网站建设询价采购做网站的预算表
Python 自动化从入门到实战-一键将 Excel 表格转为 PDF 文件(3)
高效办公必备:Python实现Excel转PDF脚本及常见问题解决方案
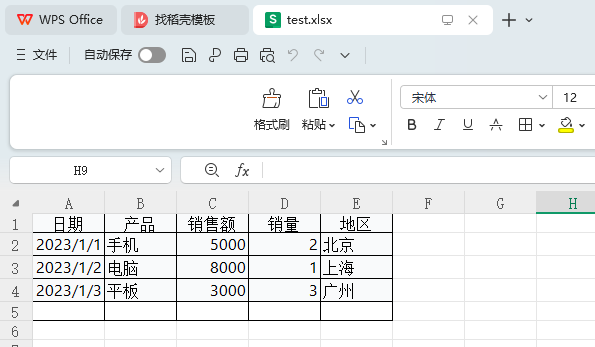
在日常办公中,我们经常需要将Excel表格转换为PDF格式以便分享、打印或存档。今天,我将为大家分享一个实用的Python脚本,不仅能解决Excel转PDF的基础需求,还能处理中文显示、日期格式优化、表格边框显示等常见问题。
一、功能概述
我们开发的excel_to_pdf_new.py脚本具有以下核心功能:
- 将Excel文件(.xls/.xlsx)一键转换为PDF格式
- 完美支持中文显示,解决乱码问题
- 智能处理日期格式,只显示年月日不显示时分秒
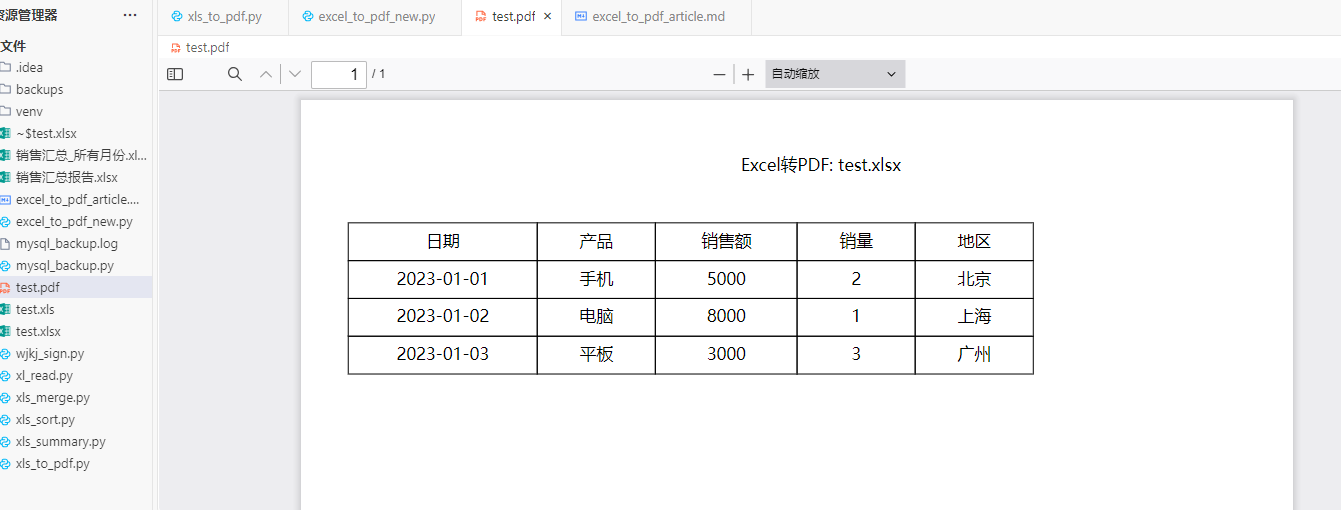
- 自动调整表格布局,确保所有列的边框完整显示
- 友好的错误提示和异常处理
二、技术实现要点
1. 核心依赖库
脚本主要使用了两个Python库:
- pandas:用于读取和处理Excel文件数据
- fpdf2:用于创建和格式化PDF文档
- openpyxl:用于处理Excel文件的底层库
2. 解决中文显示问题
中文字符显示是PDF生成中的常见痛点,我们通过以下方法解决:
# 自动检测操作系统并加载系统中文字体
if sys.platform.startswith('win'):font_path = r"C:\Windows\Fonts\msyh.ttc" # 微软雅黑
elif sys.platform.startswith('darwin'):font_path = r"/System/Library/Fonts/PingFang.ttc" # 苹方
elif sys.platform.startswith('linux'):font_path = r"/usr/share/fonts/truetype/wqy/wqy-microhei.ttc" # 文泉驿微米黑# 动态加载字体
if os.path.exists(font_path):pdf.add_font(family="Chinese", style="", fname=font_path)pdf.set_font(family="Chinese", size=12)
3. 日期格式优化
为了让日期显示更加简洁清晰,我们实现了只保留年月日的功能:
# 处理日期数据,针对第一列,只保留年月日部分
if not df.empty and len(df.columns) > 0:first_col = df.columns[0]# 检查是否为日期类型if pd.api.types.is_datetime64_any_dtype(df[first_col]):# 格式化日期,只保留年月日df[first_col] = df[first_col].dt.strftime('%Y-%m-%d')# 对于字符串类型,尝试转换为日期再格式化elif pd.api.types.is_string_dtype(df[first_col]):try:# 尝试不同的日期格式df[first_col] = pd.to_datetime(df[first_col], format='%Y-%m-%d', errors='coerce')# 如果成功转换为日期类型,则格式化if pd.api.types.is_datetime64_any_dtype(df[first_col]):df[first_col] = df[first_col].dt.strftime('%Y-%m-%d')except:pass
4. 表格边框完整显示解决方案
针对表格最后一列边框无法完整显示的问题,我们实现了动态计算单元格宽度的功能:
# 计算单元格宽度,确保所有列都能完整显示并保留边框
page_width = pdf.w - 2 * pdf.l_margin # 可用页面宽度(减去左右边距)
num_cols = len(df.columns)if num_cols > 0:# 动态计算单元格宽度,确保所有列能容纳在页面宽度内cell_width = min(40, page_width / num_cols)# 添加表头和数据,使用计算出的单元格宽度for col in df.columns:pdf.cell(w=cell_width, h=10, text=str(col), border=1, align='C')# 后续代码略...
三、安装与使用步骤
1. 安装必要的Python库
首先,确保您的Python环境已安装以下依赖库:
pip install pandas fpdf2 openpyxl
2. 下载脚本
将excel_to_pdf_new.py脚本保存到您的工作目录。
3. 使用方法
基本使用
在命令行中运行:
python excel_to_pdf_new.py
默认情况下,脚本会查找当前目录下的test.xlsx文件,并在同目录下生成同名的PDF文件。
自定义文件路径
您也可以修改脚本中的excel_to_pdf函数调用,指定Excel文件路径和输出PDF路径:
# 在脚本末尾添加
if __name__ == "__main__":excel_to_pdf("your_excel_file.xlsx", "output_pdf_file.pdf")
四、应用场景
这个脚本适用于以下办公场景:
- 报表分享:将月度/季度/年度Excel报表转换为PDF格式,方便邮件发送或群内分享
- 文档归档:将重要的Excel数据转换为不可编辑的PDF格式进行长期存档
- 会议材料:将Excel数据转换为PDF,作为会议材料发放给参会人员
- 财务文件:将财务数据、发票等转换为PDF,便于打印和保存
- 项目汇报:将项目进度表、甘特图等Excel文件转换为PDF格式进行汇报
五、常见问题与解决方案
1. 中文字体显示问题
如果PDF中中文显示异常,请检查您的系统是否安装了相应的中文字体(如微软雅黑、宋体等)。
2. Excel文件格式兼容性
脚本主要支持.xlsx格式的Excel文件,对于.xls格式的旧版文件,建议先转换为.xlsx格式再进行处理。
3. 表格内容过多问题
如果Excel表格内容过多,可能会导致PDF页面布局问题。对于复杂表格,建议拆分处理或调整列宽后再转换。
4. 大文件处理
处理大型Excel文件时,可能会消耗较多内存,请确保您的电脑有足够的内存空间。
六、完整代码
import pandas as pd
from fpdf import FPDF
from fpdf import FontFace
import os
import sysdef excel_to_pdf(excel_path, pdf_path=None, column_widths=None):"""将Excel文件转换为PDF文件(支持中文)参数:excel_path: Excel文件路径pdf_path: 输出PDF文件路径,默认为与Excel同目录同名称column_widths: 可选,每一列的宽度列表,如果不提供则自动计算"""# 检查文件是否存在if not os.path.exists(excel_path):print(f"错误:文件 {excel_path} 不存在")return# 设置默认PDF路径if pdf_path is None:file_name = os.path.splitext(os.path.basename(excel_path))[0]pdf_path = os.path.join(os.path.dirname(excel_path), f"{file_name}.pdf")try:# 读取Excel文件df = pd.read_excel(excel_path)# 处理日期数据,针对第一列,只保留年月日部分if not df.empty and len(df.columns) > 0:first_col = df.columns[0]# 首先尝试直接检查和格式化日期类型if pd.api.types.is_datetime64_any_dtype(df[first_col]):# 格式化日期,只保留年月日df[first_col] = df[first_col].dt.strftime('%Y-%m-%d')# 如果是字符串类型,尝试转换为日期再格式化elif pd.api.types.is_string_dtype(df[first_col]):try:# 尝试不同的日期格式来避免警告# 先尝试常见的ISO格式try:df[first_col] = pd.to_datetime(df[first_col], format='%Y-%m-%d', errors='coerce')# 如果转换后有效数据不足50%,尝试另一种格式if df[first_col].isna().sum() / len(df) > 0.5:# 尝试中文日期格式df[first_col] = pd.to_datetime(df[first_col], format='%Y年%m月%d日', errors='coerce')# 如果仍不理想,尝试自动解析if df[first_col].isna().sum() / len(df) > 0.5:df[first_col] = pd.to_datetime(df[first_col], errors='coerce')except:# 如果指定格式失败,使用自动解析df[first_col] = pd.to_datetime(df[first_col], errors='coerce')# 如果成功转换为日期类型,则格式化if pd.api.types.is_datetime64_any_dtype(df[first_col]):# 保存原始值,用于无法解析的日期original_values = df[first_col].copy()# 格式化有效的日期值df[first_col] = df[first_col].dt.strftime('%Y-%m-%d').fillna(original_values.astype(str))except:# 转换失败,保持原字符串不变pass# 创建PDF对象pdf = FPDF()pdf.add_page()# 设置字体,支持中文# 使用系统字体目录中的中文字体# 如果是Windows系统,尝试使用微软雅黑font_path = ""if sys.platform.startswith('win'):font_path = r"C:\Windows\Fonts\msyh.ttc" # 微软雅黑elif sys.platform.startswith('darwin'):font_path = r"/System/Library/Fonts/PingFang.ttc" # 苹方elif sys.platform.startswith('linux'):font_path = r"/usr/share/fonts/truetype/wqy/wqy-microhei.ttc" # 文泉驿微米黑# 如果找不到系统字体,使用FPDF内置字体处理英文if os.path.exists(font_path):pdf.add_font(family="Chinese", style="", fname=font_path)pdf.set_font(family="Chinese", size=10)else:pdf.set_font(family="helvetica", size=10)print("警告:未找到中文字体,可能无法正确显示中文")# 添加标题(使用新版API参数名)title_text = f"Excel转PDF: {os.path.basename(excel_path)}"pdf.cell(w=200, h=8, text=title_text, align='C', new_x="LMARGIN", new_y="NEXT")pdf.ln(8) # 空行# 计算单元格宽度,确保所有列都能完整显示并保留边框page_width = pdf.w - 2 * pdf.l_margin # 可用页面宽度(减去左右边距)num_cols = len(df.columns)# 如果提供了column_widths参数,则使用手动设置的宽度# 否则自动计算宽度use_auto_width =False # column_widths is None or len(column_widths) != num_cols# 准备列宽列表if use_auto_width:# 自动计算宽度(不超过40,同时确保所有列能容纳在页面宽度内)cell_width = min(40, page_width / num_cols)column_widths = [cell_width] * num_colselse:# 验证手动设置的宽度总和不超过页面宽度total_width = sum(column_widths)if total_width > page_width:print(f"警告:所有列的总宽度({total_width})超过页面可用宽度({page_width}),可能会导致显示问题")# 添加表头,确保所有边框完整显示for i, col in enumerate(df.columns):pdf.cell(w=column_widths[i], h=8, text=str(col), border=1, align='C')pdf.ln() # 换行# 添加表格数据,确保所有边框完整显示for _, row in df.iterrows():for i, col in enumerate(df.columns):# 确保文本不超出单元格宽度,必要时截断显示cell_text = str(row[col])col_width = column_widths[i]# 计算文本长度并在必要时截断font_size = pdf.font_size_pt# 估算文本在当前字体和大小下的宽度(大约每个字符6个单位)text_width_estimate = len(cell_text) * 6# if text_width_estimate > col_width * 0.9: # 如果文本太长,进行截断# # 计算可以显示的字符数# max_chars = int((col_width * 0.9) / 6)# cell_text = cell_text[:max_chars-3] + '...' # 截断并添加省略号pdf.cell(w=col_width, h=8, text=cell_text, border=1, align='C')pdf.ln() # 换行# 保存PDFpdf.output(pdf_path)print(f"转换成功!PDF文件已保存至:{pdf_path}")except Exception as e:print(f"转换失败:{str(e)}")if __name__ == "__main__":# 示例:转换当前目录下的test.xlsx文件# 手动设置每一列的宽度,根据需要调整# 这里提供了一个默认的宽度列表,用户可以根据实际表格列数和内容调整excel_file = "test.xlsx"# 假设Excel文件有5列,可以根据实际情况调整# 示例:第一列日期宽度设为25,其他列根据内容重要性设置不同宽度column_widths = [40, 25, 30, 25, 25] # 可以根据实际列数和需要调整这些值excel_to_pdf(excel_file, column_widths=column_widths)
七、总结
通过本文介绍的excel_to_pdf_new.py脚本,您可以轻松解决工作中Excel转PDF的各种需求和问题。这个脚本不仅功能实用,还通过巧妙的技术实现解决了中文显示、日期格式、表格边框等常见痛点。
无论是财务人员、行政人员还是项目管理者,这个小工具都能帮助您提高办公效率,让文档处理更加得心应手。如果您在使用过程中遇到任何问题或有改进建议,欢迎在评论区留言讨论!
小贴士:如果您需要批量处理多个Excel文件,可以进一步扩展脚本功能,添加文件夹遍历和批量转换功能,让工作效率更进一步!