高频 Redis 面试题答案解析
1. Redis 是什么?有哪些优缺点?
一、Redis 是什么?
标准回答
Redis(Remote Dictionary Server)是一个开源的、基于内存的高性能键值数据库,支持多种数据结构,常用于缓存、消息队列、排行榜、会话存储等场景。
它采用单线程 + IO 多路复用模型,数据存储在内存中,并支持持久化到磁盘,保证数据安全。
补充细节(加分点):
- 开发语言:C 语言编写,性能极高
- 数据结构:支持 String、List、Set、Hash、ZSet、Bitmap、HyperLogLog、Geo 等
- 持久化:支持 RDB(快照)和 AOF(追加日志)两种方式
- 高可用:支持主从复制、哨兵模式、Cluster 集群
- 应用场景:缓存加速、分布式锁、限流、排行榜、延时队列、消息队列等
二、Redis 的优点
| 优点 | 说明 |
|---|---|
| 高性能 | 数据存储在内存中,读写速度可达 10万+ QPS,远高于传统关系型数据库 |
| 多数据结构 | 除了简单的 key-value,还支持丰富的数据结构,方便实现复杂业务逻辑 |
| 持久化支持 | RDB 和 AOF 两种持久化方式,既能保证性能又能保证数据安全 |
| 高可用与扩展性 | 支持主从复制、哨兵模式、Cluster 集群,方便水平扩展 |
| 原子性操作 | 单线程模型保证命令的原子性,不需要额外加锁 |
| 丰富的功能 | 发布订阅(Pub/Sub)、Lua 脚本、事务、Pipeline 等 |
三、Redis 的缺点
| 缺点 | 说明 | 解决思路 |
|---|---|---|
| 内存成本高 | 数据存储在内存中,成本比磁盘高 | 只缓存热点数据,使用内存压缩(ziplist、intset) |
| 数据易丢失 | 如果不开启持久化,宕机会丢失数据 | 开启 AOF(everysec)或混合持久化 |
| 单线程 CPU 瓶颈 | 单线程处理命令,CPU 成为瓶颈 | 多实例分片、Cluster 集群 |
| 不适合大数据量全量存储 | 内存限制,无法像 MySQL 那样存储 TB 级数据 | 作为缓存层,配合数据库使用 |
| 大 key/热 key 问题 | 大 key 会阻塞线程,热 key 会造成访问集中 | 拆分大 key、热点数据分片 |
四、面试回答示例(流畅版)
Redis 是一个开源的内存型键值数据库,采用单线程 + IO 多路复用模型,支持多种数据结构,并且可以通过 RDB 和 AOF 持久化到磁盘。它的优点是性能极高、支持丰富数据结构、持久化、高可用和原子性操作,常用于缓存、分布式锁、排行榜等场景。
缺点是内存成本高、可能丢失数据、单线程 CPU 瓶颈、不适合大规模全量存储,以及可能出现大 key/热 key 问题。
在实际业务中,我们通常会结合数据库,把 Redis 作为缓存层使用,同时开启 AOF everysec 保证数据安全。
解答:Redis 的单线程 + IO 多路复用模型
1. 什么是单线程?
- 单线程指的是 Redis 处理网络请求的核心模块(命令解析、执行、返回结果)只有一个线程来完成。
- 也就是说,Redis 一次只处理一个命令,不会同时执行多个命令。
- 这样做的好处:
- 避免多线程加锁开销(不需要考虑线程安全问题)
- 减少上下文切换(线程切换会消耗 CPU 时间)
- 代码实现简单,性能稳定
⚠️ 注意:
Redis 不是完全单线程,它在持久化(RDB/AOF 重写)、集群数据迁移等场景会用到额外的子进程或线程,但核心命令执行是单线程。
2. 什么是 IO 多路复用?
- IO 多路复用是一种高效处理多个网络连接的技术。
- Redis 使用 epoll(Linux)/ kqueue(BSD)/ select(通用) 来同时监听多个客户端连接。
- 它的作用是:一个线程就能同时管理成千上万个连接,而不是一个连接一个线程。
生活类比
想象你是一个餐厅服务员:
- 单线程:你一个人负责点菜、上菜、收钱(一次只做一件事)
- IO 多路复用:你有一个呼叫器系统,可以同时监听 100 张桌子,一旦有桌子按铃,你就去处理那一桌的需求,而不是傻傻地一桌一桌轮流问。
3. Redis 的单线程 + IO 多路复用工作流程
- 监听所有客户端连接(通过 epoll/kqueue)
- 事件触发:某个连接有数据可读(客户端发来命令)或可写(可以返回结果)
- 事件放入队列:Redis 把这些事件放到事件队列中
- 单线程依次处理事件:
- 读取命令
- 解析命令
- 执行命令(操作内存数据)
- 返回结果
- 继续监听,等待下一个事件
流程图(简化版)
复制代码
客户端1 ─┐ 客户端2 ─┼─> epoll 监听事件 ─> 事件队列 ─> 单线程依次处理 客户端3 ─┘
4. 为什么单线程还能很快?
- 内存操作:Redis 所有数据都在内存中,读写速度接近纳秒级
- 无锁竞争:单线程避免了多线程加锁的性能损耗
- IO 多路复用:一个线程就能同时处理成千上万个连接
- 高效数据结构:底层用 SDS、跳表、哈希表等优化结构
- 命令执行快:大部分命令时间复杂度低(O(1) 或 O(logN))
5. 面试回答示例
Redis 的核心命令执行是单线程的,这样可以避免多线程加锁和上下文切换的开销,保证命令的原子性。
它通过 IO 多路复用(epoll/kqueue)同时监听多个客户端连接,把有事件的连接放到事件队列中,然后单线程依次处理。
这种模型结合内存存储和高效数据结构,使得 Redis 即使是单线程,也能轻松处理每秒十万级的请求。
6. 补充加分点(面试官会喜欢)
- Redis 6.0 之后引入了多线程 IO(只用于网络读写,命令执行仍是单线程),进一步提升了高并发场景下的性能。
- 如果 CPU 成为瓶颈,可以通过多实例分片或Cluster 集群来扩展。
2. Redis 支持哪些数据类型?使用场景分别是什么?
Redis 支持以下数据类型:
String
- 最基本的类型,二进制安全,可以存储字符串、数字、JSON 等
- 场景:缓存对象、计数器、分布式锁
- 案例:
SET user:1001 '{"name":"Tom"}'
List
- 双向链表结构,可以从两端插入/弹出
- 场景:消息队列、任务列表
- 案例:
LPUSH queue task1
Set
- 无序集合,元素唯一
- 场景:去重、标签系统
- 案例:
SADD tags java python
Hash
- 类似 Map,适合存储对象的多个字段
- 场景:用户信息、配置项
- 案例:
HSET user:1001 name Tom age 20
ZSet(Sorted Set)
- 有序集合,每个元素有一个分数(score)
- 场景:排行榜、延时任务
- 案例:
ZADD rank 100 Tom
Bitmap
- 位图,适合存储布尔状态
- 场景:签到、活跃用户统计
- 案例:
SETBIT sign:20250101 1001 1
HyperLogLog
- 基数统计,内存占用极小
- 场景:UV 统计
- 案例:
PFADD uv 1001
Geo
- 地理位置存储与计算
- 场景:附近的人、地图服务
- 案例:
GEOADD city 116.40 39.90 beijing
3. Redis 为什么这么快?
Redis 快的原因主要有:
- 内存存储:数据全部在内存中,访问速度接近 CPU 缓存速度
- 单线程模型:避免多线程锁竞争和上下文切换
- IO 多路复用:使用 epoll 处理大量连接
- 高效数据结构:SDS、ziplist、skiplist 等
- 优化的命令执行:命令解析和执行非常轻量
案例
在一次秒杀项目中,Redis 每秒处理了 10万+ 请求,而 MySQL 在同样场景下只能处理几千请求。
4. Redis 持久化方式有哪些?区别是什么?
(我们之前已经详细讲过 RDB 和 AOF,这里简述)
- RDB:定时快照,恢复快,可能丢数据
- AOF:记录写命令,数据安全,文件大,恢复慢
- 混合持久化:结合两者优点
5. Redis 过期策略有哪些?
Redis 过期策略:
- 定期删除:每隔一段时间随机抽取部分设置了过期时间的 key,检查是否过期并删除
- 惰性删除:访问 key 时才检查是否过期,过期则删除
- 内存淘汰:内存不足时,根据淘汰策略删除数据
1. 什么是 Redis 过期策略?
Redis 允许给 key 设置过期时间(TTL, Time To Live),一旦过期,Redis 会删除这个 key。
但是,删除策略有多种,不同策略会影响性能和内存占用。
Redis 采用的是 “定期删除(Periodic Deletion)+ 惰性删除(Lazy Deletion)” 结合的方式,并在内存不足时配合内存淘汰策略(Memory Eviction Policy)。
2. 三种过期策略
① 定时删除(Scheduled Deletion / Timer-based Deletion)
- 给每个 key 设置一个定时器(Timer),到期立即删除。
- 优点:内存释放及时
- 缺点:需要大量定时器,CPU(Central Processing Unit)开销大,影响性能
- Redis 不采用这种方式,因为会严重影响性能。
② 定期删除(Periodic Deletion)
- Redis 每隔一段时间(默认 100ms,即 0.1 秒)随机抽取部分设置了过期时间的 key,检查是否过期,如果过期就删除。
- 优点:控制 CPU 占用,不会一次性扫描所有 key
- 缺点:可能有部分过期 key 没被及时删除,占用内存
执行细节:
- Redis 会从**过期字典(Expire Dictionary)**中随机取出 N 个 key(默认 20 个)
- 检查是否过期,过期则删除
- 如果过期比例超过 25%,继续循环检查,直到比例下降
③ 惰性删除(Lazy Deletion)
- 当客户端访问某个 key 时,Redis 会先检查它是否过期,如果过期就删除并返回空(null)。
- 优点:对 CPU 友好,不会主动扫描
- 缺点:如果过期 key 从未被访问,就会一直占用内存
3. Redis 实际使用的策略
Redis 采用 定期删除(Periodic Deletion)+ 惰性删除(Lazy Deletion) 结合:
- 定期删除:减少过期 key 堆积
- 惰性删除:保证访问到的 key 一定是有效的
4. 内存淘汰策略(Memory Eviction Policy)
如果定期删除和惰性删除都没及时清理,导致内存不足,Redis 会触发内存淘汰策略(maxmemory-policy):
| 策略名称 | 全称(英文补全) | 说明 |
|---|---|---|
volatile-lru | Volatile Least Recently Used | 从设置了过期时间的 key 中淘汰最近最少使用的 |
allkeys-lru | All Keys Least Recently Used | 从所有 key 中淘汰最近最少使用的 |
volatile-ttl | Volatile Time To Live | 从设置了过期时间的 key 中淘汰即将过期的 |
allkeys-random | All Keys Random | 从所有 key 中随机淘汰 |
volatile-random | Volatile Random | 从设置了过期时间的 key 中随机淘汰 |
noeviction | No Eviction | 不淘汰,直接返回错误 |
5. 执行流程图
┌───────────────────┐│ 设置 TTL (Time To Live) │└─────────┬─────────┘│┌──────────▼──────────┐│ 定期删除 (Periodic Deletion) │└──────────┬──────────┘│┌──────────▼──────────┐│ 客户端访问 key │└──────────┬──────────┘│┌──────────▼──────────┐│ 惰性删除 (Lazy Deletion) │└──────────┬──────────┘│┌──────────▼──────────┐│ 内存不足? │───否──> 结束└──────────┬──────────┘│是┌──────────▼──────────┐│ 内存淘汰策略 (Memory Eviction Policy) │└─────────────────────┘
6. 案例
场景:
假设你有一个电商系统,用户浏览商品时会缓存商品详情,TTL 设置为 10 分钟。
- 定期删除(Periodic Deletion):Redis 每 100ms 随机抽查部分商品缓存,发现过期的就删除
- 惰性删除(Lazy Deletion):如果某个商品缓存过期了,但用户没访问,就不会立即删除;等用户访问时才删除
- 内存淘汰策略(Memory Eviction Policy):如果缓存太多,内存不足,就会根据 LRU(Least Recently Used)策略淘汰一些最久没访问的商品缓存
7. 面试回答示例(带英文全称)
Redis 的过期策略是 定期删除(Periodic Deletion)+ 惰性删除(Lazy Deletion) 结合使用。
定期删除会每隔一段时间随机抽取部分设置了 TTL(Time To Live)的 key 检查是否过期,减少过期 key 堆积;惰性删除是在访问 key 时才检查是否过期,保证访问到的数据一定有效。
如果这两种方式都没及时清理,导致内存不足,Redis 会根据maxmemory-policy执行 内存淘汰策略(Memory Eviction Policy),比如 LRU(Least Recently Used)、TTL 优先等。
这种组合策略在性能(Performance)和内存利用率(Memory Utilization)之间做了平衡。
6. Redis 常见的内存淘汰策略有哪些?
volatile-lru:从设置了过期时间的 key 中淘汰最近最少使用的allkeys-lru:从所有 key 中淘汰最近最少使用的volatile-ttl:从设置了过期时间的 key 中淘汰即将过期的allkeys-random:随机淘汰volatile-random:随机淘汰设置了过期时间的 keynoeviction:不淘汰,直接返回错误
7. Redis 分布式锁的实现原理?如何保证安全释放?
1. 为什么需要分布式锁?
在分布式系统(Distributed System)中,多个服务实例可能会同时访问或修改同一份数据(例如库存、订单),如果不加控制,就会出现并发冲突(Concurrency Conflict)。
分布式锁的作用就是保证同一时间只有一个客户端(Client)能操作某个资源。
2. Redis 分布式锁的核心原理
Redis 分布式锁的实现依赖于 SET 命令的扩展参数:
SET key value NX EX expire_time- NX(Set if Not Exists,全称:Only Set Key if it Does Not Exist)
保证只有在 key 不存在时才能成功设置(原子性加锁) - EX expire_time(Expire Time in Seconds,全称:Set Expiration Time in Seconds)
设置锁的过期时间,防止死锁 - value:锁的唯一标识(通常是 UUID,全称:Universally Unique Identifier),用来区分不同客户端的锁
加锁流程
- 客户端生成一个唯一标识(UUID)
- 执行
SET lock_key UUID NX EX 10(10 秒过期) - 如果返回
OK,表示加锁成功;否则锁已被其他客户端持有
3. 安全释放锁的关键问题
问题 1:锁过期后被其他客户端获取
如果客户端 A 持有锁,但执行时间过长,锁过期了,客户端 B 获取了锁。
此时如果 A 直接执行 DEL lock_key,就会误删 B 的锁。
解决方案:
释放锁时必须先检查锁的 value 是否是自己设置的 UUID,只有匹配才删除。
问题 2:检查和删除不是原子操作
如果用两条命令:
GET lock_key
DEL lock_key在 GET 和 DEL 之间可能会被其他客户端抢锁,导致误删。
解决方案:
使用 Lua 脚本(Lua Script) 保证检查和删除的原子性(Atomicity)。
安全释放锁的 Lua 脚本
if redis.call("GET", KEYS[1]) == ARGV[1] thenreturn redis.call("DEL", KEYS[1])
elsereturn 0
end
KEYS[1]:锁的 keyARGV[1]:锁的唯一标识(UUID)- 如果锁的 value 等于 UUID,则删除锁并返回 1;否则返回 0
4. RedLock 算法(更安全的分布式锁)
RedLock 是 Redis 作者提出的分布式锁算法,用于多节点环境,保证更高的安全性。
原理
- 在多个 Redis 节点(建议 5 个)上同时加锁
- 必须在半数以上节点加锁成功才算加锁成功
- 锁的有效时间 = 原始过期时间 - 获取锁的耗时
- 释放锁时在所有节点执行 Lua 脚本删除
优点:即使部分节点宕机,也能保证锁的安全性
缺点:实现复杂,性能比单节点锁低
5. 案例:库存扣减
场景:秒杀活动中,多个服务实例同时扣减库存
实现步骤:
- 客户端生成 UUID
SET stock_lock UUID NX EX 5(5 秒过期)- 扣减库存(操作数据库或 Redis)
- 使用 Lua 脚本安全释放锁
- 如果加锁失败,说明有其他客户端在操作,直接返回“抢购失败”
6. 面试回答示例(带英文全称)
Redis 分布式锁依赖
SET key value NX EX expire_time命令,其中 NX(Only Set Key if it Does Not Exist)保证原子性加锁,EX(Expire Time in Seconds)设置过期时间防止死锁,value 通常是 UUID(Universally Unique Identifier)用来区分不同客户端的锁。
为了安全释放锁,需要先检查锁的 value 是否是自己设置的 UUID,并且使用 Lua Script(Lua 脚本)保证检查和删除的原子性。
在多节点环境中,可以使用 RedLock 算法,在多个 Redis 节点上同时加锁,必须半数以上节点成功才算加锁成功,这样即使部分节点宕机也能保证锁的安全性。
这种方式在高并发场景(High Concurrency Scenario)下可以有效防止并发冲突(Concurrency Conflict)。
7. 加分点
- Redis 6.0 之后支持多线程 IO(Input/Output),但分布式锁的命令执行仍是单线程(Single-threaded Execution)
- 过期时间要根据业务执行时间设置,避免锁提前过期
- 可以配合
WATCH机制或SET PX(Expire Time in Milliseconds)使用毫秒级过期时间
8. Redis 如何实现延时队列?
1. 什么是延时队列(Delayed Queue)?
延时队列是一种消息队列(Message Queue, MQ),它的特点是消息不会立即被消费,而是延迟一段时间后才被处理。
常见场景:
- 订单超时取消(例如 30 分钟未支付自动取消)
- 延迟发送通知
- 定时任务调度
2. Redis 实现延时队列的常见方式
方式 1:基于 Sorted Set(有序集合)
原理:
- 使用 Redis 的 ZSet(Sorted Set,有序集合) 存储任务
score存储任务的执行时间(时间戳,Timestamp)- 定时轮询(Polling)取出
score <= 当前时间的任务执行
实现步骤:
- 生产者(Producer) 添加任务:
ZADD delay_queue 1672531200 "order:1001"这里 1672531200 是 Unix 时间戳(Unix Timestamp),表示任务执行时间
- 消费者(Consumer) 定时扫描:
ZRANGEBYSCORE delay_queue 0 current_timestamp LIMIT 0 1取出到期任务,然后执行并删除:
ZREM delay_queue "order:1001"优点:
- 实现简单
- 支持按时间排序
缺点:
- 需要轮询(Polling),会有一定延迟
- 如果任务量大,扫描可能有性能压力
方式 2:基于 List + 延时阻塞
原理:
- 使用
BRPOP(Blocking Right Pop)阻塞读取任务 - 生产者先
sleep(延迟)再LPUSH任务到队列
缺点:
- 延迟逻辑在生产者端,不是真正的延时队列
- 不适合精确调度
方式 3:基于 Stream(Redis 5.0+)
原理:
- 使用 Redis Stream(流数据结构) 存储任务
- 消费者按时间顺序读取
- 延迟逻辑由消费者控制(例如定时检查)
优点:
- 支持消费者组(Consumer Group)
- 消息可持久化
缺点:
- 实现复杂度比 ZSet 高
方式 4:基于 Key 过期事件(Keyspace Notifications)
原理:
- 给任务 key 设置过期时间(TTL, Time To Live)
- 开启 Redis 键空间通知(Keyspace Notifications)
- 当 key 过期时,Redis 会发布事件,消费者订阅该事件并处理任务
配置:
CONFIG SET notify-keyspace-events ExE 表示 Keyevent 事件,x 表示过期事件(Expired Events)
优点:
- 无需轮询,实时触发
- 延迟精度高
缺点:
- 需要开启通知功能(有额外性能开销)
- 过期事件不是持久化的,Redis 重启可能丢失任务
3. 推荐方案
- 如果任务量大、需要排序 → ZSet
- 如果需要实时触发、任务量不大 → Keyspace Notifications
- 如果需要多消费者并行处理 → Stream
4. 案例:订单超时取消(ZSet 实现)
生产者(下单时):
ZADD order_delay_queue 1735660800 "order:1001"这里 1735660800 是订单超时时间(Unix 时间戳)
消费者(定时任务,每秒执行一次):
local now = os.time()
local orders = redis.call("ZRANGEBYSCORE", "order_delay_queue", 0, now, "LIMIT", 0, 10)
for _, order_id in ipairs(orders) do-- 取消订单逻辑redis.call("ZREM", "order_delay_queue", order_id)
end
5. 面试回答示例(带英文全称)
Redis 实现延时队列(Delayed Queue)最常用的方法是基于 ZSet(Sorted Set,有序集合),将任务作为 member,执行时间作为 score(时间戳,Timestamp)。
生产者(Producer)使用ZADD添加任务,消费者(Consumer)定时使用ZRANGEBYSCORE获取到期任务并处理,然后用ZREM删除任务。
这种方式实现简单,支持按时间排序,但需要轮询(Polling)。
如果需要实时触发,可以使用 Redis 的 Keyspace Notifications(键空间通知)监听过期事件(Expired Events);如果需要多消费者并行处理,可以使用 Redis Stream(流数据结构)。
在订单超时取消等场景中,ZSet 方案是最常用的,因为它能高效管理大量延时任务。
6. 加分点
- ZSet 的时间复杂度:
ZADD和ZREM是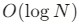 ,
,ZRANGEBYSCORE是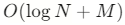 (M 为返回元素个数)
(M 为返回元素个数) - Keyspace Notifications 需要额外配置,且事件可能丢失
- Stream 支持持久化(Persistence)和消费者组(Consumer Group),适合高可靠场景
9. 详解解释Redis 如何实现秒杀系统?
1. 秒杀系统的特点
秒杀(Flash Sale)是电商高并发场景的典型案例,特点:
- 瞬时高并发(High Concurrency):可能在几秒内有几百万请求
- 库存有限(Limited Stock):先到先得
- 要求低延迟(Low Latency):用户体验要快
- 防止超卖(Overselling):库存不能卖超
Redis 因为是内存数据库(In-memory Database),读写速度极快,非常适合做秒杀的核心库存控制。
2. Redis 秒杀系统核心架构
架构流程
- 请求入口(API Gateway)
接收用户秒杀请求,做基础限流(Rate Limiting) - 用户资格校验(Eligibility Check)
检查用户是否有秒杀资格(登录状态、是否重复购买) - 库存预扣(Stock Pre-deduction)
使用 Redis 原子操作扣减库存 - 异步下单(Asynchronous Order Creation)
将成功的用户请求放入消息队列(Message Queue, MQ) - 订单系统(Order Service)
消费队列消息,生成订单并持久化到数据库(Database) - 支付系统(Payment Service)
完成支付,更新订单状态
3. Redis 实现库存扣减的关键方法
方法 1:原子递减(Atomic Decrement)
使用 DECR 或 DECRBY:
DECR stock:product_1001- 如果结果 >= 0,表示扣减成功
- 如果结果 < 0,表示库存不足,需要回滚
缺点:可能出现超卖(多个请求同时扣减)
方法 2:Lua 脚本(Lua Script)保证原子性
local stock = redis.call("GET", KEYS[1])
if not stock thenreturn -1
end
if tonumber(stock) > 0 thenredis.call("DECR", KEYS[1])return 1
elsereturn 0
end
GET+DECR在 Lua 脚本中执行,保证原子性(Atomicity)- 返回 1 表示成功,0 表示库存不足
方法 3:List 队列(Queue-based Stock Control)
- 预先将库存数量的 token(令牌)放入 Redis List
- 用户秒杀时
LPOP一个 token - 如果返回值为空,表示库存已售完
优点:天然防止超卖
缺点:库存量大时 List 占用内存多
4. 防止超卖的关键点
- 原子操作(Atomic Operation):Lua 脚本或队列方式
- 库存预扣(Pre-deduction):先扣库存再异步下单
- 幂等性(Idempotency):同一用户只能成功一次
- 分布式锁(Distributed Lock):防止并发修改同一订单
5. 防止超买 & 超卖的安全策略
| 问题 | 解决方案 |
|---|---|
| 超卖(Overselling) | Lua 脚本原子扣减库存 / List 队列 |
| 超买(Overbuying) | 用户资格校验(Set 存储已购买用户 ID) |
| 重复下单 | 使用 SETNX(Set if Not Exists)记录用户秒杀状态 |
| 恶意请求 | 限流(Rate Limiting)+ 验证码(CAPTCHA) |
| 数据一致性 | 异步下单 + 消息队列(Message Queue) |
6. 秒杀系统 Redis 关键数据结构
| 功能 | Redis 数据结构 | 说明 |
|---|---|---|
| 库存管理 | String | 存储库存数量,配合 Lua 脚本扣减 |
| 用户资格 | Set | 存储已秒杀成功的用户 ID |
| 请求队列 | List / Stream | 存储待处理的秒杀请求 |
| 分布式锁 | String + Lua Script | 保证订单处理的原子性 |
7. 案例:Redis + Lua 秒杀库存扣减
初始化库存:
SET stock:product_1001 100Lua 脚本扣减库存:
local stock = redis.call("GET", KEYS[1])
if not stock thenreturn -1
end
if tonumber(stock) > 0 thenredis.call("DECR", KEYS[1])return 1
elsereturn 0
end
执行:
EVAL "lua_script_here" 1 stock:product_10018. 面试回答示例(带英文全称)
Redis 在秒杀系统中主要用于库存控制(Stock Control)和高并发请求处理(High Concurrency Request Handling)。
常用方法包括:
- 使用 Lua Script(Lua 脚本)保证库存扣减的原子性(Atomicity)
- 使用 List(列表)作为库存队列,天然防止超卖(Overselling)
- 使用 Set(集合)记录已秒杀成功的用户,防止重复购买(Duplicate Purchase)
- 配合分布式锁(Distributed Lock)和消息队列(Message Queue, MQ)实现异步下单,保证数据一致性(Data Consistency)
这种架构能在高并发场景下保证秒杀的公平性(Fairness)、一致性(Consistency)和高性能(High Performance)。
9. 加分点
- 可以用 Redis Cluster(集群) 扩展秒杀系统的并发能力
- 秒杀入口要做 限流(Rate Limiting),防止 Redis 被瞬时流量压垮
- 可以配合 延时队列(Delayed Queue) 处理未支付订单的库存回滚
10. Redis 如何实现排行榜功能?
1. 排行榜需求场景
排行榜是很多系统的常见功能,例如:
- 游戏积分榜(Game Score Leaderboard)
- 电商销量榜(Sales Ranking)
- 活动排名(Event Ranking)
特点:
- 按分数排序(Score Sorting)
- 支持实时更新(Real-time Update)
- 支持分页查询(Pagination Query)
- 支持获取某个用户的排名(Get User Rank)
2. Redis 排行榜的核心数据结构
Redis 使用 Sorted Set(有序集合) 来实现排行榜:
- Member:排行榜对象(例如用户 ID)
- Score:排序依据(例如积分、销量)
- Redis 会自动按
score从小到大排序(可以反向查询实现从大到小)
3. 核心命令(带英文全称)
| 功能 | 命令 | 全称(英文补全) | 说明 |
|---|---|---|---|
| 添加/更新分数 | ZADD | Add Member to Sorted Set | 添加成员并设置分数(如果存在则更新分数) |
| 获取排名(升序) | ZRANK | Get Rank of Member | 返回成员的排名(从 0 开始) |
| 获取排名(降序) | ZREVRANK | Get Reverse Rank of Member | 返回成员的排名(从高分到低分) |
| 获取分数 | ZSCORE | Get Score of Member | 返回成员的分数 |
| 获取前 N 名(升序) | ZRANGE | Get Members by Rank Range | 按排名范围返回成员 |
| 获取前 N 名(降序) | ZREVRANGE | Get Members by Reverse Rank Range | 按排名范围返回成员(高分优先) |
| 增加分数 | ZINCRBY | Increment Score of Member | 给成员的分数增加指定值 |
| 删除成员 | ZREM | Remove Member from Sorted Set | 删除排行榜中的成员 |
4. 基本实现流程
添加/更新分数
ZADD game_leaderboard 1500 user:1001
ZADD game_leaderboard 2000 user:1002获取前 3 名(降序)
ZREVRANGE game_leaderboard 0 2 WITHSCORES返回:
1) "user:1002" 2000 2) "user:1001" 1500
获取某个用户的排名
ZREVRANK game_leaderboard user:1001返回:
1
表示第 2 名(因为排名从 0 开始)
5. 进阶玩法
① 分页查询排行榜
ZREVRANGE game_leaderboard 0 9 WITHSCORES # 第 1 页
ZREVRANGE game_leaderboard 10 19 WITHSCORES # 第 2 页
② 获取某个用户的分数
ZSCORE game_leaderboard user:1001③ 增加用户分数
ZINCRBY game_leaderboard 50 user:1001④ 删除用户
ZREM game_leaderboard user:10016. 排行榜的优化策略
| 问题 | 解决方案 |
|---|---|
| 数据量大 | 使用 Redis Cluster(集群)分片存储 |
| 排名实时更新压力大 | 批量更新(Batch Update)或异步更新(Asynchronous Update) |
| 需要多维度排行榜 | 为每个维度建立一个 Sorted Set |
| 需要历史榜单 | 定期将当前榜单备份到新的 key(例如按日期命名) |
7. 案例:游戏积分排行榜
初始化数据:
ZADD game_leaderboard 1500 user:1001
ZADD game_leaderboard 2000 user:1002
ZADD game_leaderboard 1800 user:1003
获取前 2 名:
ZREVRANGE game_leaderboard 0 1 WITHSCORES增加分数:
ZINCRBY game_leaderboard 100 user:1003获取某个用户排名:
ZREVRANK game_leaderboard user:10038. 面试回答示例(带英文全称)
Redis 排行榜功能通常使用 Sorted Set(有序集合) 实现,成员(Member)是排行榜对象,分数(Score)是排序依据。
通过ZADD(Add Member to Sorted Set)添加或更新分数,ZREVRANGE(Get Members by Reverse Rank Range)获取前 N 名,ZREVRANK(Get Reverse Rank of Member)获取某个成员的排名,ZINCRBY(Increment Score of Member)增加分数。
这种方式支持实时更新(Real-time Update)、分页查询(Pagination Query)和多维度排行榜(Multi-dimensional Leaderboard),在游戏积分榜、销量榜等场景中非常高效。
9. 加分点
- Sorted Set 的时间复杂度:
ZADD、ZREM、ZINCRBY是 �(log�)O(logN),ZRANGE是 �(log�+�)O(logN+M) - 可以用 Redis Pipeline(管道) 批量更新分数,减少网络开销
- 如果需要历史榜单,可以每天备份一个 Sorted Set
11. Redis 如何防止缓存穿透、缓存击穿、缓存雪崩?
1. 三个问题的区别
| 问题 | 定义 | 影响 |
|---|---|---|
| 缓存穿透(Cache Penetration) | 请求的数据在缓存(Cache)和数据库(Database)中都不存在,导致每次请求都直接访问数据库 | 数据库压力大,可能被恶意攻击 |
| 缓存击穿(Cache Breakdown) | 某个热点数据(Hot Data)在缓存中过期的瞬间,有大量并发请求直接访问数据库 | 瞬时数据库压力暴增 |
| 缓存雪崩(Cache Avalanche) | 大量缓存数据在同一时间集中失效,导致大量请求直接访问数据库 | 数据库和应用可能直接崩溃 |
2. 缓存穿透(Cache Penetration)
原因
- 请求的 key 在缓存和数据库中都不存在
- 恶意攻击:大量请求不存在的 key
解决方案
缓存空值(Cache Null Value)
- 当数据库返回空结果时,也在缓存中存一个空值,并设置较短的过期时间(TTL, Time To Live)
SET user:1001 "" EX 60- 下次请求直接返回空值,避免访问数据库
布隆过滤器(Bloom Filter)
- 在缓存前加一个布隆过滤器(Bloom Filter),存储所有可能存在的 key
- 如果布隆过滤器判断 key 不存在,直接拦截请求
- 常用命令(Redis Module: RedisBloom):
BF.ADD user_filter 1001 BF.EXISTS user_filter 1001
3. 缓存击穿(Cache Breakdown)
原因
- 热点数据(Hot Data)过期的瞬间,大量并发请求直接访问数据库
解决方案
互斥锁(Mutex Lock)
- 第一个请求发现缓存失效时,加锁(Distributed Lock)去加载数据
- 其他请求等待锁释放后再访问缓存
- Lua 脚本保证加锁和释放锁的原子性(Atomicity)
逻辑过期(Logical Expiration)
- 在缓存中存一个逻辑过期时间字段
- 即使逻辑过期,仍返回旧数据,同时异步更新缓存
{ "data": {...}, "expireTime": 1735660800 }热点数据永不过期(Never Expire Hot Data)
- 对热点数据设置超长 TTL 或不设置过期时间
- 通过异步任务定期更新数据
4. 缓存雪崩(Cache Avalanche)
原因
- 大量缓存数据在同一时间集中失效
- 可能是批量设置了相同的 TTL
解决方案
随机过期时间(Random TTL)
- 设置缓存时,在 TTL 基础上加一个随机值,避免同时失效
SET product:1001 "data" EX 3600+rand(0,600)多级缓存(Multi-level Cache)
- 本地缓存(Local Cache,例如 Caffeine)+ Redis 缓存
- Redis 挂掉时,本地缓存仍可提供部分数据
缓存预热(Cache Pre-warming)
- 系统启动或大促前提前加载热点数据到缓存
降级策略(Degrade Strategy)
- 当缓存不可用时,限制部分功能或返回默认数据
5. 三者对比总结
| 问题 | 触发条件 | 解决方案 |
|---|---|---|
| 缓存穿透(Cache Penetration) | 请求数据不存在 | 缓存空值 / 布隆过滤器 |
| 缓存击穿(Cache Breakdown) | 热点数据过期瞬间 | 互斥锁 / 逻辑过期 / 永不过期 |
| 缓存雪崩(Cache Avalanche) | 大量缓存同时失效 | 随机 TTL / 多级缓存 / 缓存预热 |
6. 面试回答示例(带英文全称)
Redis 在高并发场景下可能遇到三类缓存问题:
缓存穿透(Cache Penetration):请求的数据在缓存和数据库中都不存在,解决方案包括缓存空值(Cache Null Value)和布隆过滤器(Bloom Filter)。
缓存击穿(Cache Breakdown):热点数据过期瞬间大量并发请求直接访问数据库,解决方案包括互斥锁(Mutex Lock)、逻辑过期(Logical Expiration)和热点数据永不过期(Never Expire Hot Data)。
缓存雪崩(Cache Avalanche):大量缓存同时失效导致数据库压力暴增,解决方案包括随机过期时间(Random TTL)、多级缓存(Multi-level Cache)和缓存预热(Cache Pre-warming)。
这些策略结合使用,可以有效保证系统的高可用性(High Availability)和稳定性(Stability)。
7. 加分点
- 布隆过滤器的空间复杂度低,但有一定误判率(False Positive Rate)
- 逻辑过期适合对一致性要求不高的场景
- 多级缓存可以减少 Redis 故障带来的影响
12. Redis 主从复制的原理?
。。。