【Agentic RL 专题】三、深入浅出强化学习算法 TRPO 和PPO

🧔 这里是九年义务漏网鲨鱼,研究生在读,主要研究方向是人脸伪造检测,长期致力于研究多模态大模型技术;国家奖学金获得者,国家级大创项目一项,发明专利一篇,多篇论文在投,蓝桥杯国家级奖项、妈妈杯一等奖。
✍ 博客主要内容为大模型技术的学习以及相关面经,本人已得到B站、百度、唯品会等多段多模态大模型的实习offer,为了能够紧跟前沿知识,决定写一个“从零学习 RL”主题的专栏。这个专栏将记录我个人的主观学习过程,因此会存在错误,若有出错,欢迎大家在评论区帮助我指出。除此之外,博客内容也会分享一些我在本科期间的一些知识以及项目经验。
🌎 Github仓库地址:Baby Awesome Reinforcement Learning for LLMs and Agentic AI
📩 有兴趣合作的研究者可以联系我:yirongzzz@163.com
深入浅出强化学习算法 TRPO 和PPO
文章目录
- 深入浅出强化学习算法 TRPO 和PPO
- 🦈 前言
- 一、 Policy Optimization
- 二、信任区域的尝试:TRPO
- 三、PPO:平衡性能与简易性的王者
- 四、TRPO vs PPO
- 五、PPO代码实现
- 六、专栏面试问题角
- 七、总结与展望
- ✍ 参考链接
🦈 前言
在了解完Memory专题后,我们可以了解到智能体中的记忆功能,是需要通过强化学习技术进行动态的环境交互,通过奖励信号学习何时写入、更新、删除或保留记忆,从而更好地支持下游决策和任务完成。例如,在 Memory-R1 框架中,Memory Manager 使用PPO或GRPO来动态调整记忆操作,而 Answer Agent 则通过 Memory Distillation 对 RAG 检索到的信息进行推理和回答。为了更进一步的深入,本专题将从经典的TRPO, PPO强化学习算法开始学习。
一、 Policy Optimization
在强化学习中,主要可以分为两种学习方法,一种是 Value-based 的方法 (Q-learning),此类方法是通过学习一个值函数来间接决定动作的。 Value-based 的方法在许多简单的问题上都失败了,并且很难理解,并不是Agentic RL中所采用的强化学习方式。 另一种是Policy-based方法 (TRPO, PPO),是直接学习一个策略函数 π(a∣s;θ)π(a|s; θ)π(a∣s;θ),表示在参数为θ\thetaθ, 状态为s的情况下选择行动a的概率。此类方法时通过优化参数来学习。但由于\theta涉及到了环境的随机性,梯度无法直接计算,因此还需要找到一个estimator来计算这个梯度:
g=Et[∇θlogπθ(at∣st)At]g = E^t[∇_θ logπ_θ(a_t∣s_t)A_t] g=Et[∇θlogπθ(at∣st)At]
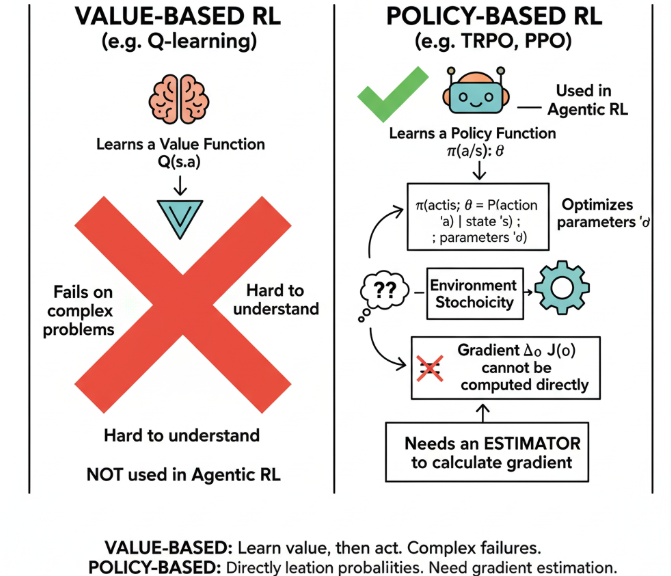
🧠 AtA_tAt 是什么,为什么要估计梯度时要乘上他?
因为如果是简单的求梯度,只是优化了增加当前状态选择该动作的概率。动作是有好有坏的,需要告诉他参数应该往哪边偏,因此需要有一个优势函数AtA_tAt来辅助参数的优化,告诉模型当前的动作是一个好动作还是一个坏的动作,好动作我们希望奖励,坏动作则对应惩罚:
At=Q(st,at)A_t=Q(s_t,a_t)At=Q(st,at),−V(st)≈Rt−V(st), −V(s_t)≈R_t−V(s_t),−V(st)≈Rt−V(st)
🧠 为什么不能直接用 RtR_tRt (未来的总回报) 替换 AtA_tAt?
可以,但效果不好。logπθ(at∣st)\log\pi_\theta(a_t|s_t)logπθ(at∣st) 项的意义是“增加(或减少)在状态 sts_tst 时选择 ata_tat 的概率”。
- 如果我们直接乘以 RtR_tRt(总回报),RtR_tRt 几乎总是正的(比如游戏得分)。这意味着模型会“增加所有动作的概率”,只是“好动作”增加得多,“坏动作”增加得少,收敛很慢。
- 我们需要的是一个“基线 (Baseline)”。动作的好坏是相对的。
🧠 RL的采样成本高,为什么不能对同一批数据进行反复更新?
这是由于在强化学习中,我们首先采用一个旧策略去得到一批数据,这批数据反应的是旧策略的状态-动作数据分布,如果反复更新,会导致新策略已经和旧策略差别很大了,用它去更新新策略,这个估计可能严重偏离真实梯度,从而导致会导致训练崩塌。
二、信任区域的尝试:TRPO
为了解决 On-Policy 采样效率低的问题,TRPO (Trust Region Policy Optimization) 在 2015 年被提出。TRPO属于早期的Policy-based方法,TRPO 的核心思想是:我们可以用旧数据(πold\pi_{old}πold)做多步更新,但前提是必须给新策略(πθ\pi_\thetaπθ)一个“信任区域 (Trust Region)”。
TRPO 通过 trust region 明确约束 KL 散度,同样保证梯度估计在安全范围内,通过约束新旧策略的KL散度来避免策略崩塌,通过优化目标:
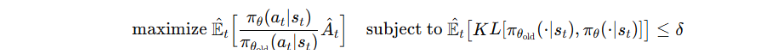
🧠 但是该方法无法适用于复杂的架构,为什么不适用?
Dropout层会使得梯度带有高方差,从而破坏了KL散度约束的精确计算。TRPO 的 KL 散度约束是基于“单一策略参数”的,而共享参数会让 KL 计算更复杂、不再严格符合理论前提。

三、PPO:平衡性能与简易性的王者
PPO 在 2017 出来后,成为最常用的 policy optimization 算法,因为它又稳又简单,并且在instructGPT中的RLHF微调,也是采用了PPO来优化模型的。PPO与TRPO 类似,PPO提出了Clipped Surrogate Objective限制新旧策略差距, 允许在同一批数据上做多步更新。相较于KL散度约束,PPO采用了硬约束的方式:
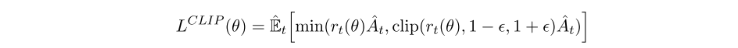
我们来拆解这个公式:
- rt(θ)r_t(\theta)rt(θ):这是新旧策略的概率比 (Probability Ratio),其中:rt(θ)=πθ(at∣st)πθold(at∣st)r_t(\theta) = \frac{\pi_\theta(a_t|s_t)}{\pi_{\theta_{old}}(a_t|s_t)}rt(θ)=πθold(at∣st)πθ(at∣st)
- rt(θ)>1r_t(\theta) > 1rt(θ)>1:新策略更倾向于做 a_t。
- rt(θ)r_t(\theta)rt(θ) < 1:新策略更不倾向于做 a_t。
- clip(rt,1−ϵ,1+ϵ)\text{clip}(r_t, 1-\epsilon, 1+\epsilon)clip(rt,1−ϵ,1+ϵ):这就是 PPO 的灵魂。ϵ\epsilonϵ 是一个超参数(通常为 0.2)。它强行把 rtr_trt 裁剪到 [1−ϵ,1+ϵ][1-\epsilon, 1+\epsilon][1−ϵ,1+ϵ](即 [0.8,1.2][0.8, 1.2][0.8,1.2])的区间内。
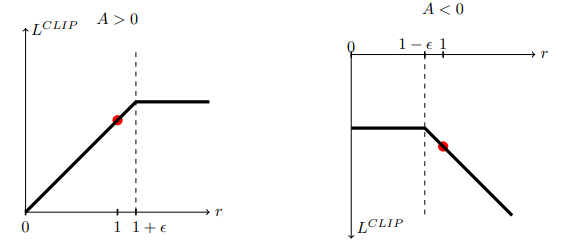
为了防止训练不稳定,除了LCLIPL^{CLIP}LCLIP损失外,PPO还引入了value function loss 和entropy bonus:
value function loss: 既要更新策略,又要保证 value function 能准确预测状态价值;entropy bonus: 如果策略损失收敛过快,会导致数据的多样性下降,只能学习到局部最优;
除此之外,PPO中也可以通过KL散度进行约束: maximizeEt[πθπoldAt−βKL[πold,πθ]]\text{maximize} E^t[\frac{π_θ}{π_{old}}A^t−βKL[π_{old},π_θ]]maximizeEt[πoldπθAt−βKL[πold,πθ]],但是不同问题需要不同β,同一问题中,随着训练进程,最优 β 也会变化。因此,还需要通过自适应的β来调整。
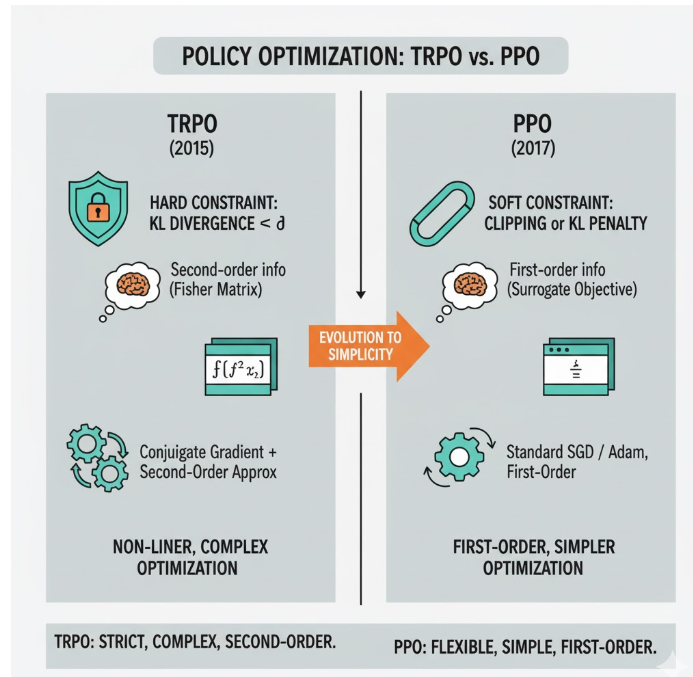
四、TRPO vs PPO
| 特性 | TRPO | PPO |
|---|---|---|
| 控制策略更新 | hard constraint:KL divergence ≤ δ | soft constraint:clipping 或 KL penalty |
| 数学形式 | 非线性约束,需要二阶信息(Fisher矩阵) | 一阶可直接在 surrogate objective 上优化 |
| 优化方法 | 共轭梯度 + 二阶近似 | 标准 SGD / Adam,一阶优化即可 |
五、PPO代码实现
理论部分掌握了,就需要开始实战演练了。这部分代码参考了 nikhilbarhate99/PPO-PyTorch (GitHub),这是一个非常清晰的实现。我们将实现一个 Actor-Critic (A2C) 架构的 PPO。
- 定义 Actor 和 critic 网络,其中
act()函数主要用于记录旧决策的action以及对应的对数概率,evaluate()函数主要用于计算新决策下旧action的对数概率。因此首先是需要通过旧决策前馈得到旧决策下的action,action_logprob以及state_val
class ActorCritic(nn.Module):def __init__(self, state_dim, action_dim, has_continuous_action_space, action_std_init):super(ActorCritic, self).__init__()self.has_continuous_action_space = has_continuous_action_spaceif has_continuous_action_space:self.action_dim = action_dimself.action_var = torch.full((action_dim,), action_std_init * action_std_init).to(device)# actorif has_continuous_action_space :self.actor = nn.Sequential(nn.Linear(state_dim, 64),nn.Tanh(),nn.Linear(64, 64),nn.Tanh(),nn.Linear(64, action_dim),nn.Tanh())else:self.actor = nn.Sequential(nn.Linear(state_dim, 64),nn.Tanh(),nn.Linear(64, 64),nn.Tanh(),nn.Linear(64, action_dim),nn.Softmax(dim=-1))# criticself.critic = nn.Sequential(nn.Linear(state_dim, 64),nn.Tanh(),nn.Linear(64, 64),nn.Tanh(),nn.Linear(64, 1))def set_action_std(self, new_action_std):if self.has_continuous_action_space:self.action_var = torch.full((self.action_dim,), new_action_std * new_action_std).to(device)else:print("--------------------------------------------------------------------------------------------")print("WARNING : Calling ActorCritic::set_action_std() on discrete action space policy")print("--------------------------------------------------------------------------------------------")def forward(self):raise NotImplementedErrordef act(self, state):if self.has_continuous_action_space:action_mean = self.actor(state)cov_mat = torch.diag(self.action_var).unsqueeze(dim=0)dist = MultivariateNormal(action_mean, cov_mat)else:action_probs = self.actor(state)dist = Categorical(action_probs)action = dist.sample()action_logprob = dist.log_prob(action)state_val = self.critic(state)return action.detach(), action_logprob.detach(), state_val.detach()def evaluate(self, state, action):if self.has_continuous_action_space:action_mean = self.actor(state)action_var = self.action_var.expand_as(action_mean)cov_mat = torch.diag_embed(action_var).to(device)dist = MultivariateNormal(action_mean, cov_mat)# For Single Action Environments.if self.action_dim == 1:action = action.reshape(-1, self.action_dim)else:action_probs = self.actor(state)dist = Categorical(action_probs)action_logprobs = dist.log_prob(action)dist_entropy = dist.entropy()state_values = self.critic(state)return action_logprobs, state_values, dist_entropy
- PPO代码
class PPO:def __init__(self, state_dim, action_dim, lr_actor, lr_critic, gamma, K_epochs, eps_clip, has_continuous_action_space, action_std_init=0.6):self.has_continuous_action_space = has_continuous_action_spaceif has_continuous_action_space:self.action_std = action_std_initself.gamma = gammaself.eps_clip = eps_clipself.K_epochs = K_epochsself.buffer = RolloutBuffer()self.policy = ActorCritic(state_dim, action_dim, has_continuous_action_space, action_std_init).to(device)self.optimizer = torch.optim.Adam([{'params': self.policy.actor.parameters(), 'lr': lr_actor},{'params': self.policy.critic.parameters(), 'lr': lr_critic}])self.policy_old = ActorCritic(state_dim, action_dim, has_continuous_action_space, action_std_init).to(device)self.policy_old.load_state_dict(self.policy.state_dict())self.MseLoss = nn.MSELoss()def set_action_std(self, new_action_std):if self.has_continuous_action_space:self.action_std = new_action_stdself.policy.set_action_std(new_action_std)self.policy_old.set_action_std(new_action_std)else:print("--------------------------------------------------------------------------------------------")print("WARNING : Calling PPO::set_action_std() on discrete action space policy")print("--------------------------------------------------------------------------------------------")def decay_action_std(self, action_std_decay_rate, min_action_std):print("--------------------------------------------------------------------------------------------")if self.has_continuous_action_space:self.action_std = self.action_std - action_std_decay_rateself.action_std = round(self.action_std, 4)if (self.action_std <= min_action_std):self.action_std = min_action_stdprint("setting actor output action_std to min_action_std : ", self.action_std)else:print("setting actor output action_std to : ", self.action_std)self.set_action_std(self.action_std)else:print("WARNING : Calling PPO::decay_action_std() on discrete action space policy")print("--------------------------------------------------------------------------------------------")def select_action(self, state):if self.has_continuous_action_space:with torch.no_grad():state = torch.FloatTensor(state).to(device)action, action_logprob, state_val = self.policy_old.act(state)self.buffer.states.append(state)self.buffer.actions.append(action)self.buffer.logprobs.append(action_logprob)self.buffer.state_values.append(state_val)return action.detach().cpu().numpy().flatten()else:with torch.no_grad():state = torch.FloatTensor(state).to(device)action, action_logprob, state_val = self.policy_old.act(state)self.buffer.states.append(state)self.buffer.actions.append(action)self.buffer.logprobs.append(action_logprob)self.buffer.state_values.append(state_val)return action.item()def update(self):# Monte Carlo estimate of returnsrewards = []discounted_reward = 0for reward, is_terminal in zip(reversed(self.buffer.rewards), reversed(self.buffer.is_terminals)):if is_terminal:discounted_reward = 0discounted_reward = reward + (self.gamma * discounted_reward)rewards.insert(0, discounted_reward)# Normalizing the rewardsrewards = torch.tensor(rewards, dtype=torch.float32).to(device)rewards = (rewards - rewards.mean()) / (rewards.std() + 1e-7)# convert list to tensorold_states = torch.squeeze(torch.stack(self.buffer.states, dim=0)).detach().to(device)old_actions = torch.squeeze(torch.stack(self.buffer.actions, dim=0)).detach().to(device)old_logprobs = torch.squeeze(torch.stack(self.buffer.logprobs, dim=0)).detach().to(device)old_state_values = torch.squeeze(torch.stack(self.buffer.state_values, dim=0)).detach().to(device)# calculate advantagesadvantages = rewards.detach() - old_state_values.detach()# Optimize policy for K epochsfor _ in range(self.K_epochs):# Evaluating old actions and valueslogprobs, state_values, dist_entropy = self.policy.evaluate(old_states, old_actions)# match state_values tensor dimensions with rewards tensorstate_values = torch.squeeze(state_values)# Finding the ratio (pi_theta / pi_theta__old)ratios = torch.exp(logprobs - old_logprobs.detach())# Finding Surrogate Loss surr1 = ratios * advantagessurr2 = torch.clamp(ratios, 1-self.eps_clip, 1+self.eps_clip) * advantages# final loss of clipped objective PPOloss = -torch.min(surr1, surr2) + 0.5 * self.MseLoss(state_values, rewards) - 0.01 * dist_entropy# take gradient stepself.optimizer.zero_grad()loss.mean().backward()self.optimizer.step()# Copy new weights into old policyself.policy_old.load_state_dict(self.policy.state_dict())# clear bufferself.buffer.clear()def save(self, checkpoint_path):torch.save(self.policy_old.state_dict(), checkpoint_path)def load(self, checkpoint_path):self.policy_old.load_state_dict(torch.load(checkpoint_path, map_location=lambda storage, loc: storage))self.policy.load_state_dict(torch.load(checkpoint_path, map_location=lambda storage, loc: storage))
六、专栏面试问题角
在学习 Agentic RL 的过程中,PPO 是面试中必考的基础。
❓ PPO 是 On-Policy 还是 Off-Policy 算法?
PPO 本质上是 On-Policy 算法,因为它使用当前策略(或上一个旧策略 \pi_{old})采样数据。但是,它通过“概率比”和“裁剪”技术,引入了 Off-Policy 的思想,允许使用同一批数据进行多步(K-Epochs)更新,极大地提高了采样效率,使其成为 On-Policy 算法中最高效的代表。
❓ PPO 中的 Actor-Critic 架构,Actor 和 Critic 必须共享参数吗?
不是必须的,但推荐共享。
共享参数(如代码实现中,共享底层的
nn.Linear(64, 64)):Critic 可以“偷听”到 Actor 的特征表示,使得 V(s_t) 的估算更准确,训练更稳定。不共享参数(两个完全独立的网络):实现更简单,但 Critic 可能需要更多数据才能学好 V(s_t)。TRPO 算法就(因为其二阶计算的限制)难以处理参数共享。
❓代码中 act() 和 evaluate() 两个函数的根本区别是什么?
act(state):由policy_old调用。它的目的是**“与环境交互并采样”。它输出一个具体的动作action** 和这个动作的logprob,用于存入 Buffer。
evaluate(state, action):由policy(新策略) 调用。它的目的是**“计算损失”。它接收 Buffer 中“旧的”state和action,然后计算“新策略”下,做出这个“旧动作”**的对数概率logprobs和熵dist_entropy,用于计算概率比ratios。
❓ 如果我把 PPO 的 K_epochs 设得非常大(比如 100),会发生什么?
这会破坏 PPO 的假设。PPO 的 LCLIPL^{CLIP}LCLIP 约束是基于 πθ和πold\pi_\theta 和\pi_{old}πθ和πold 差别不大的前提下才近似有效的。
如果 K 太大,πθ\pi_\thetaπθ 在这 100 个 epoch 中会和 πold\pi_{old}πold 差别非常大。LCLIPL^{CLIP}LCLIP 提供的“信任区域”会失效,梯度估计将不再准确,数据分布会“漂移 (Drift)”,训练很可能会崩溃。
七、总结与展望
在这一章中,我们从 Agentic RL 的需求出发,深入了 Policy-based 方法。我们理解了 PPO 是为了解决传统 Policy Gradient 采样效率低和 TRPO 计算复杂度高而诞生的。
- PPO 原理:通过概率比 rt(θ)r_t(\theta)rt(θ) 和裁剪 clip\text{clip}clip(…),在一阶优化中实现了“信任区域”,允许 On-Policy 算法进行多步更新。
- PPO 实战:我们通过 PyTorch 代码,彻底厘清了 LCLIP、LVF和S^{CLIP}、 L^{VF} 和 SCLIP、LVF和S(熵)这“三位一体”的损失函数是如何在
update()函数中实现的。
下一步展望:我们有了引擎 (PPO),但这个引擎需要“燃料”(Reward)。在 LLM 中,Reward 从哪里来?这就是我们专栏下一篇要深入的主题:RLHF 与 RM (Reward Model),即 InstructGPT 如何使用 PPO 来“对齐”人类偏好。
✍ 参考链接
- PPO 原始论文 (必读):Schulman, J., et al. (2017). Proximal Policy Optimization Algorithms. arXiv:1707.06347
- TRPO 原始论文 (选读):Schulman, J., et al. (2015). Trust Region Policy Optimization. arXiv:1502.05477
- 代码实现参考 (GitHub):nikhilbarhate99/PPO-PyTorch