分类性能的目的。
当然如果还有些疑惑,可以继续往下看算法实现。
攻击损失的定义
这里要提及的是关于的定义,文中提到两种定义方式:
第一种,令,这种想法思路比较简单,因为我们总是希望攻击后模型效果越来越差,那么如果和训练损失刚好相反,就可以实现这个目标。
第二种,令,在训练时,我们可以通过已知节点的标签去推测未知节点的标签,因此我们可以先在原始图数据上训练一个模型去把未知节点的标签全部预测出来,这一步被称为自学习(self-learning)。然后攻击目标就可以描述为,让未知节点的标签尽量和我们自学习得到的标签不同。
这里可能会有疑问,这两种攻击损失的定义有什么不同吗?
是在被修改样本上训练出来的,使用这个定义攻击损失的含义是尽量使未知节点的标签不要和已经在被修改样本上训练好的模型预测的标签相同。
而
是在原始样本上训练出来的。
简言之,第一种定义基于训练数据的训练损失来间接实现攻击,第二种定义则基于对未标记节点标签的预测以及在未标记节点上计算的损失来实现攻击,二者的核心区别在于损失计算所依赖的数据及方式不同。
元梯度
元梯度就是用于解决这个双层优化问题的。
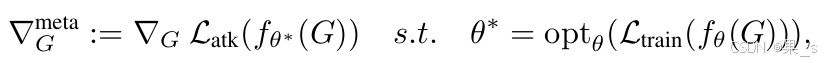
公式如上,其实和双层优化公式是很相似的,只是现在考虑的是在对其进行一点点微小干扰时的变化。
直接计算元梯度是代价相当昂贵的,为此,作者还引入了近似计算:
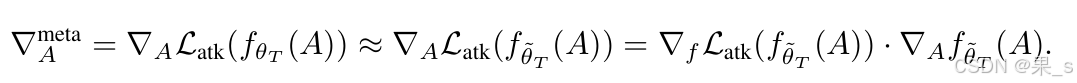
不再具体解释这个公式是怎么一步步推导得到的了,感兴趣的可以去自行阅读这篇论文。
算法实现
文中附录给出了算法步骤:

输入:
Graph G = (A, X):表示输入的图结构,其中A是邻接矩阵,描述了图中节点之间的连接关系;X是节点特征矩阵,记录了每个节点的特征信息。modification budget ∆:表示允许对图进行修改的预算,即最多可以进行多少次边的插入或删除操作。number of training iterations T:训练迭代的次数,即模型在训练过程中进行参数更新的次数。training class labels:训练数据的类别标签,用于训练代理模型。
这里采用方式计算攻击损失,因此首先训练了自学习模型后得到预测标签
。
要提醒的是由于设定图邻接矩阵是对称的,也就是说修改一条边会导致两个值发生改变,因此预算是。
算法循环主体:
- 在修改后的邻接矩阵
上迭代
次训练出一个模型,得到最优参数
- 计算元梯度
,方便计算扰动性得分S
- 计算每条边的扰动得分后,选择符合约束条件的且得分最高的边进行修改,如果边存在,则删除;不存在,则添加。
算法中没有显式提到攻击损失,但是从元梯度计算到扰动性得分,已经暗含了这部分内容。优化问题,蓝色框的是内层优化,橙色的是外层优化:
