LLM基础·Huggingface使用教程
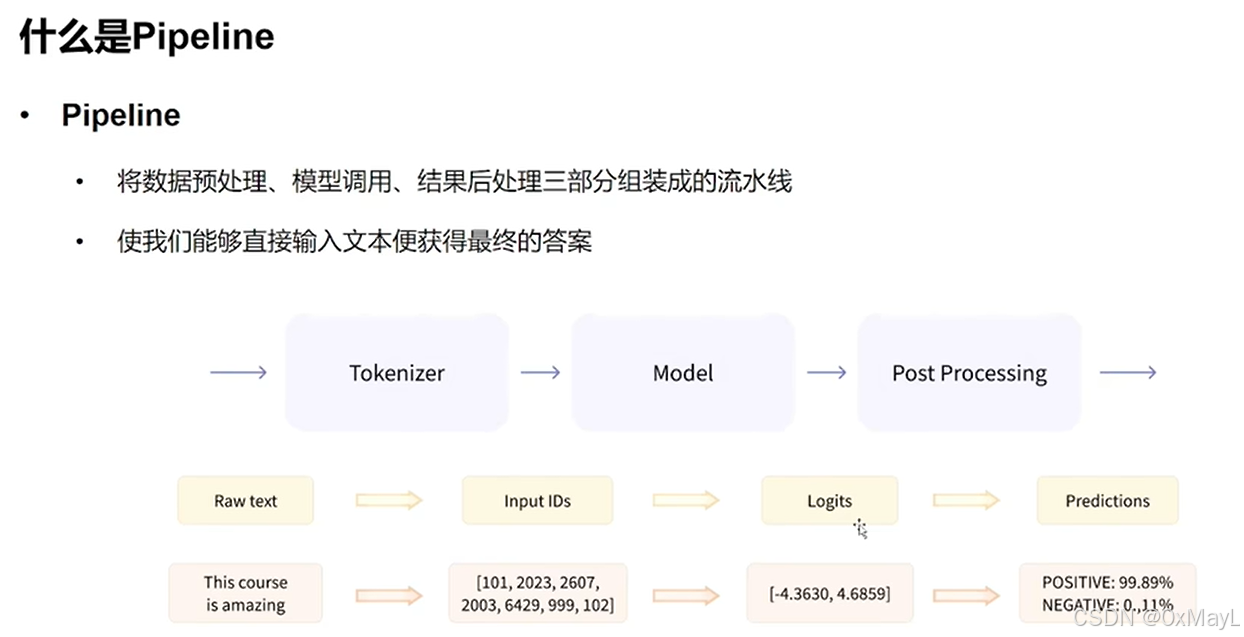
Pipeline
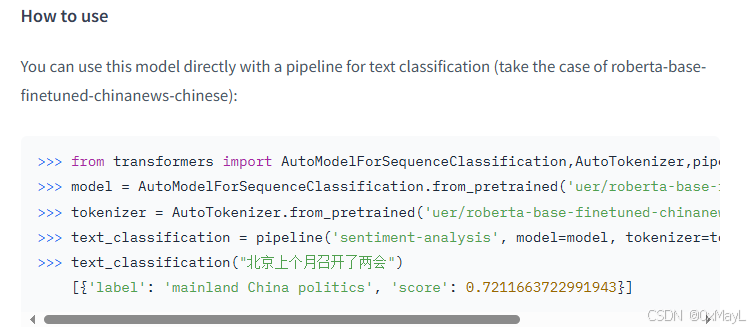
加载模型
不需要记忆,只需要在官网找就行。
- 注意
local_path指的是权重相关文件的目录路径. - 注意
device参数需配置,默认部署于CPU上.
local_path='model\models--uer--roberta-base-finetuned-dianping-chinese'
pipe = pipeline("text-classification", model=local_path,device=0)
- 分别加载模型和分词器,但是注意这个类不要用错了。
model=AutoModelForSequenceClassification.from_pretrained(local_path)
AutoTokenizer=AutoTokenizer.from_pretrained(local_path)
pipe=pipeline("text-classification", model=model, tokenizer=AutoTokenizer)
pipe("很好玩")
[{'label': 'positive (stars 4 and 5)', 'score': 0.9271045327186584}]Tokenizer
分词+编码+中间过程(填充、阶段等)

encode和decode
encode
- 分词+编码
- 注意:add_special_tokens=True这一个参数,默认是添加的。
- 可以设置填充和截断
- 开启
max_length参数后,默认是截断,默认不开启填充。
# 截断
ids = tokenizer.encode(sen, max_length=20, truncation=True,padding="max_length")
ids
[101,2483,2207,4638,2769,738,3300,1920,3457,2682,106,102,0,0,0,0,0,0,0,0]
decode
只针对编码后的结果进行解码,返回完整的句子,默认是保留特殊token的
str_sen = tokenizer.decode(ids, skip_special_tokens=False)
str_sen
'[CLS] 弱 小 的 我 也 有 大 梦 想! [SEP]'
encode_plus
- 在encode基础上增加了掩码(对应填充)和其他信息(例如区分Bert的SEQ的掩码)
inputs = tokenizer.encode_plus(sen, padding="max_length", max_length=20)
inputs
{'input_ids': [101, 2483, 2207, 4638, 2769, 738, 3300, 1920, 3457, 2682, 106, 102, 0, 0, 0, 0, 0, 0, 0, 0], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0]}
tokenizer的call函数=encode_plus
inputs = tokenizer(sen, padding="max_length", max_length=15,return_tensors='pt')
inputs
Model
有点类似骨干和输出头的关系,AutoModel只是骨干,AutoConfig定义了骨干接受的一些参数,AutoModelForSequenceClassification作为具体的模型,包括骨干+输出头,输出的是预期结果,而不是中间特征。
AutoConfig
- 配置了模型的基本权重
config = AutoConfig.from_pretrained(local_path)
config
BertConfig {"_name_or_path": "","architectures": ["BertForMaskedLM"],"attention_probs_dropout_prob": 0.1,"classifier_dropout": null,
...
}
AutoModel
- 不带model head,输出结果有多个,可以定制多个
model = AutoModel.from_pretrained(local_path)
output = model(**inputs)
output
output.last_hidden_state.size()
torch.Size([1, 12, 768])
AutoModelForSequenceClassification
- 具体的模型,可以看到已经是后处理的结果了(包括输出头)。
clz_model = AutoModelForSequenceClassification.from_pretrained(local_path, num_labels=10)
output=clz_model(**inputs)
SequenceClassifierOutput(loss=None, logits=tensor([[-0.1186, -0.0889, 0.5786, 0.5472, -0.1552, -0.0849, 0.2084, 0.1590,-0.1090, 0.3114]], grad_fn=<AddmmBackward0>), hidden_states=None, attentions=None)