从复杂到原子:通过知识感知的双重组写和推理提升增强生成能力

摘要
检索增强生成(RAG)系统近期的进展通过整合外部知识检索显著增强了大型语言模型(LLMs)的能力。然而,仅依赖检索往往不足以挖掘深度专业知识以及执行解决领域特定复杂问题所需的逻辑推理。为了应对这些挑战,我们提出了一种方法,旨在以原子方式提取、理解和利用专业知识,同时构建连贯的理由。我们方法的核心在于四个关键组件:一个知识原子化器,用于从原始数据中提取原子标签;一个查询提议器,用于生成后续问题以促进原始询问;一个原子检索器,基于原子知识对齐定位知识;一个原子选择器,根据检索到的信息确定要查询的原子标签和块对。通过这种方法,我们实施了一种知识感知的任务分解策略,该策略迭代地构建与初始问题和获取的知识一致的理由。我们进行了全面的实验,以证明我们的方法在各种基准测试中的有效性,特别是那些需要多跳推理步骤的基准测试。性能提升高达+10.1(20。相较于次优方法,4%的优势凸显了该方法在复杂、知识密集型应用中的潜力。该代码可在https://github.com/microsoft/PIKE-RAG上公开获取。
核心速览
研究背景
研究问题:这篇文章要解决的问题是如何在复杂的专业领域中,通过增强生成模型(RAG)系统来提取和利用专业知识,并进行逻辑推理,以解决领域特定的复杂问题。
研究难点:该问题的研究难点包括:现有RAG系统在处理领域特定复杂任务时表现不佳,尤其是在需要多步推理的情况下;依赖纯文本检索的方法难以有效捕捉领域特定表达中的相关性;现有的问题分解方法未考虑可用知识,导致次级问题生成不理想、检索和推理失败。
相关工作:该问题的研究相关工作有:RAG系统通过外部知识检索来增强大型语言模型(LLMs)的能力;现有的RAG方法在预检索、检索和后检索过程中进行了改进,包括查询优化、多粒度分块、混合检索和重排;多跳问答(MHQA)任务需要从多个来源综合信息和进行推理。
研究方法
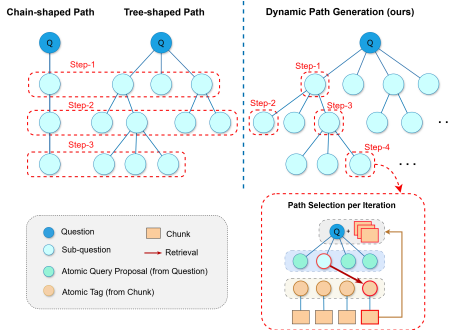
这篇论文提出了一个名为KAR3-RAG的新框架,用于解决复杂多跳问答问题。具体来说,
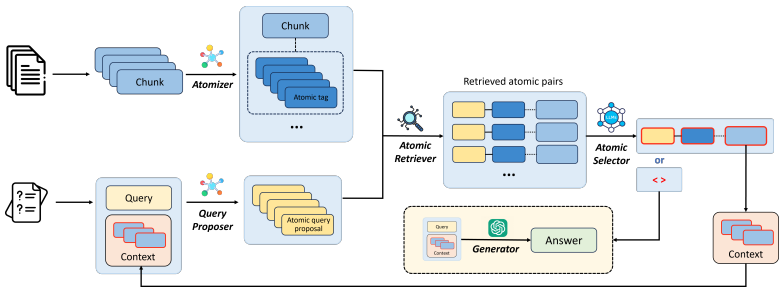
知识原子化:首先,使用知识原子化器将原始数据分块并提取原子标签,构建原子知识库。原子标签被表示为可以由给定块回答的相关查询,从而涵盖块的多方面知识,便于有效检索。
查询提出:其次,使用查询提出器生成基于上下文演变的原子查询提案,用于检索相关的原子标签。
原子检索:然后,使用原子检索器根据原子知识对齐识别和检索相关知识。
原子选择:最后,使用原子选择器根据检索到的信息确定最有用的原子标签对,并将其对应的原始块添加到上下文中。这个过程迭代进行,直到无法检索到合适的原子标签或达到最大迭代次数。
该方法的核心在于通过知识感知的双重重写和推理机制,实现问题的逐步分解和知识的逐步收集。具体流程如下:
实验设计
为了验证所提出方法的有效性,实验设计包括以下几个方面:
数据集:实验使用了多个多跳问答数据集,包括HotpotQA、2WikiMultiHopQA和MuSiQue。每个数据集随机抽取500个问答对,并从所有抽样的问答对中编译上下文段落,形成一个更复杂的检索场景。
模型:实验中使用了GPT-4和Llama-3.1-70B-Instruct两种模型进行评估。对于迭代次数N,设置为5。
参数配置:原子检索器的初始参数设置为k=4和δ=0.5。详细的超参数列表见附录A.3。
结果与分析
主要结果:在HotpotQA、2Wiki和MuSiQue数据集上,KAR3方法在所有数据集上均表现出色。与第二好的方法相比,准确率分别提高了约1.4%(1.6%)、2.2%(2.8%)和7.0%(12.6%)。
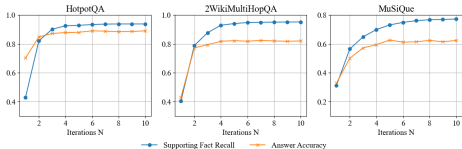
消融研究:通过消融实验评估了各个组件的贡献。结果表明,替换知识原子化器、查询提出器、原子检索器和原子选择器会导致准确率下降高达15.1%、16.6%、15.3%和16.2%。
限制讨论:实验还表明,KAR3依赖于所使用的LLMs的推理能力,可能需要更多迭代来完全捕捉必要的信息。此外,KAR3在使用开源模型Llama 3时表现出显著的性能提升,但相比某些方法,其token消耗更高。
总体结论
本文提出了一种先进的RAG系统,通过知识感知的双重重写和推理能力,显著提高了在专业数据集中的知识提取和理由构建。广泛的实验结果表明,该方法在处理复杂多跳问答任务时具有显著的有效性。未来的工作包括通过上下文学习提高系统的熟练度,并通过自适应选择示例来改进查询提出器。
论文评价
优点与创新
提出了一个知识感知的RAG框架,将检索到的知识纳入问题分解中,实现了推理路径的迭代探索。
引入了一种原子知识对齐方法,通过双向写作紧密耦合查询分解与检索,显著提高了检索效率。
进行了全面的实验和消融研究,验证了该方法在多个基准数据集上的优越性能,最高提升了20.4%。
设计了一个动态交互的问题重写和知识检索机制,使系统能够在每次迭代中自适应地细化查询和检索到的上下文。
通过原子标签的使用,实现了多粒度的问题分解和从文本块中提取内在知识,提高了检索的精度和推理的连贯性。
不足与反思
需要额外的迭代来提取复杂问题的关键信息,特别是当问题复杂性增加时,可能需要更多的迭代。
该方法依赖于所使用的LLM的推理能力,进一步的迭代可能需要更复杂的推理来完全捕捉必要的信息。
与某些方法相比,KAR3在令牌消耗上较高,特别是在使用专有模型如GPT-4时,可能会增加成本。
未来工作包括通过上下文学习来提高系统的熟练度,以及开发能够结合样本问题的反馈的知识感知原子化器,从而更好地理解最有益的原子知识类型。
关键问题及回答
问题1:KAR3-RAG框架中的知识原子化器是如何工作的?它如何帮助改进检索效率?
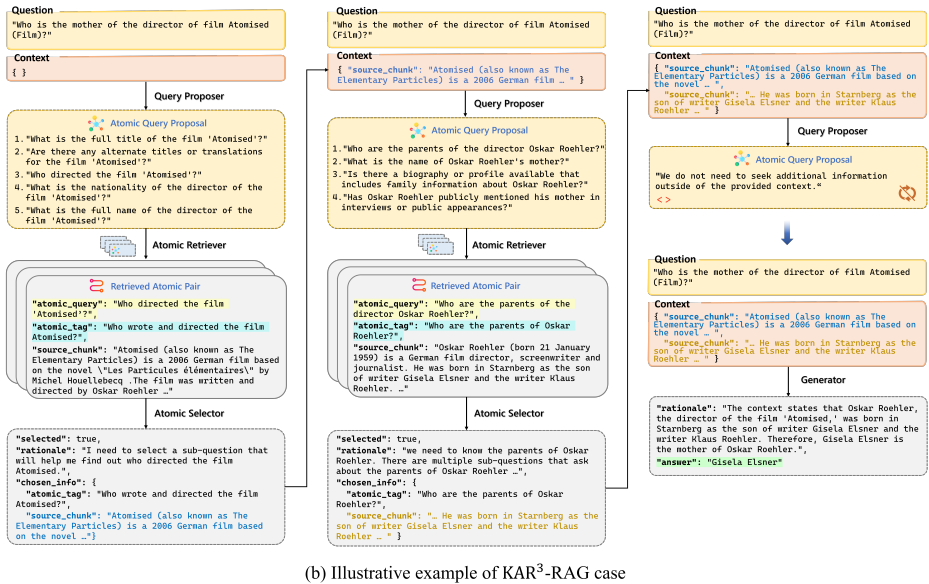
知识原子化器是KAR3-RAG框架的核心组件之一,其工作原理是将原始数据分块并提取原子标签,构建原子知识库。具体步骤如下:
分块:将原始文本数据分割成多个文档块(chunks)。
生成原子标签:对每个文档块,使用大型语言模型(LLM)生成多个相关的原子问题(atomic questions),这些问题可以回答该块中的特定知识点。
存储原子标签:将这些原子问题与相应的文档块一起存储,形成一个原子知识库。
这种方法的优点在于:
细化检索单元:通过将文档块分解为多个原子标签,可以更细粒度地进行知识检索,从而提高检索的准确性和效率。
增强语义对齐:原子标签作为文档块的语义表示,有助于更好地捕捉文档块中的专业知识,使得后续的检索和推理更加精准。
通过这些改进,KAR3-RAG框架能够更有效地从知识库中检索相关信息,提升整体系统的性能。
问题2:KAR3-RAG框架中的迭代推理机制是如何设计的?它在处理复杂多跳问答任务时有何优势?
KAR3-RAG框架采用迭代推理机制来处理复杂的多跳问答任务。具体设计如下:
初始化:将原始问题和初始上下文(通常是空的)提供给系统。
生成原子查询提案:在每次迭代中,查询提出器基于当前上下文和原始问题生成多个原子查询提案。
检索相关知识:原子检索器根据生成的原子查询提案从知识库中检索相关的原子标签对。
选择有用标签:原子选择器根据检索到的原子标签对选择最有用的一个,并将其对应的文档块添加到上下文中。
迭代更新:将新选定的文档块与原始问题合并,形成新的上下文,重复上述过程,直到无法检索到合适的原子标签或达到最大迭代次数。
迭代推理机制的优势在于:
逐步分解问题:通过多次迭代,系统能够逐步分解复杂问题,逐步收集相关信息,从而实现更准确的推理。
动态调整:每次迭代都会更新上下文,系统能够根据最新的知识和上下文动态调整查询和推理策略,提高整体性能。
减少错误积累:通过逐步推理和验证,系统能够在每一步修正可能的错误,避免错误信息的累积和传播。
这种设计使得KAR3-RAG框架在处理复杂的多跳问答任务时表现出色,特别是在需要多步推理和跨多个知识源整合信息的任务中。
问题3:KAR3-RAG框架在实验中表现如何?与其他方法相比有哪些优势?
KAR3-RAG框架在多个多跳问答数据集上进行了实验,包括HotpotQA、2WikiMultiHopQA和MuSiQue。实验结果表明:
显著的性能提升:与第二好的方法相比,KAR3-RAG框架在HotpotQA、2Wiki和MuSiQue数据集上的准确率分别提高了约1.4%(1.6%)、2.2%(2.8%)和7.0%(12.6%)。
稳健性:KAR3-RAG框架在不同模型(如GPT-4和Llama 3.1-70B-Instruct)上均表现出色,显示出其稳健性和适应性。
组件贡献:通过消融实验评估了各个组件(知识原子化器、查询提出器、原子检索器和原子选择器)的贡献,结果表明替换这些组件会导致准确率显著下降,验证了每个组件的重要性。
与其他方法相比,KAR3-RAG框架的优势包括:
知识感知的任务分解:通过引入原子标签和任务分解机制,KAR3-RAG框架能够更好地利用可用知识,逐步推理和解决问题。
动态查询生成:框架能够生成多个原子查询提案,增加了检索和推理的灵活性和准确性。
高效的检索策略:通过原子标签的引入,KAR3-RAG框架能够更精确地检索相关知识,减少了不必要的检索和推理步骤。
这些优势使得KAR3-RAG框架在处理复杂的多跳问答任务时表现出色,具有较高的实用价值和应用前景。