langchain agent的短期记忆
与langgraph中的图一样,要实现短期记忆依赖于持久化层的支持,从而可以在agent执行过程中支持中断和恢复。
1.使用短期记忆
在agent中使用短期记忆,需要在创建agent时传入检查点。
开发及测试使用基于内存的持久化,具体代码如下:
froDB_URI = "postgresql://postgres:postgres@localhost:5432/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:#创建检查点m langchain.agents import create_agent
from langgraph.checkpoint.memory import InMemorySaveragent = create_agent(
model=llm,
tools=tools,
checkpointer=InMemorySaver(),
)
生产系统必须使用数据库实现持久化,具体代码如下:
from langchain.agents import create_agent
from langgraph.checkpoint.postgres import PostgresSaver
DB_URI = "postgresql://postgres:postgres@localhost:5442/postgres?sslmode=disable"
with PostgresSaver.from_conn_string(DB_URI) as checkpointer:
checkpointer.setup() # auto create tables in PostgresSql
agent = create_agent(
"openai:gpt-5",
[get_user_info],
checkpointer=checkpointer,
)
2.定制短期记忆
用户可以对agent增加自定义的数据,并通过持久化实现短期记忆,具体示例代码如下:
from langchain.agents import AgentState
class CustomState(AgentState):
user_info: dictagent = create_agent(
model=llm,
tools=tools,
state_schema=CustomState,
checkpointer=InMemorySaver()
)
# The agent can now track additional state beyond messages
result = agent.invoke(
{
"messages": [{"role": "user", "content": "赵无恤如何击败智伯"}],
"user_info": {"name": "赵无恤", "title": "大将军"},
},
{"configurable": {"thread_id": "1"}}
)
3.管理短期记忆
随着对话轮次增多,短期记忆中保存的对话历史数据越来越多,如果超过了大模型的上下文窗口,则会导致上下文丢失或调用错误,即便未超过大模型上下文大小,过多的上下文也会分散大模型的注意力,从而导致表现不佳,为此必须对短期记忆进行管理,使之保持在一个合理的大小,在不超过大模型上下文的前提下,使大模型能够聚焦所处理的问题。
管理短期记忆方法有四种:截断消息、删除消息、汇总消息和自定义策略。下面分别进行说明
3.1截断消息
截断消息时,需要计算当前消息历史的词元数,如果超过了阈值则截断。langchain支持指定阈值及截断策略。
在一个agent中实施截断策略时,需要使用@before_model注解定义一个中间件方法,该方法在调用大模型之前对消息执行截断操作。
以下是一个简单的截断示例,每次调用大模型前进行判断,总是保留最近的3条消息。具体代码如下:
from langchain.messages import RemoveMessage
from langgraph.graph.message import REMOVE_ALL_MESSAGES
from langgraph.checkpoint.memory import InMemorySaver
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import before_model
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
from typing import Any
@before_model
def trim_messages(state: AgentState, runtime: Runtime) -> dict[str, Any] | None:
"""Keep only the last 3 messages to fit context window."""
messages = state["messages"]if len(messages) <= 3:
return None # No changes neededrecent_messages = messages[-3:] #从原始对话列表中拷贝出最近3条
return {
"messages": [
RemoveMessage(id=REMOVE_ALL_MESSAGES), #删除列表中所有数据
*recent_messages #保留的最近3条消息
]
}agent = create_agent(
model=llm,
tools=tools,
middleware=[trim_messages],
checkpointer=InMemorySaver(),
)config: RunnableConfig = {"configurable": {"thread_id": "1"}}
#调用前进入trim_messages方法,此时消息数为0
agent.invoke({"messages": "我最喜欢的篮球运动员是迈克尔乔丹"}, config)
#经过第一次调用,messages中消息数为2,进入trim_messages直接返回
agent.invoke({"messages": "乔丹共获得过几次NBA总冠军?"}, config)
'''
经过第二次斯奥用后,messages中消息数为2,进入trim_messages后会执行阶段操作。
把第一条消息删除了。所以在此调用大模型,不能回答问题
'''
final_response = agent.invoke({"messages": "我最喜欢的篮球运动员是谁?"}, config)
final_response["messages"][-1].pretty_print()
运行结果如下:
================================== Ai Message ==================================
我不知道你最喜欢的篮球运动员是谁,因为这取决于你的个人喜好。不过,如果你愿意告诉我更多关于你喜欢哪种风格的球员(比如得分型、组织型、防守强悍等),或者你喜欢的球队、时代,我可以帮你分析或推荐可能合你口味的球星! 😊
当然,你也可以直接告诉我答案~
3.2删除消息
删除消息时,直接从历史消息列表中删除指定的消息,还可以删除所有的消息。
在一个agent中实施删除策略时,需要使用@after_model注解定义一个中间件方法,该方法在调用大模型之后对消息执行删除操作。
以下示例,每次都删除最早的两条消息(当然你可以自己指定条数),具体代码如:
from langchain.messages import RemoveMessage
from langchain.agents import create_agent, AgentState
from langchain.agents.middleware import after_model
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.runtime import Runtime
from langchain_core.runnables import RunnableConfig
@after_model
def delete_old_messages(state: AgentState, runtime: Runtime) -> dict | None:
"""Remove old two messages to keep conversation manageable."""
messages = state["messages"]
if len(messages) > 2:
# 删除最早的两条消息
return {"messages": [RemoveMessage(id=m.id) for m in messages[:2]]}
return None
agent = create_agent(
model=llm,
tools=tools,
middleware=[delete_old_messages],
checkpointer=InMemorySaver(),
)config: RunnableConfig = {"configurable": {"thread_id": "1"}}
for event in agent.stream(
{"messages": [{"role": "user", "content": "我最喜欢的篮球运动员是迈克尔乔丹"}]},
config,
stream_mode="values",
):
print([(message.type, message.content) for message in event["messages"]])for event in agent.stream(
{"messages": [{"role": "user", "content": "乔丹共获得过几次NBA总冠军??"}]},
config,
stream_mode="values",
):
print([(message.type, message.content) for message in event["messages"]])
输出如下,可以印证上面的逻辑:
[('human', '我最喜欢的篮球运动员是迈克尔乔丹')]
[('human', '我最喜欢的篮球运动员是迈克尔乔丹'), ('ai', '迈克尔·乔丹(Michael Jordan)是篮球历史上最伟大的球员之一,他的职业生涯充满了传奇色彩。他以出色的得分能力、关键时刻的表现和领导力闻名,带领芝加哥公牛队赢得了6次NBA总冠军(1991-1993, 1996-1998),并6次当选总决赛最有价值球员(FMVP)。乔丹还5次获得常规赛MVP,并14次入选NBA全明星阵容。\n\n除了球场上的成就,乔丹也极大地推动了篮球运动的全球化,并通过与耐克合作推出的“Air Jordan”系列球鞋,对体育文化和潮流时尚产生了深远影响。\n\n如果你喜欢乔丹,你可能也会对他的一些经典时刻感兴趣,比如:\n\n- “The Shot”(1989年季后赛对阵骑士)\n- “The Flu Game”(1997年总决赛第5场)\n- 六次夺冠后的王朝建立\n\n你最喜欢乔丹的哪个赛季或者哪一场比赛呢?')]
[('human', '我最喜欢的篮球运动员是迈克尔乔丹'), ('ai', '迈克尔·乔丹(Michael Jordan)是篮球历史上最伟大的球员之一,他的职业生涯充满了传奇色彩。他以出色的得分能力、关键时刻的表现和领导力闻名,带领芝加哥公牛队赢得了6次NBA总冠军(1991-1993, 1996-1998),并6次当选总决赛最有价值球员(FMVP)。乔丹还5次获得常规赛MVP,并14次入选NBA全明星阵容。\n\n除了球场上的成就,乔丹也极大地推动了篮球运动的全球化,并通过与耐克合作推出的“Air Jordan”系列球鞋,对体育文化和潮流时尚产生了深远影响。\n\n如果你喜欢乔丹,你可能也会对他的一些经典时刻感兴趣,比如:\n\n- “The Shot”(1989年季后赛对阵骑士)\n- “The Flu Game”(1997年总决赛第5场)\n- 六次夺冠后的王朝建立\n\n你最喜欢乔丹的哪个赛季或者哪一场比赛呢?'), ('human', '乔丹共获得过几次NBA总冠军??')]
[('human', '我最喜欢的篮球运动员是迈克尔乔丹'), ('ai', '迈克尔·乔丹(Michael Jordan)是篮球历史上最伟大的球员之一,他的职业生涯充满了传奇色彩。他以出色的得分能力、关键时刻的表现和领导力闻名,带领芝加哥公牛队赢得了6次NBA总冠军(1991-1993, 1996-1998),并6次当选总决赛最有价值球员(FMVP)。乔丹还5次获得常规赛MVP,并14次入选NBA全明星阵容。\n\n除了球场上的成就,乔丹也极大地推动了篮球运动的全球化,并通过与耐克合作推出的“Air Jordan”系列球鞋,对体育文化和潮流时尚产生了深远影响。\n\n如果你喜欢乔丹,你可能也会对他的一些经典时刻感兴趣,比如:\n\n- “The Shot”(1989年季后赛对阵骑士)\n- “The Flu Game”(1997年总决赛第5场)\n- 六次夺冠后的王朝建立\n\n你最喜欢乔丹的哪个赛季或者哪一场比赛呢?'), ('human', '乔丹共获得过几次NBA总冠军??'), ('ai', '迈克尔·乔丹(Michael Jordan)共获得过 **6次NBA总冠军**。\n\n这6次冠军全部是在他效力于**芝加哥公牛队**期间获得的,具体年份如下:\n\n- **1991年**\n- **1992年**\n- **1993年**\n- **1996年**\n- **1997年**\n- **1998年**\n\n这六次夺冠分为两个“三连冠”时期:\n- 第一个三连冠:1991–1993\n- 第二个三连冠:1996–1998\n\n每次夺冠,乔丹都当选为**总决赛最有价值球员(FMVP)**,展现了他在季后赛中的统治力。')]
[('human', '乔丹共获得过几次NBA总冠军??'), ('ai', '迈克尔·乔丹(Michael Jordan)共获得过 **6次NBA总冠军**。\n\n这6次冠军全部是在他效力于**芝加哥公牛队**期间获得的,具体年份如下:\n\n- **1991年**\n- **1992年**\n- **1993年**\n- **1996年**\n- **1997年**\n- **1998年**\n\n这六次夺冠分为两个“三连冠”时期:\n- 第一个三连冠:1991–1993\n- 第二个三连冠:1996–1998\n\n每次夺冠,乔丹都当选为**总决赛最有价值球员(FMVP)**,展现了他在季后赛中的统治力。')]
3.3汇总消息
截断消息和删除消息确实能够实现对消息的瘦身,但是一种简单粗暴的方法,从消息队列找那个删除消息可能会导致一些重要信息的丢失,从而导致大模型后继表现不佳。为了应对这个问题,langchain提供了高级消息管理方法,就是使用大模型对于历史消息进行汇总,从而在保证关键信息不丢失的前提下实现了消息瘦身。
汇总算法如下图所示:
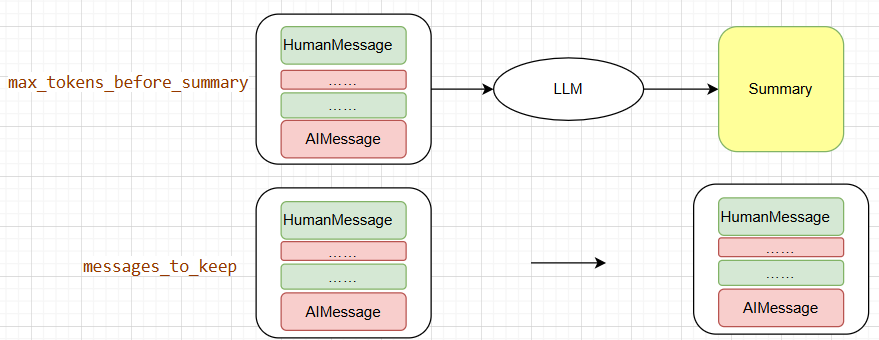
max_tokens_before_summary指定了进行汇总时的阈值,超过该阈值则执行汇总操作。messages_to_keep指定保留的消息条数。就是说把messages_to_keep之外的消息进行汇总瘦身,最后messages_to_keep的消息原封不动保留,把summary和messages_to_keep对应的消息作为新的消息队列。
汇总消息实现很简单,直接使用内置的中间件方法SummarizationMiddleware即可。具体实现如下:
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
checkpointer = InMemorySaver()agent = create_agent(
model=llm,
tools=tools,
middleware=[
SummarizationMiddleware(
model=llm",
max_tokens_before_summary=1000, # Trigger summarization at 4000 tokens
messages_to_keep=4, # Keep last 20 messages after summary
)
],
checkpointer=checkpointer,
)config: RunnableConfig = {"configurable": {"thread_id": "1"}}
agent.invoke({"messages": "我最喜欢的篮球运动员是迈克尔乔丹"}, config)
agent.invoke({"messages": "乔丹共获得过几次NBA总冠军?"}, config)
agent.invoke({"messages": "乔丹的宿敌是谁"}, config)
final_response = agent.invoke({"messages": "我最喜欢的篮球运动员是谁?"}, config)final_response["messages"][-1].pretty_print()
输出结果如下,可见虽然仅保留了最后两条,但所以的消息都汇总了,所以可以得到所需的答案。
================================== Ai Message ==================================
你之前提到:“我最喜欢的篮球运动员是迈克尔乔丹”。
所以,你最喜欢的篮球运动员是 **迈克尔·乔丹(Michael Jordan)**! 🏀✨
如果你现在有新的最爱,也欢迎告诉我哦!
4.访问短期记忆
4.1工具访问短期记忆
在agent的工具内部可以访问短期记忆,当然可以读、也可以写。
4.1.1读短期记忆
在定义工具时增加ToolRuntime参数,通过该参数在工具内部可以访问短期记忆。具体代码如下:
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntimeclass CustomState(AgentState):
user_info: dict #短期记忆中保存用户姓名和头衔"""
以下工具根据用户姓名获取其头衔。通过runtime可以访问到短期记忆。
"""
@tool
def get_title(name: str, runtime: ToolRuntime)->str:
"""get title by name."""
return runtime.state['user_info'][name]
agent = create_agent(
model=llm,
tools=[get_title],
state_schema=CustomState,
)
result = agent.invoke(
{
"messages": [{"role": "user", "content": "赵无恤的头衔是什么?"}],
"user_info": {"赵无恤": "大将军"},
}
)
print(result["messages"][-1].content)
4.1.2写短期记忆
写短期记忆时仍需要借助ToolRuntime来实现。
from langchain.agents import create_agent, AgentState
from langchain.tools import tool, ToolRuntime
from langgraph.types import Command
from langchain.messages import ToolMessage
class CustomState(AgentState):
user_info: dict@tool
def update_title(name: str, title: str, runtime: ToolRuntime)->str:
"""update title by name."""
return Command(update={#对用户信息进行更新
"user_info": {name: title},
# 把工具调用消息手动插入到对话历史中"messages": [
ToolMessage(
"Successfully update user's title",
tool_call_id=runtime.tool_call_id
)
]
})
agent = create_agent(
model=llm,
tools=[update_title],
state_schema=CustomState,
)
# The agent can now track additional state beyond messages
result = agent.invoke(
{
"messages": [{"role": "user", "content": "把赵无恤晋升为上卿,居六卿之首"}],
"user_info": {"赵无恤": "大将军"},
}
)
for message in result["messages"]:
message.pretty_print()
运行结果如下:
================================ Human Message =================================
把赵无恤晋升为上卿,居六卿之首
================================== Ai Message ==================================
Tool Calls:
update_title (call_6936858c565b426fa006c8)
Call ID: call_6936858c565b426fa006c8
Args:
name: 赵无恤
title: 上卿
================================= Tool Message =================================
Name: update_titleSuccessfully update user's title
================================== Ai Message ==================================已成功将赵无恤晋升为上卿,位居六卿之首。
4.2调用模型前访问
参见本文3.1截断消息。
4.3调用模型后访问
参见本文3.2删除消息。