第二十一周周报
文章目录
- 摘要
- Abstract
- 为什么BERT有用呢?
- Multi-lingual BERT(多语言BERT)
- 总结
摘要
本周在继续学习 BERT 模型的基础上,重点理解了其为何能以这种方式工作。通过李宏毅老师的讲解,进一步掌握了 BERT 依靠自监督学习与双向 Transformer 结构从上下文中提取语义信息的原理。同时还学习了多语言 BERT(Multilingual BERT)的设计思路,了解其如何在不同语言间共享语义表示,从而实现跨语言理解与迁移。本次学习加深了我对 BERT 内部机制与多语言模型的认识,为后续深入研究语言模型架构与应用奠定了基础。
Abstract
This week, while continuing to study the BERT model, I focused on understanding why it works in this particular way. Through Professor Hongyi Lee’s lectures, I gained deeper insights into how BERT utilizes self-supervised learning and a bidirectional Transformer architecture to extract semantic information from context. Additionally, I learned about the design principles of Multilingual BERT and how it shares semantic representations across different languages to achieve cross-lingual understanding and transfer. This study has enhanced my comprehension of BERT’s internal mechanisms and multilingual models, laying a solid foundation for further research on language model architectures and their applications.
为什么BERT有用呢?
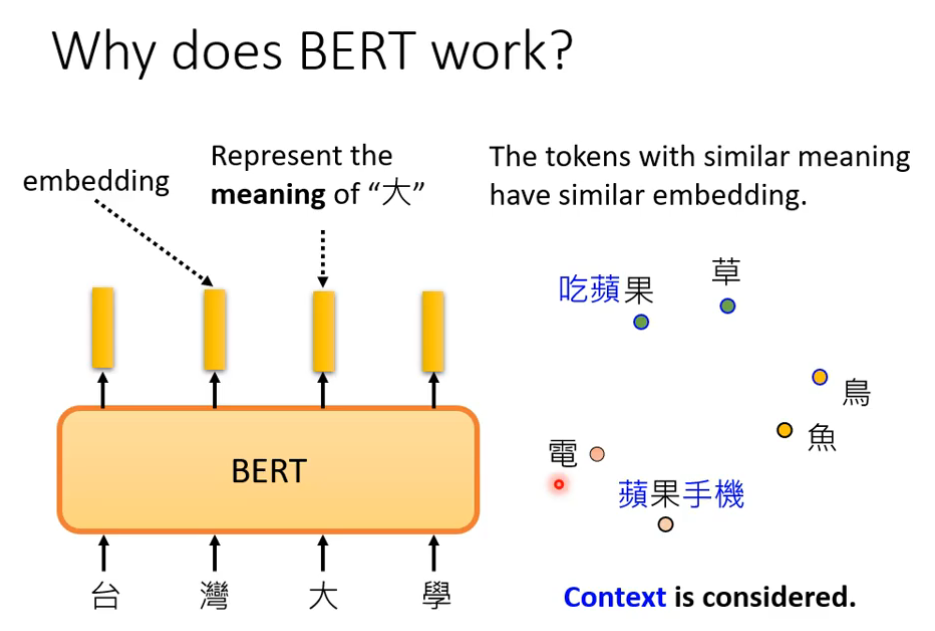
意思越相近的字产生的向量越接近,如图部分。同时,BERT会根据上下文,不同语义的同一个字产生不同的向量,(例如果字),对于吃的苹果和苹果手机,经过BERT后输出的向量是不同的。
于是我们搜寻许多包括“果”字的句子,将它们都放入到BERT里面进行处理,下图中,果对应的两个向量是不同的,为什么不同呢,因为训练填空题BERT时,就是从上下文抽取资讯来填空的,所以语义不同输出的向量当然不同了。
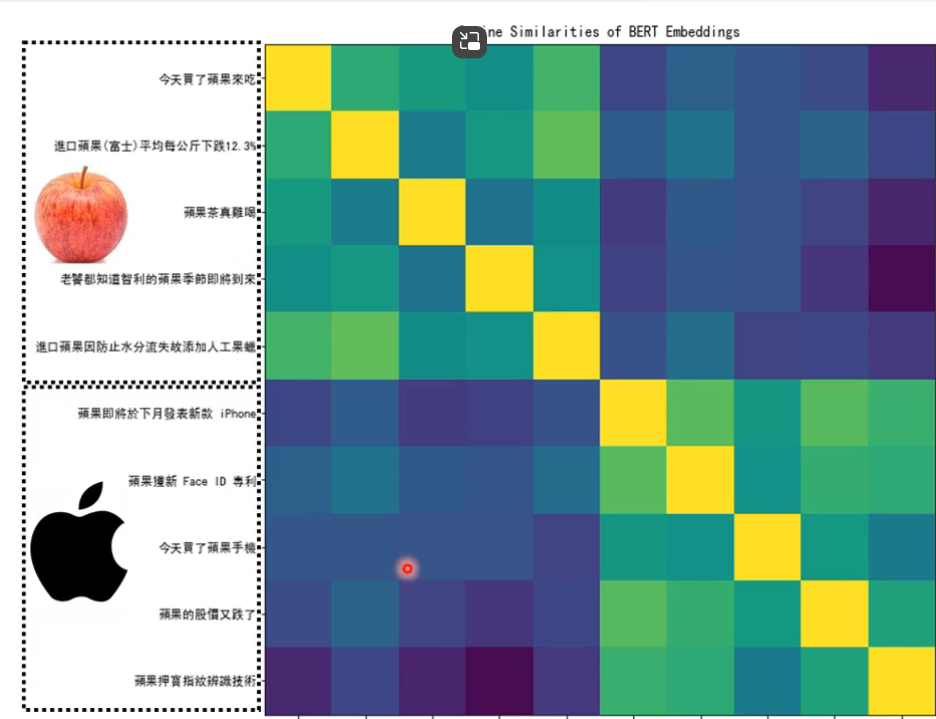
如上图所示,我们找了10个句子,经过BERT输出的向量,把他们两两进行相似度比较后得到一个10*10的矩阵,(黄色为自己和自己进行相似度比较,所以相似度最高),通过相似度对比我们发现,前五个“果”之间的相似度比较高;后五个“果”之间的相似度比较高;而前五个和后五个之间的相似度就比较低了。
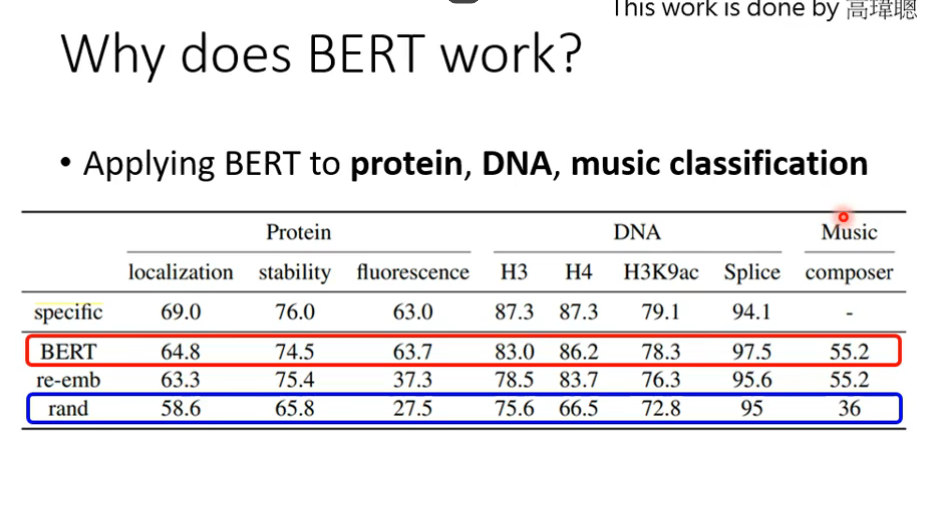
应用BERT来研究蛋白质、DNA、音乐分类等问题中在,使用we,you等字代替氨基酸,最后训练出来的结果竟然会比较好,所以可能BERT的初始化参数就比较好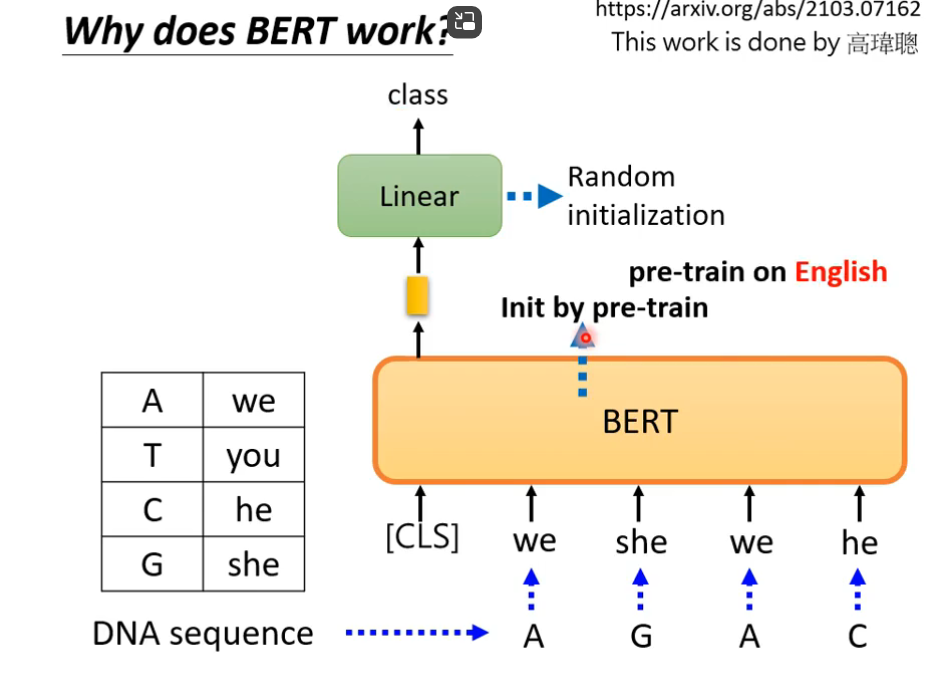
Multi-lingual BERT(多语言BERT)
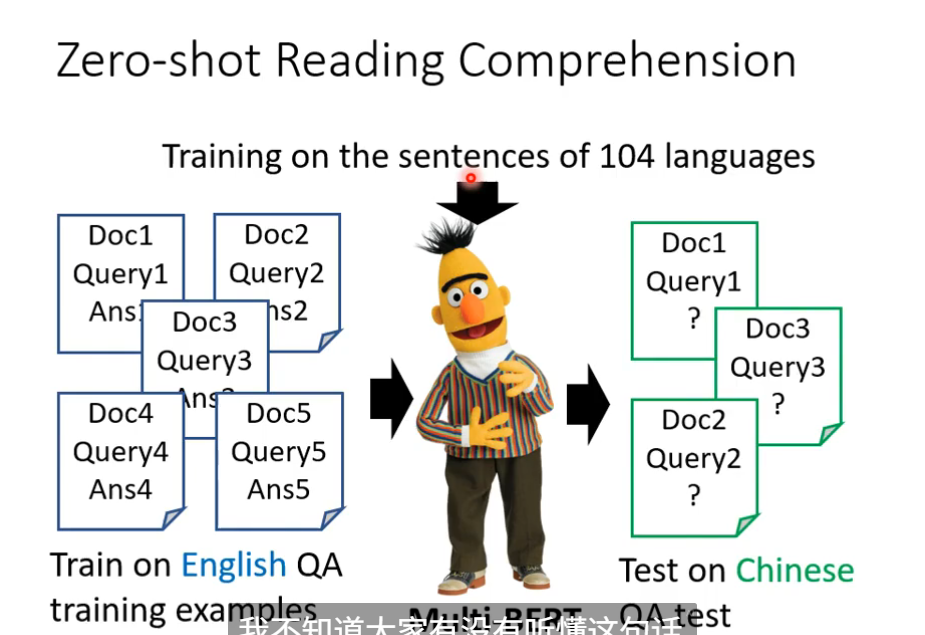
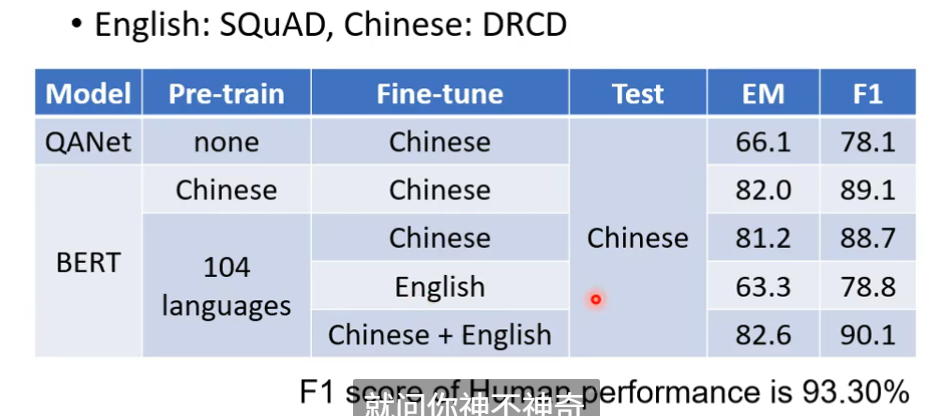
为什么可以做到multi-BERT
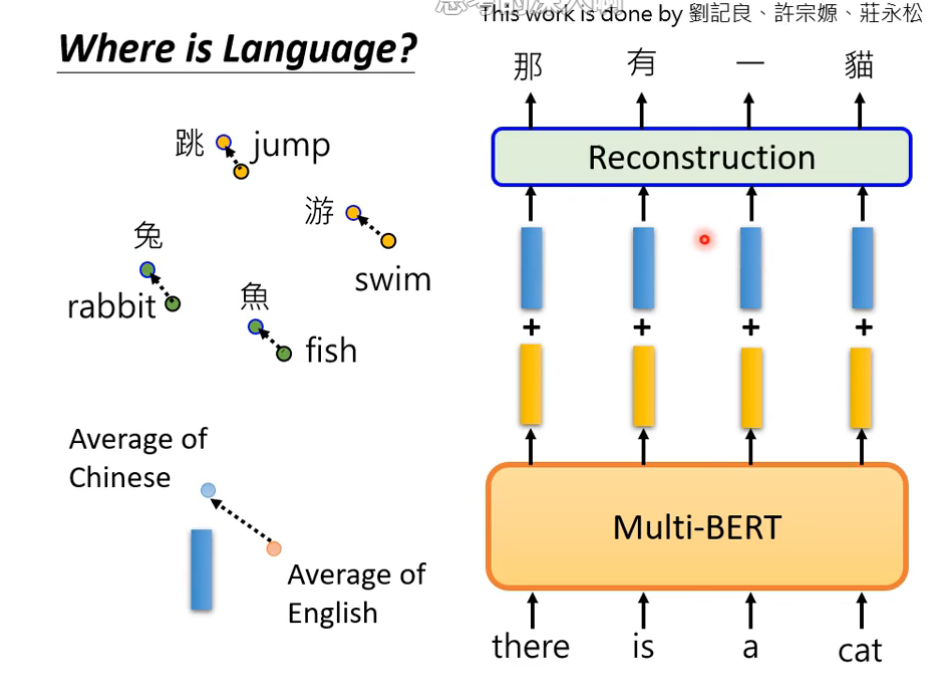
因为不同语言之间存在对齐情况,即同义的不同语言的向量会比较接近,所以语言和语言之间输出的向量是存在一定关系的。
为了探寻不同语言之间的关系,做了下面这样一件事:
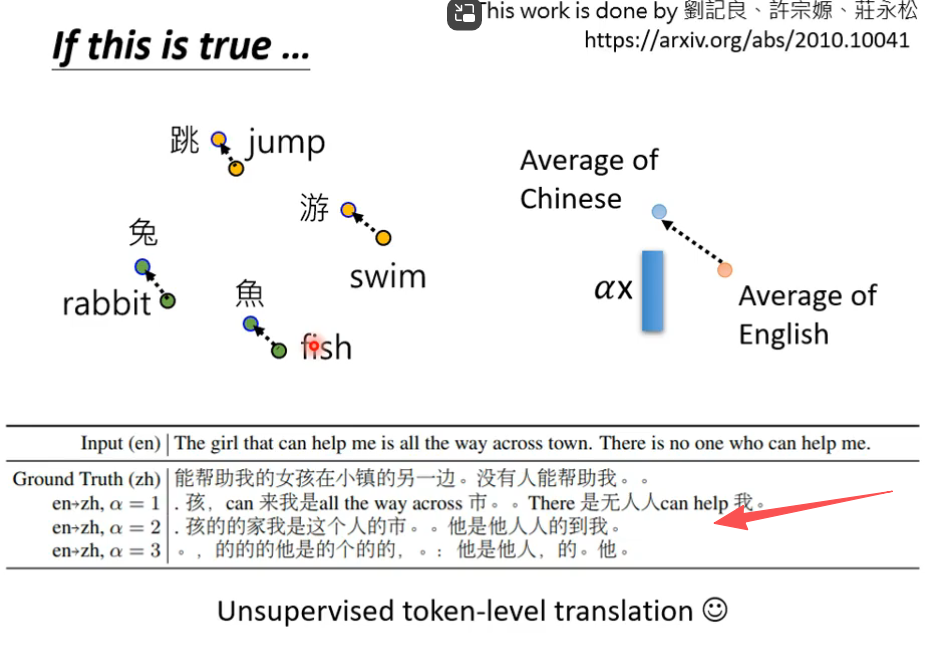
将所有中文的embbeding平均一下,英文的embbeding平均一下,发现两者之间存在着差距,这个差距用一个蓝色向量来表示。对一个multi-BERT输入英文问题和文章,他会输出一堆embedding,这堆embedding加上这个差距后,最终竟然能输出中文的答案。
eg:
总结
通过本周的学习,我进一步理解了 BERT 的工作原理和背后的自监督机制,明白了模型如何通过上下文双向学习实现更深层的语义理解。对多语言 BERT 的跨语言表示能力有了初步认识,体会到共享语义空间在多语言任务中的重要作用。