ReSpec:突破RL训练瓶颈的推测解码优化系统
ReSpec:突破RL训练瓶颈的推测解码优化系统
随着大语言模型通过强化学习进行对齐训练的需求激增,生成阶段的计算瓶颈日益凸显。ReSpec系统首次系统性地解决了推测解码在RL训练中面临的三大关键挑战,通过自适应配置调整、动态drafter演化和奖励加权更新机制,在保持训练稳定性的同时实现了高达4.5倍的加速效果,为高效的RL-based LLM适应提供了实用解决方案。
论文标题:ReSpec: Towards Optimizing Speculative Decoding in Reinforcement Learning Systems
来源:http://arxiv.org/abs/2510.26475
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 AI极客熊 」 即刻免费解锁
文章核心
研究背景:
大语言模型通过强化学习进行对齐训练已成为处理复杂高级目标的实用路径,如改进对齐、推理能力和特定领域技能。RL训练迭代通常包含三个阶段:生成、推理和训练。其中生成阶段一直是主要的性能瓶颈,如表1所示,对于最大响应长度为8K tokens的LLMs,生成阶段在数学和代码模型中分别占用了高达86%和75%的wall-clock迭代时间。这一瓶颈在广泛使用的算法实践中进一步加剧,如PPO和基于组的方法(GRPO、DAPO)通过为每个提示生成多个候选完成来提高探索和梯度质量,但这也会增加每个提示的解码token数量,进一步放大了生成阶段的成本。
研究问题:
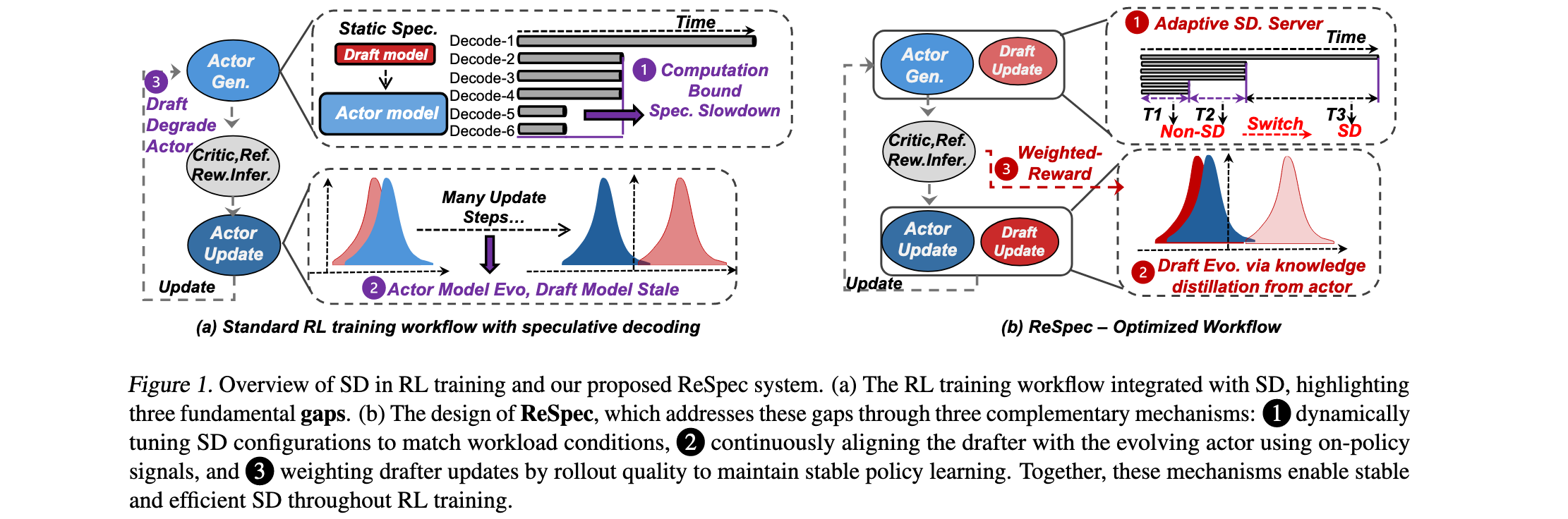
ReSpec系统识别了推测解码在RL训练中面临的三个关键缺陷(G1/G2/G3问题):
-
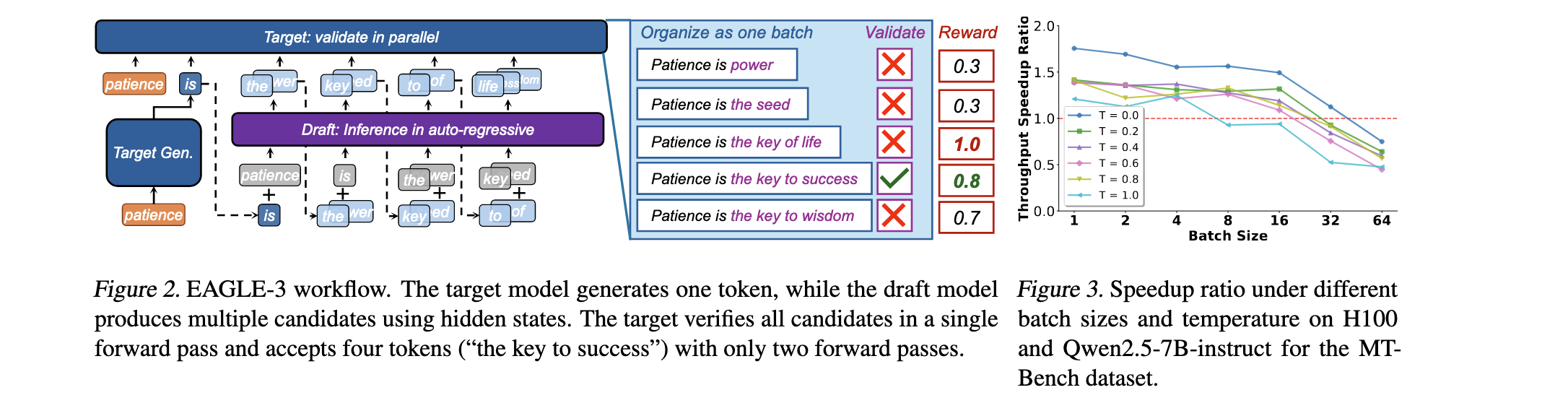
G1:大规模批处理下的加速递减:当生成已经以大批处理大小运行在高GPU利用率时,SD提供的边际并行性变得有限,甚至可能被起草和同步开销抵消。如图3所示,随着批处理大小增加,SD的加速效果显著下降,在某些配置下甚至变为减速(0.76×)。
-
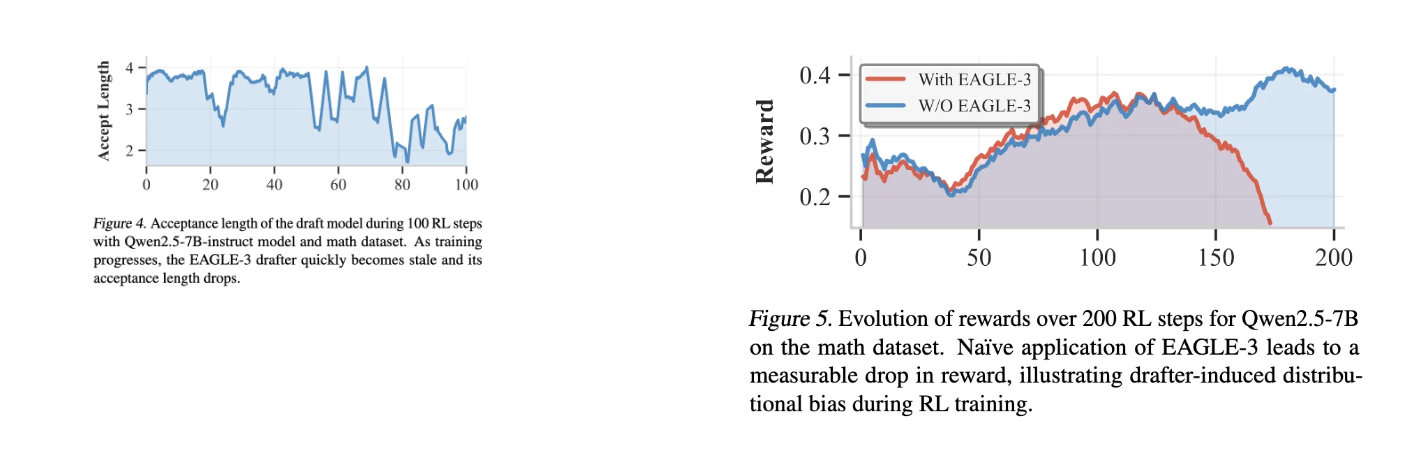
G2:持续actor更新下的drafter陈旧性:随着actor模型在每次策略更新中演进,固定的drafter迅速变得与actor分布不对齐,导致加速效益的损失。如图4所示,在RL训练过程中,EAGLE-3 drafter的接受长度随训练步数增加而急剧下降,从初始的约4个token降至1个token以下。
-
G3:Drafter诱导的actor性能退化:即使token级接受保持正确,多token起草也可能具有很大方差,这种方差随着drafter陈旧性而增加,导致低质量轨迹比率更高。如图5所示,直接应用EAGLE-3会导致奖励分数在约100步后开始下降,从0.4降至接近0,证明drafter引入的分布偏移损害了策略学习。
主要贡献:
- 首次系统性研究:对LLM端到端RL训练中的SD进行了首次系统性研究,揭示了三个关键缺陷:加速递减、drafter陈旧性和策略退化,解释了为什么naive SD集成无法提供一致的加速
- 关键机会识别:识别了RL生成中两个未被充分探索的机会:(1)倾斜的生成工作负载支持SD配置的动态适应;(2)on-policy诊断信号可作为持续drafter对齐的监督源
- ReSpec系统设计:设计了首个适应RL训练的SD系统,包含两个紧密耦合的组件:通过分析和运行时调度的自适应SD服务器,以及通过知识蒸馏、奖励加权和异步更新维护drafter对齐的在线学习器
- 实验验证:在Qwen模型(3B-14B)上实现并评估ReSpec,表明它在保持训练稳定性和奖励收敛的同时,相比标准RL训练实现了高达4.5倍的加速
方法论精要
ReSpec系统的核心设计基于对RL训练中生成阶段特性的深入洞察,通过三个互补机制解决了SD在RL环境中的适应性问题。
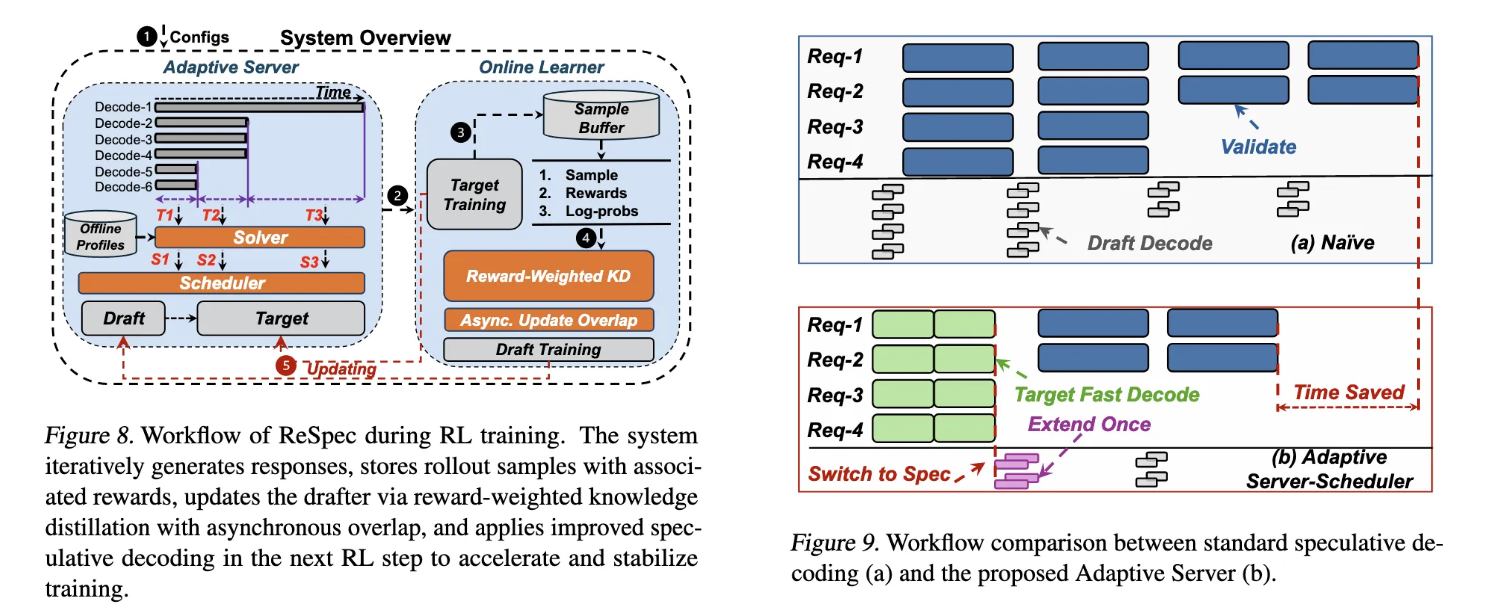
自适应推测解码服务器针对G1问题,通过轻量级分析和运行时工作负载信号动态选择和应用推测解码配置。该服务器包含两个关键组件:Solver通过离线分析引导搜索,Scheduler控制运行时模式切换。在离线分析阶段,系统在各种SD超参数设置和批处理大小下基准测试起草和目标模型的执行时间,结果用于拟合预测性能模型,估计不同SD配置作为活动批处理大小函数的吞吐量加速比。在运行时,Solver根据离线导出的性能模型和观察到的活动批处理大小动态选择预期最大化加速的SD配置。Scheduler作为运行时控制器,决定在生成期间何时以及如何激活SD,同时最小化系统开销。它将解码阶段建模为两状态过程:spec-enabled和non-spec,通过轻量级转换实现零开销运行时切换。
Drafter进化机制针对G2问题,通过在线学习器实现与持续更新actor的对齐。算法1总结了RL集成的推测起草更新工作流程。在rollout期间,系统使用当前drafter(qθ)运行SD,并使用目标模型§验证每个候选。对于每个rollout,系统存储输入和响应以及目标logits和标量奖励。在线学习器从rollout缓冲区提取蒸馏目标,在回放缓冲区(Q)中累积,并每隔(I)次迭代执行周期性奖励加权更新。这种设计确保drafter能够跟踪目标模型的演进分布,而不会减慢整体训练速度。
奖励加权适应机制针对G3问题,通过奖励加权知识蒸馏避免诱导损害策略学习的分布偏移。对于具有每步目标分布和标量奖励的rollout样本,系统最小化样本级损失:LKD(x,y)=w(r)∑t=1TKL(p(⋅∣x,y<t)∣∣qθ(⋅∣x,y<t))L_{KD}(x,y) = w(r) \sum_{t=1}^T KL(p(\cdot|x,y_{<t}) || q_{\theta}(\cdot|x,y_{<t}))LKD(x,y)=w(r)∑t=1TKL(p(⋅∣x,y<t)∣∣qθ(⋅∣x,y<t)),其中w(r)>0w(r) > 0w(r)>0是基于奖励的加权函数(默认w(r)=rw(r) = rw(r)=r)。使用存储的logits(logp\log plogp),在更新时通过softmax(logp)softmax(\log p)softmax(logp)实现软目标,并计算与当前drafter(qθq_{\theta}qθ)的加权交叉熵。与标准KD相比,奖励加权KD减轻了低奖励样本的贡献,放大了高奖励样本,引导drafter向与目标匹配并经验上产生高奖励的行为。实验表明,在Qwen2.5-7B上,无奖励KD和仅eagle方法在约125步左右开始退化,而奖励加权KD在相同范围内保持稳定增长的奖励。
异步更新重叠机制通过利用RL流水线中的空闲时隙,将drafter模型更新与目标rollout并行运行,确保更新产生可忽略的额外wall-clock延迟。这种设计平衡了系统效率和算法新鲜度:避免阻塞同步同时仍提供足够频繁的更新,使drafter模型能够持续跟踪目标的演进分布而不减慢整体训练速度。
实验洞察
ReSpec在Qwen系列模型(3B-14B参数)上的全面评估验证了其在训练稳定性和计算效率方面的卓越表现。
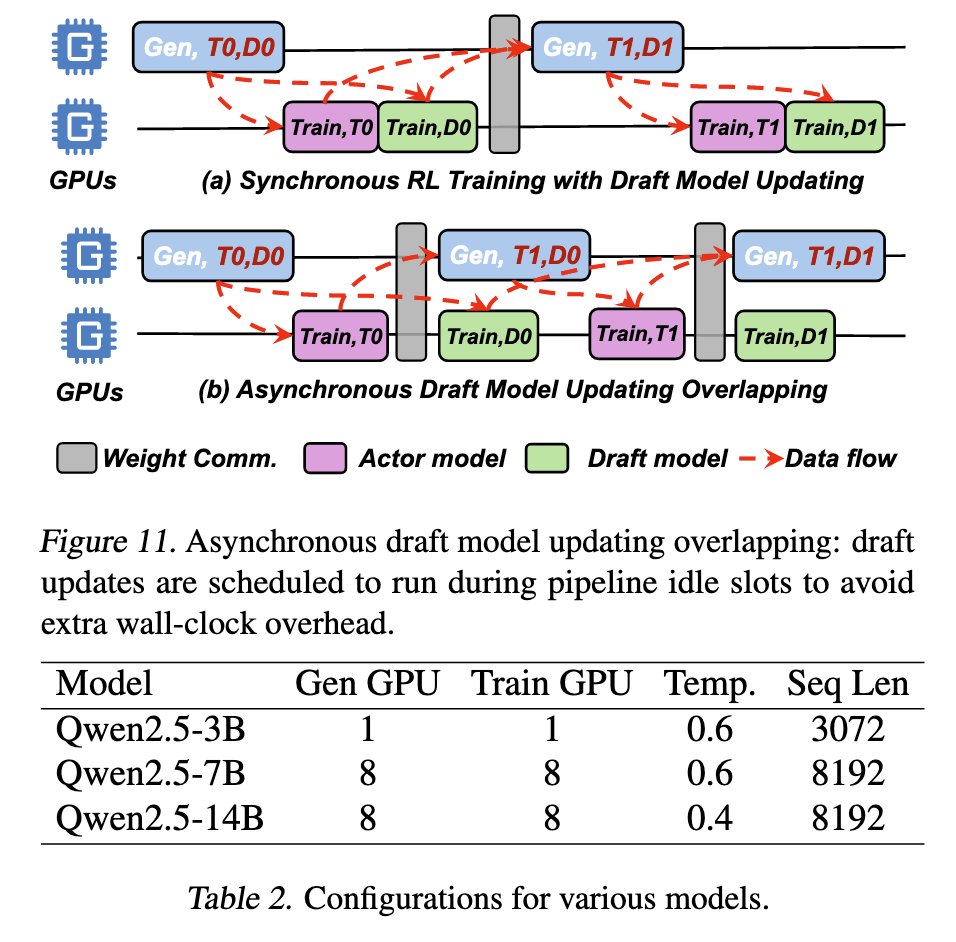
训练稳定性分析显示ReSpec的在线学习器保持了与无推测加速基线相当的稳定验证分数。如图12所示,跨不同规模的模型,该方法避免了在RL训练中直接应用EAGLE-3时经常出现的崩溃。在Qwen-3B中,即使在400步后,我们的验证分数轨迹仍与无加速基线保持一致,而EAGLE-3经常导致退化,如在400步后降至0.15。在Qwen-7B中观察到类似模式,我们的方法在160-180步时维持较高分数(0.4),而EAGLE-3早期崩溃(0.06-0.2)。对于更大的模型如Qwen-14B,ReSpec始终跟踪基线趋势,而EAGLE-3在更长范围后表现出分歧,验证分数不稳定或下降。这些结果确认了我们的方法在保持收敛保证的同时仍能从SD中受益。
端到端加速效果令人印象深刻。如图13所示,对于Qwen-3B,我们的方法产生高达4.53倍的端到端训练加速,中位数提升约为1.84倍,特别是在推测执行最有效的早期生成阶段。对于更大的模型,增益仍然可观且更加稳定:Qwen-7B平均1.69倍(峰值2.41倍),Qwen-14B为1.50倍(高达2.60倍)。我们观察到推测加速在早期生成阶段最为显著,此时token级并行性得到最大利用。这些发现突显了ReSpec提供了期望的平衡:它在准确性和奖励稳定性方面匹配基线RL训练,同时在不同模型规模上提供一致的端到端加速。
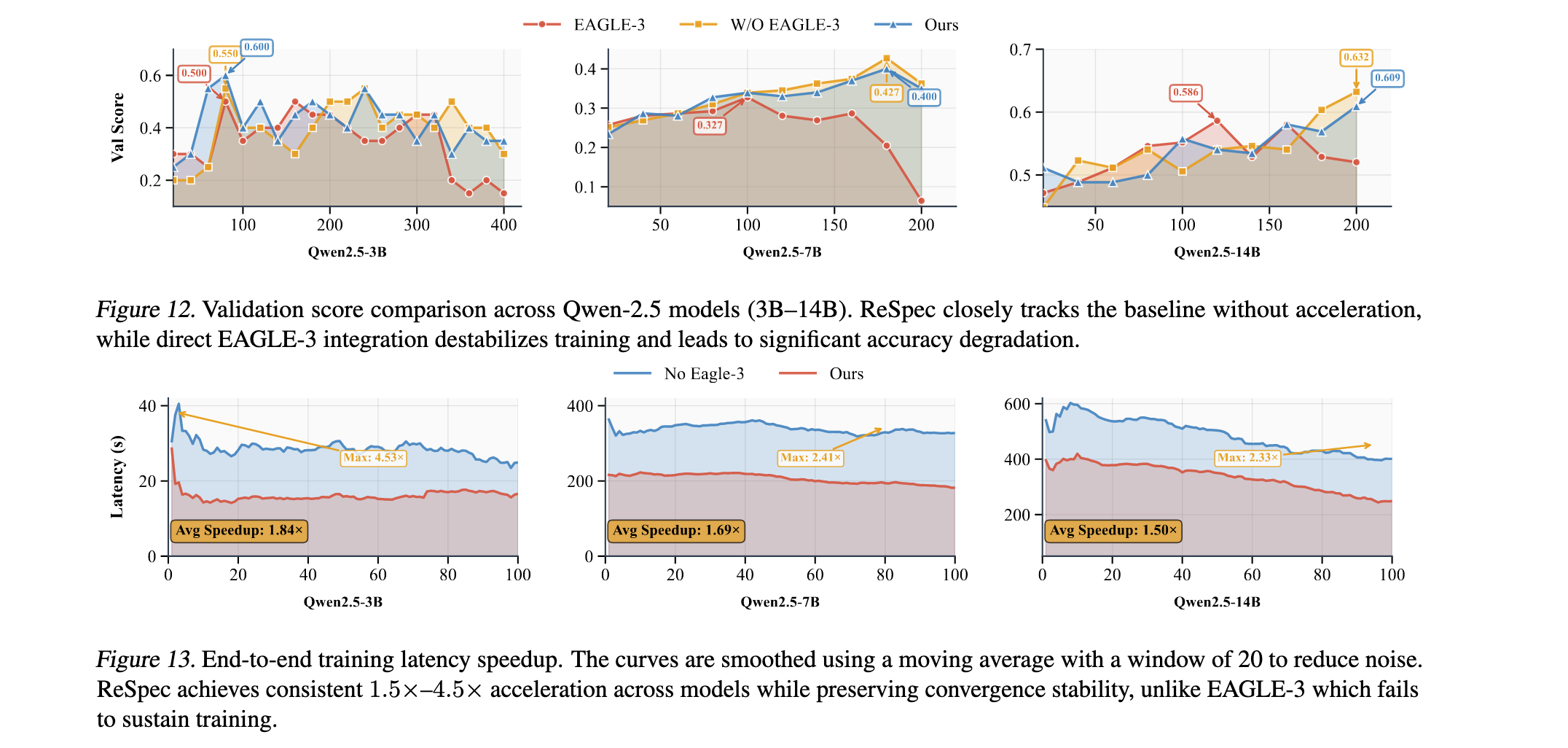
组件贡献分析进一步量化了ReSpec各组件的贡献。如图14所示,无SD的基线系统标准化为1.0×。在在线学习器中引入奖励加权KD算法通过稳定SD和增强起草接受率实现了1.48倍的改进。添加包括solver和scheduler的自适应服务器带来了额外的12%增益(总计1.66倍),通过在变化工作负载下动态选择最有效的SD配置。最后启用异步更新重叠机制通过将在线学习与rollout执行重叠进一步隐藏了drafter更新延迟,达到整体1.78倍的加速。这些结果表明ReSpec中的算法和系统级优化是互补的,共同贡献于端到端效率。
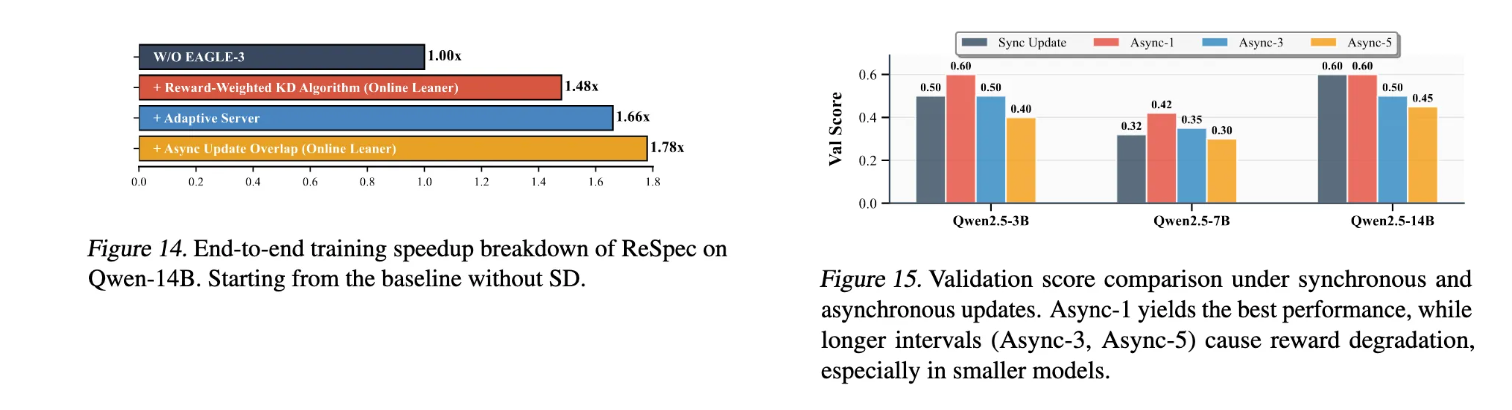
异步更新频率分析验证了异步更新重叠设计的有效性。图15报告了同步更新和不同间隔(I=1,3,5)的异步更新下的验证分数。对于Qwen2.5-3B和7B,我们观察到小间隔下异步更新的明显优势。特别是Async-1达到最高奖励(分别为0.60和0.42),明显优于同步更新。将间隔增加到3步消除了这一增益,在5步时性能进一步降至同步水平以下。这一趋势表明较小的模型更关键地依赖于及时的drafter模型适应来跟踪演进的目标分布。对于Qwen2.5-14B,同步更新已经达到相对较高的奖励(0.60),Async-1保持这一水平而无改进。然而在更长间隔下性能仍然退化(Async-3: 0.50, Async-5: 0.45)。这表明较大的模型本质上对陈旧drafter更新更鲁棒,但仍受益于避免过度延迟。
总体而言,ReSpec在保持RL训练收敛稳定性的同时实现了显著的计算加速,为大规模LLM的强化学习训练提供了实用且高效的解决方案。