【论文精读/Survey】高效扩散模型:从原理到实践的全面解析
标题:Efficient Diffusion Models: A Comprehensive Survey from Principles to Practices
作者:Zhiyuan Ma, Yuzhu Zhang, Guoli Jia, Liangliang Zhao, Yichao Ma, Mingjie Ma, Gaofeng Liu, Kaiyan Zhang, Jianjun Li, Bowen Zhou
单位:1Tsinghua University(清华大学), 2HUST(华中科技大学), 3SJTU(上海交通大学), 4Shanghai AI Lab(上海人工智能实验室)
发表:TPAMI 2024
论文链接:https://arxiv.org/pdf/2410.11795
代码链接:https://github.com/ponyzym/Efficient-Diffusion-Models-Survey
关键词:Efficient Diffusion Models, Diffusion Model Principles, Efficient Architecture, Efficient Training, Fast Inference, Model Deployment, Generative AI
***关注一下吧,一起探索更多前沿内容...***
扩散模型(Diffusion Models, DMs)作为近年来生成式 AI 领域的 “明星模型”,凭借扎实的理论基础和卓越的生成能力,已在图像合成、视频生成、分子设计等多个领域实现突破。

然而,其高计算复杂度、长采样耗时等问题,限制了在低资源场景的落地。如果你和我一样,在实际用扩散模型时被 “训练慢、采样久、部署难” 折磨过,那这篇《Efficient Diffusion Models》绝对会有很大帮助。这篇来自清华、华科等团队的综述,不是空谈理论,而是把 “如何让扩散模型更快、更省资源” 的每一步都拆得明明白白。论文发表在TPAMI上,充分经过了同行的审阅。
一、先搞懂:为什么要做 “高效扩散模型”?
在聊技术前,得先明白我们的痛点到底在哪。扩散模型这几年确实猛,从 Stable Diffusion 到 Sora,生成质量没话说,但实际用起来全是坑:
- 采样慢:传统 DDPM 要 1000 步才能出一张图,就算是优化后的模型,默认也得 50 步,实时应用根本扛不住;
- 训练贵:SDXL 参数量 2.6B,训一次要好几块 A100,小团队根本玩不起;
- 部署难:手机端跑不动,云端多用户并发时延迟能飙到几十秒;
- 泛化差:改个任务(比如从图生图转视频生成),要么重训模型,要么加一堆额外模块,灵活性太低。
这篇论文的核心就是解决这些问题。它没搞虚的,直接用 “效率” 串起整个领域,从理论原理到落地应用,整理出了一个完整的技术框架(图 2)。而且作者还搞了个 GitHub 仓库实时更最新论文,真心良心()。
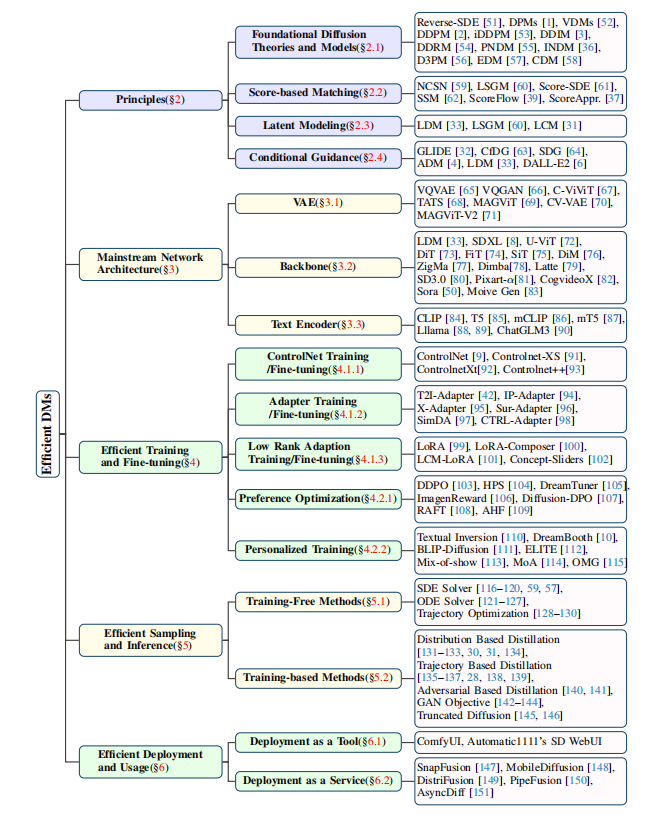
二、扩散模型的底层原理:高效优化的根基
要做高效优化,得先懂扩散模型的 “骨架”。论文第 2 章把最核心的理论讲透了,这部分是后面所有优化的基础,必须吃透。
2.1 扩散模型的数学本质:两个对称过程
扩散模型的核心就是 “前向加噪” 和 “反向去噪”,论文分别从离散和连续两个角度讲,其实本质是一回事,只是数学工具不同。
2.1.1 离散扩散(DDPM 那套)
-
前向加噪:从真实图片
开始,每一步按固定规则加一点高斯噪声,直到
变成纯噪声(服从
)。关键公式是这个条件分布:
,这里
,
是提前设好的 “噪声强度”(一般从 0.0001 线性增到 0.02),保证加噪过程平稳。更实用的是直接算
和
,
是
到
的乘积,意思是 “
步后还保留的原始信息比例”,越往后
-
反向去噪:模型要学的就是从
,然后用这个噪声算
的分布:
,这里
是均值(由噪声预测网络算出来),
可以固定(比如用
-
训练目标:本质是最小化 “变分下界(VLB)”,论文把它拆成三部分,实际训练时简化成 “预测噪声的 MSE 损失”:
,就是让模型预测的噪声
和真实加进去的噪声
尽量接近,简单直接。
2.1.2 连续扩散(Score-SDE 那套)
离散模型步长多了计算麻烦,连续模型用随机微分方程(SDE)把加噪 / 去噪过程写成连续函数,更灵活。
- 前向 SDE:
,
是布朗运动(随机项),
和
是漂移和扩散系数;
- 反向 ODE:去噪过程可以看成解一个 “概率流 ODE”(PF-ODE),不用随机项,更稳定:
,这里
是 “分数函数”(可以理解为 “数据分布的梯度方向”),由模型
为什么要提连续模型?因为后面很多快速采样方法(比如 DDIM、DPM-Solver)都是从连续视角推导的,把几百步采样压缩到十几步甚至几步。
2.2 分数匹配:让模型学会 “找方向”
分数函数 是连续扩散的核心,它表示 “从当前点往数据分布中心走的方向”。但这个函数没法直接算,所以用 “分数匹配” 来估计。
核心思想:给一堆数据样本,训练一个网络 去近似
,损失函数是 “分数匹配损失”:
,简单说,就是让模型预测的 “方向” 和真实的 “噪声方向”(
)相反,这样去噪时才能往正确方向走。
2.3 Latent 建模:把扩散从像素空间 “降维”
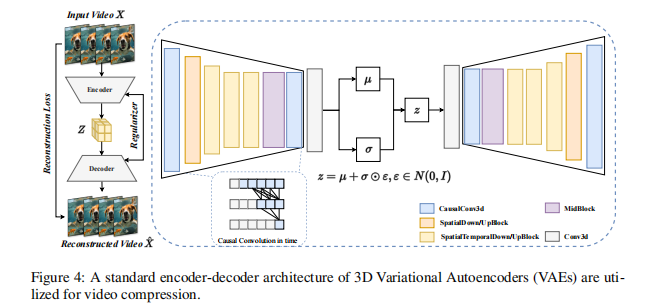
这是高效扩散的关键一步!传统模型在 RGB 像素空间(比如 512x512x3)做扩散,计算量爆炸。Latent 扩散(LDM)的思路是:先用 VAE 把图片压缩到低维 latent 空间(比如 64x64x4),再在这个小空间里做扩散,最后用 VAE 解码回像素。
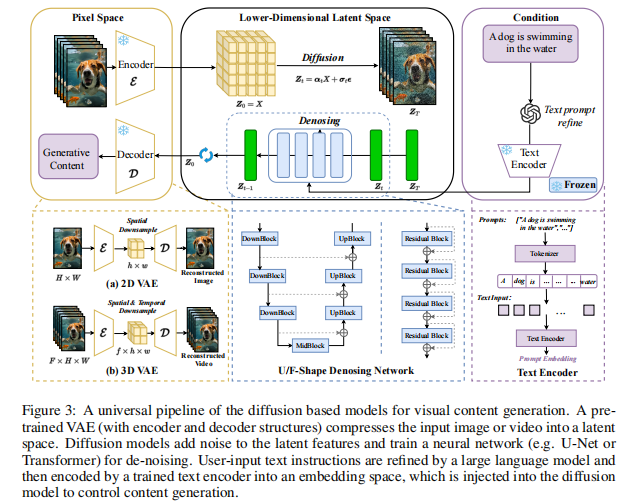
论文里给了具体流程(图 3):
- VAE 压缩:输入图片
(H×W×3),经 encoder 得到 latent
(h×w×d),缩放因子
(比如 512→64),维度直接降 64 倍;
- Latent 扩散:在
空间做加噪 / 去噪,模型还是预测噪声,但输入输出都是 latent;
- 解码重建:扩散后的
。
关键是 VAE 的参数在扩散训练时是 “冻结” 的,只训扩散模型,省了大量计算。现在主流模型(SD、SDXL)全是这套架构,没有例外。
2.4 条件引导:让扩散 “听话”
光能生成图还不够,得让模型按文本、深度图等条件生成。论文里讲了几种核心方法:
2.4.1 文本引导(Classifier-Free Guidance)
这是 Stable Diffusion 用的方法,公式很直观:
是文本嵌入(比如 CLIP 编码的),
是 “空文本”(全零向量);
是引导权重(默认 7.5),越大文本对生成的影响越强,但太大会出 artifacts。
原理是:同时训 “有文本条件” 和 “无文本条件” 的噪声预测,推理时用两者的差值放大文本信号,既保证生成质量,又不用额外训分类器。
2.4.2 结构引导(ControlNet)
比如用边缘图、深度图控制生成内容,ControlNet 的做法很巧妙(图 8):
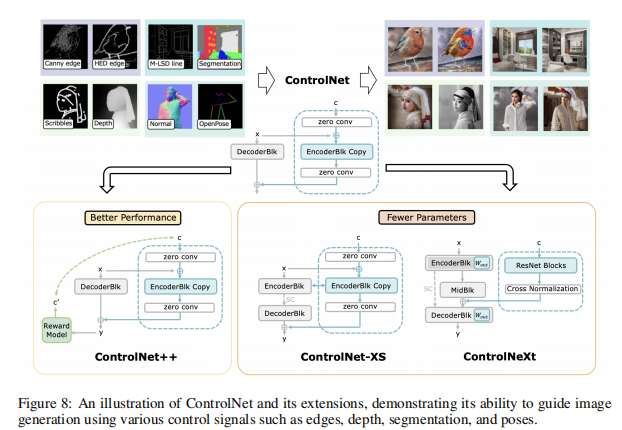
- 把预训练好的 U-Net 拆成 “冻结部分(
)” 和 “可训练副本(
)”;
- 在副本的每一层加入控制信号(比如边缘特征),用 “零卷积” 初始化副本参数,保证初始时和冻结部分输出一致;
- 训练时只更副本参数,既保留预训练模型的生成能力,又能让控制信号生效。
后来的 ControlNet-XS、ControlNeXt 都是在这个基础上减参(比如用轻量卷积)、加归一化,让模型更小、训得更快。
三、高效架构:从 U-Net 到 Mamba,选对骨架很重要
扩散模型的 “backbone” 直接决定效率,论文第 3 章对比了当前主流架构,每个都有明确的适用场景,不是盲目堆参。
3.1 VAE:Latent 空间的 “压缩器”
再补一句,VAE 是 Latent 扩散的基础,论文里对比了不同 VAE 的性能(表 2),关键看两个指标:
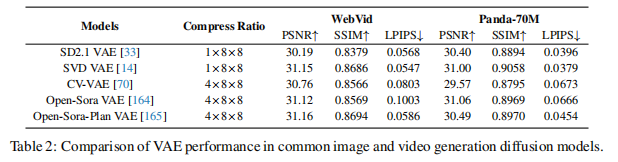
- 压缩比:比如 1×8×8 表示 H/W 各缩 8 倍,通道数可能增,总体维度降很多;
- 重建质量:用 PSNR(越高越好)、LPIPS(越低越好)衡量,比如 SVD VAE 比 SD2.1 VAE 重建质量更高。
视频生成里常用 “3D VAE”(图 4),但直接训 3D VAE 成本太高,所以很多模型(比如 Open-Sora)用 “2D+3D 混合结构”,先对空间降维,再处理时间维度,平衡效率和质量。
3.2 去噪网络 backbone:三大流派
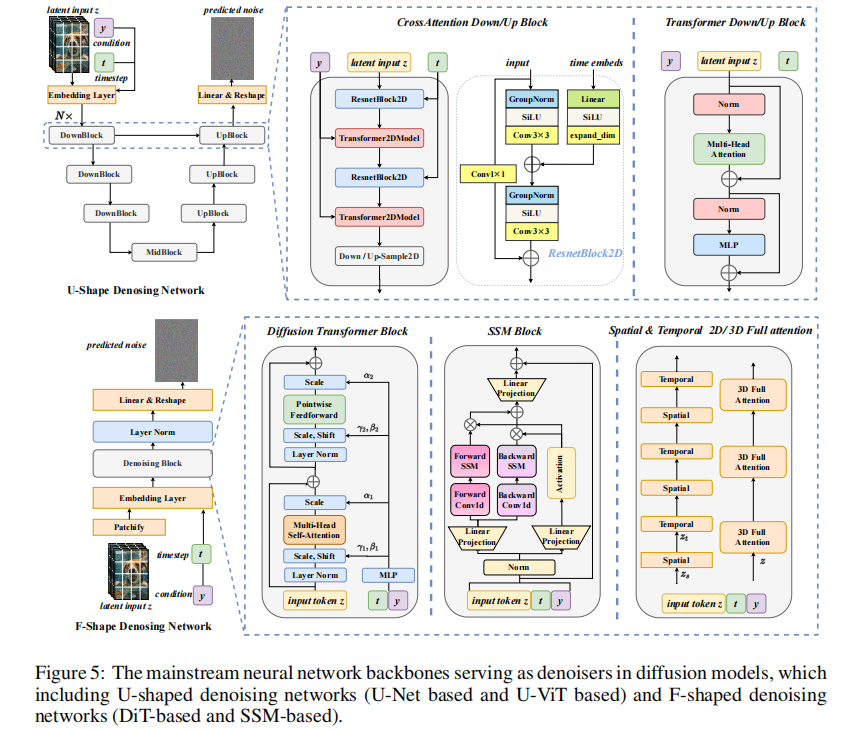
3.2.1 U-Net 系(传统派)
DDPM 最早用的就是 U-Net,核心是 “编码器下采样(提特征)+ 解码器上采样(恢复分辨率)+ 跳连(传细节)”。
- 优点:空间建模能力强,适合小分辨率(比如 256x256);
- 缺点:参数量大,高分辨率(1024x1024)和视频生成时扛不住。
后来的优化方向:
- 加注意力模块(比如 SD 在 U-Net 中间层加交叉注意力,结合文本嵌入);
- 加宽 / 加深网络(比如 ADM 把 U-Net 做宽,性能超过 GAN);
- 3D 化(比如 VDM 加 3D 卷积,适配视频生成)。
3.2.2 Transformer 系(DiT 为代表)
Transformer 擅长建模长距离依赖,这对高分辨率生成很重要。论文里重点讲了 DiT(Diffusion Transformer):
- 做法:把 latent 特征切成 patch,用 ViT 结构代替 U-Net,每一层是 “注意力 + MLP”,没有卷积;
- 优点:扩展性强,参数量能轻松涨到几十亿(比如 Sora 用的就是类似架构),高分辨率生成质量比 U-Net 好;
- 缺点:注意力是
复杂度,
大了(比如 1024x1024 的 patch 数)计算量爆炸。
优化方案:
- U-ViT:把 U 型结构和 Transformer 结合,下采样减少 patch 数,缓解计算压力;
- PixArt-α:用 T5 编码文本,通过交叉注意力注入条件,去掉 DiT 里冗余的类条件分支,提速 30%。
3.2.3 SSM 系(Mamba 新势力)
Transformer 的 复杂度是硬伤,SSM(状态空间模型)比如 Mamba 能做到
复杂度,专门解决长序列问题。论文里的 DiM(Diffusion Mamba)就是把 Mamba 改成扩散 backbone:
- 关键设计:让 Mamba 块按 “上下左右” 四个方向扫描特征,避免单向扫描丢失空间连续性;
- 优点:高分辨率(比如 2048x2048)和长视频生成时,速度比 Transformer 快好几倍,参数量还小;
- 缺点:空间细节建模不如 U-Net,适合对速度要求高的场景。
3.3 文本编码器:从 CLIP 到 LLM
文本引导的核心是 “把文本语义准确传给扩散模型”,论文里对比了不同文本编码器(表 1):
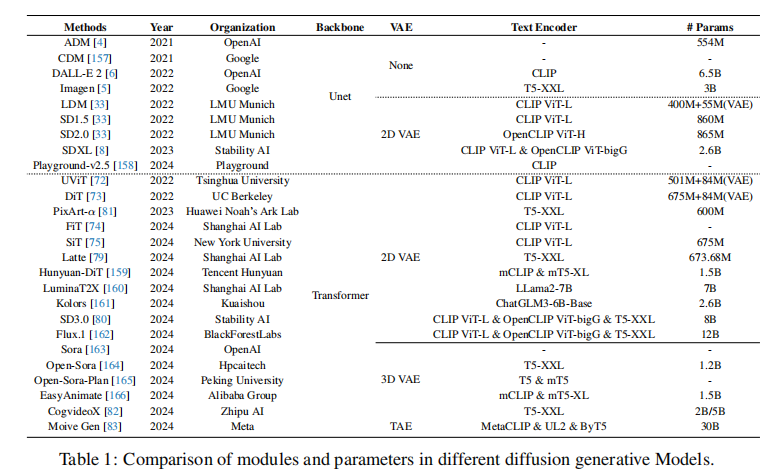
- CLIP 系:SD 用的 CLIP ViT-L,优点是快、轻,缺点是理解复杂文本(比如长句子、多物体)能力弱;
- LLM 系:Imagen 用 T5-XXL,SD3.0 用 CLIP+T5+OpenCLIP 组合,能理解更细的语义(比如 “红色帽子戴在白发老人头上”);
- 多语言支持:Hunyuan-DiT 用 mCLIP + mT5,支持中文;Kolors 用 ChatGLM3,对中文 prompt 理解更准(图 6 能看到生成效果差异)。

四、高效训练与微调:少训参数,少用数据
训练扩散模型太费资源,论文第 4 章讲的 “参数高效” 和 “标签高效” 方法,是现在落地的关键。
4.1 参数高效训练:只训一小部分参数
不用全量微调,只更新模型的 “边角料”,既能适配新任务,又不丢预训练能力。可分为三类:ControlNet、适配器、LoRA。
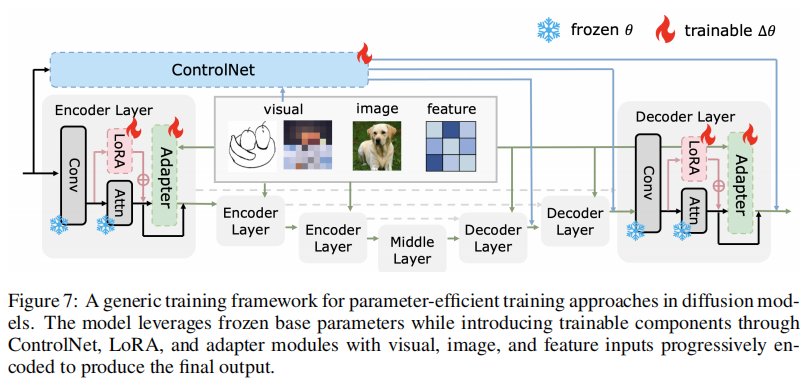
4.1.1 ControlNet
前面提过(图8),核心是 “冻结原模型,训一个副本 + 控制模块”,参数增量一般在 100M 以内(比全训 SD 的 860M 省多了)。变种:
- ControlNet-XS:减少控制模块的通道数,用高频通信让控制信号更高效,参数量减到 30M,训得更快;
- ControlNeXt:用 “交叉归一化” 代替零卷积,让副本和原模型参数分布更对齐,收敛更快。
4.1.2 Adapter(适配器)
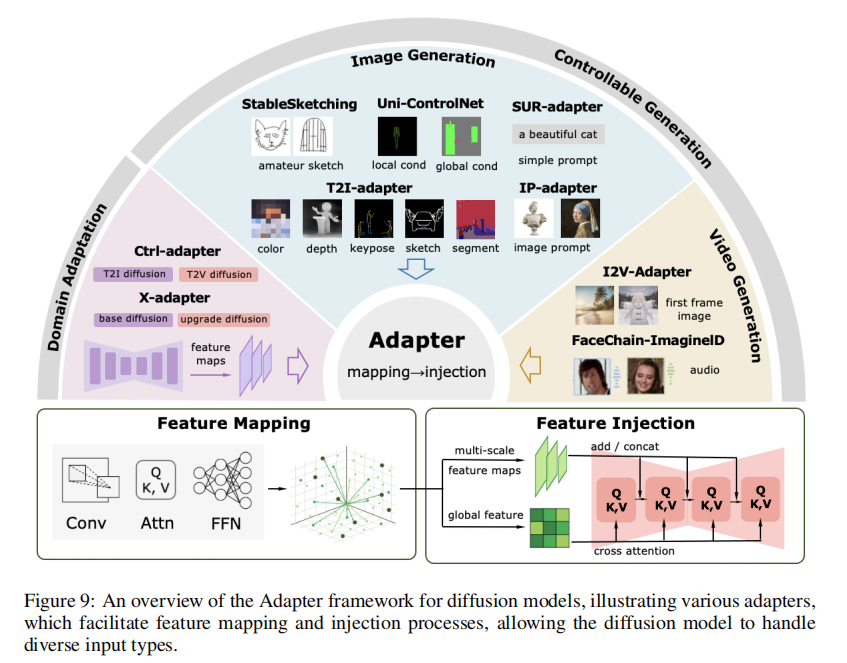
比 ControlNet 更灵活,在原模型里插小模块(比如在 Transformer 层间加 “bottleneck 结构”),只训这些小模块。论文里的 T2I-Adapter 是典型:
- 做法:在 SD 的 U-Net 各层插 Adapter,输入是控制信号(比如边缘图),输出是调整后的特征;
- 优点:参数量只有 77M,训 3 天就能适配新控制任务(比如素描转图);
- 场景:可控生成(T2I-Adapter 支持素描、深度图)、领域适配(X-Adapter 把图像模型适配到视频)。
4.1.3 LoRA(低秩适应)
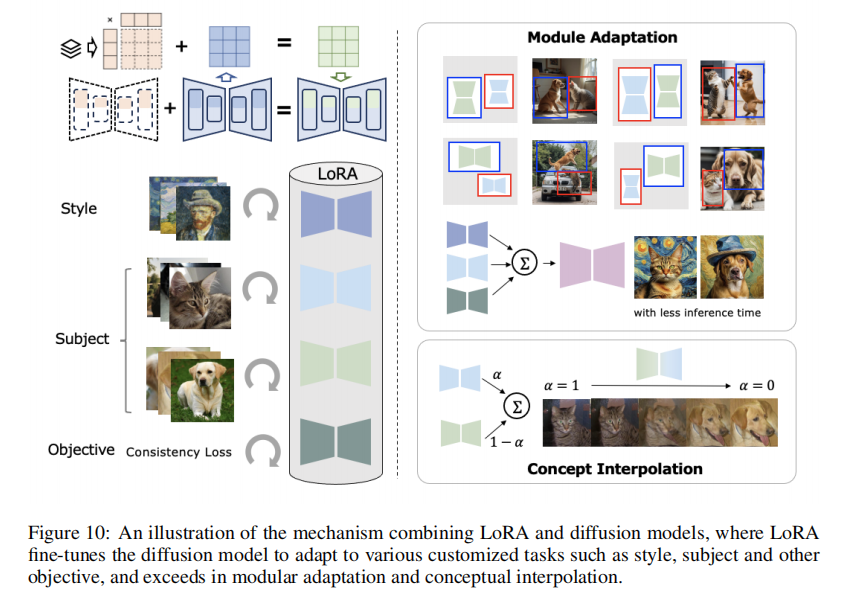
现在最火的微调方法,核心是 “用低秩矩阵近似参数更新”。
- 原理:假设模型权重更新
可以分解成
(
是
,
是
,
是低秩,比如 4、8),则
;
- 优点:参数量极小(比如 SD 用 LoRA 训风格,参数量只有 100K),训完能和原模型合并,推理时不增加延迟;
- 变种:
- LCM-LoRA:把 “风格 LoRA” 和 “加速 LoRA” 合并,既能保持风格,又能把采样步从 50 减到 4;
- LoRA-Composer:多个 LoRA 组合,比如 “猫 LoRA + 梵高风格 LoRA”,能生成 “梵高风格的猫”,还能控制位置和大小。
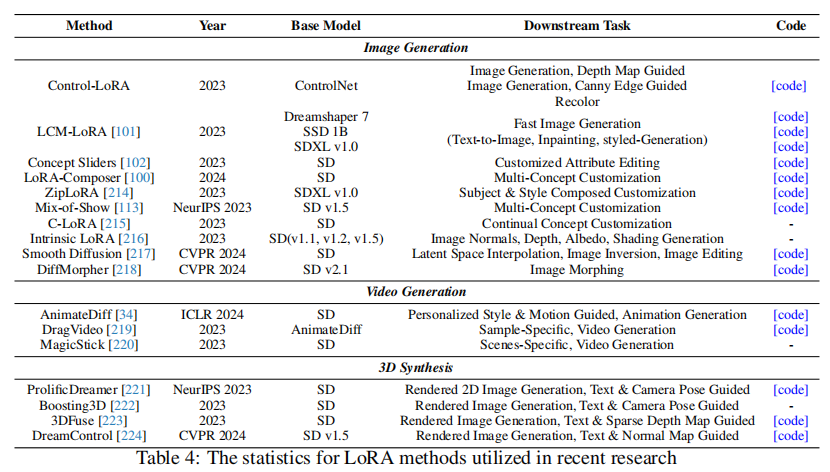
应用十分广泛:
4.2 标签高效训练:少用数据,甚至不用标注
很多场景没有大量标注数据,论文讲了两种解决思路:
4.2.1 偏好优化(对齐人类审美)
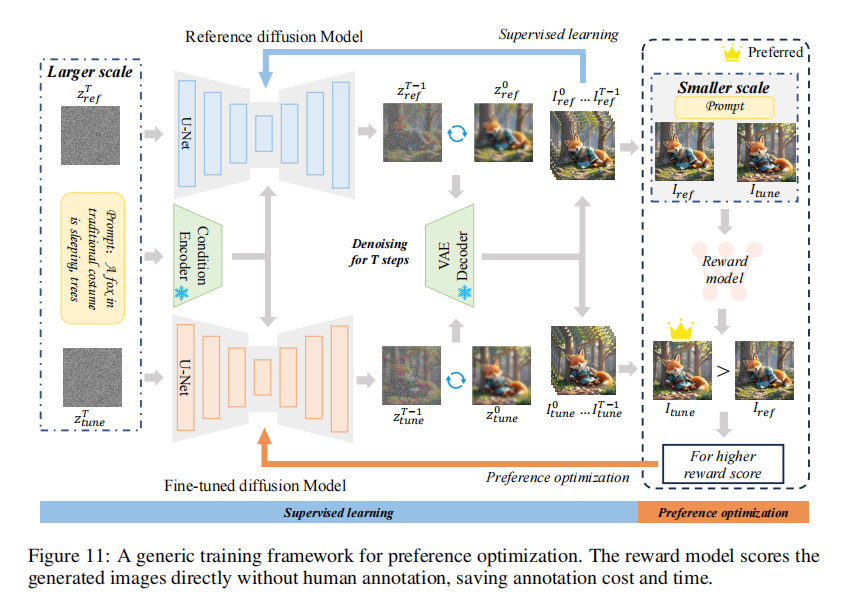
传统训练只看 “损失小”,但损失小不代表生成的图好看。偏好优化的思路是:
- 训一个 “奖励模型(RM)”:用人类标注的 “偏好数据”(比如 “A 图比 B 图好看”)训 RM,让 RM 能给图打分;
- 用 RM 指导扩散模型训练:
- 直接微调:选 RM 打分高的样本训模型(RAFT 用这个方法,避免过拟合);
- RLHF:把扩散的去噪过程当成 “马尔可夫决策过程”,用强化学习最大化 RM 分数(DDPO 是代表,比传统 RLHF 更稳定)。
4.2.2 个性化训练(小数据定制)
比如用 10 张自己的照片训模型,让它能生成 “自己风格的图”。
- Fine-tuning 派:
- DreamBooth:用 “[V]” 这样的特殊 token 代表目标物体,训的时候加 “类别先验”(比如 “[V] 是一只猫”),避免过拟合;
- Textual Inversion:只训文本嵌入,不训扩散模型,参数量极小(几 K),适合低资源场景。
- Encoder 派:
- BLIP-Diffusion:用 Q-Former(BLIP 的 encoder)提取参考图的特征,注入扩散模型,不用微调扩散模型本身,零样本就能个性化生成;
- ELITE:从粗到细提取目标特征,先训一个 “粗 encoder” 抓整体,再训 “细 encoder” 抓细节,生成质量比 DreamBooth 高。
五、快速采样与推理:把 1000 步压到 10 步内
扩散模型最大的落地障碍是 “采样慢”,论文第 5 章把快速采样方法分成 “无训练依赖” 和 “有训练依赖” 两类,覆盖了几乎所有主流方案。
5.1 无训练依赖方法:不用训新模型,直接改采样逻辑
这类方法最实用,直接在预训练模型上改,不用额外数据。
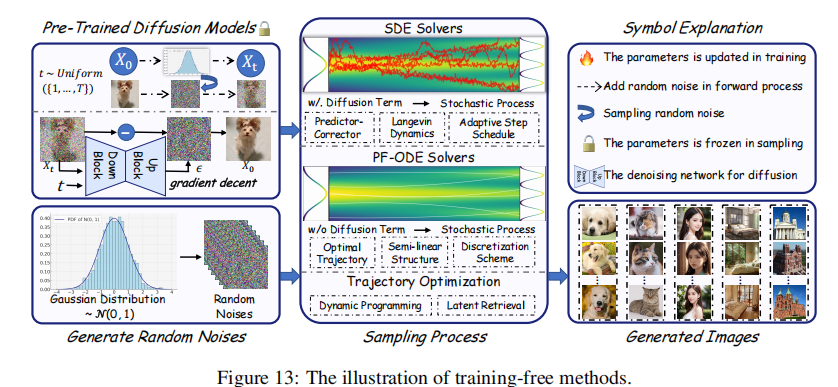
5.1.1 SDE/ODE 求解器优化
扩散模型的采样过程本质是解 SDE/ODE,优化求解器就能减少步数。
-
SDE 求解器:
- CLD(Critically-damped Langevin Diffusion):加一个 “速度变量”
,让扩散在 “数据 - 速度” 联合空间进行,避免欠阻尼振荡和过阻尼慢收敛,采样步从 1000 减到 50;
- 自适应步长:根据误差调整步长(比如 Jolicoeur-Martineau 的方法),误差小就加大步长,误差大就缩小,平均步数能减 40%。
- CLD(Critically-damped Langevin Diffusion):加一个 “速度变量”
-
ODE 求解器(确定性采样,比 SDE 快):
- DDIM:把扩散过程改成非马尔可夫的,采样步可以自由设(比如 50 步→10 步),质量下降少;
- DPM-Solver:发现扩散 ODE 可以拆成 “线性 + 非线性” 两部分,线性部分能解析解,非线性部分用泰勒展开近似,10 步就能达到 DDPM 1000 步的质量;
- PNDM:在流形上解 ODE,避免采样时跳出模型的 “有效区域”,10 步采样的 FID 比 DDIM 低 15%。
5.1.2 检索式加速(ReDi)
思路很简单:采样前几步生成的特征,去预存的 “轨迹库” 里找相似的,后面的步骤直接用库中的轨迹,不用重新算。
- 关键:前几步决定图像布局,后面几步只加细节,布局相似的话细节可以复用;
- 效果:采样步从 50 减到 20,FID 只降 0.3,适合实时应用。
5.2 有训练依赖方法:训一个 “轻量学生模型”
用预训练的 “教师模型”(比如 100 步采样的 SD)训一个 “学生模型”,让学生模型能 1-10 步出图。
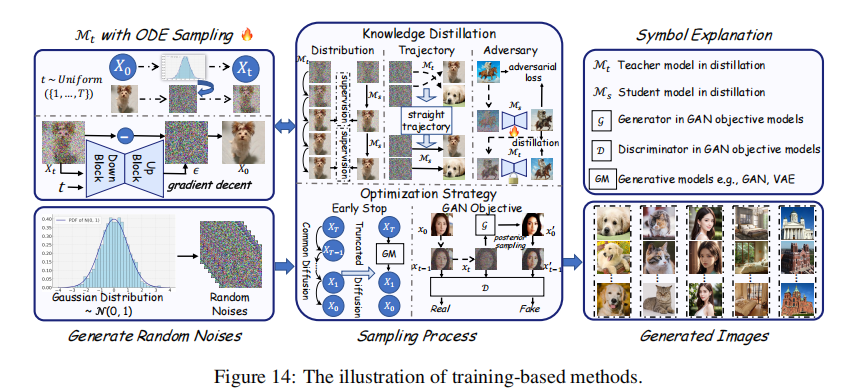
5.2.1 知识蒸馏
- 分布蒸馏:让学生模型的生成分布和教师模型对齐(比如 Denoising Student 训 1 步模型,对齐 100 步教师模型的分布);
- 轨迹蒸馏:把教师模型的采样轨迹(每一步的
- 对抗蒸馏:加一个判别器,让学生模型生成的图和教师模型的图 “看起来一样”(比如 ADD 用 DINOv2 当判别器,1 步采样 FID 接近教师模型)。
5.2.2 一致性模型(CM)
这是个里程碑方法,核心是 “让模型在任意步的预测都一致”:
- 训练目标:如果从
去噪一步得到
- 效果:不用蒸馏,直接训一个 CM,4 步采样就能达到 SD 50 步的质量,还能零样本适配超分、修复任务。
5.2.3 GAN 融合(DDGAN)
扩散模型生成质量高但慢,GAN 快但质量差,融合两者:
- 做法:用 GAN 的目标训扩散模型,让模型在少步采样时生成 “多模态分布”(不用再假设是高斯分布);
- 效果:UFOGen 用这个方法实现 1 步采样,MS-COCO 上 FID 比 SD 50 步只高 2.1,速度快 50 倍。
六、高效部署:从云端到手机,全场景覆盖
训练和采样优化完,最后一步是落地。论文第 6 章把部署分成 “工具化” 和 “服务化”,对应不同用户需求。
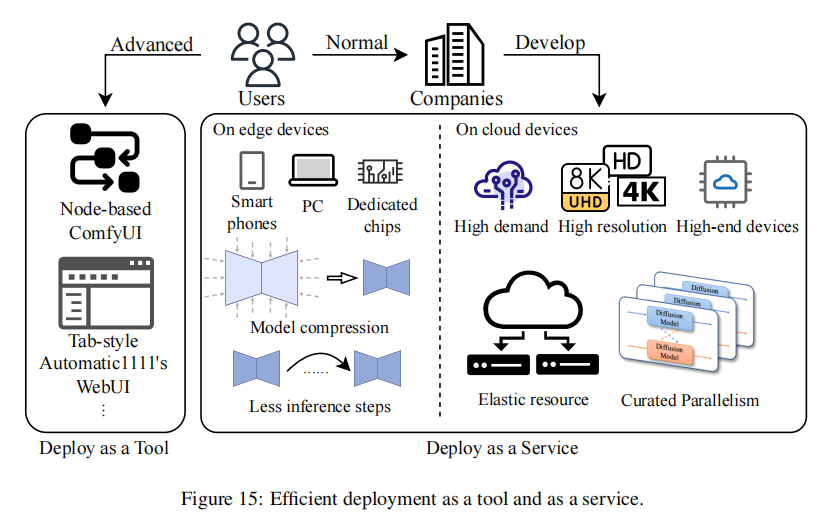
6.1 部署为工具:给开发者用的灵活方案
这类工具强调 “可定制”,适合研究员和开发者调参、改模型。
-
ComfyUI:
- 节点式界面,把 “加载模型→加控制信号→采样→解码” 拆成节点,拖拖拽拽就能搭流程;
- 优点:灵活,支持自定义节点(比如加个 LoRA 节点、ControlNet 节点),适合调试新算法;
- 缺点:学习曲线陡,新手用不惯。
-
Automatic1111 WebUI:
- 表单式界面,输入 prompt、采样步、分辨率就能生成,支持插件(比如 ControlNet、DreamBooth 插件);
- 优点:易用性高,新手半小时就能上手,插件生态丰富;
- 缺点:自定义能力弱,改底层逻辑(比如换 backbone)不方便。
6.2 部署为服务:给普通用户用的 “一键生成”
服务化要解决 “低延迟、跨平台、低成本”,论文里讲了几个关键技术:
6.2.1 移动端部署
手机算力有限,核心是 “模型压缩 + 采样优化”:
-
SnapFusion:
- 优化 U-Net:去掉冗余卷积,用 “进化训练” 让模型适应少步采样;
- 结果:iPhone 14 Pro 生成 512x512 图只要 2 秒,比之前的方法快 6 倍,内存控制在 2GB 内。
-
MobileDiffusion:
- 极致压缩:U-Net 用 “共享投影矩阵” 减参,VAE 解码器剪枝,采样用 UFOGen 的 1 步方法;
- 结果:iPhone 15 Pro 生成 512x512 图只要 0.2 秒,还支持边缘图控制、LoRA 风格。
6.2.2 云端部署
云端要处理高并发、高分辨率,核心是 “并行计算 + 资源调度”:
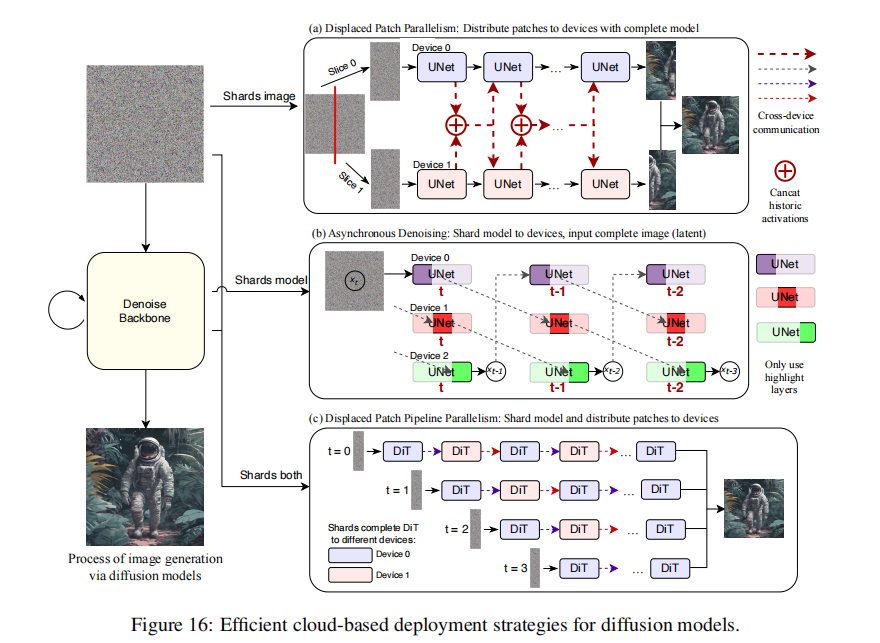
-
DistriFusion:
- 分片并行:把高分辨率图像切成 patch,分给多个 GPU 处理,复用前一步的全局特征,减少通信;
- 结果:8 张 A100 生成 3840x3840 图,速度比单卡快 6.1 倍,FID 几乎不变。
-
PipeFusion:
- 管道并行:把 DiT 模型的层分给不同 GPU,同时处理不同采样步,只传关键层的激活值,减少通信量;
- 结果:4 张 A100 生成 8192x8192 图,延迟比 DistriFusion 低 40%,还不会 OOM。
-
AsyncDiff:
- 异步并行:打破采样步的顺序依赖,多个步同时算,用 “步间相似性” 预测中间结果;
- 结果:4 张 A5000 跑 SDv2.1,速度快 4 倍,CLIP 分数只降 0.38。
七、应用场景
论文第 7 章覆盖了 7 个核心应用,每个场景都有明确的技术选型,不是空谈。
7.1 图像合成
- 定制生成:用 DreamBooth+LoRA 做 “个人风格定制”,比如训一个 “自己的头像 LoRA”,生成各种场景的头像;
- 多语言支持:用 Hunyuan-DiT(mCLIP+mT5)、Kolors(ChatGLM3)支持中文 prompt,比如 “一个戴红帽子的白发老人” 生成效果比 SD 准;
- 安全生成:加隐写水印(比如 Safe-SD),生成的图里藏 “不可见水印”,防止版权纠纷。
7.2 图像编辑
- 指令编辑:InstructPix2Pix 用文本指令编辑(比如 “把猫变成狗”),ControlNet 用边缘图控制编辑(比如 “按素描改图”);
- 虚拟试衣:OutfitAnyone 用扩散模型做 “超高清虚拟试衣”,衣服褶皱、光影效果比传统方法真实;
- 低阶视觉:超分(CDDF 用 10 步扩散做 4K 超分)、去模糊(DiffIR 用 20 步扩散去运动模糊)、修复(RePaint 用 50 步扩散修复大面积缺失)。
7.3 视频生成
- 可控生成:AnimateDiff 用 LoRA 控制动作(比如 “走路”“跑步”),ControlVideo 用深度图控制镜头运动;
- 长视频生成:Open-Sora 用 3D VAE 压缩视频,Latte 用 DiT 做时空建模,能生成 16 秒 512x512 视频;
- 世界模拟:Sora 把视频模型当 “世界模拟器”,能生成物理规律一致的视频(比如水流、物体碰撞),但闭源,论文里提了 Open-Sora 作为开源替代。
7.4 视频编辑
- 视频虚拟试衣:ViViD 用层级约束固定人物姿态与背景(比如避免试衣后人物动作脱节),OutfitAnyone 通过 3D 人体姿态估计实现衣物贴合(比如走路时衣角自然摆动);
- 视频动作编辑:MotionEditor 用单样本微调 AnimateDiff 控制动作(比如 “慢走改快走”),DragVideo 靠注意力机制优化实现拖拽式编辑(比如调整人物手部位置);
- 统一编辑:FLATTEN 用光流引导特征融合(比如同时修改风格与动作节奏),Dreamix 通过大规模视频 - 文本训练支持多需求编辑(比如 “人物骑行车改骑独角兽”);
- 零样本编辑:无训练适配方案用特征传播(比如将关键帧编辑特征传递到相邻帧)、注意力调整(比如编辑时参考相邻帧相似区域)解决时空失真(比如避免物体位置跳变)。
7.5 3D 合成
- 文本转 3D:DreamFusion 用文本生成 3D 模型,ProficDreamer 用 LoRA 控制 3D 物体姿态;
- 数字人:RodinHD 生成高保真 3D 头像,DiffPortrait3D 支持零样本视角合成(比如从正面图生成侧面图);
- 动作建模:MotionDiffuse 用文本生成人类动作(比如 “跳舞”),Animate Anyone 用单张图生成连贯的人物动画。
7.6 医学成像
- 模态转换:用扩散模型把 CT 转 MRI(DiffMa),减少患者辐射暴露;
- 数据增强:合成高质量医学图像(比如病理切片),解决标注数据少的问题;
- 异常检测:生成 “健康器官图像”,和真实图像对比找异常区域(比如肺癌筛查)。
7.7 生物信息
- 蛋白质设计:AlphaFold3 用扩散模型预测蛋白质结构,RFdiffusion 设计新蛋白质(比如酶);
- 分子设计:DiffDock 预测小分子药物和蛋白质的结合构象,加速药物研发;
- 抗体设计:DiffAb 生成抗原特异性抗体,比传统方法快 10 倍。
八、未来方向
论文最后提了几个关键方向,都是现在行业的痛点:
- 统一多模态控制框架:现在 ControlNet 只支持视觉条件,Adapter 要为每个任务改结构,未来需要一个框架能同时处理文本、图像、深度、音频等多模态条件,不用重训;
- 动态网络:把 MoE(混合专家)加到扩散模型里,比如按输入内容激活不同专家模块(比如生成风景图激活 “天空专家”,生成人物激活 “人脸专家”),省计算;
- 训练 - 采样权衡:现在无训练方法要 10 步以上才保证质量,有训练方法训起来贵,未来要结合两者,比如用少量数据训一个 “轻量加速模块”,插在预训练模型里;
- 低资源部署:现在手机端生成 1024x1024 图还很慢,未来要做更极致的压缩(比如量化到 4bit)、硬件适配(比如用 NPU 加速);
- 涌现能力:让扩散模型像 LLM 一样,参数量大到一定程度出现 “新能力”(比如 Sora 的世界模拟),现在还不清楚扩散模型的涌现阈值在哪。
九、总结:这篇论文为什么值得读?
这篇综述不是简单罗列论文,而是给了一个 “高效扩散模型” 的完整技术地图:
- 从理论到落地:每个技术点都讲清 “原理→做法→效果”,比如 LoRA 的低秩分解、DPM-Solver 的 ODE 求解,不是黑箱;
- 数据翔实:表格里列了 50+ 模型的参数、性能、开源情况,比如表 1 对比 SD 各版本、表 6 对比采样方法的 FID 和步数,能直接当工具书查;
- 落地导向:部署部分讲了 ComfyUI、MobileDiffusion 等实际工具,不是空谈理论,能直接参考做工程。
如果你是做扩散模型研究的,这篇论文能帮你找清方向;如果你是做工程落地的,这里面的训练、采样、部署方法能直接用。建议配合作者的 GitHub 仓库看,里面有最新的论文和代码链接,跟着更新不会落后。