(论文速读)EgoLife:走向自我中心的生活助手
论文题目:EgoLife: Towards Egocentric Life Assistant(走向自我中心的生活助手)
会议:CVPR2025
摘要:我们推出了EgoLife项目,这是一个以自我为中心的生活助手,通过人工智能可穿戴眼镜陪伴并提高个人效率。为了为这款助手奠定基础,我们进行了一项全面的数据收集研究,六名参与者在一起生活了一周,持续记录他们的日常活动——包括讨论、购物、烹饪、社交和娱乐——使用人工智能眼镜进行多模式自我中心视频捕捉。伴随着同步的第三人称视角视频参考。这一努力产生了EgoLife数据集,这是一个全面的300小时以自我为中心、人际关系、多视角和多模式的日常生活数据集,带有密集的注释。利用这个数据集,我们引入了EgoLifeQA,这是一套长期上下文、以生活为导向的问答任务,旨在通过解决实际问题(如回忆过去的相关事件、监测健康习惯和提供个性化建议),为日常生活提供有意义的帮助。
为了解决以下关键技术挑战:1)为以自我为中心的数据开发鲁棒的视听模型,2)实现身份识别,以及3)促进对大量时间信息的长上下文问题回答,我们引入了EgoBulter,这是一个由EgoGPT和EgoRAG组成的集成系统。EgoGPT是一个在以自我为中心的数据集上训练的全模态模型,在以自我为中心的视频理解上实现了最先进的性能。EgoRAG是一个基于检索的组件,支持回答超长上下文问题。我们的实验研究验证了它们的工作机制,揭示了关键因素和瓶颈,指导了未来的改进。通过发布我们的数据集、模型和基准,我们的目标是促进以自我为中心的人工智能助手的进一步研究。
项目地址:https://egolife-ai.github.io/

EgoLife——开启以自我为中心的AI生活助手新时代
想象一下,未来有一个AI助手能无缝融入你的日常生活:根据你的习惯提供个性化的饮食建议,提醒你下班后要买的东西,不仅分析你的活动,还能理解你家人的需求。这样的助手将极大提升个人和人际效率,提供有意义的生活导向辅助和可操作的见解。来自南洋理工大学、北京邮电大学等机构的研究团队在CVPR 2025上发表的论文《EgoLife: Towards Egocentric Life Assistant》,正朝着这个愿景迈出了重要一步。
为什么我们需要EgoLife?
当前的自我中心视觉研究面临着显著的局限性。尽管现有数据集如Epic-Kitchen和Ego4D支持许多有价值的任务,但它们受限于相对较短的录制时长和主要的单人视角。这些限制使得它们难以捕捉全面的习惯模式和复杂的社交互动动态。
要克服这些挑战,我们需要一个能够跨越长时间活动、整合多模态数据并融入多人视角的数据集,以反映真实生活体验的复杂性。EgoLife项目应运而生。
EgoLife数据集:前所未有的规模和深度
数据收集设计
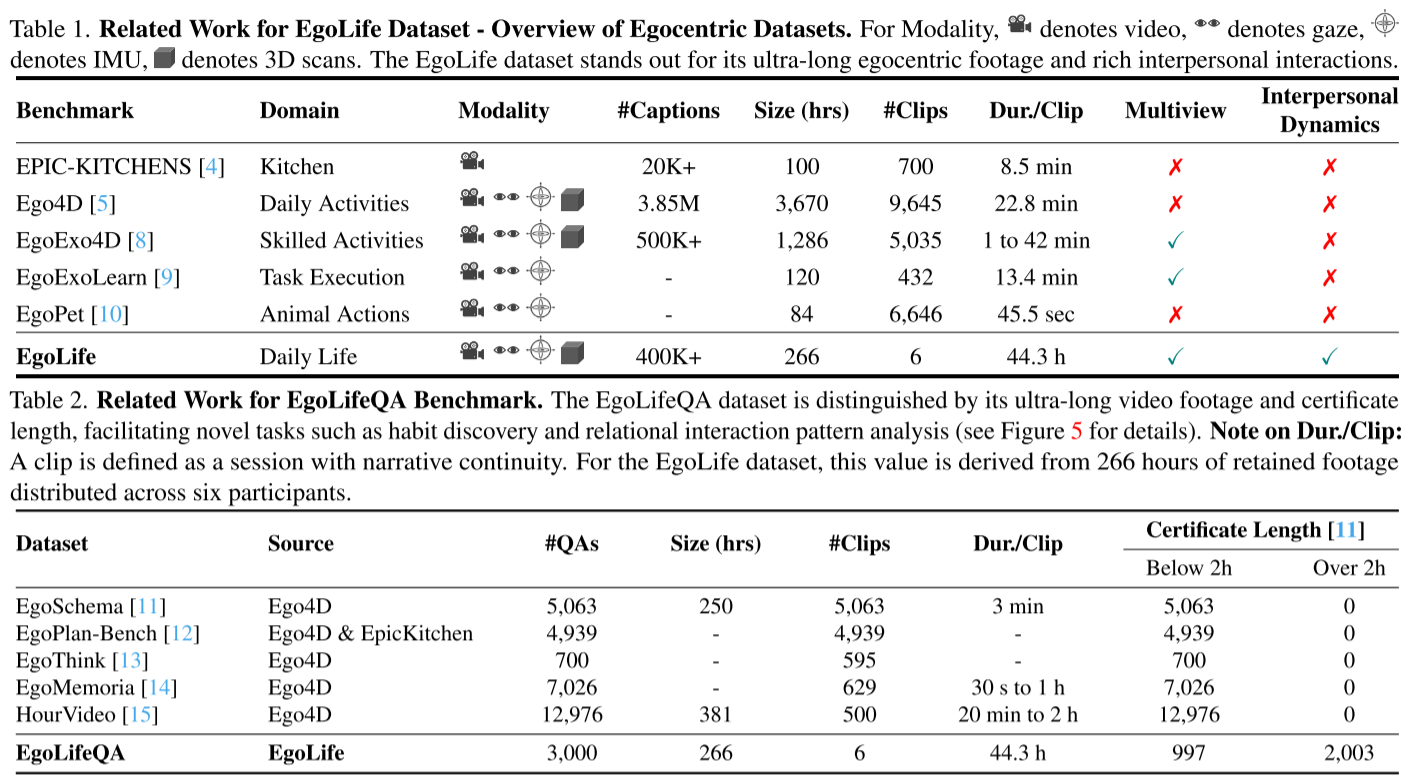
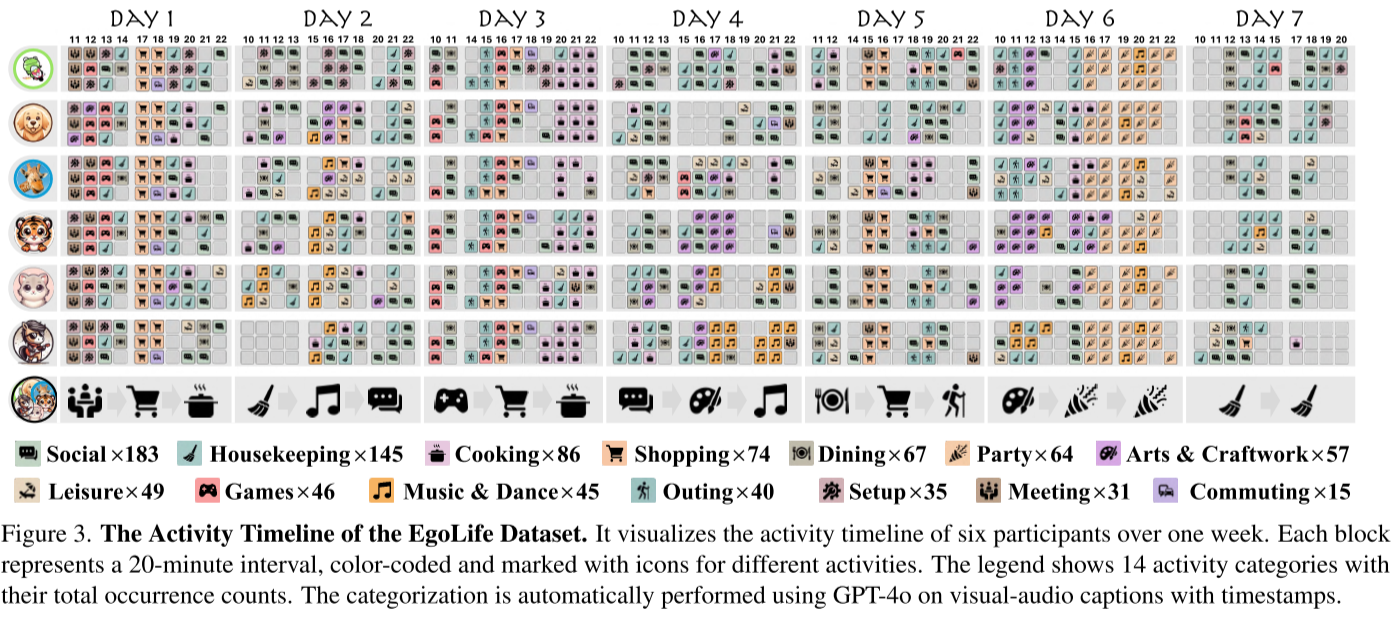
在为期一周的时间里,六名参与者共同居住在一个完全配备仪器的生活环境中,每天使用Meta Aria眼镜录制约八小时的自我中心多模态视频。这产生了EgoLife数据集,一个丰富的300小时自我中心、多模态和多视角数据集合。
多视角捕捉:
- 6名参与者佩戴Meta Aria智能眼镜
- 15个战略性放置的GoPro相机从多个角度记录参与者的活动
- 毫米波雷达提供空间和运动数据
真实的生活场景
在这一周期间,参与者被要求在倒数第二天组织一次地球日派对。为了准备,他们举行会议和讨论,排练表演(如音乐和舞蹈),练习和分享烹饪技能,并装饰房子以符合地球日主题。活动甚至延伸到房子之外,参与者去购物和观光。
密集的标注体系
数据集配备了多层次的标注:
-
转录标注:使用语音识别生成初始带时间戳的转录,然后使用开源说话人分离算法区分说话者,产生带有重叠对话的初步转录。这50小时的转录经过仔细审核以确保准确性。
-
字幕标注:
- 初始标注包括361K个简短的、字幕样式的短语,平均每个标注2.65秒
- 使用GPT-4o-mini将相关短语合并为25K个"合并字幕"
- 通过与代表性帧(以1 FPS采样)和相应转录配对,将其扩展为"视听字幕"
-
活动分类:数据集涵盖14个活动类别,包括社交互动(183次)、家务(145次)、烹饪(86次)等。
EgoLifeQA:面向生活的问答基准
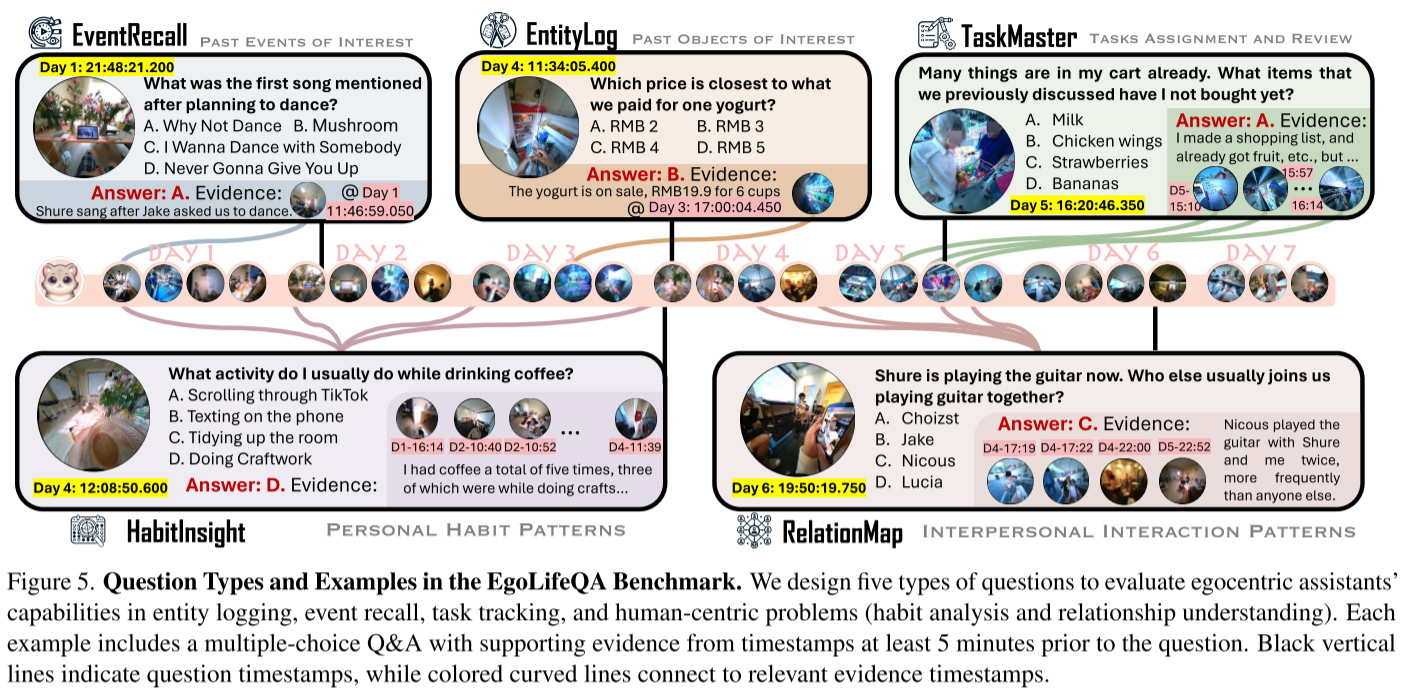
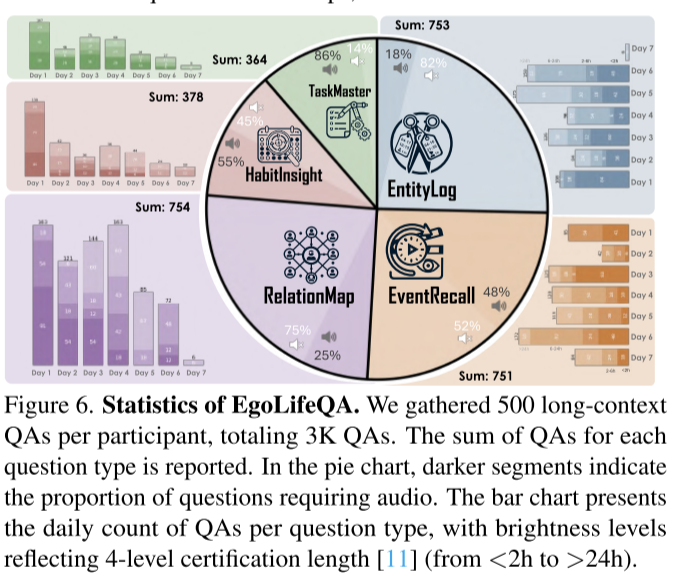
基于EgoLife数据集,研究团队引入了EgoLifeQA基准测试,包含3,000个长上下文、面向生活的问答对。这些问题旨在评估AI助手在真实生活场景中提供有意义帮助的能力。
五种问题类型
1. EntityLog(实体日志)
- 示例:我们买一杯酸奶最接近哪个价格?A. 2元 B. 3元 C. 4元 D. 5元
- 该问题类型占总数的18%需要音频信息
2. EventRecall(事件回忆)
- 示例:计划跳舞后提到的第一首歌是什么?
- 52%的问题需要音频信息
3. HabitInsight(习惯洞察)
- 示例:我通常在喝咖啡时做什么活动?
- 75%的问题需要音频信息
4. RelationMap(关系图谱)
- 示例:Shure现在正在弹吉他。还有谁通常和我们一起弹吉他?
- 55%的问题需要音频信息
5. TaskMaster(任务管理)
- 示例:我的购物车里已经有很多东西了。我之前讨论过但还没买的物品是什么?
- 86%的问题需要音频信息
认证长度分布
值得注意的是,EgoLifeQA在认证长度方面与其他基准测试有显著区别:997个问题的认证长度低于2小时,而2,003个问题超过2小时。相比之下,EgoSchema、EgoPlan-Bench、EgoThink等现有基准测试中所有问题的认证长度都低于2小时。
EgoButler:智能的自我中心生活助手系统
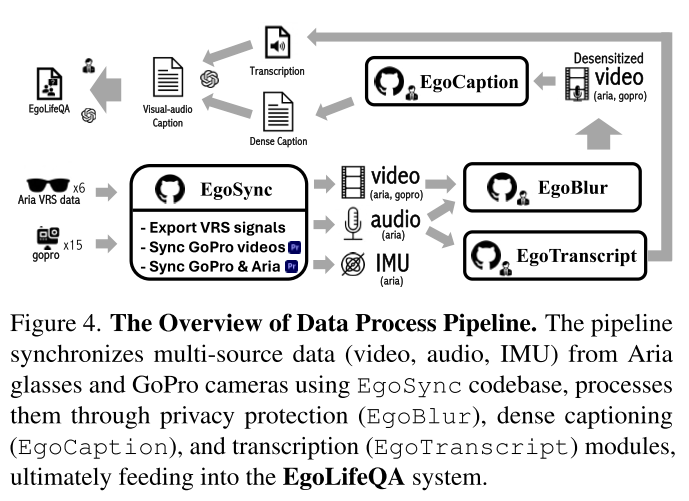
为了应对EgoLifeQA提出的挑战,研究团队开发了EgoButler系统,它由两个核心子系统组成。
System-I: EgoGPT——片段级理解
EgoGPT是一个基于LLaVA-OneVision微调的轻量级个性化视听语言模型。它在EgoButler中发挥两个主要功能:
- 连续视频字幕生成:处理每个30秒的片段,使用视觉和音频输入生成字幕
- 问答辅助:利用从EgoRAG检索的线索协助回答问题
训练数据:EgoIT-99K
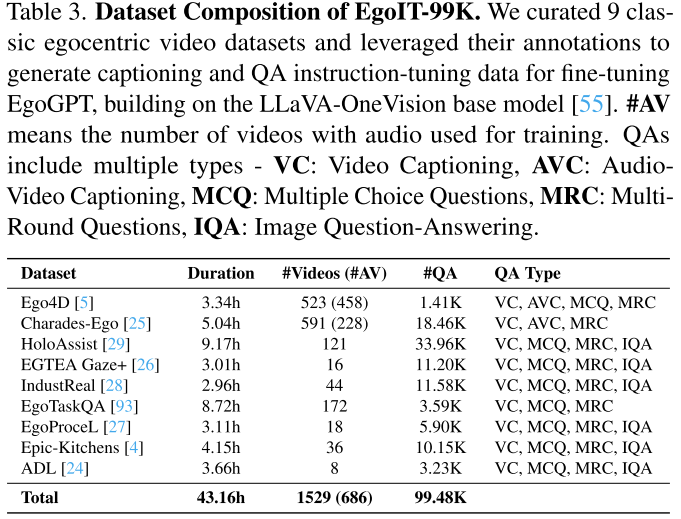
为了更好地与自我中心视频领域对齐并整合音频理解,研究团队引入了EgoIT-99K,一个多样化且具代表性的自我中心视频数据集。该数据集包含:
- 来自9个经典自我中心视频数据集的43.16小时视频
- 1,529个视频(其中686个包含音频)
- 99.48K个问答对
音频整合:
由于LLaVA-OneVision基于Qwen2构建,研究团队开发了类似Ola的音频分支,使用Whisper Large v3编码音频,并在LibriSpeech上训练音频投影模块。
个性化微调:
为了实现个性化,研究团队在EgoLife第1天的视频上微调EgoGPT,使其能够在EgoLifeQA中进行身份感知的提问。
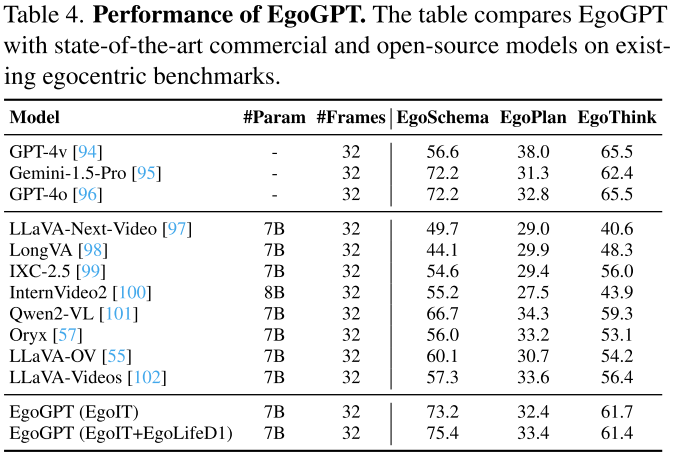
System-II: EgoRAG——长上下文问答
EgoRAG是一个检索增强生成(RAG)系统,增强记忆和查询能力,实现个性化和长期理解。它采用两阶段方法:
1. 记忆库构建
EgoRAG与EgoGPT集成,提取视频片段字幕并将其存储在结构化记忆模块中,确保高效检索带时间戳的上下文信息。字幕由EgoGPT持续生成,并由语言模型在每小时和每日级别进行摘要,形成多级记忆库以实现可扩展检索。
记忆库M由以下组成:
- ci:片段特征
- di:文本描述
- ti:带时间戳的摘要(每小时、每日)
2. 内容检索和响应生成
当提出问题时,EgoRAG通过首先检索更高级别的摘要ti并从日到小时细化搜索,来假设相关时间窗口。在选定的窗口内,使用基于相关性的评分函数执行细粒度检索。
评分函数平衡视觉和文本相关性:
si = Similarity(q, ci) + λ·Similarity(q, di)
然后选择得分最高的top-k个片段,输入到语言模型生成回答。
实验结果:突破性的性能
EgoGPT在现有基准测试上的表现

在EgoSchema基准测试上,EgoGPT(EgoIT)达到73.2的准确率,EgoGPT(EgoIT+EgoLifeD1)达到75.4。这些成绩显著优于其他最先进的模型:
| 模型 | 参数量 | EgoSchema | EgoPlan | EgoThink |
|---|---|---|---|---|
| GPT-4v | - | 56.6 | 38.0 | 65.5 |
| Gemini-1.5-Pro | - | 72.2 | 31.3 | 62.4 |
| GPT-4o | - | 72.2 | 32.8 | 65.5 |
| LLaVA-OV | 7B | 60.1 | 30.7 | 54.2 |
| Qwen2-VL | 7B | 66.7 | 34.3 | 59.3 |
| EgoGPT (EgoIT) | 7B | 73.2 | 32.4 | 61.7 |
| EgoGPT (EgoIT+EgoLifeD1) | 7B | 75.4 | 33.4 | 61.4 |
EgoLifeQA上的性能
在EgoLifeQA上,EgoGPT识别个体和有效整合全模态信息的能力使其区别于GPT-4o和Gemini-1.5-Pro等通用商业模型。
| 模型 | EntityLog | EventRecall | HabitInsight | RelationMap | TaskMaster | 平均 |
|---|---|---|---|---|---|---|
| Gemini-1.5-Pro | 36.0 | 37.3 | 45.9 | 30.4 | 34.9 | 36.9 |
| GPT-4o | 34.4 | 42.1 | 29.5 | 30.4 | 44.4 | 36.2 |
| LLaVA-OV | 36.8 | 34.9 | 31.1 | 22.4 | 28.6 | 30.8 |
| EgoGPT (EgoIT-99K) | 35.2 | 36.5 | 27.9 | 29.6 | 36.5 | 33.1 |
| EgoGPT (EgoIT-99K+D1) | 39.2 | 36.5 | 31.1 | 33.6 | 39.7 | 36.0 |
EgoRAG的巨大提升
EgoRAG的整合显著增强了视频语言模型在长上下文问答中的性能,特别是对于需要更长认证长度的问题。
不同认证长度下的性能对比:
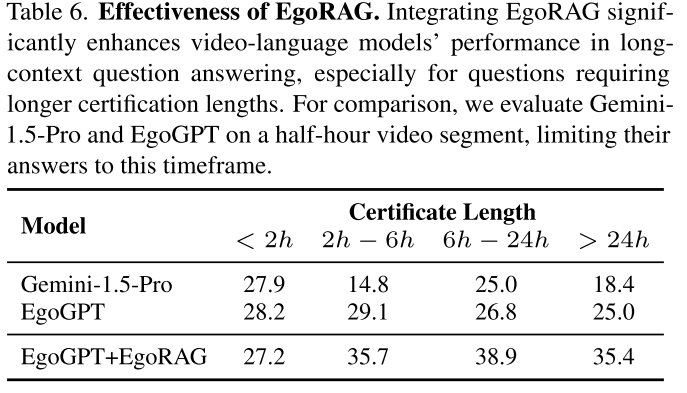
| 模型 | < 2h | 2h-6h | 6h-24h | > 24h |
|---|---|---|---|---|
| Gemini-1.5-Pro | 27.9 | 14.8 | 25.0 | 18.4 |
| EgoGPT | 28.2 | 29.1 | 26.8 | 25.0 |
| EgoGPT+EgoRAG | 27.2 | 35.7 | 38.9 | 35.4 |

对于跨越超过24小时的查询,EgoGPT+EgoRAG达到35.4分,而单独的EgoGPT和Gemini-1.5-Pro分别只有25.0和18.4分,展示了长期检索的关键作用。
消融实验的发现
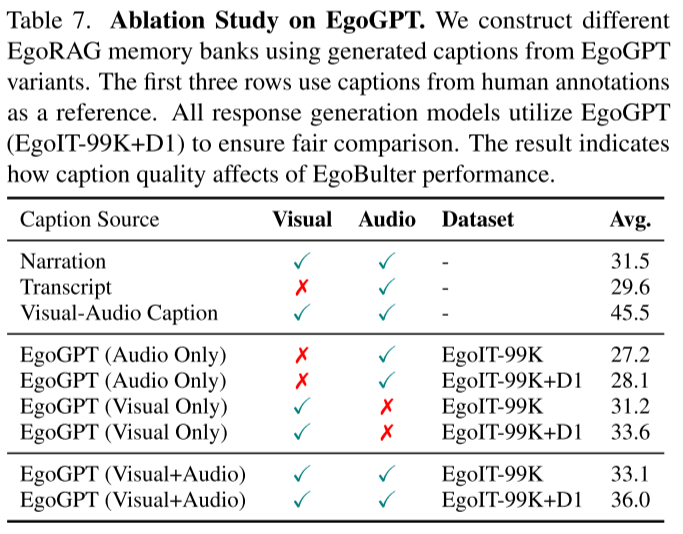
人工标注显示,人工字幕产生最高得分(45.5),强调了高质量字幕对更好检索的重要性。
不同字幕来源的性能:
| 字幕来源 | 视觉 | 音频 | 平均分 |
|---|---|---|---|
| 叙述(人工) | ✓ | ✓ | 31.5 |
| 转录(人工) | ✗ | ✓ | 29.6 |
| 视听字幕(人工) | ✓ | ✓ | 45.5 |
| EgoGPT(仅音频) | ✗ | ✓ | 27.2 |
| EgoGPT(仅视觉) | ✓ | ✗ | 31.2 |
| EgoGPT(视觉+音频,EgoIT-99K) | ✓ | ✓ | 33.1 |
| EgoGPT(视觉+音频,EgoIT-99K+D1) | ✓ | ✓ | 36.0 |
仅使用音频的模型表现最弱,而仅使用视觉的模型表现更好,表明音频本身不足以应对EgoLifeQA。结合视觉和音频输入实现了最佳性能,添加EgoLife第1天字幕后进一步改善。
定性分析:优势与挑战
研究团队通过定性实验揭示了系统的优势和局限性:
EgoGPT的优势:
- 在个性化和上下文相关字幕方面表现出色
- 相比通用模型,在自我中心视频上产生更少的幻觉
当前的局限性:
- 在语音理解方面存在困难,特别是情绪和笑声
- 对第1天数据过拟合,导致个体误识别
- EgoRAG检索长上下文证据,但缺乏多步推理能力,当关键信息缺失时会失败
未来的改进应该聚焦于语音理解、个性化和高级检索。
研究意义与未来展望
EgoLife项目通过提供全面的数据集、基准测试和系统,填补了自我中心AI研究中的关键空白。这些资源为面向生活的AI的未来研究奠定了坚实基础。
未来计划:
- 扩展数据集以覆盖更广泛的语言、地点和活动
- 开发更复杂的模型,推动AI理解和增强日常生活能力的边界
- 最终目标是接近AI眼镜无缝支持和丰富人类体验的世界
结语
EgoLife项目代表了自我中心AI助手研究的重要里程碑。通过300小时的多模态、多视角数据,创新的EgoLifeQA基准测试,以及强大的EgoButler系统,研究团队为开发真正理解和辅助我们日常生活的AI助手铺平了道路。
虽然仍有许多挑战需要克服——从改进语音理解到增强个性化能力——但这项研究展示了AI技术在成为我们生活中不可或缺伙伴方面的巨大潜力。随着技术的不断进步,我们可以期待一个AI助手不仅能记住我们的习惯,理解我们的需求,还能预测我们的愿望,真正增强我们的日常体验的未来。