C++—string(1):string类的学习与使用
引言
在 C++ 中,std::string 是标准库(STL)提供的字符串类,用于便捷地处理字符串数据。它封装了字符序列的存储、管理和操作,相比 C 语言的字符数组(char*),std::string 提供了更安全、更易用的接口,是 C++ 中处理字符串的首选方式。
一. 字符编码:二进制值与符号的映射关联集合
在学习string类之前,我们需要先了解一下编码的知识。我们都知道,在计算机中,所有的数据都是采用二进制值的形式存储的,在C语言中,我们已经了解过了ASCII编码,然而仅仅通过ASCII编码是完全不足以让表示全球的字符,所以就衍生出了各种不同的编码。
1.1 基础概念:字符集与编码
首先明确两个核心概念:
- 字符集(Character Set):是字符的集合(如英文字母、中文汉字、日文假名等)。例如:ASCII 字符集(仅包含英文字符和控制字符)、GB2312(中文简体字符集)、Unicode(全球统一字符集,包含几乎所有语言的字符)。
- 编码(Encoding):是字符集中的字符与二进制数据的映射规则。同一字符集可对应多种编码(如 Unicode 字符集可通过 UTF-8、UTF-16、UTF-32 等方式编码)。
1.2 C++中主要涉及的编码方案
1. ASCII 编码(单字节编码)
- 字符集:包含 128 个字符(0-127),包括英文字母(大小写)、数字、标点符号及控制字符(如换行
\n、回车\r)。 - 编码规则:每个字符用 1 个字节(8 位)表示,最高位固定为 0(因此范围是 0-127)。
- C++ 支持:
char类型默认兼容 ASCII(char占 1 字节),例如'A'在 ASCII 中编码为 65(二进制01000001),可直接用char c = 'A'表示。
2. 多字节编码(针对非英文字符)
ASCII 仅能表示英文字符,为支持中文、日文等语言,出现了多字节编码(1 个字符可能占 1-2 个字节)。
- GB2312/GBK(中文编码):
- GB2312:包含 6763 个简体汉字,兼容 ASCII(英文字符用 1 字节,汉字用 2 字节,且每个字节的最高位为 1,避免与 ASCII 冲突)。
- GBK:GB2312 的扩展,包含更多汉字(如繁体)和符号,仍兼容 ASCII。
- C++ 支持:
char数组或std::string可存储 GBK 编码的字符串(本质是字节序列),例如"你好"在 GBK 中是两个双字节序列(0xC4 0xE3 0xBA 0xC3)。
3. Unicode 与 UTF 编码(全球统一编码)
ASCII 和 GBK 等编码仅支持局部语言,Unicode 字符集(包含全球所有字符)成为通用标准,其编码方案主要有:
-
UTF-8:
- 可变长度编码(1-4 字节):英文字符用 1 字节(与 ASCII 完全兼容),汉字通常用 3 字节,生僻字用 4 字节。
- 优势:节省空间(英文占 1 字节)、适合网络传输(无字节序问题)。
- C++ 支持:
char或std::string可存储 UTF-8 字节序列(C++20 新增char8_t和std::u8string专门用于 UTF-8,增强类型安全性)。
-
UTF-16:
- 可变长度编码(2 或 4 字节):大部分常用字符(如汉字)用 2 字节,生僻字用 4 字节(通过代理对表示)。
- 注意:存在字节序问题(大端 / 小端),需用 BOM(字节顺序标记)区分。
- C++ 支持:
char16_t类型(C++11 新增),字符串字面量用u""前缀,例如u"你好",对应std::u16string。
-
UTF-32:
- 固定长度编码(4 字节):每个字符直接用 4 字节表示,无字节序歧义(但空间开销大)。
- C++ 支持:
char32_t类型(C++11 新增),字符串字面量用U""前缀,例如U"你好",对应std::u32string。
4. 宽字符编码(wchar_t)
C++ 早期为支持多字节字符引入了wchar_t(宽字符类型),但其宽度依赖平台:
- Windows:
wchar_t占 2 字节,通常用于存储 UTF-16 编码。 - Linux/macOS:
wchar_t占 4 字节,通常用于存储 UTF-32 编码。 - 字符串字面量:用
L""前缀,例如L"你好",对应std::wstring。 - 缺点:平台依赖导致移植性差,C++11 后逐渐被
char16_t/char32_t替代。
二. 为什么要学习string类
2.1 C语言字符串的痛点
C 语言中没有专门的 “字符串类型”,字符串通过字符数组(char[])或字符指针(char*)表示,以空字符'\0'作为结束标志,并依赖strlen、strcpy、strcat等库函数操作。这种方式存在明显缺陷:
1. 内存管理繁琐,容易泄漏或溢出
- C 字符串的内存需要手动分配(
malloc)和释放(free),若忘记释放会导致内存泄漏;若分配的空间不足(如拼接字符串时),会导致缓冲区溢出(Buffer Overflow),引发程序崩溃或安全漏洞(如黑客利用溢出注入恶意代码)。 - 例如,用
strcpy(dst, src)复制字符串时,若src长度超过dst的缓冲区大小,会直接越界写入内存,破坏其他数据。
2. 操作不便,函数设计反直觉
- C 字符串的操作依赖大量库函数,且函数接口设计不直观。例如:
- 比较两个字符串是否相等,不能用
==,必须用strcmp(a, b) == 0; - 拼接字符串需用
strcat,但必须先确保目标缓冲区足够大; - 获取长度需用
strlen(遍历字符直到'\0',时间复杂度O(n))。
- 比较两个字符串是否相等,不能用
- 这些操作不符合人类对 “字符串” 的自然理解,增加了代码编写难度和出错概率。
3. 安全性差,缺乏边界检查
- C 字符串的库函数几乎不做边界检查。例如
strcat(dst, src)会无脑将src的内容追加到dst,完全不检查dst的剩余空间;strncpy虽然能指定长度,但行为设计反直觉(若源字符串过长,不会自动添加'\0',可能导致字符串无结束标志)。 - 这些缺陷使得 C 字符串成为程序漏洞的高频来源(如 “心脏滴血” 漏洞就与缓冲区溢出相关)。
4. 不支持面向对象特性
- C 语言是面向过程的,无法将字符串的 “数据”(字符序列)和 “操作”(拼接、比较、查找等)封装在一起。开发者必须手动管理数据和函数的关联,代码复用性和可维护性差。
2.2 string类的核心优势
C++ 作为面向对象语言,引入std::string类的本质是对字符串进行封装,将数据(字符序列)和操作(方法)结合,同时通过内部机制解决 C 字符串的痛点。
1. 自动内存管理,杜绝手动分配 / 释放
std::string内部维护字符序列的内存,会根据字符串的长度动态分配和释放内存。例如:- 初始化时无需指定大小(如
std::string s = "hello"); - 拼接字符串(
s += " world")时,string会自动检查当前容量,不足则扩容(通常按一定策略翻倍,避免频繁分配); - 字符串销毁时(如离开作用域),
string的析构函数会自动释放内存,无需手动free,彻底避免内存泄漏。
- 初始化时无需指定大小(如
2. 安全的操作接口,减少越界风险
std::string的成员函数和运算符重载均包含边界检查,从根本上避免缓冲区溢出:- 用
operator+=或append拼接时,内部会确保内存足够; - 用
at(index)访问字符时,若索引越界会抛出out_of_range异常(相比[]运算符更安全); - 复制字符串时(如
s2 = s1),string会自动分配足够空间,无需手动计算长度。
- 用
3. 直观的操作符和方法,降低使用成本
std::string重载了大量运算符,符合人类对字符串的自然操作习惯:- 比较:
s1 == s2、s1 < s2(内部自动按字典序比较,无需strcmp); - 拼接:
s = s1 + s2、s += "test"(替代strcat); - 访问:
s[i](类似数组,简洁直观)。
- 比较:
- 提供丰富的成员函数,覆盖常见需求:
- 获取长度:
s.size()或s.length()(O(1)时间复杂度,内部维护长度变量,无需遍历); - 查找子串:
s.find("sub")(返回位置,替代strstr); - 截取子串:
s.substr(pos, len); - 清空:
s.clear()(替代手动置'\0')。
- 获取长度:
4. 面向对象封装,提升代码可维护性
std::string将字符串的 “数据”(字符数组、长度、容量等)和 “行为”(拼接、比较、查找等)封装在类中,用户无需关心内部实现细节(如内存如何分配、如何确保'\0'结尾),只需调用接口即可。- 这种封装使得字符串操作的代码更简洁、可读性更强,也便于后续维护和扩展(例如 C++ 标准对
string的优化,用户无需修改代码即可受益)。
5. 与 STL 无缝集成,扩展能力强
std::string是标准模板库(STL)的一部分,可直接使用 STL 的算法(如std::sort、std::find)处理字符串,例如:
#include <algorithm>
#include <string>
std::string s = "bac";
std::sort(s.begin(), s.end()); // 排序后s为"abc"
- 相比之下,C 字符串需要额外处理指针范围,使用 STL 算法非常繁琐。
6. 支持多字符类型,适配不同编码
- C++11 及以后,
std::string扩展出针对不同编码的版本:std::u8string(char8_t):处理 UTF-8 编码;std::u16string(char16_t):处理 UTF-16 编码;std::u32string(char32_t):处理 UTF-32 编码;std::wstring(wchar_t):处理宽字符编码。
- 这些类型统一继承了
std::string的便捷操作,解决了 C 语言中宽字符与窄字符处理接口不统一的问题。
三. 什么是string类
string类文档介绍
从文档中,我们可以看出,string类实际上是basic_string这个模板实例化出来的模版类typedef得到的,除了这个类之外,basic_string个模板还实例化出了3个类。这些类本质上还是为了支持使用不同编码场景
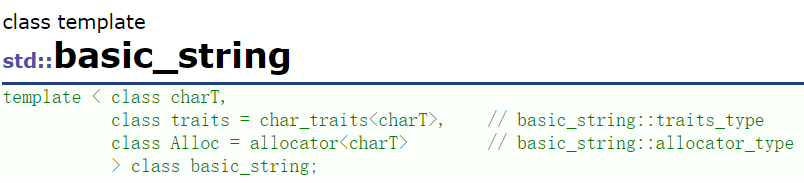
basic_string模板实例化出的不同的类:(string类使用的最多)




C++ 不同的字符类型和字符串类支持上述编码的对应关系如下:
| 字符类型 | 宽度(通常) | 编码场景 | 字符串类 |
|---|---|---|---|
char | 1 字节 | ASCII、GBK、UTF-8 | std::string |
char16_t | 2 字节 | UTF-16 | std::u16string |
char32_t | 4 字节 | UTF-32 | std::u32string |
wchar_t | 2/4 字节 | 平台相关(UTF-16/32) | std::wstring |
四. auto和范围for
C++11引入的auto和范围for与后续的迭代器相关,这里先学习一下
4.1 auto关键字:
- 在早期C/C++中auto的含义是:使用auto修饰的变量,是具有自动存储器的局部变量,后来这个不重要了。C++11中,标准委员会变废为宝赋予了auto全新的含义即:auto不再是一个存储类型指示符,而是作为一个新的类型指示符来指示编译器,auto声明的变量必须由编译器在编译时期推导而得。
- auto在声明变量是,必须通过初始化表达式让编译器推断类型,未初始化的
auto变量会导致编译错误 - 用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
- 若初始化表达式是非引用的
const变量,auto会忽略const(因为是值拷贝,不影响原变量) - 若初始化表达式是 **
const引用或指向const的指针 **,auto会保留const(确保引用 / 指针的权限不被放大) - 当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
- auto不能作为函数的参数,可以做返回值,但是建议谨慎使用
- auto不能直接用来声明数组
auto的使用
void test_string1()
{ // auto// 基础类型推导int i = 10;// 通过初始化表达式值的类型自动推导对象类型// 对象类型长、复杂,比较好用,但是降低了代码的可读性auto j = i;auto k = 20;auto p1 = &i; // 推导出是指针// 与指针、引用结合// 指定一定是指针auto* p2 = &i; // 这个必须传指针cout << p1 << endl;cout << p2 << endl;// 引用int& r1 = i;// r2不是引用,是intauto r2 = r1; // 推出是int,推不出引用// 这样才是引用auto& r3 = i;cout << &r2 << endl; // r2地址与(r1、i、r3)不同,说明不是引用cout << &r1 << endl;cout << &i << endl;cout << &r3 << endl;// 与const结合const int y = 20;auto a = y; // a是int(忽略const,因为是值拷贝)const auto b = y; // b是const int(显式保留const)const int& cr = y;auto& r = cr; // r是const int&(保留const,引用必须与原类型匹配)auto c = cr; // c是int(值拷贝,忽略const)const int* cp = &y;auto p = cp; // p是const int*(保留const,指针指向的对象不可改)
}4.2 范围for
- 对于一个有范围的集合而言,由程序员来说明循环的范围是多余的,有时候还会容易犯错误。因此 C++11中引入了基于范围的for循环。for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围,自动迭代,自动取数据,自动判断结束。
- 范围for可以作用到数组和容器对象上进行遍历,需注意初始化和
const/ 引用的推断规则。 - 范围for的底层很简单,容器遍历实际就是替换为迭代器,这个从汇编层也可以看到。
范围for的使用:
void test_string1()
{string s1("hello world"); // 范围for// 范围for遍历(所有容器都可以用)// 自动取容器中的值赋值给这个对象(对象名字自己随便取),自动迭代++,自动判断结束for (auto ch : s1) {cout << ch << " ";}cout << endl;//for(char& ch : s1)for (auto& ch : s1) // 底层原理是迭代器(语法糖){ch -= 1; // 引用可以修改原字符串修改}cout << endl;// for (const char& ch : s1)for (const auto& ch : s1){++ch; // 不能修改cout << ch << ' ';}cout << endl;// 支持迭代器的容器,都可以用范围for,因为范围for的底层就是迭代器// 数组也支持范围for(特殊处理)int a[10] = { 1,2,3 };for (auto i : a){cout << i <<" ";}cout << endl;// 不能直接遍历指针指向的数组int arr[] = {1, 2, 3};int* p = arr;// for (auto x : p) { ... } // err:p是指针,无法推断数组范围const string s2("apple");// for (char& ch : s2) errfor (const char& ch : s2){// ch++; // 不能修改cout << ch << " ";}for (auto& ch : s2){// ch++; // 不能修改cout << ch << " ";}
}五. string类常用接口的使用
5.1 string类的常用构造及析构
| 函数名称 | 功能说明 |
| string() | 构造空的string类对象,即空字符串 |
| string(const string* s) | 用C-string(C字符串)来构造string类对象 |
| string(size_t n, char c) | string类对象中包含n个字符c |
| string(const string&s) (重点) | 拷贝构造函数 |
| ~string() | 销毁字符串,释放存储字符串的空间 |
void TestString()
{string s1; // 构造空的string类对象s1string s2("hello bit"); // 用C格式字符串构造string类对象s2string s3(s2); // 拷贝构造s3
}5.2 string类对象的容量操作
| 函数名称 | 功能说明 |
| size(一般用这个) | 返回字符串有效字符的个数,不包括' \0' |
| length | 返回字符串有效字符的个数,不包括' \0' |
| capacity | 返回空间总大小,不包含'\0' |
| empty | 检测字符串是否为空串,是返回true,否则返回false |
| clear | 清空有效字符 |
| reserve | 尾字符串预留空间 |
| resize | 将有效字符的个数变为n个,多出的空间用字符c填充 |
注意:
- size()与length()方法底层实现原理完全相同,引入size()的原因是为了与其他容器的接口保持一致,一般情况下基本都是用size()
- clear()只是将string中有效字符清空,不改变底层空间大小
- resize(size_t n) 与 resize(size_t n, char c)都是将字符串中有效字符个数改变到n个,不 同的是当字符个数增多时:resize(n)用'\0'来填充多出的元素空间,resize(size_t n, char c)用字符c来填充多出的元素空间。注意:resize在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变
- reserve(size_t res_arg=0):为string预留空间,不改变有效元素个数,当reserve的参数小于string的底层空间总大小时,reserver不会改变容量大小
size、length、capacity、clear、empty
void test_string1()
{string s1("hello world");// 实际上是16个字节空间,因为capacity不包含'\0'cout << s1.capacity() << endl; // 15cout << s1.size() << endl; // 11cout << s1.length() << endl; // 11if (!s1.empty()){cout << "不是空串" << endl;}else{cout << "是空串" << endl;}s1.clear(); // 会清空有效字符,但是不会改变容量cout << s1.capacity() << endl; // 15cout << s1.size() << endl; // 0if (!s1.empty()){cout << "不是空串" << endl;}else{cout << "是空串" << endl;}
}reserve、resize、shrink_to_fit
void test_string1()
{string s2("apple bnana");cout << s2.capacity() << endl; // 15cout << s2.size() << endl; // 11 // reserve只能扩容,不能缩容// 如果n大于字符串的容量(capacity),则编译器可能调整到指定的n或比n大// 如果n小于字符串的容量(capacity),则编译器的调整是由自己定义的(VS下不会缩容),但是一般都不会缩容// 不会影响字符串的长度,更不会改变其内容s2.reserve(5);cout << s2.capacity() << endl; // 15 cout << s2.size() << endl; // 11s2.reserve(20);cout << s2.capacity() << endl; // 31cout << s2.size() << endl; // 11string s4("hello world");cout << s4.capacity() << endl;// 缩容可以用这个,但是一般不要缩容,因为缩容实际上是用空间换时间,会降降低效率// 除非容量特别大,但是有效字符个数很少的情况下可以用缩容s4.shrink_to_fit(); // 可能会缩容,但是不可能小于字符串长度,因为它不能影响字符串长度,也不能修改字符串cout << s4.size() << endl;cout << s4.capacity() << endl;
}// linux下是2倍扩容
// vs下是1.5倍扩容
void TestCapacity()
{string s1;s1.reserve(200); // 确定知道要插入多少个数据,提前扩容,可以提高效率;不知道不要盲目扩容size_t old = s1.capacity();cout << s1.capacity() << endl;for (size_t i = 0; i < 200; i++){s1.push_back('x');if (s1.capacity() != old){cout << s1.capacity() << endl;old = s1.capacity();}}cout << endl << endl;
}void test_string1()
{string s3("hello nihao"); cout << s3 << endl; // hello nihaocout << s3.size() << endl; // 11cout << s3.capacity() << endl; // 15s3.resize(3);cout << s3 << endl; // helcout << s3.size() << endl; // 3cout << s3.capacity() << endl; // 15s3.resize(10); // 不指定字符,默认用'\0'来补充size到ncout << s3 << endl;cout << s3.size() << endl; // 10cout << s3.capacity() << endl; // 15s3.resize(20, 'x'); // 指定定字符,就用指定字符补充size到ncout << s3 << endl; // helxxxxxxxxxx hel与xxxxxxxxxx之间还有7个'\0',打印时观察不到,调试时才能看到cout << s3.size() << endl; // 20cout << s3.capacity() << endl; // 31 capacity底层自己会扩容,不用管
}5.3 string类对象的遍历及访问操作
| 函数名称 | 功能说明 |
| operator[ ] | 返回pos位置的字符,并且可以对pos位置字符进行修改,有const修饰则不能 |
| at | 与operator[ ]功能相同,不同的是越界访问会抛异常 |
| begin + end | begin获取第一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器 |
| rbegin + rend | rbegin获取反向的第一个字符的迭代器 + rend获取反向的最后一个字符下一个位置的迭代器 |
| 范围for | C++11支持更简洁的范围for的新遍历方式 |
1. 下标+[ ]遍历
void test_string()
{ // 对string某个位置度或写string s1("hello world");s1[0] = 'x';cout << s1 << endl;cout << s1[0] << endl;// 越界有严格的断言检查//s1[12]; // 断言 debug下断言才有效果,release不行;断言程序会直接终止//s1.at(12); // 抛异常 at与[]类似,但他越界是抛异常,而不是断言;异常捕获后,程序不会终止,如果后面还有程序可以继续运行// 下标遍历、修改for (size_t i = 0; i < s1.size(); i++){// ++s1[i]; // 可以修改cout << s1[i] << " ";}cout << endl;const string s2("apple");for (size_t i = 0; i < s1.size(); i++){// ++s1[i]; // err:不可以修改cout << s1[i] << " ";}
}2. 迭代器遍历
void test_string()
{string s1("hello world");// [ begin(),end() ) 区间是左闭右开的// it1 = s1.end();// cout << *it1 << endl; // err 取不到// 迭代器(用来遍历的)// iterator正向迭代器// 行为像指针一样的东西,可以认为是指针,实际底层实现不一定是指针string::iterator it1 = s1.begin();while (it1 != s.end()) // 遍历{// *it1 = 'x'; // OK:可以修改cout << *it1 << " ";++it1;}cout << endl;string::const_iterator _it1 = s1.begin();while (_it1 != s.end()) // 遍历{// *it1 = 'x'; // err:不能修改cout << *it1 << " ";++it1;}cout << endl;// const修饰const string s2("apple");string::const_iterator _it = s2.begin();while (_it != s2.end()){// *it2 = 'x'; // err:不能修改cout << *it << endl;it2++;}
}问:为什么不使用const iterator去遍历?
答:因为这样的话,const修饰的是迭代器本身(类比指针:T* const,修饰的是指针本身),不能++了,就无法遍历,应该类比指向内容的const(const T*)
void test_string()
{string s1("hello world");// 反向迭代器(倒着遍历)string s1("hello world");string::reverse_iterator it1 = s1.rbegin();while (it1 != s1.rend()){*it1 = 'x'; //OK:可以修改cout << *it1;it1++;}string::const_reverse_iterator it2 = s.rbegin();while (it2 != s.rend()) // 遍历{// *it1 = 'x'; // err:不能修改cout << *it2 << " ";++it2;}cout << endl;
}3. 范围for(C++11)
void test_string1()
{string s1("hello world"); // 范围for// 范围for遍历(所有容器都可以用)// 自动取容器中的值赋值给这个对象(对象名字自己随便取),自动迭代++,自动判断结束for (auto ch : s1) {cout << ch << " ";}cout << endl;//for(char& ch : s1)for (auto& ch : s1) // 底层原理是迭代器(语法糖){ch -= 1; // 引用可以修改原字符串修改}cout << endl;// for (const char& ch : s1)for (const auto& ch : s1){++ch; // 不能修改cout << ch << ' ';}cout << endl;// const修饰const string s2("apple");// for (char& ch : s2) errfor (const char& ch : s2){// ch++; // 不能修改cout << ch << " ";}for (auto& ch : s2){// ch++; // 不能修改cout << ch << " ";}
}5.4 string类对象的修改操作
| 函数名称 | 功能说明 |
| push_back | 在字符串尾插一个字符c |
| append | 在字符串后追加一个字符串(字符不行) |
| operator+= | 在字符串末尾追加一个字符串或字符 |
| c_str | 返回C格式的字符串 |
| npos | 静态成员常量,常与find/rfind搭配使用 |
| find + npos | 从字符串pos位置开始往后找字符c,返回该字符在字符串中的位置,没找到则返回npos |
| rfind + npos | 从字符串pos位置开始往前找字符c,返回该字符在字符串中的位置,没找到则返回npos |
| substr | 从字符串pos位置开始截取n个字符,然后将其返回 |
注意:
- 在string尾部追加字符时,s.push_back(c) / s.append(1, c) / s += 'c'三种的实现方式差 不多,一般情况下string类的+=操作用的比较多,+=操作不仅可以连接单个字符,还可以连接字符串。
- 对string操作时,如果能够大概预估到放多少字符,可以先通过reserve把空间预留好。
push_back、append、operator+=、assign
void test_string1()
{string s1("hello world");s1.push_back('*');s1.append("haha"); // 空间不够自己会扩容cout << s1 << endl;s1.append(5, '%'); //append追加单个字符必须指定个数cout << s1 << endl;string s2("hehexixi");//s1.append(s2);s1.append(++s2.begin(), --s2.end()); // 可以用迭代器cout << s1 << endl;// +=更加方便string s3("hello world");s3 += 'x';s3 += ' ';s3 += "apple";cout << s3 << endl;// +是重载在全局的,因为如果是成员函数,this指针一定在前,那么只能在后面加,不能再前面加cout << s3 + "xxx" << endl;cout << "xxx" + s3 << endl;s3.assign("zzz"); // 为字符串分配新值,替换其当前内容cout << s3 << endl;
}insert、erase、replace
void test_string()
{// 少用insert,erase,replace// 本质是用时间换空间,会降低效率string s1("hello world");cout << s1 << endl;s1.insert(0, "xxx");cout << s1 << endl;//s1.insert(0, '^'); // 不能这样插入一个字符s1.insert(0, 1, '^'); // 在指定位置插入单个自字符必须指定个数cout << s1 << endl;s1.insert(5, 2, '*');cout << s1 << endl;s1.insert(s1.begin(), '%'); // 可以使用迭代器cout << s1 << endl << endl;string s2("hello world");cout << s2 << endl;s2.erase(s2.begin()); // 头删cout << s2 << endl;s2.erase(0, 1); // 头删cout << s2 << endl;s2.erase(5, 2); // 下标为5开始,删2个cout << s2 << endl;s2.erase(5, 10); // 下标为5之后的全删,10要大于剩余的字符串,就把剩的全删了;10不给默认到整型最大值,也是全删cout << s2 << endl << endl;s2.erase(); // 全删,一般不用这个;用s2.clear()string s3("hello world");cout << s3 << endl;// replace(),从pos位置开始n个字符替换为指定的内容s3.replace(5, 1, "***"); // 本质是插入cout << s3 << endl;s3.replace(5, 3, "%"); // 本质是删除cout << s3 << endl;
}题目:所有空格替换成%%
void test_string()
{// 法1:效率很低string s4("hello world hello apple");size_t pos = s4.find(' ');while (pos != string::npos){s4.replace(pos, 1, "%%");// 找下一个空格pos = s4.find(' ', pos + 2);}cout << s4 << endl;// 法2string s5("hello world hello apple");string s6;s6.reserve(s5.size());for (auto ch : s5){if (ch != ' '){s6 += ch;}else{s6 += "%%";}}cout << s6 << endl;// s5 = s6;
}c_str
C++ 的 std::string 是对字符串的封装,而很多场景(尤其是 C 语言遗留的库函数或 API)要求使用C 风格字符串(即 const char* 类型,且必须以 '\0' 结尾)。c_str() 的存在就是为了填补这个兼容性缺口。
int main() {std::string filename = "data.txt";// fopen要求const char*类型的文件名,必须用c_str()转换FILE* f = fopen(filename.c_str(), "r"); std::string msg = "hello";// printf的%s格式需要C风格字符串printf("Message: %s\n", msg.c_str()); return 0;
}substr、find、rfind
void test_string()
{// substr很好用,copy少用// substr:返回一个新的字符串对象,其值被初始化为该对象一个子字符串的一个副本// find:在字符串中寻找从指定位置开始,要找的字符第一次出现的位置下标// 找后缀string file1("test.c");size_t pos1 = file1.find('.'); if (pos1 != string::npos){string suffix = file1.substr(pos1); // 如果要取到末尾,可以不传,直接用缺省值cout << suffix << endl;}// 后缀比较长,找最后一个后缀的情况string file2("test.c.tar.zip");size_t pos2 = file2.rfind('.'); // rfind倒着找if (pos2 != string::npos){string suffix = file2.substr(pos2); // 如果要取到末尾,可以不传,直接用缺省值cout << suffix << endl;}// 分割字符串string url = "https://gitee.com/liang-xiandi/2025.9.14";// copy还要计算使用多大的空间在开空间,比较麻烦;substr底层自己管理size_t i1 = url.find(':');if (i1 != string::npos){// 网络协议string protocol = url.substr(0, i1);cout << protocol << endl;// 域名size_t i2 = url.find('/', i1 + 3);if (i2 != string::npos){string domain = url.substr(i1 + 3, i2 - (i1 + 3));cout << domain << endl;}// 资源string uri = url.substr(i2 + 1);cout << uri << endl;}
}find_first_of、find_last_of、find_first_not_of、find_last_not_of
void test_string()
{// find_first_of 返回第一个为"aeiou"其中任意一个字母的下标// find_first_not_of 返回第一个不为"aeiou"其中任意一个字母的下标std::string str("Please, replace the vowels in this sentence by asterisks.");std::size_t found = str.find_first_not_of("aeiou");while (found != std::string::npos){str[found] = '*';found = str.find_first_not_of("aeiou", found + 1);}std::cout << str << '\n';// find_last_of 倒着找// find_last_not_of 与上面类似
}5.5 string类非成员函数(全局函数)
| 成员函数 | 功能说明 |
| operator+ | + 运算符重载,尽量少用,因为传值返回,导致深拷贝效率低 |
| operator>> | 输入运算符重载 |
| operator<< | 输出运算符重载 |
| getline | 获取一行字符 |
| relational operators (重点) | 大小比较 |
relational operators
void test_string()
{// 用ASCII码值比较(逐个比较,ASCII码值小的就小,相等就比较下一个)cout << (str < url) << endl; // 注意运算符优先级// 比较用运算符重载更简便,不用compare
}operator+
void test_string()
{// + 要重载在全局,不能是成员函数cout << str + "xxxxx" << endl;cout << str + url << endl;cout << "xxxxx" + str << endl; // 重载为成员函数无法实现这个}getline
void test_string()
{string s1, s2;// 流插入默认空格或换为为间隔// cin >> s1 >> s2;// getline默认换行为间隔getline(cin, s1,);// getline也可以自己指定间隔标准getline(cin, s2,'*');cout << s1 << endl;cout << s2 << endl;
}总结
如有不足或改进之处,欢迎大家在评论区积极讨论,后续我也会持续更新C++相关的知识。文章制作不易,如果文章对你有帮助,就点赞收藏关注支持一下作者吧,让我们一起努力,共同进步!