hive中数据的来源
Hive中数据的来源
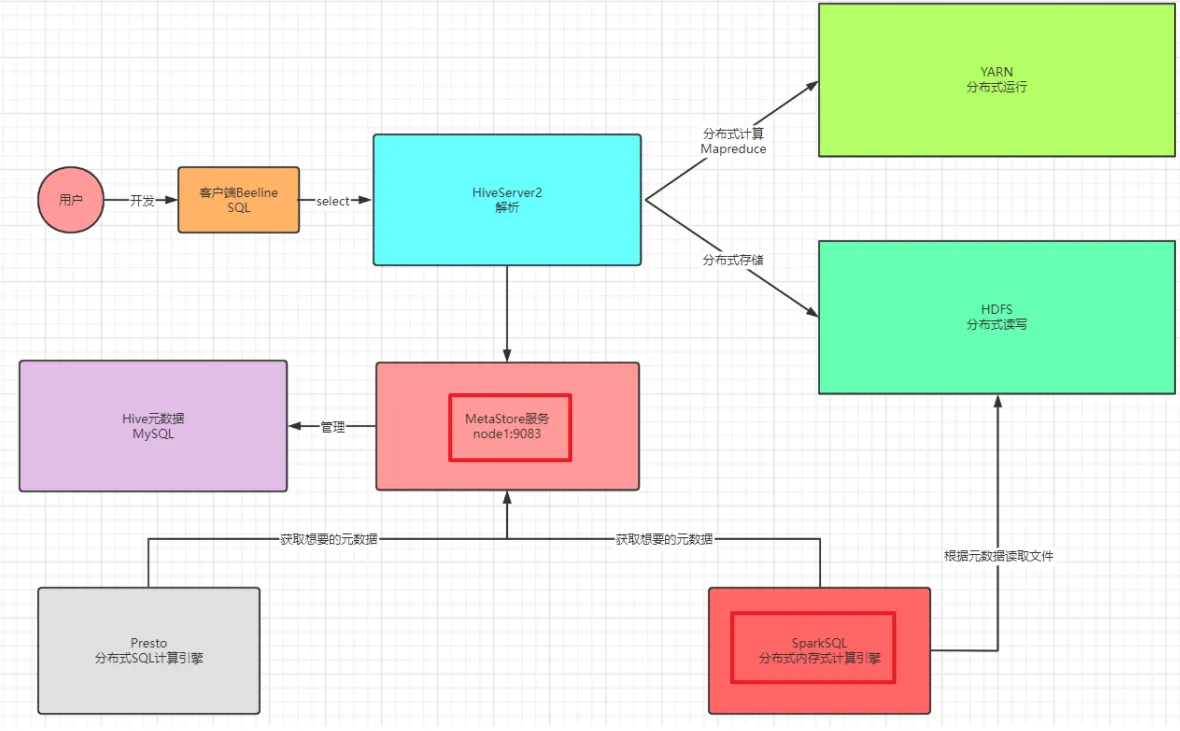
- 场景:Hive底层默认是MR引擎,计算性能特别差,一般用Hive作为数据仓库,使用SparkSQL对Hive中的数据进行计算
-
- 存储:数据仓库:Hive:将HDFS文件映射成表
- 计算:计算引擎:SparkSQL、Impala、Presto:对Hive中的数据表进行处理
- 问题:SparkSQL怎么能访问到Hive中有哪些表,以及如何知道Hive中表对应的HDFS的地址?
Hive中的表存在哪里?元数据--MySQL , 启动metastore服务即可。
本质上:SparkSQL访问了Metastore服务获取了Hive元数据,基于元数据提供的地址进行计算
开发环境如何编写代码,操作hive:
Pycharm工具集成Hive开发SparkSQL,必须申明Metastore的地址和启用Hive的支持
spark = SparkSession \
.builder \
.appName("HiveAPP") \
.master("local[2]") \
.config("spark.sql.warehouse.dir", 'hdfs://bigdata01:9820/user/hive/warehouse') \
.config('hive.metastore.uris', 'thrift://bigdata01:9083') \
.config("spark.sql.shuffle.partit