PostgreSQL 的表继承与分区
一、PostgreSQL 的表继承
PostgreSQL 的表继承(Inheritance)允许一个表“继承”另一个表的结构和约束,就像子类继承父类的属性一样。
换句话说,子表会自动拥有父表的所有列定义(字段),并且可以新增自己的字段。同时,查询父表时,也可以选择是否自动包含子表中的数据。
其基本语法如下:
CREATE TABLE 子表 (子表自有字段 数据类型,...
) INHERITS (父表);
表继承示例
假设我们有一个电商平台,商品分为三类:
- 普通商品(normal_product)
- 电子商品(digital_product)
- 生鲜商品(fresh_product)
三者都共有基础字段:id, name, price,但子类商品有各自特有的属性。
定义父表(通用商品表)
CREATE TABLE products (id SERIAL PRIMARY KEY,name TEXT NOT NULL,price NUMERIC(10, 2) NOT NULL,created_at TIMESTAMP DEFAULT now()
);
父表定义所有商品的公共字段。
定义子表(继承父表)
-- 电子商品表
CREATE TABLE digital_products (file_size_mb INT,download_url TEXT
) INHERITS (products);-- 生鲜商品表
CREATE TABLE fresh_products (expiration_date DATE,storage_temp TEXT
) INHERITS (products);
每个子表通过
INHERITS(products) 继承父表字段。
插入数据
INSERT INTO products (name, price) VALUES ('普通鼠标', 39.9);INSERT INTO digital_products (name, price, file_size_mb, download_url)
VALUES ('课程:PostgreSQL指南', 99.0, 512, 'https://example.com/pg-course');INSERT INTO fresh_products (name, price, expiration_date, storage_temp)
VALUES ('火龙果', 5.5, '2025-11-10', '0-5°C');查询数据
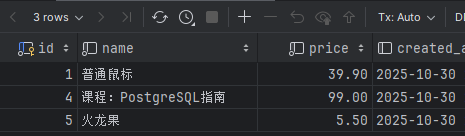
(1)查询父表(默认包含子表数据)
SELECT id, name, price, created_at FROM products;
结果包含所有三类商品:
(2)只查询父表自身数据
SELECT * FROM ONLY products;
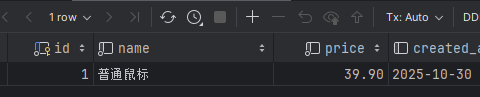
仅返回普通商品(不含继承表)。
查看继承关系
\d+ products

继承的特性与限制
- 数据隔离:子表的数据物理上存储在自己的表空间中,与父表分离。
- 约束继承:CHECK约束会被子表继承,但主键、外键、唯一约束和索引不会自动继承。
- 多表继承:一个表可以同时继承多个父表(多继承),继承所有父表的列。
继承的典型应用场景
- 商品分类存储:将不同类别的商品(如电子产品、服装、图书)存储在不同的子表中,但通过 products 父表统一查询所有商品。
- 权限管理:为不同类别的商品表设置不同的访问权限,同时保持统一的查询接口。
- 逻辑分组:在应用层实现多态行为,如不同类型的“商品”共享基础字段
二、PostgreSQL表分区
随着数据量的增长,单表性能会成为瓶颈。从 PostgreSQL10 开始引入表分区,专为性能和可维护性设计,它将一个大表逻辑上分为多个子表(分区),但对外表现为单一表,极大提升了查询性能和管理效率。
分区类型
PostgreSQL 当前主要支持四种分区类型,每种类型适用于不同的业务场景:
| 分区类型 | 定义关键字 | 说明 | 常见应用场景 |
|---|---|---|---|
| 范围分区(Range) | PARTITION BY RANGE(column) | 按某个列的值范围(区间)划分数据 | 按时间、ID、价格等连续字段分表,如日志表、订单表 |
| 列表分区(List ) | PARTITION BY LIST(column) | 按枚举值列表划分数据 | 按国家、地区、商品类型等分类,如按国家分库 |
| 哈希分区(Hash) | PARTITION BY HASH(column) | 通过哈希函数对列进行取模划分 | 数据分布均匀、负载均衡的场景,如用户ID分区 |
| 复合分区(Subpartitioning) | 嵌套定义(如 PARTITION BY RANGE + PARTITION BY LIST) | 在一级分区的基础上再细分子分区 | 大型系统中的层级分区,如时间 + 地区双维度划分 |
分区示例(RANGE )
例如我们可以按商品上架年份进行分区。
定义分区表(主表)
CREATE TABLE products_partitioned (id BIGINT GENERATED ALWAYS AS IDENTITY,name TEXT NOT NULL,price NUMERIC(10,2) NOT NULL,created_at DATE NOT NULL,PRIMARY KEY (id, created_at) -- 注意:包含了分区键 created_at
) PARTITION BY RANGE (created_at);
创建各个分区表
CREATE TABLE products_2024 PARTITION OF products_partitionedFOR VALUES FROM ('2024-01-01') TO ('2025-01-01');CREATE TABLE products_2025 PARTITION OF products_partitionedFOR VALUES FROM ('2025-01-01') TO ('2026-01-01');
插入数据(自动路由)
INSERT INTO products_partitioned (name, price, created_at)
VALUES ('电动牙刷', 199.0, '2024-06-01');INSERT INTO products_partitioned (name, price, created_at)
VALUES ('蓝牙耳机', 299.0, '2025-03-15');
查询与优化
SELECT * FROM products_partitioned WHERE created_at >= '2025-01-01';
查看分区结构
\d+ products_partitioned
你会看到类似输出:
Partition key: RANGE (created_at)
Indexes:"products_partitioned_pkey" PRIMARY KEY, btree (id, created_at)
Partitions: products_2024 FOR VALUES FROM ('2024-01-01') TO ('2025-01-01'),products_2025 FOR VALUES FROM ('2025-01-01') TO ('2026-01-01')
说明
在PostgreSQL中,分区表的主键或唯一约束必须包含所有分区键列,否则会出现:
ERROR: unique constraint on partitioned table must include all partitioning columns
三、继承VS分区:区别总结
| 对比维度 | 表继承(Inheritance) | 表分区(Partitioning) |
|---|---|---|
| 设计目的 | 逻辑数据模型扩展 | 性能优化与数据管理 |
| 定义语法 | INHERITS | PARTITION BY |
| 查询行为 | 父表聚合所有子表 | 自动分区路由 |
| 约束继承 | 不会自动继承 | 系统自动管理 |
| 主键要求 | 可独立定义 | 必须包含分区列 |
| 应用场景 | 业务类型区分 | 大表按时间/范围拆分 |
使用建议总结:
如果你是为了“性能”和“可维护性”拆分数据 → 用分区;
如果是为了“逻辑建模”或“多态”而组织数据 → 才考虑继承(但需谨慎,维护成本高,易出错)。