网页制作与网站建设 自考网站页面模板页面布局
目录
编辑
前言
1.需求分析
2.项目分析
3.Java中进行多进程编程
1.进程创建
2.进程等待
4.CommandUtil类的编写
5.Task类的编写
1.Answer类
2.Task类的设计
6.实现题目管理模块
编辑
7.设计服务器提供的API
1.向服务器请求 -- 题目列表
2.向服务器请求 -- 获取指定题目的详细信息
3.向服务器发送用户当前编写的代码,并获取到结果
8.实现服务器提供的API
1.实现ProblemServlet类
2.实现CompileServlet类
总结

前言
本章所使用的技术到maven,没有使用到javaSpringBoot的地方,也可以在学习完成之后使用SpringBoot的方式进行实现.代码这块只会简介后端的代码,前端的代码博主不是很熟练可能会在前后端交互的代码中简单的讲解一下,前端的代码可以去gitee中进行查看(java_oj: 使用maven实现的一个在线OJ的答题系统),本篇文章所有代码都上传到了这个仓库中.
1.需求分析
1,能够管理题目(保存很多的题目信息:题干 + 测试用例)
这块我的数据库是使用mysql没有使用到一些工具,里面的数据不是很好查看,就展示一下数据库中表.
2.题目列表页: 能够展示题目列表
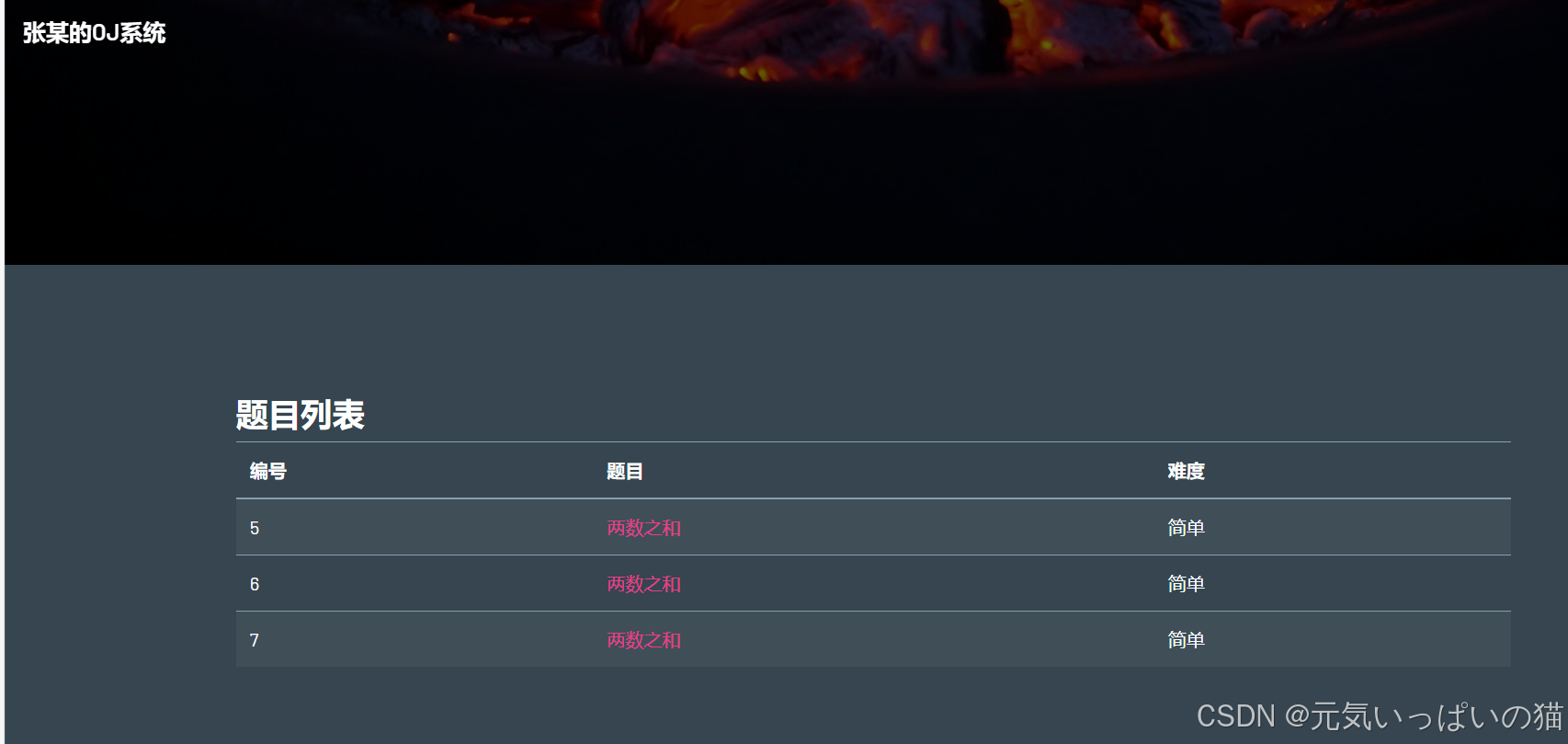
此处的题目列表页由于是小的系统没有设置很多题目就没有使用分页查询的功能,这个可以优化一下(前端加一个页码选择,后端配合创建一个表示当前为第几页然后进行分页查询的功能),
3.题目详情页:能够展示所选题目的具体信息 + 代码编辑框.
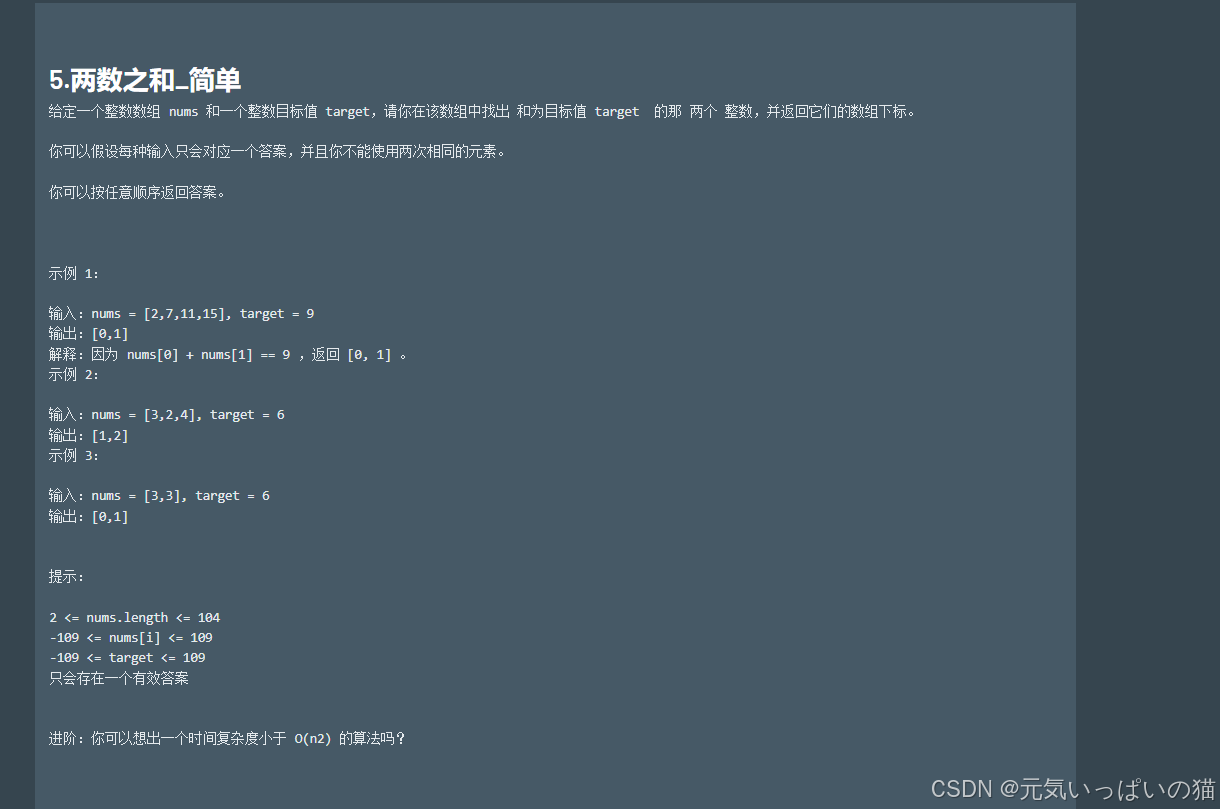
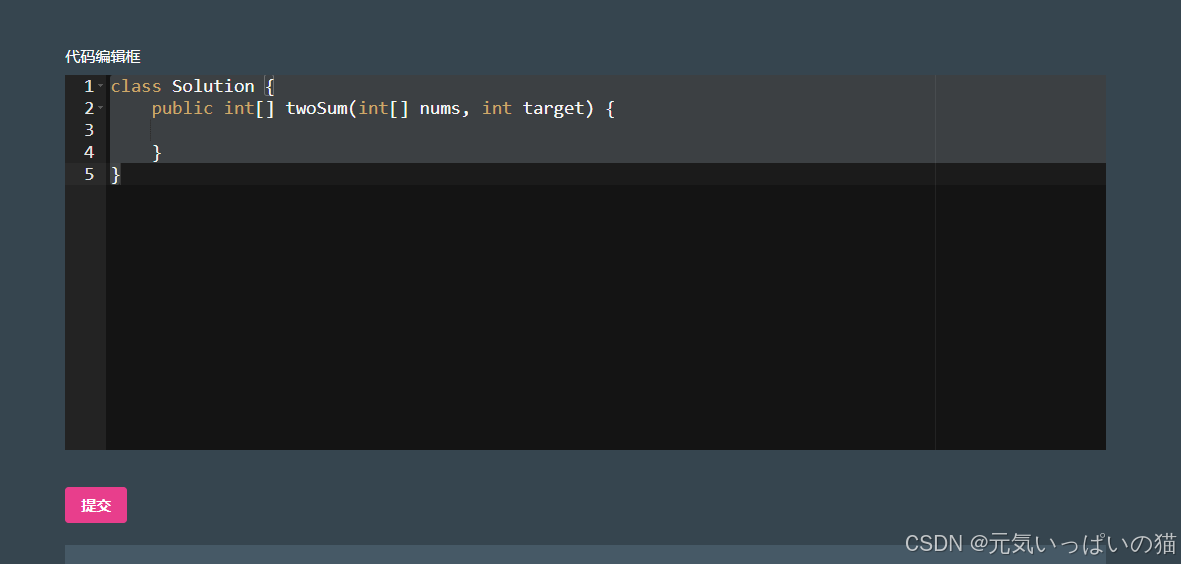
4.提交并运行题目:详情页中有一个"提交"按钮,点击按钮之后会把用户在代码编辑框的代码提交到服务器上进行运行,并且会给出运行的结果.
5.查看运行结果:在提交代码之后,会有专门的地方展示上次提交是否有通过或者没通过的原因.
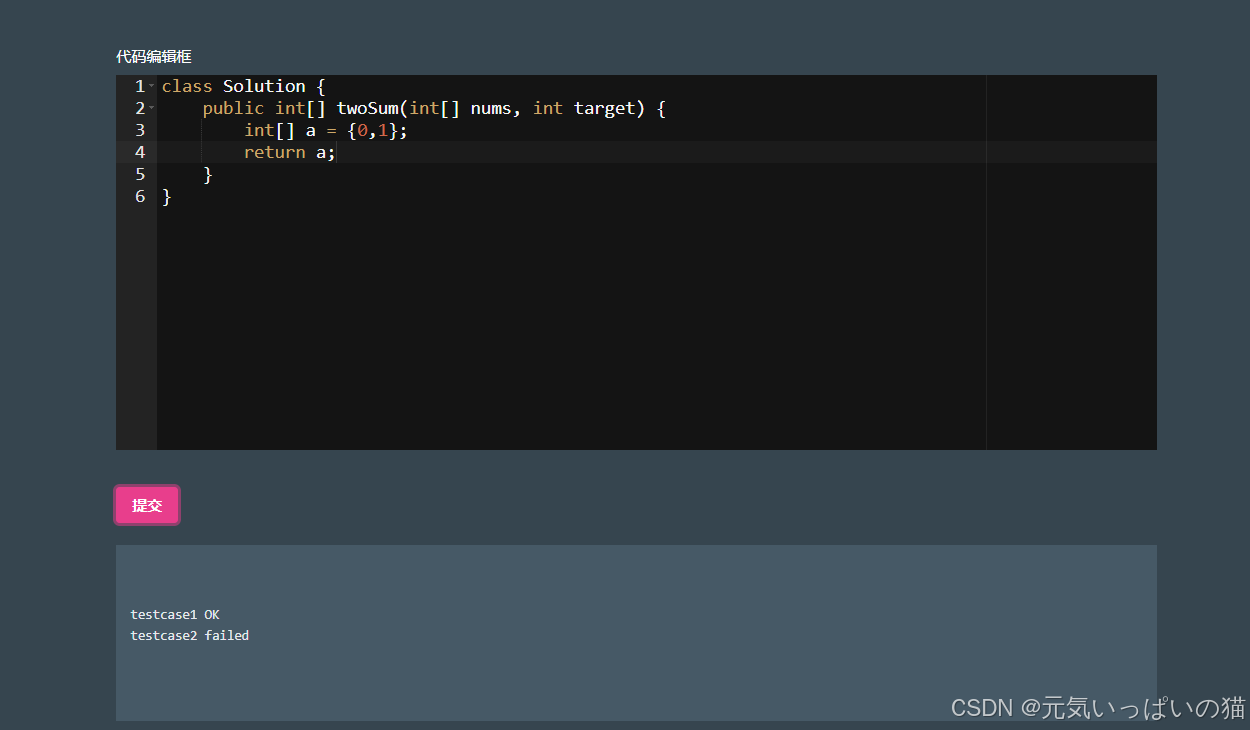
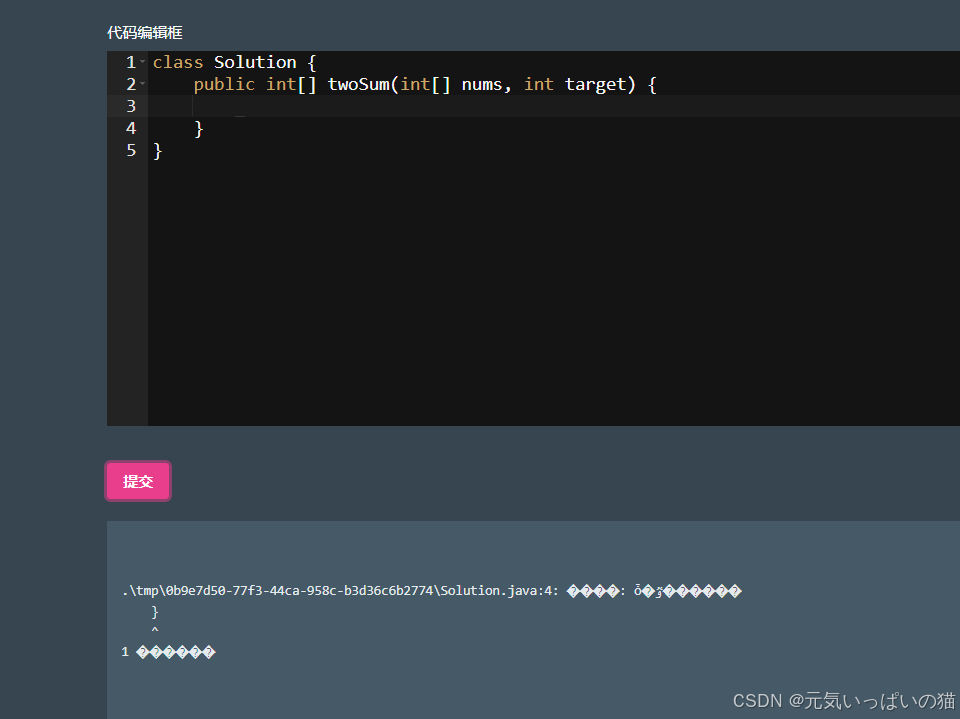
这里由于浏览器的字符集为GBK,当项目部署到Linux系统上的时候就会正常显示,错误信息我本地也会进行存储可以正常查看的
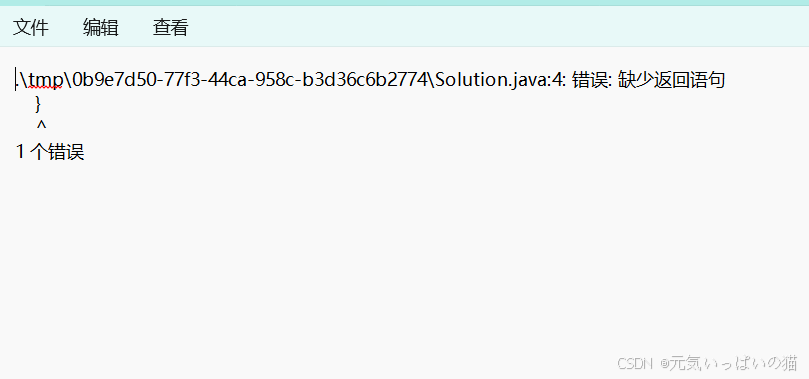
这个OJ项目的具体需要我们实现的功能就在上面展示完成了,下面就来看看这个需要什么前置芝士(知识,博主粉丁真的).
2.项目分析
这个项目需要使用到的技术点不多,一为文件的写入和读出,第二个为并发编程,IO操作就没啥必要进行简介了,就是InputStream和OutputStream这两个的方法使用问题.
重要的是并发编程,我们这个项目是个在线的答题平台(可以参考一下力扣),肯定不是只有一个人进行使用这个平台,此时我们就需要考虑并发编程的问题,说到并发编程我们在之前的学习中第一时间会想到的"多进程编程"和"多线程编程",多线程编程编程在创建一个线程和销毁一个线程的时候所需消耗的资源会比多进程编程进行该操作小很多,所以我们在很多项目要使用并发编程往往都是使用多线程编程进行实现的.
但是在这个项目中我们需要考虑一个问题,如果是使用多线程编程实现并发编程的话,我们想象一个场景,滑稽宿舍6个人要使用这个平台进行每一道题的答题比赛,
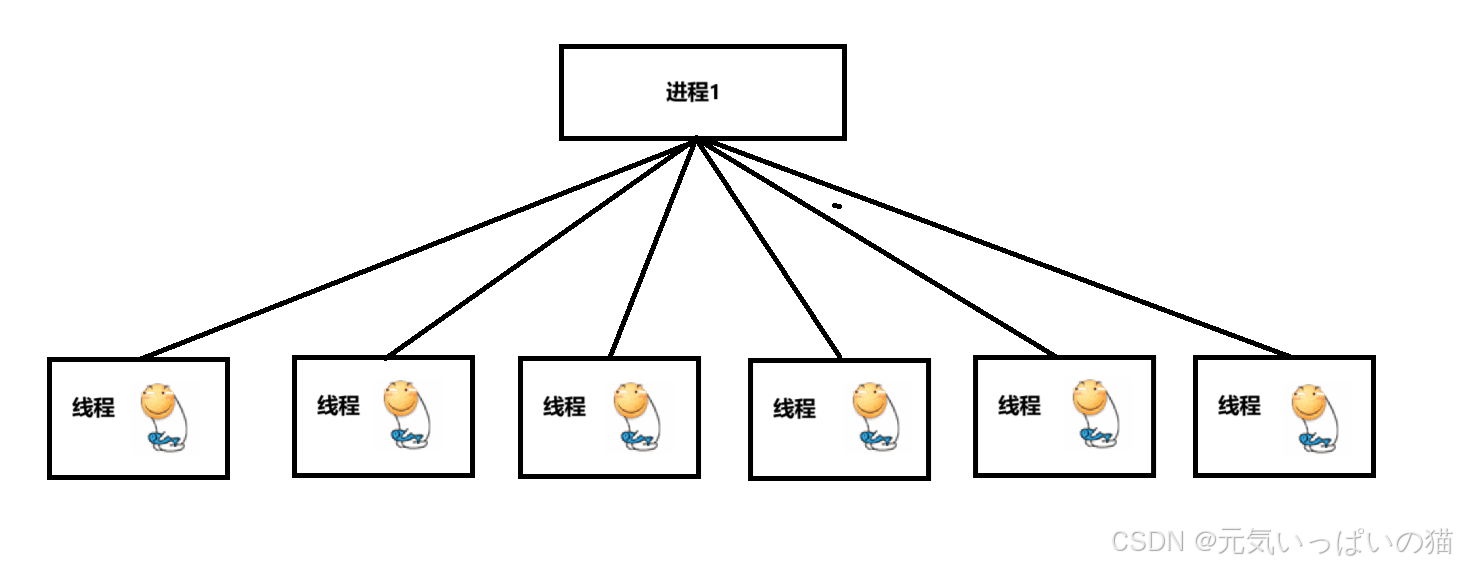
这块就在假设滑稽宿舍的编程水平时候很均匀(有的滑稽老铁写的很猛,有的滑稽老铁写bug很猛),如果在答题的过程中很有实力的滑稽老铁写的好好的,突然发现平台自己的答题页面崩了,请找出原因,这里的原因是那个写bug很猛的滑稽老铁不出所料的又写出了一个bug提交运行的时候崩了,把这个进程给崩没了.
这里就是多线程编程一个很明显的问题 --- 独立性很低,我们在力扣进行答题的时候没有遇到自己写着写着突然崩的情况和自己程序出bug了把别人给崩了情况(这种真要顺着网线来打你了),这个时候就需要请出多进程编程了,多进程编程相比于多线程编程的优点就是"独立性",在一个操作系统上可以同时存在多个进程,如果某个进程"挂"了也不会影响到其他正在运行着的进程(每个进程有各自的地址空间)
所以我们此处总结一下:
有一个服务器进程(运行着Servlet,接收用户请求,返回响应);用户提交代码,其实也是一个独立的逻辑,这个逻辑是使用多线程执行好,还是多进程呢?对于这里用户提交的代码,一定是要通过"多进程"的方式来执行的;因为无法笃定用户是提交了什么样的代码,提交上来的代码可能存在着问题,很有可能一运行就会崩溃,如果是多线程的话,自己崩了还是小事,把别人的崩了就是大事了
3.Java中进行多进程编程
多进程编程主要需要做的事情:站在操作系统的角度(以Linux为例),提供了很多和多进程编程相关的接口,如:进程创建,进程终止,进程等待,进程程序替换,进程间通信....,但是在在Java中对系统提供的这些操作进行了限制,最终给用户只提供了两个操作
1.进程创建
创建出一个新的进程,让这个新的进程来执行一系列任务,被创建出来的进程被称为"子进程",创建出子进程的进程被称为"父进程".
一个父进程可以有多个子进程,但是一个子进程,只能有一个父进程 Runtime.exec方法(Runtime -- Java中内置的一个类 参数是一个字符串,表示一个可执行程序的路径,执行exec方法就会把指定路径的可执行程序,创建出进行并执行)
Process process = runtime.exec("javac");exec里面的代码"javac"可以在自己的cmd上跑一下会有执行结果的(java相关的配置文件配置完成为前提)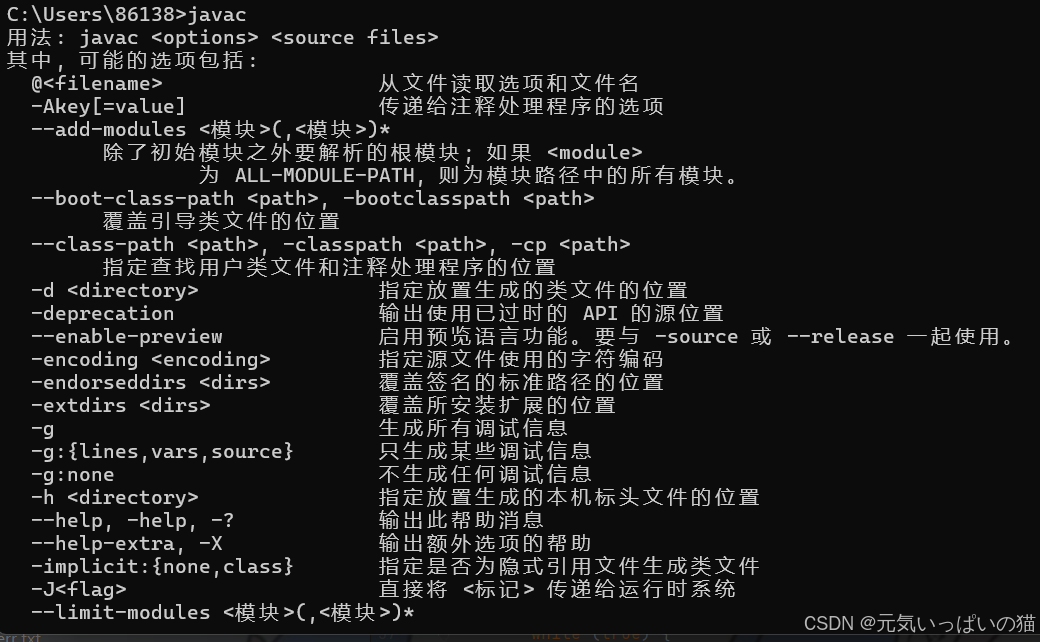
Process process = runtime.exec("javac");在编译器中执行这个代码,就相当于在cmd中输入了一个对应的指令
javac是一个控制台程序,它的输出,是输出到一个"标准输出"和"标准错误"这两个特殊的文件中
想要看到这个程序运行的效果,就得获取到标准输出和标准错误的内容!!
虽然子进程启动后同样也会打开这三个文件,但是由于子进程没有和idea的终端关联,因此在idea中是看不到子进程的输出的,要想获取输出,就需要在代码中手动获取到(IO操作进行读取)

2.进程等待

通过这个代码确实能创建出子进程,但是父子进程之间,是"并发执行"的关系
另一方面,往往也需要让父进程知道子进程的执行状态
在当前的场景中,希望是父进程等待子进程执行完毕之后,再执行后续代码(在线OJ系统,需要让用户提交代码,编译执行代码,肯定是要在编译执行完毕之后,再把响应返回给用户 )
public class TestExec {public static void main(String[] args) throws IOException, InterruptedException {//Runtime 在jvm中是一个单例Runtime runtime = Runtime.getRuntime();//Process 就表示 "进程"Process process = runtime.exec("javac");//获取子进程的标准输出和标准错误,并写入到两个文件中//获取标准输出,从这个文件对象中读,就能把子进程的标准输出给读取出来InputStream stdoutFrom = process.getInputStream();FileOutputStream stdoutTo = new FileOutputStream("stdout.txt");while(true) {int ch = stdoutFrom.read();if(ch == -1 ) {break;}stdoutTo.write(ch);}stdoutFrom.close();stdoutTo.close();//获取标准错误InputStream stderrForm = process.getErrorStream();FileOutputStream stderrTo = new FileOutputStream("stderr.txt");while (true) {int ch = stderrForm.read();if(ch == -1) {break;}stderrTo.write(ch);}stderrForm.close();stderrTo.close();//通过Process类的waitFor方法来实现进程的等待//父进程执行到waitFor的时候,就会阻塞,一直阻塞到子进程执行完毕为止//(和 Thread.join 是非常类似的)//这个退出码 就表示子进程的执行结果是否ok,如果子进程是代码执行完正常退出,此时返回的退出码就是0// 如果子进程执行了一半异常退出,此时返回的退出码是非0int exitCode = process.waitFor();System.out.println(exitCode);//这里是裸一个javac异常退出是正常的}
}这上面的代码就是多进程编程的试验代码,这段代码会执行"javac"的指令,并读取出标准输出和标准错误文件,在本地创建两个txt文件夹并将读取输出和标准错误的内容给写入到这两个文件中.
这块要注意的一点就是一开始点开的时候由于字节码可能不同,idea会提示点一下转化就可以正常显示出信息了.
4.CommandUtil类的编写
我们在第三部分简介了Java中该如何进行多进程编写,下面我们就需要给我们后面的操作创建一个关于创建子进程的工具类,我们就命名为CommandUtil.
在这个类中我们就创建一个方法run(我们就给他设置成静态的方法,后面不需要实例化这个类就直接使用),在run方法中我们要实现的功能为,1.通过Runtime类得到Runtime的实力,执行exec方法;2.获取到标准输出,并写入到指定文件中;3.获取到标准错误,并写入到指定文件中;4.等待子进程结束,获取到进程的状态码,并放回.由上述可知我们这个run方法需要使用到的参数为,用于exec执行的指令String cmd,用于存放标准输出的文件String stdoutFile和用于存储标准错误的文件String stderrFile,代码的实现过程和第三部分使用的代码没啥区别的,这块就直接把CommandUtil给放出来了.
//创建子进程
public class CommandUtil {// 1. 通过Runtime类得到 Runtime 实例,执行exec方法// 2. 获取标准输出,并写入到指定文件中// 3, 获取标准错误,并写入到指定文件中// 4. 等待子进程结束,获取到进程的状态码,并返回public static int run(String cmd,String stdoutFile,String stderrFile) {try{// 1. 通过Runtime类得到 Runtime 实例,执行exec方法Process process = Runtime.getRuntime().exec(cmd);// 2. 获取标准输出,并写入到指定文件中if(stdoutFile != null) {InputStream stdoutFrom = process.getInputStream();FileOutputStream stdoutTo = new FileOutputStream(stdoutFile);while (true) {int ch = stdoutFrom.read();if(ch == -1) {break;}stdoutTo.write(ch);}stdoutTo.close();stdoutFrom.close();}// 3, 获取标准错误,并写入到指定文件中if(stderrFile != null) {InputStream stderrFrom = process.getErrorStream();OutputStream stderrTo = new FileOutputStream(stderrFile);while (true) {int ch = stderrFrom.read();if(ch == -1) {break;}stderrTo.write(ch);}stderrTo.close();stderrFrom.close();}// 4. 等待子进程结束,获取到进程的状态码,并返回int exitCode = process.waitFor();return exitCode;} catch (IOException | InterruptedException e) {e.printStackTrace();}return 1;//程序出错}public static void main(String[] args) {CommandUtil.run("javac","stdout.txt","stderr.txt");}
}这块给了一个main方法用来测试CommandUtil是否可以正常运行的,大伙在实现完成之后也可以自己把程序跑跑测试一下有没有bug(每写完一个部分的代码最好都要测试一下).
在实现完CommandUtil类后,我们就要基于准备好的CommandUtil,实现一个完整的"编译运行"的功能模块 --- Task
5.Task类的编写
Task类需要做的工作:
1.输入:用户提交的代码
2.输出:程序的编译结果和运行结果
1.Answer类
在编写Task类之前我们先封装一个类用来存放Task在执行完用户提交的代码的结果,这个类我们就命名为Answer,这个类中我们需要的属性有:
1.错误码:error,我们在这里约定error为0表示编译运行都可以;error为1表示编译出错;error为2表示运行出错(抛异常)
2.和错误码配套的reason(错误信息),如果error为1(编译出错),reason就存放编译的错误信息;如果error为2(运行出错)
3.运行程序得到的标准输出:stdout
4.运行程序得到的标准错误:stderr.
// 表示一个 compile.Task 的执行结果
public class Answer {// 错误码// 约定:error为0表示编译运行都可以,error为1表示编译出错,error为2表示运行出错(抛异常)private int error;// 出错的信息// 如果error为1,编译出错了,reason存放编译的错误信息// 如果error为2,运行异常了,reason存放异常信息private String reason;//运行程序得到的标准输出的结果private String stdout;//运行程序得到的标准错误结果private String stderr;public int getError() {return error;}public void setError(int error) {this.error = error;}public String getReason() {return reason;}public void setReason(String reason) {this.reason = reason;}public String getStdout() {return stdout;}public void setStdout(String stdout) {this.stdout = stdout;}public String getStderr() {return stderr;}public void setStderr(String stderr) {this.stderr = stderr;}@Overridepublic String toString() {return "Answer{" +"error=" + error +", reason='" + reason + '\'' +", stdout='" + stdout + '\'' +", stderr='" + stderr + '\'' +'}';}
}Answer的代码就放这块了
2.Task类的设计
这块我们先研究研究Task需要啥,由于我们执行完程序之后会有两个文件(标准输出和标准错误文件),那我们这块需要给到两个文件创建一个目录,所以此处第一个需要的属性就是临时文件所在的目录,第二和第三个就是标准输入和标准错误的文件名称;在java中,类名要和文件名要保持一个,所以我们要给一个CODE属性来存放代码文件名;代码文件名有了代码的类名我们这块页需要给一个属性来存放一下,在这块就约定CLASS为代码的类名;我们在Answer中给了一个属性为error.当error为1时是表示编译错误的情况,意思就是说我们还需要存储程序在编译错误是的报错信息,我们这块就使用COMPILE_ERROR来存储编译错误信息的文件名
在确定好了需要使用到的属性后,我们就要针对它们进行一下初始化了WORK_DIR我们放到最后面在讲解.
我们先搞搞简单的,先从代码的类名和代码文件名,我们在写力扣的时候是不是有时候感觉有点怪怪的,就是他给的代码模板类名的类名好像每道题都长得差不多,这个不是错觉,力扣的题里面给的代码模板的题都是一样的都是Solution(这块你可以打开LeetCode看看),所以我们在这块的类名就固定为Solution,代码文件名也就固定为"Solution.java" (这个约定在后续数据库编写数据的时候要注意).
标准输出,标准错误和编译时错误的信息的文件名称,我们在这块统一约定都为.

最后就是我们临时文件的名称WORK_DIR,这块放到最后的原因就是我们是一个多进程编程的程序,我们在多线程编程的时候讨论到最多的就是"线程安全"的问题了,在多进程编程中也是会存在这个问题的,我们在信息文件的命名中已经是一样的了,如果我们在存放临时文件的目录还是一样的话,这个时候肯定会存在进程安全问题,这里我们假设一个情况,一号滑稽老铁和二号滑稽老铁都提交了自己的代码,二号滑稽老铁贴了一个python的代码,一号滑稽老铁贴了一个可以正确运行出结果的代码,如果我们存放临时文件的目录名称是一样的话,我们从多个执行顺序的结果中找出这种,二号老铁先执行了代码,代码执行的结果存放到了文件中,紧接着就是一号老铁执行完了代码也存储到了文件中,但是把二号老铁的执行结果给覆盖了结果二号老铁和一号老铁都拿到了一号老铁的正确执行的结果,二号老铁表示(我嘞个豆,我在Java环境下跑python代码都能过,下次还来这个平台写题).
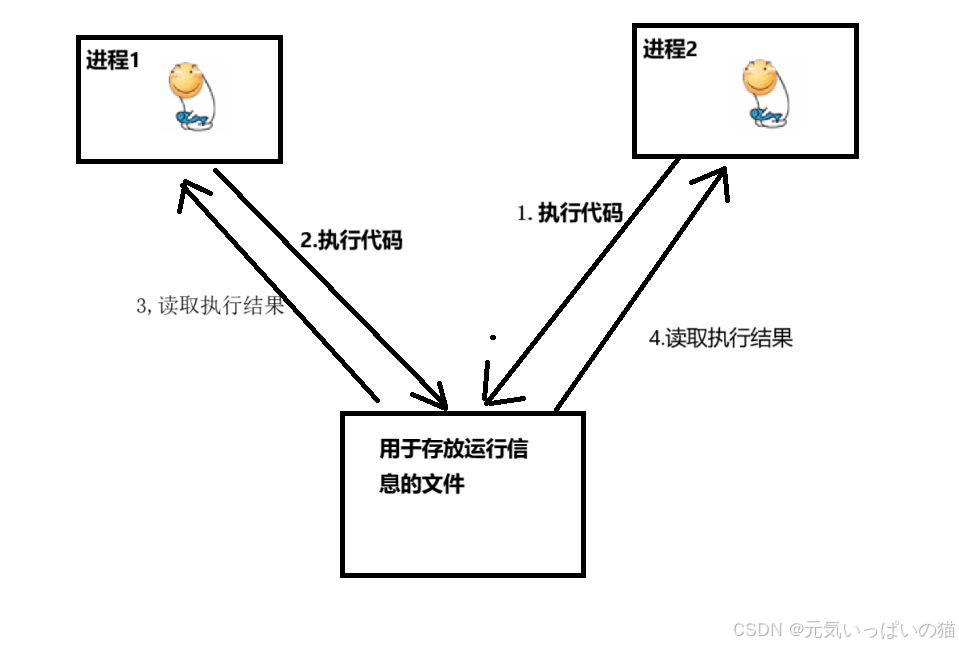
这上面的例子就出来进程安全问题,我们在这块给出的解决方法就是存放临时文件的目录名称都不一样,那我们就需要一个猛男了

这块我们使用UUID来生成一个随机的字符串来充当我们临时文件的名称,
我们Task中初始化的代码如下:
public Task() {//使用UUID来创建不同的临时文件WORK_DIR = "./tmp/" + UUID.randomUUID().toString() + "/";CLASS = "Solution";CODE = WORK_DIR + "Solution.java";COMPILE_ERROR = WORK_DIR + "compileError.txt";STDOUT = WORK_DIR + "stout.txt";STDERR = WORK_DIR + "stderr.txt";}在实现完成Task类的属性定义和初始化后,我们就要来实现Task中的核心方法---编译运行,这里我们命名为compileAndRun,compileAndRun中需要的参数就是前端用户编写的代码,我们此处可以封装一个类用来表示compileAndRun中需要的参数.
//这个类表示一个 task 的输入内容
//这个类会包含要编译的代码
public class Question {private String code;public String getCode() {return code;}public void setCode(String code) {this.code = code;}
}
在compileAndRun中我们第一步需要操作的是先准备好用来存放的临时我呢见的tmp目录,这里我们先前是为了解决"进程安全"问题,是使用每个进程之间的tmp目录是都不一样的,所以在进行编译运行操作之前,先因该创建好我们的tmp目录。在创建完成tmp目录之后,需要做的是将我们Question中的code(用户提交的代码)写入到我们约定的"Solution.java"文件中,我们约定的是CODE用来存放要编译的代码文件名。下一步就是需要创建我们的子进程,此处就需要调用javac进行编译(注:编译的时候需要一个.java的文件,当前是通过String的方式提供代码的),如果编译出错的话,javac就会把错误信息给写入到stderr中,使用专门的文件来保存编译出错的信息(compileError.txt)。所以我们先得把编译命令的构造出来。
String compileCmd = String.format("javac -encoding utf8 %s -d %s",CODE,WORK_DIR);上面这段代码就是对用户提交的代码进行编译操作,第一个%s是放代码的所在位置,第二个%s为生成文件的位置(也是在上面就约定好的),javac的命令构造好之后就可以调用CommandUtil中的run方法来执行我们的指令了,在执行的时候我们需要观察run的文件操作,我们在上面实现CommandUtil.run()的时候是有对错误进行区分的,如果是编译出错会写入到一个错误文档中,在compileAndRun执行完run方法之后我们应该去检查这个文档中是否有存放信息(如果有就证明代码出现了编译错误),如果没有则可以进行下一步的操作。创建子进程,调用java命令并执行,在运行程序的时候,也会把java子进程的标准输出和标准错误给获取到 stdout.txt和stderr.txt中,在程序运行完java命令之后要是要对标准标准错误中的文件进行查看的(如果标准错误中有数据存放,就代表程序在运行的过程中出现了错误 --- 运行时错误)。最后如果没有问题的话就由父进程来获取编译执行的结果(在我们约定的文档中进行获取),并打包成Answer对象。
下面这块就放上面所描述的代码实现
//这个Task的核心方法就是compileAndRun(编译 和 运行)// 参数: 要编译运行的Java源代码// 返回值: 表示编译运行的结果. 编译出错/运行出错/运行正确...public Answer compileAndRun(Question question) {Answer answer = new Answer();//0.先准备好用来存放临时文件的tmp目录File workDir = new File(WORK_DIR);if(!workDir.exists()) {workDir.mkdirs();//创建多级目录}//进行安全性判定if(!checkCodeSafe(question.getCode())) {System.out.println("[Task] 用户提交了不安全的代码");answer.setError(3);answer.setReason("您提交的代码可能危害到服务器,禁止执行");return answer;}//1.先得将question.code写入到一个Solution.java的文件中FileUtil.writerFile(CODE,question.getCode());//2.创建子进程,调用javac进行编译(注:编译的时候,需要一个.java的文件,当前是通过String的方式提供的代码)// 如果编译出错,javac就会把错误信息写入到stderr里,使用专门的文件来保存编译错误 --- compileError.txt// 需要把编译命令给构造出来//第一个%s是放源代码所在的位置,第二个为生成文件的位置String compileCmd = String.format("javac -encoding utf8 %s -d %s",CODE,WORK_DIR);System.out.println("编译命令: " + compileCmd);CommandUtil.run(compileCmd,null,COMPILE_ERROR);//如果编译出错,错误信息就会被COMPILE_ERROR这个文件中String compileError = FileUtil.readFile(COMPILE_ERROR);if(!compileError.equals("")) {//编译出错 -- 直接返回AnswerSystem.out.println("[compile.Task] 编译出错!");answer.setError(1);answer.setReason(compileError);return answer;}//3.创建子进程,调用java命令并执行// 运行程序的时候,也会把java子进程的标准输出和标准错误给获取到,stdout.txt / stderr.txtString rumCmd = String.format("java -classpath %s %s",WORK_DIR,CLASS);System.out.println("运行命令: " + rumCmd);CommandUtil.run(rumCmd,STDOUT,STDERR);String runError = FileUtil.readFile(STDERR);if(!runError.equals("")) {//运行时错误System.out.println("[compile.Task] 运行出错!");answer.setError(2);answer.setStderr(runError);return answer;}//4.父进程来获取编译执行的结果,并打包成Answer对象answer.setError(0);answer.setStdout(FileUtil.readFile(STDOUT));return answer;}这块要注意的是,我们约定compileAndRun的返回值是Answer对象,我们在编译执行用户提交上来的代码的过程,肯定会遇到编译错误和运行错误两种情况的,我们在先前约定了Answer中要设置好对应的error值即可.
上面的代码也是可以自己去写一个main方法试一下有没有错误的(这块就提供一个).
public static void main(String[] args) {Task task = new Task();Question question = new Question();question.setCode("public class Solution {\n" +" public static void main(String[] args) {\n" +" System.out.println(\"hello word\");\n" +" }\n" +"}");Answer answer = task.compileAndRun(question);System.out.println(answer.toString());}运行完之后的结果是这样的

这块在idea中出现乱码的原因是因为windows11简体中文版默认的字符编码是GBK,包括javac命令输出的错误信息,默认也是和系统编码一致,也就是GBK,但是IDEA的终端默认编码是UTF-8,出现乱码的原因就是编码方式不统一!! 这块不用解决(不好解决),可以等后续部署云服务器中(Linux系统)就没啥问题了.
6.实现题目管理模块
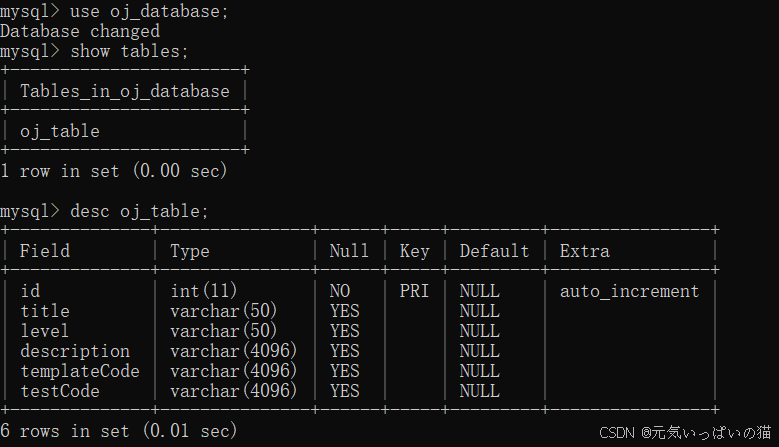
我们在上面说了一大堆编译运行代码的方法都是去执行用户提交的代码的,但是我们还没有对用户提交的题目进行管理,这个部分我们将实现题目的管理和持久化存储(存数据库),我们这块先设计一个数据表.

对应的sql代码
create database if no exists oj_database;use oj_database;drop table if exists oj_table;
create table oj_table(
id int primary key auto_increment,
title varchar(50),
level varchar(50),
description varchar(4096),
templateCode varchar(4096),
testCode varchar(4096)
);
我们在项目中也是要创建出对应的实体类,我们这块就命名为Problem,一个Problem对象就对应着表中的一条记录,我们还需要针对这张表实现"增删改查"操作,我们就命ProblemDao来负责增删改查的操作.
Problem类的代码
//题目
public class Problem {private int id; //题目idprivate String title; //标题private String level; //难度private String description; //题目描述private String templateCode; //模板代码private String testCode; //测试用例public int getId() {return id;}public void setId(int id) {this.id = id;}public String getTitle() {return title;}public void setTitle(String title) {this.title = title;}public String getLevel() {return level;}public void setLevel(String level) {this.level = level;}public String getDescription() {return description;}public void setDescription(String description) {this.description = description;}public String getTemplateCode() {return templateCode;}public void setTemplateCode(String templateCode) {this.templateCode = templateCode;}public String getTestCode() {return testCode;}public void setTestCode(String testCode) {this.testCode = testCode;}@Overridepublic String toString() {return "Problem{" +"id=" + id +", title='" + title + '\'' +", level='" + level + '\'' +", description='" + description + '\'' +", templateCode='" + templateCode + '\'' +", testCode='" + testCode + '\'' +'}';}
}在设计数据库查找的时候我们就别select * from这样全查找了,这种方式太粗暴了,数据库往往是比较娇贵的存在,在查找的时候我们需要"温柔点",比如说在题目列表需要查询数据的时候我们只需要知道题目的序号,题目名称,题目难度,这些字段,所以在查询的时候我们就只查询这些字段即可,行数是固定的,但是一次查询两列比一次查询一列,开销就是要大很多.
ProblemDao的代码我就在这块直接给出来了.
//针对Problem的增删改查
public class ProblemDao {private Connection connection = null;private PreparedStatement statement = null;private ResultSet resultSet = null;//1.新增题目public void insert(Problem problem) {try {//1.和数据库建立连接connection = DBUtil.getConnection();//2.构造sql语句String sql = "insert into oj_table values(null,?,?,?,?,?)";statement = connection.prepareStatement(sql);statement.setString(1, problem.getTitle());statement.setString(2,problem.getLevel());statement.setString(3,problem.getDescription());statement.setString(4,problem.getTemplateCode());statement.setString(5,problem.getTestCode());//3.执行sqlint ret = statement.executeUpdate();if(ret != 1) {System.out.println("[ProblemDao] 新增题目失败!!");} else {System.out.println("[ProblemDao] 新增题目成功!!");}} catch (SQLException e) {e.printStackTrace();} finally {DBUtil.close(connection,statement,null);}}//2.删除题目public void delete(int id) {try {//1.和数据库建立连接connection = DBUtil.getConnection();//2.拼装sql语句String sql = "delete from oj_table where id = ?";statement = connection.prepareStatement(sql);statement.setInt(1,id);//3.执行sqlint ret = statement.executeUpdate();if(ret != 1) {System.out.println("[ProblemDao] 删除题目失败!!");} else {System.out.println("[ProblemDao] 删除题目成功!!");}} catch (SQLException e) {e.printStackTrace();} finally {DBUtil.close(connection,statement,null);}}//3.查询题目列表 -- 把数据库所有的题目都给返回了//看需求,如果题库中的数据非常多的话就前后端都实现分页查询即可public List<Problem> selectAll() {List<Problem> problems = new ArrayList<>();try{//1.和数据库建立连接connection = DBUtil.getConnection();//2.拼装sql -- 没必要把所有的列都找出来,找题目序号,题目名称,难度就差不多了String sql = "select id,title,level from oj_table";statement = connection.prepareStatement(sql);//3.执行sqlresultSet = statement.executeQuery();//4.遍历resultSetwhile(resultSet.next()) {Problem problem = new Problem();problem.setId(resultSet.getInt("id"));problem.setTitle(resultSet.getString("title"));problem.setLevel(resultSet.getString("level"));problems.add(problem);}} catch (SQLException e) {e.printStackTrace();} finally {DBUtil.close(connection,statement,resultSet);}return problems;}//4.查询题目详情public Problem selectOne(int id) {Problem problem = null;try {//1,和数据库建立连接connection = DBUtil.getConnection();//2.拼接sql语句String sql = "Select * from oj_table where id = ?";statement = connection.prepareStatement(sql);statement.setInt(1,id);//3.执行sql语句resultSet = statement.executeQuery();//遍历查询结果 (就一个)if(resultSet.next()) {problem = new Problem();problem.setId(resultSet.getInt("id"));problem.setTitle(resultSet.getString("title"));problem.setLevel(resultSet.getString("level"));problem.setDescription(resultSet.getString("description"));problem.setTemplateCode(resultSet.getString("templateCode"));problem.setTestCode(resultSet.getString("testCode"));}} catch (SQLException e) {e.printStackTrace();} finally {DBUtil.close(connection,statement,resultSet);}return problem;}}这块设计完Problem之后可以通过main方法进行一下测试,也顺便给数据库中上点数据,这块给模板代码可以自己先在idea中敲一段代码之后放到对应的属性中,在存入数据库会方便很多,我这块就放一下我的代码截图,就不贴代码了
这块设计测试代码,就可以把要测试的数据放到main方法中,后续直接拼接上去即可(后面会有代码拼接的实现)
7.设计服务器提供的API
1.需要哪些网页(有哪几个网页,都是干什么的)
a)题目列表页(功能就是展示当前题目的列表) ==> 向服务器请求题目的列表
b)题目详情页:
功能一:展示题目的详细要求 --> 向服务器请求,获取指定题目的详细信息
功能二:能够有一个代码编辑框,让用户来写代码(这个过程无需和服务器进行交互,纯前端)
功能三:有一个提交按钮,点击提交按钮,能够把用户编辑的代码给发到服务器上,服务器进行编译和运行,并返回结果 --->向服务器发送用户当前编写的代码,并且获取到结果
还可以提供一个题目管理(只提供给管理员进行使用,不开放给正常用户,管理员通过这个页面来新增页面/删除题目)
具体设计这几个前后端交互的api
现在比较流行的前后端交互的方式,主要是通过JSON格式来组织的(要引入第三方库 --- jackson)
1.向服务器请求 -- 题目列表
约定:
请求:GET/problem(网页构造的请求就得按照这个格式来进行构造了)

网页也需要按这个格式来解析(JSON)
2.向服务器请求 -- 获取指定题目的详细信息
约定:
请求: GET/problem?id = 1(我们这块获取指定题目的详细信息的URL和获取题目列表的是一样的,但是获取指定题目信息是有参数进行区分的)

在返回题目详细信息的时候,我们题目的模板是提供给用户的,但是测试用例是不放出来的,力扣也是不会放出来的,只是在题目详情的时候给了两三个例子给我们进行分析.
3.向服务器发送用户当前编写的代码,并获取到结果
约定:
请求:POST/compile (这次给服务器发送的数据内容比较大,直接放到url中进行传输不大好,这块就通过post方法将数据放到body中)

8.实现服务器提供的API
1.实现ProblemServlet类
我们在上面是约定了获取题目列表页和题目详情是采用相同的URL("/problem"),我们是通过前端在调用url是否有传递id参数来区分是获取题目列表还是题目详情的,这块前端在点击题目时是根据对应题目id来传递参数的实现可以去gitte上看一下前端代码,我们也是在ProblemDao实现了题目数据的增删改查功能,后续直接调用就可以了,这块由于没有什么难度就直接贴实现的代码了.
//这个路径即使获取列表也是获取详情的接口(根据参数进行区分)
@WebServlet("/problem")
public class ProblemServlet extends HttpServlet {private ProblemDao problemDao = new ProblemDao();private ObjectMapper objectMapper = new ObjectMapper();@Overrideprotected void doGet(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {//Json格式的数据的Content-Type:application/json;charset=utf8 (固定的)resp.setStatus(200);resp.setContentType("application/json;charset=utf8");// 尝试获取url中的id参数(如果获取的到就是获取题目详情,如果获取不到就是题目列表)String idString = req.getParameter("id");if(idString == null || "".equals(idString)) {//没有获取到id字段 --- 获取题目列表List<Problem> list = problemDao.selectAll();
// System.out.println("[ProblemServlet] 获取的题目列表数据为 : " + list.toString());//转换成json格式String respString = objectMapper.writeValueAsString(list);//设置http响应的body部分//http协议的报头要求通过Content-Length来描述body的长度(长度部分Servlet已经自动生成了)//通过Content-Type来表示body的类型resp.getWriter().write(respString);} else {//获取题目详情Problem problem = problemDao.selectOne(Integer.parseInt(idString));//转换成json结构String respString = objectMapper.writeValueAsString(problem);resp.getWriter().write(respString);}}
}2.实现CompileServlet类
CompileServlet这个类就是用来处理我们提交代码之后编译运行并返回执行结果的API,这个API的实现和上面获取题目列表和详情的不是一个难度的.由于我们在上面约定的是前端传输过来的数据是一个json格式的数据,所以在实现业务功能之前我们得先将json格式的数据给解析出来.
这块使用到的方法是向使用byte数组去把请求读取出来,先把请求转换成二进制格式的数据,然后再通过new String[buffer(byte数组)]的方式把二进制的数据构造成字符串形式,这样就可以把json格式的数据转换成字符串格式以便后面后续对数据进行操作,这里就可以在CompileService中封装一个方法进行实现.
这块就直接实现的代码贴出来了.
private static String readBody(HttpServletRequest req) throws UnsupportedEncodingException {// 1.先根据请求头里面的ContentLength获取body的长度(字节)int contentLength = req.getContentLength();// 2.按照这个长度准备好一个字节数组byte[] buffer = new byte[contentLength];// 3.通过req里面的getInputStream方法,获取到body的流对象try (InputStream inputStream = req.getInputStream()){// 4.基于流对象读取内容,然后把内容放到 byte[] 数组中即可inputStream.read(buffer);} catch (IOException e) {e.printStackTrace();}// 5.把byte[] 数组的内容构造成一个Stringreturn new String(buffer,"utf8");}这里将请求的数据转化成String的数据之后其实还没有结束,你也不想再一大串字符串中去找我们需要的数据把,所以这个时候就需要一个"猛男".
objectMapper.readValue(?,?);这个方法可以把我们json转换成字符串的数据给映射到对应的类中,我们json在转换成之后的样式也是长"{id:xxxxx,code:xxxxx}"的,这个方法可以把对应的key的中的value给取出来,此时我们需要一个内部类,这个内部类的元素名称和元素个数要和json请求中的key保持一致,如果将我们字符串化的请求放在readValue中的第一个参数的位置,在将我们用来接收的类.class放在第二个参数的位置,最后就可以得到我们想要的数据了,我们这块由于在响应的时候返回的也是一个json格式的数据,所以我们在CompilleServlet都给请求和响应封装对应的内部类以便我们后续的使用. 这块具体的是实现将会在代码中体现
//解析请求的内部类static class CompileRequest {public int id;public String code;}//解析响应的内部类static class CompileResponse {//约定 error为0表示编译运行正常,error为1编译出错,error为2表示运行出错(用户提交的代码有问题)//error为3表示其他错误public int error;public String reason;public String stdout;}在处理完将json格式的数据转换成我们想要的类型之后,就要编译运行我们用户编写的代码了,到这里又会出现一个问题,我们用户的代码是否通过的标准是用户提交的代码跑测试用例得到的结果是否为"OK",但是现在我们用户提交的代码是解析到了一个字符串中,我们测试用例的代码又在数据库中,如果取出来也是在不同的字符串中,代码都不在一块我们咋运行呢. 这块就需要使用到我们字符串拼接了,我们需要将用户提交的代码和测试用例进拼接.

我们在编写测试用例的代码的时候其实就是在一个main方法中通过不同的数据去调用我们编写的方法,所以我们可以将测试用例的代码接入到用户编写的代码中(用户编写的代码是有类名和测试用例调用的方法的),然后再通过调用Task类中的compileAndRun方法即可.
我们这块拼接的思路是找到用户编写的代码中最后一个 "}"的位置,将这个阔号删除再接上我们测试用例的代码,在将测试用例给接上之后再补回"}"即可,就得到了一个完整的类.
这块就把这个功能实现的代码给贴出来了(也是要封装一个方法的)
private static String mergeCode(String requestCode, String testCode) {// 1.查找requestCode中的最后一个}int pos = requestCode.lastIndexOf("}");if(pos == -1) {//说明提交代码完全没有},是非法代码return null;}//2.进行截取String subStr = requestCode.substring(0,pos);//3.拼接return subStr + testCode + "}";}还有最后一个问题,等我们运行程序之后,我们用户通过前端页面进行运行程序之后,生成对应的文件应该去哪里找呢,在我们测试的时候这个临时文件是直接生成在项目的目录下面的,那是因为我们在内部测试的时候用户当前的工作目录就是这个项目,但是在tomcat部署之后就不一定了,这个生成的临时文件会根据用户当前的工作目录变化而变化的,这个时候我们就需要打印一个日志去查看当前的工作目录在哪,以便我们后台人员(就是我们自己)去查看日志.
System.out.println("用户当前的工作目录: " + System.getProperty("user.dir"));这块就可以通过这个方法来查看当前项目的工作目录(也有其他方法在CSDN中搜索就可以找到)
基本的问题就已经解决了,就可以来实现我们CompileService中的业务逻辑了,下面就直接将完整的代码给贴出来了.
@WebServlet("/compile")
public class CompileServlet extends HttpServlet {private ObjectMapper objectMapper = new ObjectMapper();private ProblemDao problemDao = new ProblemDao();//解析请求的内部类static class CompileRequest {public int id;public String code;}//解析响应的内部类static class CompileResponse {//约定 error为0表示编译运行正常,error为1编译出错,error为2表示运行出错(用户提交的代码有问题)//error为3表示其他错误public int error;public String reason;public String stdout;}@Overrideprotected void doPost(HttpServletRequest req, HttpServletResponse resp) throws ServletException, IOException {System.out.println("用户当前的工作目录: " + System.getProperty("user.dir"));CompileResponse compileResponse = new CompileResponse();CompileRequest compileRequest = null;try {resp.setContentType("application/json;charset=utf8");// 1.读取正文,按照json格式进行解析String body = readBody(req);compileRequest = objectMapper.readValue(body, CompileRequest.class);// 2.根据id在数据库中查询到题目详情 => 得到测试用例代码Problem problem = problemDao.selectOne(compileRequest.id);if(problem == null) {//题目id不存在,抛出一个异常throw new ProblemNotFoundException();}//testCode 为测试用例的代码String testCode = problem.getTestCode();//requestCode 为用户提交的代码String requestCode = compileRequest.code;// 3.把用户提交的代码和测试用例代码,给拼接成一个完整的代码String finalCode = mergeCode(requestCode,testCode);if (finalCode == null) {throw new CodeInValidException();}System.out.println(3);System.out.println(finalCode);// 4.创建一个Task实例,调用类名的compileAndRun 来进行编译运行Task task = new Task();Question question = new Question();question.setCode(finalCode);Answer answer = task.compileAndRun(question);System.out.println("[CompileServlet] 编译执行的结果为 : " + answer.getStdout());// 5.根据Task运行的结果,包装成一个HTTP响应compileResponse.error = answer.getError();compileResponse.reason = answer.getReason();compileResponse.stdout = answer.getStdout();} catch (ProblemNotFoundException e) {// 处理题目没有找到的场景compileResponse.error = 3;compileResponse.reason = "没有找到指定的题目,id = " + compileRequest.id;} catch (CodeInValidException e) {compileResponse.error = 3;compileResponse.reason = "提交代码不符合要求";} finally {//转换成json字符串发回给浏览器String respString = objectMapper.writeValueAsString(compileResponse );resp.getWriter().write(respString);}}private static String readBody(HttpServletRequest req) throws UnsupportedEncodingException {// 1.先根据请求头里面的ContentLength获取body的长度(字节)int contentLength = req.getContentLength();// 2.按照这个长度准备好一个字节数组byte[] buffer = new byte[contentLength];// 3.通过req里面的getInputStream方法,获取到body的流对象try (InputStream inputStream = req.getInputStream()){// 4.基于流对象读取内容,然后把内容放到 byte[] 数组中即可inputStream.read(buffer);} catch (IOException e) {e.printStackTrace();}// 5.把byte[] 数组的内容构造成一个Stringreturn new String(buffer,"utf8");}private static String mergeCode(String requestCode, String testCode) {// 1.查找requestCode中的最后一个}int pos = requestCode.lastIndexOf("}");if(pos == -1) {//说明提交代码完全没有},是非法代码return null;}//2.进行截取String subStr = requestCode.substring(0,pos);//3.拼接return subStr + testCode + "}";}
}
在返回响应的时候我们要注意,在编译运行用户代码的时候是可能会出现编译时错误和运行时错误的,我们在执行完每一个步骤的时候都要注意去捕获这些错误,这块可以去自定义两个异常,在不同的情况下抛出,然后在响应中填入对应错误和类型(是有进行约定的),最后在通过String respString = objectMapper.writeValueAsString(compileResponse );的方式将我们的响应打包成json格式的数据给传回给前端进行处理.
总结
这个项目基本上在这块就完成了,由于博主的前端能力不是很强,就不在这块献丑了,这个项目难点主要就是集中在如何创建多线程编程和我们如果在通过idea去编译运行用户提交的代码,剩下的部分就没啥难度了,数据库的操作也就是基础的增删改查,需要扩展的部分就是我们要识别一下用户的代码,我们现在是直接执行用户提交上来了的代码的,但是我们不能保证用户提交上来的代码是安全的,比如说文件的操作和网络的操作,这些代码如果可以开放给用户进行使用的话,可能会有别有用心之人来破坏我们的网站甚至计算机,所以这块识别代码的功能可以去实现一下,博主也是进行了实现了但是是最简单的关键词识别的方式,如果需要参考的话可以去我的gitte中看一下(公开了java_oj: 使用maven实现的一个在线OJ的答题系统).可以去看看哈,最后欢迎大伙来评论区进行讨论.