【论文精读】AID:打通 Image2Video 与文本引导视频预测的关键技术
标题:AID: Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction
作者:Zhen Xing、Qi Dai、Zejia Weng、Zuxuan Wu、Yu-Gang Jiang
单位:1. 复旦大学(Fudan University);2. 微软亚洲研究院(Microsoft Research Asia)
发表:Preprint. Under review.
论文链接:https://arxiv.org/abs/2406.06465v1 / https://arxiv.org/pdf/2406.06465
项目主页:https://chenhsing.github.io/AID
代码链接:暂无
关键词:文本引导视频预测(Text-guided Video Prediction, TVP)、Image2Video 扩散模型、多模态大语言模型(MLLM)、双查询 Transformer(DQFormer)、适配器(Adapter)、Stable Video Diffusion(SVD)、帧一致性、时间稳定性
在虚拟现实、机器人控制、内容创作等领域,文本引导的视频预测(Text-guided Video Prediction, TVP)是一项核心任务 —— 它要求根据初始帧和文本指令,生成符合动态逻辑的未来视频帧。然而,现有方法受限于视频数据集规模,普遍存在帧一致性差、时间稳定性弱等问题。
复旦大学与微软亚洲研究院联合提出的 AID(Adapting Image2Video Diffusion Models for Instruction-guided Video Prediction),创新性地将预训练 Image2Video 扩散模型的视频动态先验与文本控制结合,在 4 个主流数据集上实现了对 SOTA 方法的大幅超越(Bridge 数据集 FVD 提升 91.2%,SSv2 数据集 FVD 提升 55.5%)。
一、任务背景与核心挑战
在深入技术细节前,我们需要先明确 TVP 任务的定位、现有方案的痛点,以及 AID 试图解决的核心问题。
1.1 任务定义:从 “无控生成” 到 “指令驱动预测”
TVP 的核心目标是:给定一段视频的前 K 帧(初始帧)和文本指令,预测后续 N-K 帧,且生成结果需严格遵循指令逻辑。例如,输入 “将杯子从桌子上拿起” 的指令和初始帧,模型需生成 “手靠近杯子→拿起杯子→离开桌面” 的连贯视频。
它与传统任务的区别如下:
- 与 Text-to-Video(T2V)的区别:T2V 更侧重 “创造性生成”(如生成 “宇航员在火星散步” 的虚构视频),而 TVP 侧重 “准确性预测”(需基于真实初始帧,符合物理规律和指令逻辑);
- 与 Image2Video 的区别:Image2Video(如 SVD)仅能基于单张图片生成无控视频(如重复初始帧动态),无法响应文本指令,如图 1 所示。
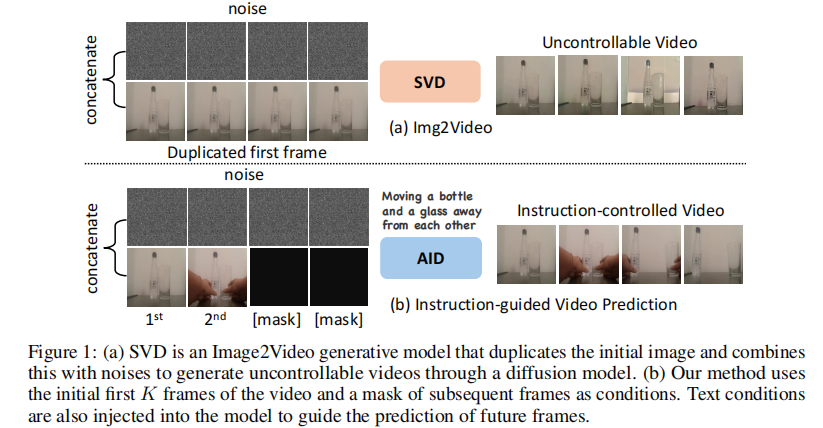
图 1 (a) SVD 作为典型 Image2Video 模型,仅能通过 “初始帧 + 噪声” 生成无控视频;(b) AID 通过 “初始 K 帧 + 文本指令 + 掩码帧”,生成受指令控制的未来帧。
1.2 现有方案的三大核心痛点
论文指出,此前 TVP 方法主要基于 Text-to-Image(T2I)模型(如 Stable Diffusion)扩展,但存在三个难以解决的问题:
- 缺乏视频动态先验:T2I 模型仅学习图像静态特征,未捕捉视频的时间关联性,导致生成帧出现 “跳变”“重影” 等一致性问题;
- 文本与视觉的对齐不足:单句文本难以完整描述视频的动态过程(如 “拿起杯子” 未明确 “手的轨迹”“杯子的角度变化”),现有方法无法将文本指令分解为帧级控制信号;
- 迁移成本高:特定领域(如机器人操作、第一视角烹饪)的视频数据集规模小,直接训练模型易过拟合,且全量微调预训练模型的计算成本极高。
1.3 AID 的核心思路:借力预训练 Image2Video 模型
论文的关键观察是:预训练 Image2Video 模型(如 SVD)已在大规模数据集上学习到 robust 的视频动态先验(如物体运动规律、帧间关联性),但缺乏文本控制能力。
因此,AID 的核心思路可概括为 “迁移先验 + 注入控制”:
- 迁移先验:以 SVD(Stable Video Diffusion)为基础模型,复用其在大规模视频上学习的动态特征;
- 注入控制:设计文本 - 视觉融合模块,将文本指令转化为可指导扩散过程的控制信号;
- 高效适配:通过轻量化适配器(Adapter),实现模型向特定数据集的快速迁移,避免全量微调。
二、AID 的整体框架
AID 的框架围绕 “如何将文本控制与 Image2Video 模型结合” 展开,整体分为数据预处理、文本条件注入、适配器建模、扩散生成四大模块。其端到端流程如图 2 所示,我们先建立整体认知,再逐一拆解关键组件。
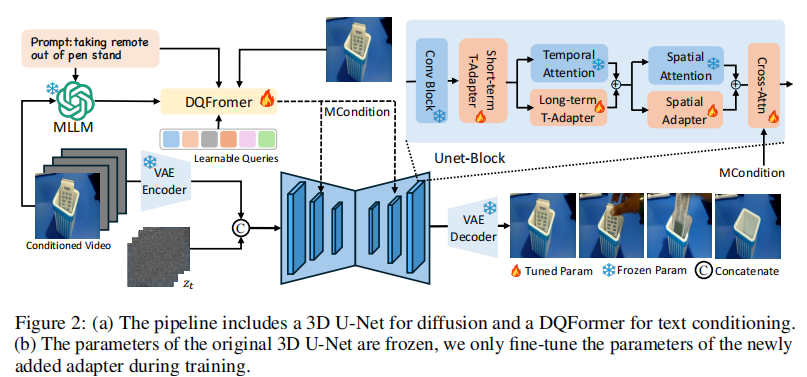
图 2 (a) 框架核心包括:VAE 编码器(将初始帧转为 latent)、DQFormer(生成多模态条件 MCondition)、3D UNet(扩散 denoising)、VAE 解码器(重建视频帧);(b) 训练时冻结原始 SVD 的 UNet 和 VAE 参数,仅微调 DQFormer 和适配器,大幅降低计算成本。
框架的核心逻辑可总结为三步:
- 输入处理:初始 K 帧经 VAE 编码器转为条件 latent,后续 N-K 帧用 “掩码” 表示,与噪声 latent 在通道维度拼接;
- 条件生成:通过 DQFormer 将 “初始帧视觉特征 + 文本指令 + MLLM 预测的状态描述” 融合为 MCondition(多模态条件);
- 扩散生成:MCondition 通过交叉注意力注入 UNet,指导 denoising 过程,最终经 VAE 解码器输出完整视频。
三、核心创新技术拆解
AID 的突破点集中在三个方面:基于 MLLM 的视频状态建模、双分支 DQFormer 的条件融合、轻量化适配器的高效迁移。这三大技术共同解决了 “文本 - 视觉对齐”“动态先验复用”“低成本迁移” 三大痛点。
3.1 第一步:用 MLLM 破解 “文本动态描述不足” 问题
单句文本指令(如 “拿起杯子”)无法完整描述视频的时间动态 —— 模型不知道 “何时手开始动”“动的轨迹如何”。为解决这一问题,AID 引入多模态大语言模型(MLLM,如 LLaVA),将 “初始帧 + 文本指令” 转化为 “多阶段状态描述”,为后续帧级控制提供依据。
具体流程:
- 输入 MLLM 的 prompt 设计:将初始帧和文本指令组合为提示,例如:“我有一个视频生成指令:< 将药片盒的一端抬起,然后放下>。请根据给定图像,将这个过程拆分为 4 个状态描述。”
- MLLM 输出帧级状态:MLLM 基于视觉内容和指令逻辑,生成细粒度的状态序列,例如:
- 药片盒平放在深色表面,未被触碰;
- 药片盒的一端被抬起,形成倾斜角度,另一端仍接触表面;
- 抬起的一端被释放,开始向表面回落;
- 药片盒接触表面,恢复原位或轻微反弹。

图 3 MLLM 通过 “初始帧 + 文本指令”,将动态过程拆解为离散状态,为后续帧级控制提供文本依据。
这一步的核心价值是:将 “模糊的文本指令” 转化为 “可对齐到帧的状态序列”,解决了文本与视频时间维度的对齐问题。
3.2 第二步:DQFormer—— 双分支融合多模态条件
有了 MLLM 生成的状态描述,下一步需要将 “初始帧视觉特征”“文本指令特征”“MLLM 状态特征” 融合为统一的多模态条件(MCondition),并注入扩散模型。AID 设计的双查询 Transformer(DQFormer) 是实现这一目标的核心组件。
DQFormer 的输入与输出
- 输入特征:
- 视觉特征 v:初始帧经 CLIP 视觉编码器提取;
- 指令特征 t₁:原始文本指令经 CLIP 文本编码器提取;
- 状态特征 t₂:MLLM 生成的多状态描述经 CLIP 文本编码器提取。
- 输出:MCondition(融合后的多模态条件,将作为 UNet 交叉注意力的 Key 和 Value)。
双分支设计与数学表达
DQFormer 通过两个并行分支,分别实现 “跨模态对齐” 和 “帧级分解”,最终拼接为 MCondition,结构如图 4 所示。
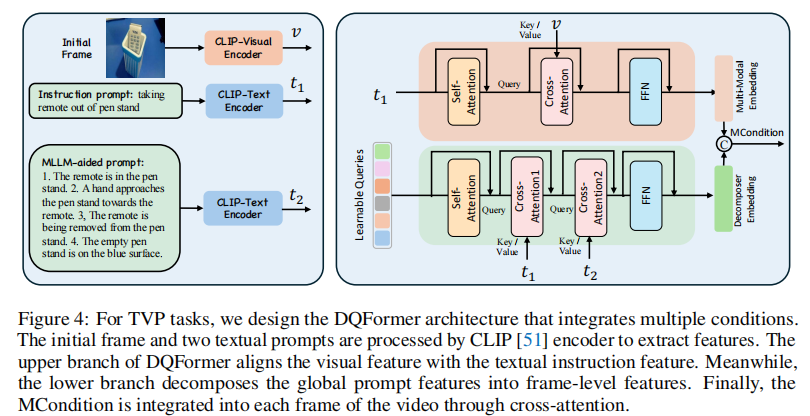
图 4 上分支实现 “视觉 - 指令对齐”,下分支实现 “状态特征的帧级分解”,两者拼接形成 MCondition。
分支 1:多模态对齐分支(Multimodal Embedding)
目标:将初始帧的视觉特征与文本指令特征对齐,确保模型理解 “指令对应的视觉对象”(如 “杯子” 在初始帧中的位置)。流程:
- 对指令特征 t₁进行自注意力(Self-Attn),强化指令内部语义关联;
- 与视觉特征 v 进行交叉注意力(Cross-Attn),建立 “文本概念 - 视觉区域” 的映射;
- 经前馈网络(FFN)输出对齐后的多模态嵌入。
数学表达:
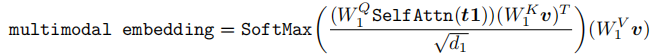
其中, 为可学习参数,
为缩放系数(避免梯度消失)。
分支 2:帧级分解分支(Decomposed Embedding)
目标:将 MLLM 生成的多状态特征 t₂,分解为与 “每帧” 对应的控制信号(如第 2 帧对应 “手靠近杯子”,第 3 帧对应 “拿起杯子”)。流程:
- 初始化可学习查询向量 Q(维度为
,N 为总帧数,
对齐 CLIP 文本长度);
- Q 先与 t₁进行交叉注意力,学习 “指令与帧的关联”;
- 再与 t₂进行交叉注意力,将多状态特征分配到对应帧;
- 经 FFN 输出帧级分解嵌入。
数学表达:
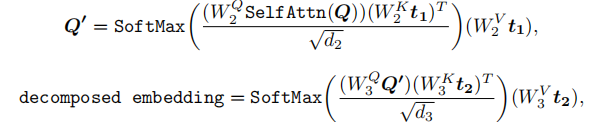
最终 MCondition
将两个分支的输出拼接,得到最终的多模态条件:
![]()
(![]() 表示通道维度拼接)
表示通道维度拼接)
3.3 第三步:适配器建模 —— 低成本迁移与性能提升
预训练 Image2Video 模型(如 SVD)的参数规模庞大(UNet 含数千万参数),若直接在小数据集上全量微调,会导致过拟合和高计算成本。AID 设计了三类轻量化适配器(Adapter),仅训练少量参数(约占原模型的 1%),即可实现模型向特定数据集的迁移,并提升时间稳定性和空间一致性。
适配器的核心设计原则
- 冻结原模型:SVD 的 UNet、VAE 参数全部冻结,仅训练适配器和 DQFormer;
- 即插即用:适配器嵌入原模型的关键位置(空间注意力、时间建模层),不改变原结构;
- 针对性优化:三类适配器分别解决 “空间分布适配”“短期动态适配”“长期动态适配” 问题。
三类适配器的结构与功能
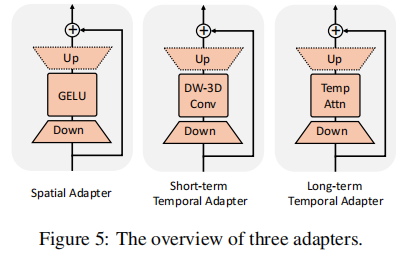
图 5 从左到右分别为空间适配器、短期时间适配器、长期时间适配器,均采用 “残差连接 + 轻量化结构” 设计。
1. 空间适配器(Spatial Adapter)
目标:适配特定数据集的空间分布(如机器人数据集的 “机械臂 + 工作台” 布局、烹饪数据集的 “灶台 + 厨具” 布局)。结构:由 “下采样线性层 + GELU 激活 + 上采样线性层” 组成,如图 5(左图) 所示。
- 下采样:将输入特征维度压缩,降低计算量;
- 上采样:恢复原维度,并通过 “零初始化” 确保初始时不干扰原模型输出;
- 残差连接:保留原模型的空间特征,仅补充数据集特定的空间信息。
数学表达:
![]()
( 为下采样权重,
为上采样权重)
2. 短期时间适配器(Short-term Temporal Adapter, ST-Adapter)
目标:捕捉相邻帧的短期动态(如 “手移动 1cm”“杯子倾斜 5 度” 等细粒度变化)。结构:在 “下采样 - 上采样” 之间加入深度可分离 3D 卷积(Depth-wise 3D Conv),如图 5(中图) 所示。
- 3D 卷积:捕捉帧间的时间关联性(如 t 时刻与 t+1 时刻的像素变化);
- 深度可分离:相比标准 3D 卷积,参数量减少 8-9 倍,兼顾效率与性能。
数学表达:
![]()
3. 长期时间适配器(Long-term Temporal Adapter, LT-Adapter)
目标:捕捉长序列帧的全局动态(如 “拿起杯子→移动到冰箱→放下” 的完整轨迹)。结构:在 “下采样 - 上采样” 之间加入时间自注意力(Temporal Self-Attn),如图 5(右图) 所示。
- 自注意力:建模非相邻帧的依赖关系(如第 1 帧与第 10 帧的位置关联);
- 区别于 ST-Adapter:ST-Adapter 侧重局部相邻帧,LT-Adapter 侧重全局长序列。
数学表达:
![]()
四、技术细节补充:扩散模型基础与推理策略
AID 基于连续时间扩散模型框架,且在推理阶段采用了多条件引导策略,这部分是理解模型运行机制的关键补充。
4.1 扩散模型基础:从噪声到视频的生成过程
扩散模型的核心是 “先向数据中添加噪声,再学习从噪声中恢复数据”。AID 采用 EDM(Elucidating the Design Space of Diffusion Models)预条件框架,其关键公式如下:
1. 噪声添加过程
设原始数据分布为 (
为干净视频帧),向
中添加方差为
的独立高斯噪声,得到含噪数据
(
)。当
足够大时,
近似服从
。
2. 去噪过程(核心)
模型学习一个去噪器 ,输入含噪数据
、噪声尺度
和条件
(即 MCondition),输出恢复的干净数据
。去噪器通过去噪分数匹配(Denoising Score Matching) 优化,损失函数为:
![]()
其中, 为噪声尺度的权重函数,
。
3. 分数函数近似
扩散模型的核心是对 “分数函数” (描述数据在含噪空间中的概率密度梯度)的近似,AID 中用
表示:
4.2 推理阶段的多条件引导策略
为平衡 “初始帧一致性” 和 “文本指令遵循度”,AID 在推理时采用双条件引导(Frame Condition + Text Condition),公式如下:
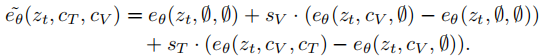
其中:
:t 时刻的 latent 特征;
:初始帧条件,\(c_T\):文本条件;
:帧条件引导系数(控制生成帧与初始帧的一致性);
:文本条件引导系数(控制生成帧对指令的遵循度);
:噪声预测网络(输出对噪声的估计)。
这一策略避免了 “仅依赖初始帧导致无法响应指令” 或 “仅依赖文本导致与初始帧脱节” 的问题。
五、实验验证:全面评估 AID 的性能
论文在4 个主流数据集(Something Something V2、Bridge Data、Epic Kitchen-100、UCF-101)上进行了定量与定性实验,充分验证了 AID 的有效性。
5.1 实验设置
1. 数据集详情
| 数据集 | 任务场景 | 视频类型 | 评估配置 |
|---|---|---|---|
| Something Something V2(SSv2) | 日常人类动作 | 第三人称动作视频(如 “拿起杯子”) | 2 个参考帧,2048 个验证样本,12 帧 / 视频 |
| Bridge Data | 机器人操作 | 机械臂操作视频(如 “将玉米放入锅中”) | 1 个参考帧,5558 个验证样本,16 帧 / 视频 |
| Epic Kitchen-100(Epic100) | 第一视角烹饪 | 厨房活动视频(如 “打开冰箱”) | 1 个参考帧,9342 个验证样本,12 帧 / 视频 |
| UCF-101 | 动作分类 | 101 类人类动作(如 “骑自行车”) | 1/5 个参考帧,2048 个测试样本,16 帧 / 视频 |
2. 基线方法
论文对比了 8 类 SOTA 方法,覆盖三类技术路线:
- 扩散模型类:Seer(SOTA)、Tune-A-Video、MCVD、PVDM、VideoFusion;
- 自回归 Transformer 类:TATS、MAGE;
- CNN 编码器 - 解码器类:SimVP。
3. 评估指标
- Fréchet Video Distance(FVD):衡量生成视频与真实视频的分布差异,值越小越好(核心指标);
- Kernel Video Distance(KVD):补充 FVD,衡量视频动态特征的相似度,值越小越好;
- Fréchet Inception Distance(FID):衡量单帧图像质量,值越小越好(UCF-101 数据集补充指标)。
5.2 定量结果:全面超越 SOTA
1. 核心数据集(SSv2、Bridge、Epic100)
表 1 展示了 AID 与基线方法的对比:
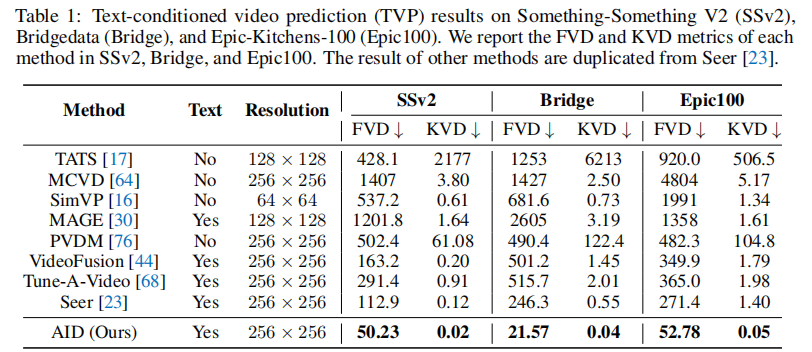
核心结论如下:
- 性能碾压:AID 在所有数据集的 FVD 和 KVD 上均排名第一。例如,Bridge 数据集上,AID 的 FVD 仅为 21.57,远低于 Seer 的 246.3(提升 91.2%);SSv2 数据集上,AID 的 FVD 为 50.23,低于 Seer 的 112.9(提升 55.5%);
- 文本控制的必要性:无文本控制的方法(如 TATS、MCVD)FVD 普遍大于 100,证明文本条件对 TVP 任务的关键作用;
- 分辨率优势:部分方法(如 TATS)分辨率仅为 128×128,而 AID 在 256×256 分辨率下仍保持最优性能,证明其对高分辨率视频的适配能力。
2. 扩展数据集(UCF-101)
UCF-101 为类条件视频生成数据集,AID 在该数据集上的实验主要验证 “模型对不同场景的适配能力”。
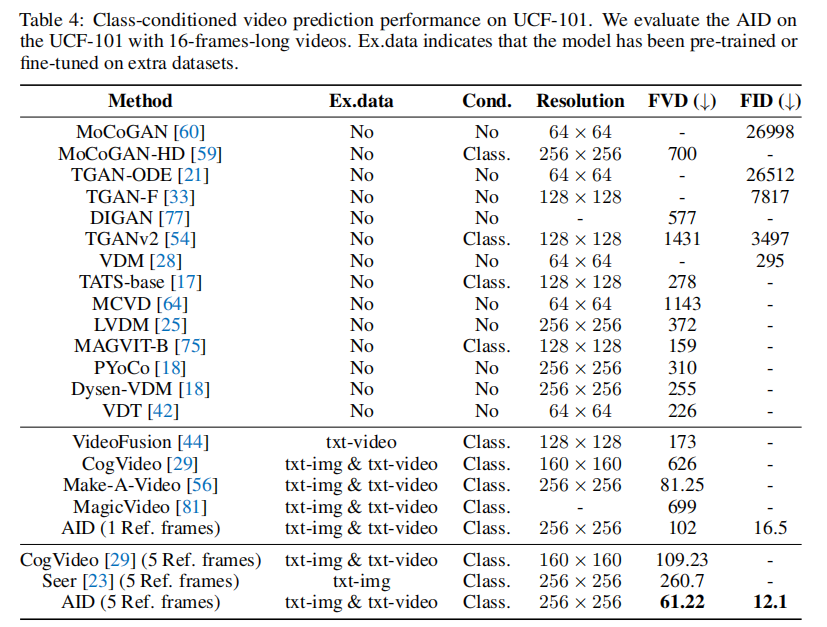
如表 4 所示:
- 当输入 1 个参考帧时,AID 的 FVD 为 102,FID 为 16.5,优于 CogVideo(FVD=626)、Seer(FVD=260.7);
- 当输入 5 个参考帧时,AID 的 FVD 进一步降至 61.22,FID 降至 12.1,证明更多初始帧能提升预测准确性;
- 与 Make-A-Video(FVD=81.25)相比,AID 在无额外文本 - 视频数据预训练的情况下,性能接近,证明其迁移能力的有效性。
5.3 定性结果:视觉一致性与指令遵循度
定量指标之外,定性结果更能直观体现 AID 的优势。论文对比了 AID 与 Seer(SOTA)、Gen-2(商用 Image2Video 模型)、Pika(商用模型)的生成效果,核心结论如下:
1. SSv2 数据集(日常动作)
如图 6 (a) 所示,指令为 “将盒子移向汽车”:
- Gen-2 和 Pika 无法理解指令,生成的盒子无明显移动;
- Seer 虽能移动盒子,但帧间存在重影(如第 4 帧盒子边缘模糊),且最终位置偏离 “汽车”;
- AID 生成的盒子轨迹连贯,最终准确靠近汽车,无重影或跳变。
2. Bridge 数据集(机器人操作)
如图 6 (b) 所示,指令为 “将玉米放入水槽中的锅中”:
- Gen-2 和 Pika 混淆了 “水槽” 和 “锅” 的位置,玉米未放入目标容器;
- Seer 生成的玉米出现重影,且机械臂动作不连贯;
- AID 准确识别 “水槽中的锅”,玉米完整放入容器,机械臂动作符合物理规律。

图 6 (a) SSv2 数据集示例(指令:将盒子移向汽车);(b) Bridge 数据集示例(指令:将玉米放入水槽中的锅中)。
5.4 消融实验:验证各组件的必要性
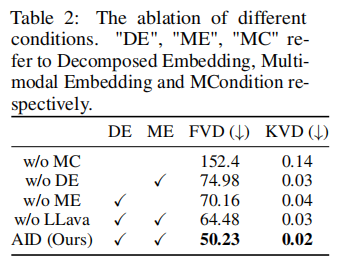
为明确 DQFormer、MLLM、适配器的贡献,论文在 SSv2 数据集上进行了消融实验。
1. MCondition 的消融(DQFormer 双分支 + MLLM)
表 2 显示,移除任何一个组件都会导致性能下降:
- 无 MCondition(不注入文本控制):FVD 骤升至 152.4,证明文本条件是 TVP 的核心;
- 无分解嵌入(DE):FVD 升至 74.98,证明帧级分解对动态一致性的重要性;
- 无多模态嵌入(ME):FVD 升至 70.16,证明视觉 - 文本对齐能提升指令遵循度;
- 无 MLLM:FVD 升至 64.48,证明 MLLM 生成的状态描述能补充文本指令的动态细节。
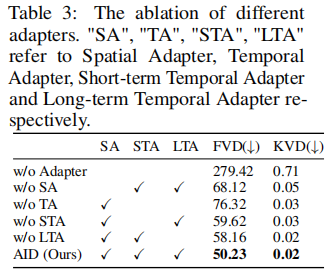
2. 适配器的消融
表 3 显示,三类适配器均对性能有显著贡献:
- 无任何适配器:FVD 升至 279.42,证明适配器是模型迁移的关键;
- 无空间适配器(SA):FVD 升至 68.12,证明空间适配能提升场景一致性;
- 无短期时间适配器(STA):FVD 升至 76.32,证明短期动态建模能减少帧跳变;
- 无长期时间适配器(LTA):FVD 升至 58.16,证明长期动态建模能提升全局连贯性。
六、总结与未来方向
AID 的核心价值在于:首次实现了预训练 Image2Video 模型向文本引导视频预测的迁移,通过 “MLLM 状态建模 + DQFormer 多模态融合 + 轻量化适配器” 三大创新,解决了 TVP 任务的核心痛点。其技术贡献可总结为三点:
- 范式创新:打破了 “TVP 依赖 T2I 模型扩展” 的传统思路,证明预训练 Image2Video 模型的动态先验能大幅提升视频一致性;
- 技术突破:DQFormer 双分支设计实现了 “跨模态对齐” 与 “帧级分解” 的统一,MLLM 状态建模填补了文本指令的动态细节空白;
- 工程价值:轻量化适配器仅需训练少量参数(约 1%),即可实现模型向特定领域的迁移,降低了工业应用门槛。
未来研究方向
结合论文讨论与领域趋势,AID 的后续优化可聚焦三个方向:
- 更长视频预测:当前 AID 主要处理 12-16 帧的短序列,未来可探索 “分层预测”(先预测关键帧,再补全中间帧),支持数百帧的长视频生成;
- 更细粒度控制:引入姿态、深度等额外条件,实现 “文本 + 视觉” 的多模态精细控制(如 “将杯子倾斜 30 度”);
- 更小模型规模:当前 AID 依赖 SVD 的大模型架构,未来可通过知识蒸馏、模型压缩,适配边缘设备(如机器人端侧推理)。
AID 的出现,不仅为 TVP 任务提供了新的 SOTA 方案,更启发了 “预训练模型迁移 + 任务特定控制” 的研究思路 —— 如何高效复用已有大模型的先验知识,同时注入细粒度控制,是未来生成式 AI 领域的重要方向。