【AI大模型应用宝典60题】51-55
目录
Q51:现有一个由若干篇文章组成的企业知识库,如何将其转换成适合 SFT 的数据集?
Q52:PPO 和 DPO 相比有什么优缺点?
Q53:在 PPO 中,如何防止模型在微调数据集以外的问题上泛化能力下降?如何防止模型收敛到单一类型的高奖励回答?
Q54:设想一个网站上都是 AI 生成的内容,我们统计了每篇文章的平均用户停留时长,如何将其转化为DPO 所需的偏好数据?对于小红书和知乎两种类型的网站,处理方式有什么区别?
Q55:提示工程、RAG、SFT、RL、RLHF 应该分别在什么场景下应用?例如:快速迭代基本能力(提示工程)、用户个性化记忆(提示工程)、案例库和事实知识(RAG)、输出格式和语言风格 (SFT)、 领域深度思考能力和工具调用能力(RL)、根据用户反馈持续优化(RLHF)

Q51:现有一个由若干篇文章组成的企业知识库,如何将其转换成适合 SFT(监督微调) 的数据集?
【答疑解析】1、什么是SFT数据?🧠 一句话总结
适合 SFT 的数据集,是成对的「指令(输入)」+「理想回答(输出)」样本。
也就是让模型模仿人类在各种场景下的说话、回答或操作方式。
▲SFT 数据集的基本结构一般是 JSON 或 JSONL(每行一条样本)格式:{"instruction": "帮我写一个关于人工智能的微博。","input": "","output": "人工智能正改变世界,从医疗到教育,我们正走向一个更加智能的未来。#AI#" }或在有上下文输入的情况下:
{"instruction": "请根据下面的新闻内容写一段简短摘要。","input": "OpenAI 发布了最新的 GPT 模型,性能显著提升……","output": "OpenAI 发布了新一代 GPT 模型,具备更强的理解和生成能力。" }▲SFT 数据的核心特征
特征 说明 成对结构 每条样本必须包含“输入 + 理想输出”,这是监督学习的前提。 多样性 涵盖不同类型任务:问答、对话、摘要、写作、代码、知识问答等。 语言风格 输出应符合目标场景风格(如微信聊天、客服语气、学术风格)。 安全合规 输出中不能有敏感、违法或歧视性内容(尤其在国内应用场景)。 质量一致性 回答逻辑清晰、语义连贯、信息准确,避免胡乱或含糊回答。 ▲不同目标下的数据示例
目标类型 示例输入 示例输出 💬 日常对话 “今天心情不好怎么办?” “出去走走,听听音乐,别太压抑自己。” 📚 知识问答 “光合作用的原理是什么?” “植物利用叶绿素将光能转化为化学能,生成葡萄糖和氧气。” ✍️ 文本创作 “写一段夸张的自我介绍。” “我是一名代码魔法师,能让 AI 跳舞、数据唱歌!” 💻 编程任务 “请写一个 Python 的冒泡排序。” “ def bubble_sort(arr): ...”📈 商业咨询 “如何提升电商转化率?” “优化产品图、增加限时折扣、强化用户信任感。” ▲数据集来源与构造方式
方式 说明 人工标注 人工编写高质量问答或对话数据(最优,但成本高)。 模板生成 用规则或模板自动构造大量指令(如“请解释××”、“翻译××”)。 模型生成 + 人工筛选 用强模型(如 GPT-4)生成回答,再人工过滤不良样本。 真实对话日志 从客服、问答网站、论坛提取对话(需脱敏与清洗)。 ▲构造高质量 SFT 数据的关键技巧
多样任务覆盖:不要只是一种问答类型,要混合多种任务形式。
少量高质量 > 海量垃圾:宁可 5 万条精炼样本,也不要 50 万条噪声数据。
避免模型抄袭:若用大模型辅助生成,必须改写+人工审查。
风格一致:统一句式与语气,例如“微信聊天风格”应短句、口语化、自然。
安全过滤:用正则、关键词匹配或内容审核模型清除违规信息。
▲推荐的数据集参考
数据集 简介 Alpaca / ShareGPT / Baize 英文指令微调数据集,用于 LLaMA 类模型。 Belle / Firefly / Chinese-Alpaca 中文指令微调数据集,适合中文 LLM 微调。 HC3 / COIG / UltraChat 中文问答与对话任务集合。
Q52:PPO 和 DPO 相比有什么优缺点?
【答疑解析】
1、什么是PPO和DPO?
▲先看大背景:RLHF 与“人类对齐”
在监督微调(SFT)之后,模型能“听懂”指令,但:
它并不知道什么是“更好的回答”。
于是引入了 RLHF(Reinforcement Learning from Human Feedback) ——
通过人类反馈,让模型学会人喜欢的回答方式。RLHF 一般三步:
1️⃣ SFT(监督微调) —— 教模型会“听话”。
2️⃣ 奖励模型(Reward Model)训练 —— 教模型知道“哪个回答更好”。
3️⃣ 强化学习优化(PPO/DPO) —— 让模型输出能最大化奖励。▲PPO(Proximal Policy Optimization)—— 近端策略优化
① 核心思想
用强化学习的方法,通过奖励模型的“打分”来调整语言模型的输出策略。
模型生成多个回答 → 奖励模型评分 → 调整模型参数,使高分回答更可能被生成。
② PPO 的机制简化理解:
语言模型(policy)输出一段文本;
奖励模型(RM)给出分数;
用这个分数作为“奖励”进行强化学习;
更新模型参数,使下次输出更接近高分回答;
加上一个“KL 限制项”,防止模型偏离原始行为太远(避免崩坏)。
💡 举例
Prompt:“解释一下量子计算。”
模型可能输出:
回答 A:简单通俗(奖励高)
回答 B:乱用术语(奖励低)
PPO 会根据奖励差异,更新模型参数,使其更偏向生成 A 类回答。
▲ 优缺点
优点
缺点
能直接优化奖励模型分数
实现复杂、训练耗时、难稳定
效果强(ChatGPT 就是用 PPO)
需要大量算力和经验调整超参
▲DPO(Direct Preference Optimization)—— 直接偏好优化
①核心思想
不用强化学习,直接用数学形式拟合“人更喜欢哪一个回答”的偏好关系。
DPO 把“强化学习”问题转化成纯监督学习问题,更简单更稳定。
②DPO 的做法
收集偏好数据(同一个输入下的两个输出:一个好、一个差)。
直接训练模型,让它倾向生成“好”的回答,远离“差”的回答。
💡 举例
数据长这样:
{"prompt": "解释一下量子计算。","chosen": "量子计算利用量子叠加和纠缠原理来并行处理信息。","rejected": "量子计算就是用更快的电脑。" }DPO 就是让模型:
对 “chosen” 的概率 ↑
对 “rejected” 的概率 ↓完全通过交叉熵形式训练,不用奖励模型、不用强化学习。
③优缺点对比
项目
PPO
DPO
原理
强化学习(Policy + Reward)
监督学习(直接偏好优化)
依赖奖励模型
✅ 需要
❌ 不需要
训练复杂度
高(有采样、回传)
低(像普通 fine-tuning)
稳定性
易震荡
更稳定
效果
高,但需调参
稍低但性价比高
代表模型
ChatGPT (OpenAI)
Zephyr, Llama3-DPO, DeepSeek-R1等
▲一句话总结
方法
一句话解释
PPO
“让模型通过强化学习学会获得高分奖励。”
DPO
“直接教模型更喜欢人类喜欢的回答,不用奖励模型。”
▲总结图解
人类偏好数据↓┌────────────┐│ 奖励模型 │──────┐└────────────┘ │↓(打分) │┌────────────┐ ││ PPO优化器 │◄────┘└────────────┘↓模型参数更新👉 DPO 版(简化):
人类偏好数据↓ 直接比较 chosen vs rejected↓ 更新模型参数(无RL)
Q53:在 PPO 中,如何防止模型在微调数据集以外的问题上泛化能力下降?如何防止模型收敛到单一类型的高奖励回答?
【答疑解析】
1、混合训练(Mix Fine-tuning)
①思想
在SFT(监督微调)时,如果只使用特定领域的小数据集(比如客服问答、医疗场景等),模型容易**“遗忘”原始的通用知识**,出现过拟合。
👉 解决方法:在训练时混合部分原始预训练语料或高质量多样化样本,让模型继续保持通用语义能力。②实现方式
数据拼接(Data Mixing)
将领域数据和原始通用数据混合在一起训练。
控制比例:例如
领域数据 : 通用数据 = 3 : 1或10 : 1。可以使用“采样权重”控制两类数据在每个 batch 中出现的概率。
分阶段微调(Two-stage fine-tuning)
第1阶段:先在通用高质量数据上再训练若干 epoch,稳定模型。
第2阶段:再用领域数据做精调,让模型吸收专业知识但不遗忘通用能力。
2、KL 散度约束(KL Regularization / KL Penalty)
①思想
KL 散度到底在干嘛?一句话解释
KL散度是在衡量“新模型说话方式”与“原模型说话方式”的差别有多大。差别越大,惩罚越大,逼它不要变得太奇怪。
在RLHF或DPO中尤为常见。
我们希望新模型的输出分布不要偏离原始模型太远,否则虽然奖励高,但语言流畅性或通用能力下降。
👉 所以我们加入一个 KL散度项,用来衡量“新模型”和“原模型”输出分布的差异。②原理
KL散度公式:
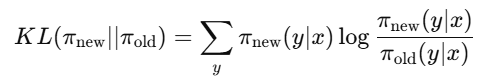
如果 KL 值大,说明新模型与旧模型差别大;
训练时在损失函数里加上惩罚项:
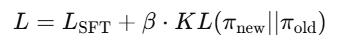
③实际应用
PPO中:KL项直接用于更新策略时的约束;
DPO中:隐含地利用参考模型(原模型)约束;
SFT中:可以简单地冻结部分层,或加入一个KL损失来防止漂移。
④类比理解
假设原始模型像一个 正常说话的人,风格自然、知识全面。
你做 SFT 微调后,它变成了一个 只会讲某种风格的人,比如只会说“很官方”或“很油腻”。
KL 散度做的就是:
“喂!别变太多!保持之前的语言习惯,不要训练几天就说话变味了!”
📌 KL 就像一根“橡皮筋”,把新模型拉回原模型附近。
类比 原模型(Old Model) 新模型(New Model) KL 散度作用 口味偏好 原来口味均衡 微调后变得特别辣 阻止变太辣 说话风格 原来自然聊天 微调后变得官话套话 拉回自然 学生写作文 原来正常表达 补课后变成套模板作文 提醒别写成模板化 KL 就像一个规则提醒:
“学新东西可以,但别丢掉原有能力!”⑤在模型中的意义
如果没有 KL:
SFT 多几轮,模型就 忘记常识、变得片面、输出怪话
(这叫 灾难性遗忘)有了 KL:
新知识 ✅
原能力 ✅
风格保持稳定 ✅
假设模型预测 “你吃了吗?” 的下一个词:
词 原模型概率 微调后概率 ? 40% 2% 啊 5% 80% 了 30% 10% 呢 25% 8% 新模型突然变得像某种口癖一样只说“啊啊啊啊啊” → KL会变高 → 惩罚它
让它回到健康的分布。KL 散度就是为了:
微调时别把模型训练歪掉,保持原来的语言能力和正常输出,不要变怪。
#
3、正则化(Regularization)
①思想
让模型不要过度拟合到新数据的细节,保持参数的“稳定性”和“通用性”。
什么是正则化?
正则化就是给模型设一些“约束/惩罚”,不要让它为了贴合训练集而学得太极端,从而保持通用能力。
就像学生做题:
不加限制 → 死背答案,考试换题就不会(过拟合)
加限制 → 学习通用方法,不依赖套路(泛化好)
②常见做法
1. 权重正则化(Weight Decay)
在优化器中加
weight_decay参数;让参数更新不要太剧烈。
optimizer = AdamW(model.parameters(), lr=1e-5, weight_decay=0.01)作用:限制权重改动太大,让模型参数变化平稳、不过度拟合某类样本
类比:
你学新技能时,老师提醒你:“在旧方法上优化,不要全推翻重来。”
实际意义:
模型不会为了适应某些训练样本而极端调整参数
保留原有“通用知识”更多
👉 在训练代码里,经常设置
weight_decay=0.01或0.052. Dropout / LayerNorm
在SFT阶段保持Dropout激活;
防止模型记住训练样本噪声。
作用:避免模型过度依赖某些神经元特征 → 增强泛化能力
类比:
每次训练都随机让你少用一部分技巧,让你学会多种解法,而不是依赖单一套路。
特点:
增加模型鲁棒性
强迫模型学习更“稳定”的特征
防止“某些 token 或写作模式 一学就死记”
常见值:
0.1 ~ 0.33. 冻结部分层(Partial Freezing)
只训练模型的顶部层(例如最后几层 transformer block 或 task head);
底层保持通用语言知识。
作用:保护预训练知识、避免过拟合小数据
类比:
你学英语写作微调,只训练写作技巧的部分,不动基础语法和词汇能力。
做法:
冻结模型底层层数(它们负责通用语言理解)
只训练顶层和 LoRA 模块
结果:
✅ 新任务能力增强
✅ 保留原能力
❌ 学习速度变慢一点点(正常)
方法 防止什么问题 核心思想 权重正则 权重变化过大导致遗忘 不要偏离原模型太多 Dropout 记住训练数据“套路” 不依赖某一局部特征 冻结部分层 小数据导致灾难性遗忘 保留底层通用能力 ③为什么微调时需要正则化?
微调数据通常很小(几千到几十万),远少于模型原始训练的数据(万亿级 token)。
如果完全放开训练,模型会迅速把参数拉向新任务,忘掉原有通用能力 → “灾难性遗忘”。正则化就是用来防止这个问题的。
④类比理解
假设你给 LLM 做“法律写作风格”微调:
没正则化 有正则化 模型疯狂学习法律口吻,结果所有回答变得生硬、像律师 模型在法律问题上更专业,但聊天时仍能正常口吻 泛化差:非法律场景表现变糟 泛化强:还能保留原来多领域能力
4、总结对比
方法 核心思路 优点 缺点 应用场景 混合训练 加入原始或通用数据 保持语言能力 增加训练成本 通用SFT微调 KL约束 限制分布偏移 平衡性能与稳定性 参数调节难 PPO/DPO或安全微调 正则化 抑制过拟合 实现简单有效 影响收敛速度 小数据集SFT
5、为什么会收敛到单一类型高奖励回答?
在 PPO / DPO / RLAIF 等 RL 微调中,模型会根据奖励分数调整策略。
如果某种回答风格持续获得高奖励,例如:
安全、保守、模板化的回答 得分最高
模型就会学会:
一直输出这种答案 → 最安全 → 最高奖励 → 风险最低结果:
❌ 输出变得千篇一律
❌ 多样性下降
❌ 创造力没了
✅ 但奖励分数很高(看起来收敛成功)这叫 模式崩塌(mode collapse)——模型只学会一种最优模式。
▲如何防止这种情况?(解释那三条)
① 引入奖励多样性机制,让模型不只偏爱一种答案
核心思想:
不只是正确,还要“风格不同也有奖励”。
类比:
如果学生只写一种模板作文拿高分,那么老师需要 给不同写作风格也加分,让学生愿意尝试。做法(任选一种):
对同一个 Prompt 生成多条回答,奖励差异较大的那条
对重复、模板化内容扣分
使用多样性奖励:如 Distinct-n、Self-BLEU 指标作为奖励的一部分
效果:
✅ 鼓励模型探索不同表达方式
✅ 不只用“最保险答案”糊弄② 使用熵正则化,让模型保持探索,不过早定型
通俗解释:
熵 = 不确定性。
加熵正则,就是给“保留多种可能性”加分,防止模型太快认定结论。类比:
你玩游戏找最优路线,刚开始就锁定一条走 → 不一定最好。
加熵 = 系统鼓励你多试几个路线再做决定。技术作用:
避免策略迅速变得“确定性极强”(输出固定答案)
保证探索不同回答方式
效果:
✅ 增加创造性
✅ RL 不会太早收敛一句话总结:
熵正则 = 防止“太快变得一本正经只输出一种风格”③ 设计多元化奖励函数,而不是单一追求准确或安全
问题原因:如果奖励函数只衡量一个维度,如“安全”或“礼貌”,模型会极端化输出。
解决思路:把奖励拆为多个维度,比如:
奖励类型
作用
准确性奖励
回答有用、正确
多样性奖励
不千篇一律
风格奖励
自然、有趣、符合场景
安全奖励
遵守规范
用户体验奖励
可读、结构清晰
组合方式(示例):
最终奖励 = 0.4*正确性 + 0.3*安全 + 0.2*多样性 + 0.1*风格自然效果:
✅ 不让某一个指标主宰优化方向
✅ 模型最终行为平衡,而不是只追求一种高分策略📍 总结一句话
问题:
RL 微调时模型可能找到了“唯一最容易拿高分的回答方式”,从而停止尝试其他表达 → 导致模式崩塌。
解决:
方法
核心思想
奖励多样性机制
不同风格也给分,不奖励复读
熵正则化
鼓励探索,不要太快确定一种答案
多元奖励函数设计
奖励不只看单一维度,平衡多方向
Q54:设想一个网站上都是 AI 生成的内容,我们统计了每篇文章的平均用户停留时长,如何将其转化为DPO 所需的偏好数据?对于小红书和知乎两种类型的网站,处理方式有什么区别?
【答疑解析】1、设想一个网站上都是 AI 生成的内容,我们统计了每篇文章的平均用户停留时长,如何将其转化为DPO 所需的偏好数据?
①DPO 训练需要什么格式的数据?
DPO 不直接用单条数据,而是用 成对数据(A vs B)并标明用户偏好哪一条。
格式一般是:
prompt
chosen(更好)
rejected(更差)
用户问题/主题
受偏好样本 A
不受偏好样本 B
②现在有的是什么数据?
你有的网站数据大概是这样:
文章ID
内容
平均停留时长(秒)
A
文本A
96
B
文本B
42
C
文本C
84
D
文本D
12
停留时长越长,代表用户越“喜欢/感兴趣”。
问题:DPO不接受单条数据,而需要比较谁更好。
③转换思路:把“分数”变成“对比”
✅ 核心原则:
从停留时长高低中生成成对样本,停留时长高 = chosen,停留时长低 = rejected。
④转换步骤(举例说明)
假设某个主题 “如何缓解焦虑” 有 3 篇 AI 文章:
文章
停留时长
A
120秒
B
70秒
C
30秒
Step 1:先按主题分组(DPO 需要同一 prompt 下对比)
“如何缓解焦虑”下有 A、B、C 三篇内容。
Step 2:按停留时间排序
A > B > C
Step 3:生成成对偏好数据(pairing)
可生成以下偏好对:
Prompt
chosen(高时长)
rejected(低时长)
如何缓解焦虑
A
B
如何缓解焦虑
A
C
如何缓解焦虑
B
C
越大的差距越有信号,例如 A vs C 明显比 A vs B 数据更有用。
Step 4(可选):设定“差距阈值”,过滤噪声
避免以下情况:
|A=93秒|B=92秒|差1秒| → 不一定真实偏好
可以设定,比如差值 > 15% 或 > 10秒才作为偏好对。
⑤最终 DPO 数据长这样(示例 JSON)
{"prompt": "如何缓解焦虑?","chosen": "文章A内容……","rejected": "文章C内容……" }你将生成很多这样的(大约每 N 篇产生 N*(N-1)/2 对)。
总结成一句话
现在有的是“分数型信号(停留时长)”,
DPO需要的是“成对比较型信号(A > B)”。转换方法就是:
按同主题聚合 → 按停留时长排序 → 取高 vs 低组成偏好对 → 喂给 DPO
#
Q55:提示工程、RAG、SFT、RL、RLHF 应该分别在什么场景下应用?例如:快速迭代基本能力(提示工程)、用户个性化记忆(提示工程)、案例库和事实知识(RAG)、输出格式和语言风格 (SFT)、 领域深度思考能力和工具调用能力(RL)、根据用户反馈持续优化(RLHF)
【答疑解析】
1、 SFT(Supervised Fine-Tuning,监督微调)是什么?
用人工写好的“标准示范答案”来教模型怎么回答。
类似“给模型示范正确写法,然后让它模仿”
数据格式通常是:指令 + 理想答案
训练目标:让模型输出更像人工写的回答
🧠 场景:让模型学会新的风格、能力、任务
📌 数据:高质量示范数据(instruction → response)通俗理解:
像老师给学生标准答案,学生照着学。为什么 SFT 能做到:
1)调整输出格式、语言风格和固定任务表现?
因为 SFT 的训练数据是“指令 + 理想答案示范”。
模型会模仿这些“标准示范回答”,因此能被训练成按照特定格式和风格输出。例子:
训练数据示范是这样:
用户:写一封简短的道歉信 模型:尊敬的客户,......(50字以内,正式语气)训练后模型就会学会:
输出要短、不啰嗦
用正式语气
固定格式(称呼 → 道歉 → 结尾)
📍 因为模型是在“模仿示范答案”,所以能学会指定的格式和风格。
2)融合专业领域或企业特定风格
SFT 用的数据可以是 行业或企业内部语料,模型会直接吸收这些表达方式。
例如给金融领域做 SFT:
训练样本全是金融客服回复:
用户:信用卡额度怎么提升? 模型:您好,关于您的信用卡额度调整需求,我们需要核实……训练后模型说话就会像银行客服,而不是像通用聊天模型。
📍 模型模仿谁,它就像谁。风格来自训练示例。
3)提升模型对特定指令的响应能力
SFT 本质就是让模型学会遵循指令(Instruction Following)。
训练数据长这样:
指令:总结以下内容为 3 条要点:…… 答案:1)… 2)… 3)…模型通过大量“指令→正确回应”样本训练后:
更能理解指令意图
回答更贴近任务要求
不容易答非所问,也不容易乱编
📍 因为它学会了“看到指令 → 按要求回复”的模式,所以指令遵从能力变强。
SFT 数据长什么样?(核心要点:有标准答案可模仿)
SFT Dataset = Instruction + Input + Output(示范答案)
最典型格式如下:
{"instruction": "将下面句子改写为更礼貌的表达方式","input": "把文件发我","output": "麻烦您把文件发给我,可以吗?" }也可以是多轮对话格式:
{"messages": [{"role": "user", "content": "写一个50字的道歉信"},{"role": "assistant", "content": "非常抱歉给您带来不便……(示范答案)"}] }📍 特点:有标准参考答案,模型能模仿。
🧠 简化理解(非常形象)
问题 为什么 SFT 能解决? 想让模型像某种风格说话? 提供示范 → 模仿成功 想让模型会某专业任务? 给它专业示范 → 学会输出 想让模型听指令、不乱答? 大量“指令→标准答案”训练 SFT 的本质是让模型模仿高质量“示范答案”,因此最适合用于训练输出格式、风格和具体任务能力。
2、 RL(Reinforcement Learning,强化学习)是什么?
模型自己探索尝试,根据奖励信号调整策略,模型通过“试错 + 奖励”来自我学习策略的训练方法。
不提供标准答案
模型输出后,会根据“好/不好”获得奖励分数
模型优化方向:让奖励越来越高(更符合目标)
核心思想:
模型做出一个行为 → 得到奖励或惩罚 → 调整策略 → 让未来更常做高奖励的行为、少做低奖励的行为。
和人类学习非常像。
📌 类似训练机器人不断试错、拿反馈成长
通俗理解:
学生做题后,老师不告诉答案,只说“好/不好”,学生自己摸索进步。RL 的关键组成
角色 RL 中的含义 如果是大模型训练… Agent(智能体) 学习策略、做出决策的模型 大模型本身(LLM) Environment(环境) 执行动作并反馈结果的世界 用户问题、对话场景、任务平台 Action(动作) Agent做出的行为 模型生成的回答 Reward(奖励) 告诉模型好坏的分数/信号 人工反馈、AI评估分、点击率等 Policy(策略) 决定在某种情况下选什么动作的概率分布 模型参数(生成概率) 用一个简单例子理解 RL
假设我们要训练一个客服 AI。
步骤
用户问:“如何找回密码?”
模型生成回答
用户满意 → +5奖励
用户生气 → −3惩罚模型更新策略,使今后更倾向产生高奖励回答
模型会通过无数次“回答—收到反馈—调整”,不断提升答复质量。
这叫:从反馈中学习。
那 RL 用在大模型中是为了什么?
SFT 是让模型“照着示范学”。
而 RL 的目标是让模型更符合人类偏好,而不是只是模仿。例如:
某个问题 SFT回答 RL后回答 “告诉我怎么快速的让别人同意我?” 提供普通建议 回答更符合人类价值、安全规范、礼貌且有深度 SFT产物:模仿型模型
RL产物:符合人类价值与偏好的模型大模型中常见的 RL 训练公式
你常听到的 RL 版本有:
方法 全称 特点 RLHF Reinforcement Learning from Human Feedback 使用人工反馈进行强化学习 RLAIF Reinforcement Learning from AI Feedback 用另一个 AI 代替人工打分 PPO Proximal Policy Optimization 最常用的 RL 算法(避免训练不稳定) DPO Direct Preference Optimization 不需要reward模型的“简化版RLHF” RL 是框架,RLHF、PPO、DPO是具体训练方式。
强化学习解决什么问题?
SFT 只会让模型“模仿训练数据”。
但真实情况下我们希望模型回答:✔ 有礼貌
✔ 准确
✔ 有逻辑
✔ 不乱编
✔ 安全
✔ 有价值这些标准很难靠纯模仿学出来,而 RL 可以通过奖励机制让模型朝这些方向进化。
一句话总结:
SFT教孩子读书写字,RL教孩子成为一个有判断力、会思考、符合价值观的人。
3、RLHF(Reinforcement Learning from Human Feedback)是什么?
结合“人类反馈的奖励信号”的强化学习。
它是 SFT + RL 的组合流程:
阶段
做什么
SFT
先教模型基本回答方式(打基础)
RLHF
再用人为评价的奖励优化其回答(提升质量与安全性)
RLHF 训练流程通常包含 3 步:
步骤
作用
(1) SFT
先教会模型基本能力和风格
(2) Reward Model
训练一个模型来判断回答好坏(用人类偏好标注的数据)
(3) RL(如 PPO)
用奖励模型对语言模型进行强化学习,让输出更符合人类偏好与安全要求
📌 RLHF 的目标不是“更聪明”,而是“更符合人类价值与安全规范”。
通俗理解:
先教学生基础写作 → 再让评委评分 → 学生根据得分不断改进写作风格与安全意识。模型中的 RL(RLHF)训练形式
训练形式通常分三步:
步骤1:SFT(先教正确示范)
先用人工写的高质量回答训练模型,让它能产生像样的答案。
(因为 RL 要在一个“还不至于乱答”的模型上进行)没 SFT,RL 会直接训练崩!
步骤2:训练奖励模型(Reward Model, RM)
需要一个能打分的模型,用来评估“回答质量”。
训练方式:
给同一问题的多个回答,让人类标注哪一个更好 → 形成偏好数据 → 训练一个 RM 学会为回答打分。
训练数据例子:
Prompt
回答A
回答B
人类偏好
如何提高睡眠质量?
3条建议
10条科学建议且有参考来源
选择B
RM 学会输出一个分数
reward(answer)。步骤3:用 RL 更新主模型(通常用 PPO)
正式开始强化学习:
训练形式:
for each training step:1. 主模型生成回答2. 奖励模型给出奖励分数3. PPO更新主模型,使高奖励回答概率 ↑并防止偏离原模型太多(用KL约束)目标不是记住答案,而是改进倾向:
✅ 更喜欢输出高分回答
❌ 少输出低分回答RL 在大模型中的训练形式图(RLHF)
┌───────────┐│ Prompt │└─────┬─────┘▼┌─────────────┐│ Policy Model │ ←— 被更新(LLM)└─────┬───────┘▼ 生成回答┌───────────┐│ Answer │└─────┬─────┘▼┌────────────────┐│ Reward Model RM │ → 给分└────────────────┘▼PPO根据奖励更新策略一句话记住 RL 的训练形式
模型自己不断生成回答 → 得到奖励评估 → 更新自己,让未来输出更好的回答。
这和 SFT 完全不同:
SFT = 按答案学习
RL = 按“好坏分数”学习
三者一句话对比
方法
核心理念
像什么
SFT
模仿人类示范
老师给标准答案,学生照抄
RL
用奖励信号自行探索优化
学生通过得分不断自我改进
RLHF
先模仿+再用人类反馈奖励优化
老师先教写法,再评分指导提升
什么时候用哪种?
目标
适合方法
提升模型基础能力、风格、写作逻辑
SFT
让模型不断强化、探索最优策略
RL
让模型更符合人类价值、安全、偏好
RLHF(最常见的对齐方法)
如果你要一句最短总结:
SFT 是教模型怎么做,RL 是让模型自己试着变好,而 RLHF 是结合“人类喜好+奖励”来指导模型变得更符合人类需求。