外贸网站平台下载内网建站教程
一、负采样
基本思想:
在训练过程中,对于每个正样本(中心词和真实上下文词组成的词对),随机采样少量(如5-20个)负样本(中心词与非上下文词组成的词对)。
模型通过区分正样本和负样本来更新词向量,而非计算整个词汇表的概率分布。
实现方式:
将原始的多分类问题(预测所有可能的上下文词)转化为二分类问题,判断词对是否属于真实上下文。
例如,对于正样本(“猫”, “跳”),模型应输出1;对于负样本(“猫”, “苹果”),模型应输出0。
采样策略:
负样本通常根据词频进行采样,高频词更可能被选为负样本。
为平衡常见词和罕见词,采用词频的3/4次方进行平滑(如“苹果”比“袋熊”更容易被采样)。
为什么需要负采样?
解决计算瓶颈:
传统Softmax需要计算词汇表中所有词的得分并归一化,时间复杂度为O(V)(V为词汇表大小)。当VV达到百万级时,计算代价极高。
负采样将计算复杂度降至O(K+1)(K为负样本数,通常远小于VV),显著提升训练速度。
提升模型效果:
通过强制模型区分少量有代表性的负样本(如高频词),词向量的语义区分能力更强。
相比原始的层次Softmax等优化方法,负采样更简单且效果更好,尤其适合大规模数据。
避免梯度稀疏性:
传统方法中,每次仅更新正样本对应的权重,导致大部分词向量缺乏有效更新。
负采样让更多词(正样本+负样本)参与参数更新,提升训练稳定性。

二、CBOW + 负采样(negative sampling)
2.1、词划分
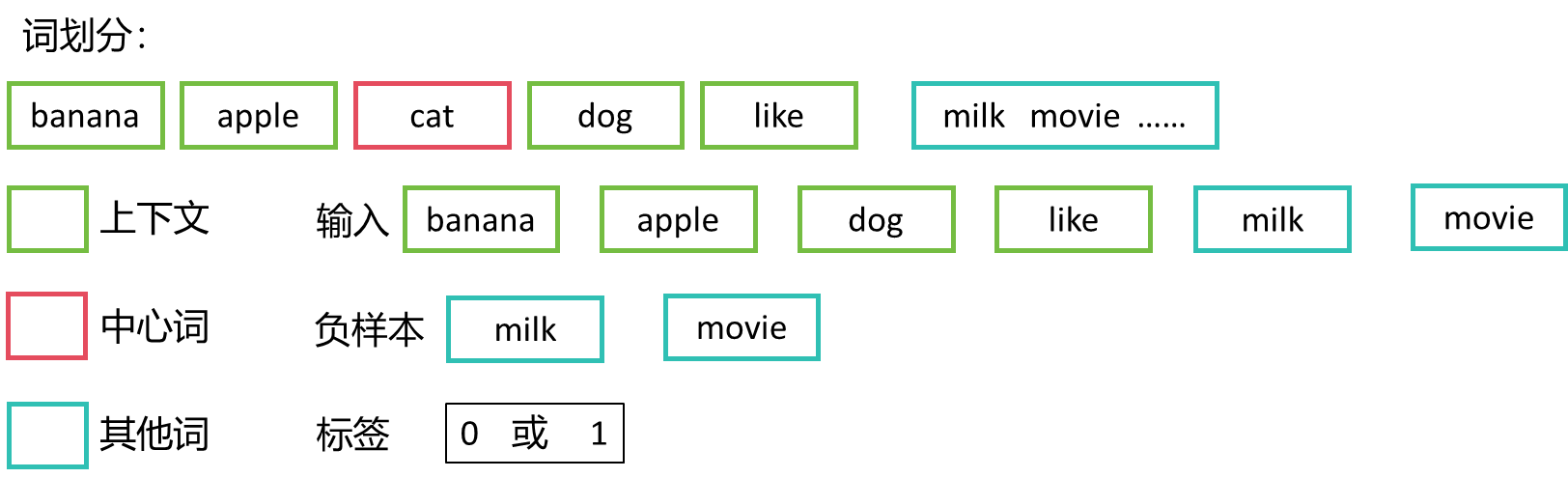
2.2、过程
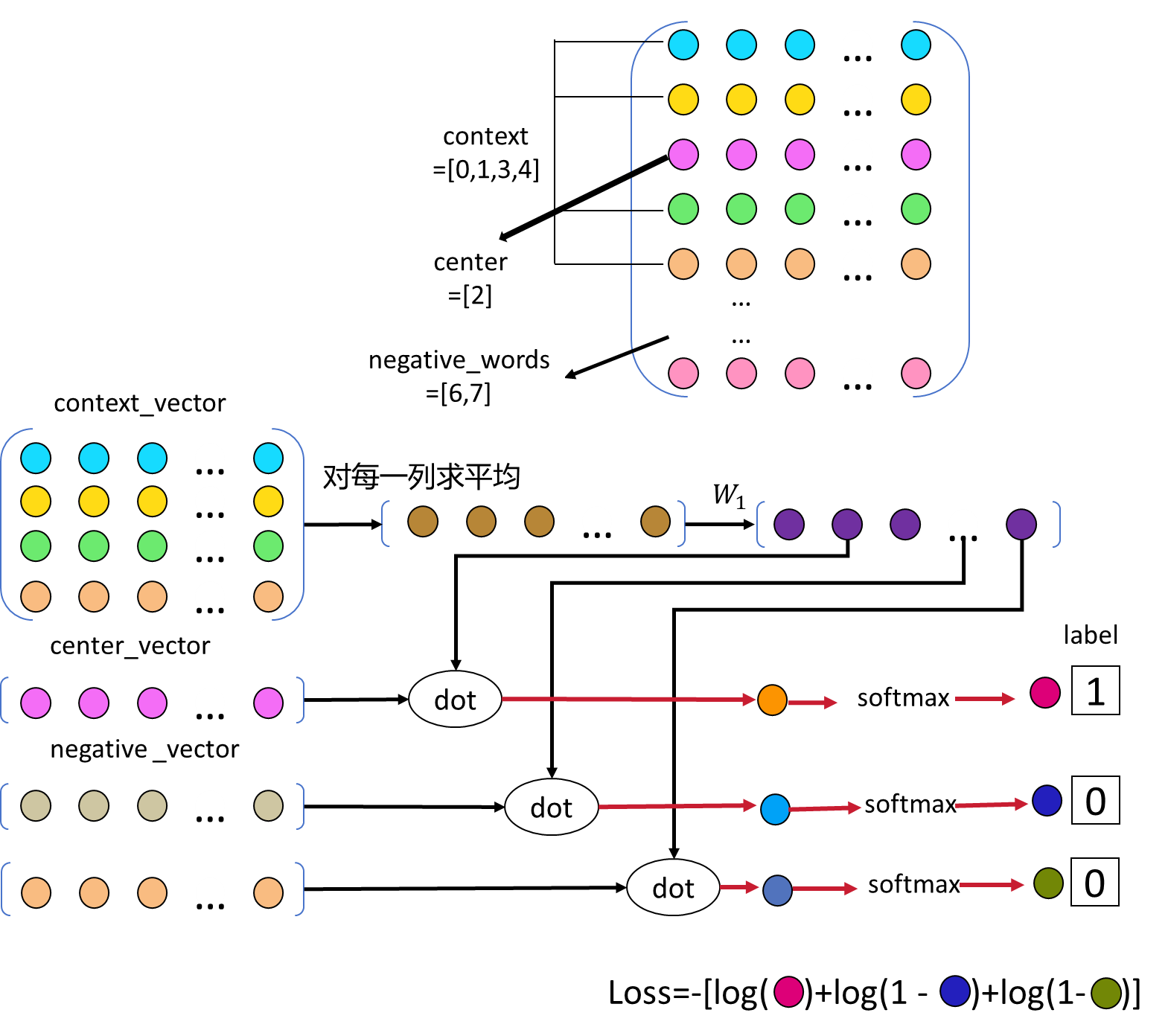
要确定模型对上下文预测的词究竟是真正的中心词还是负样本。
如果是真正的中心词,预测结果为1;如果是负样本,预测结果为0。
词向量的重要作用之 一是通过运算揭示词与词之间的关系或相似度。点积是衡量两个向量相似度的一种方 式,因此只需将预测结果与真正的中心词和负样本的词向量进行点积,再通过 softmax转换为概率,就可以得到0或1的预测结果,从而实现二分类。
总体来说,模型的输入包括三个部分:上下文、中心词和负样本。这三个输入根据字 典中的value作为索引,从嵌入矩阵中取得相应的词向量。然后,对于上下文的处 理,类似于原始的CBOW模型,进行平均操作,接着经过线性层。随后,分别将结果 与中心词和负样本的词向量进行点积,最终与实际的标签进行二分类交叉熵计算。将 这些损失加总,得到总体的损失。
import os
import random
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
from collections import Counter
import redef setup_seed(seed):np.random.seed(seed) # Numpy module.random.seed(seed) # Python random module.os.environ['PYTHONHASHSEED'] = str(seed)torch.manual_seed(seed)if torch.cuda.is_available():torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deterministic = Truesetup_seed(0)
# 数据预处理
corpus = ["jack like dog", "jack like cat", "jack like animal","dog cat animal", "banana apple cat dog like", "dog fish milk like","dog cat animal like", "jack like apple", "apple like", "jack like banana","apple banana jack movie book music like", "cat dog hate", "cat dog like"
]# 将句子分词,并转换为小写
def tokenize(sentence):# \b 单词的边界# \w+ 匹配一个或者多个单词字符(字母,数字,下划线)# \[,.!?] 匹配逗号、句号、感叹号和问号word_list = []for word in re.findall(r"\b\w+\b|[,.!?]", sentence):word_list.append(word.lower())return word_listwords = []
for sentence in corpus:for word in tokenize(sentence):words.append(word)# print(words)
word_counts = Counter(words)vocab = sorted(word_counts, key=word_counts.get, reverse=True)
# print(vocab)# {"like": 1, "dog": 2}
# 创建词汇表到索引的隐射
vocab2int = {word: ii for ii, word in enumerate(vocab, 1)}
# print(vocab2int)
# 将所有的单词转换为索引表示
int2vocab = {ii: word for ii, word in enumerate(vocab, 1)}
# print(int2vocab)# 将所有单词变成索引
word2index = [vocab2int[word] for word in words]
# print(word2index)
window = 1
center = []
context = []
negative_samples = []
num_negative_samples = 2
vocab_size = len(vocab2int) + 1 # 词汇表大小for i, target in enumerate(word2index[window: -window], window):# print(i, target)# 数据:3 1 2 3 1 4# 索引:0 1 2 3 4 5center.append(target)con = word2index[i - window: i] + word2index[i + 1: i + 1 + window]context.append(word2index[i - window: i] + word2index[i + 1: i + 1 + window])# 生成负样本,确保不包括中心词和上下文negative_samples_i = []for _ in range(num_negative_samples):#2negative_sample = np.random.choice(range(1,vocab_size))while negative_sample == target or negative_sample in con:negative_sample = np.random.choice(range(1,vocab_size))negative_samples_i.append(negative_sample)negative_samples.append(negative_samples_i)# 特殊标记:0,用于填充或者标记未知单词
# <SOS>: 句子起始标识符
# <EOS>:句子结束标识符
# <PAD>:补全字符
# <MASK>:掩盖字符
# <SEP>:两个句子之间的分隔符
# <UNK>:低频或未出现在词表中的词
# vocab_size = len(vocab2int) + 1 # 词汇表大小
embedding_dim = 2 # 嵌入维度class CBOWModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOWModel, self).__init__()# self.embeddings = nn.Parameter(torch.randn(vocab_size, embedding_dim)) # 初始化embedding矩阵self.embeddings = nn.Embedding(vocab_size, embedding_dim) # 初始化embedding矩阵print(self.embeddings)self.linear = nn.Linear(embedding_dim, vocab_size) # vocab_size = 14def forward(self, context):# context.shape -> [bs, 2]context_emb = self.embeddings(context) # 上下文的嵌入向量# print(context_emb.shape) # torch.Size([4, 2, 2])avg_emb = torch.mean(context_emb, dim=1, keepdim=True).squeeze(1)y = self.linear(avg_emb)return ymodel = CBOWModel(vocab_size, embedding_dim)
cri = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)bs = 4
epochs = 2000
for epoch in range(1, epochs + 1):total_loss = 0for batch_index in range(0, len(context), bs):# 上下文的Tensor # torch.Size([4, 2])context_tensor = torch.tensor(context[batch_index: batch_index + bs])# 中心词的tensor torch.Size([4, 1])center_tensor = torch.tensor(center[batch_index: batch_index + bs]).view(bs, 1)# 负样本的tensor torch.Size([4, 2])negative_tensor = torch.tensor(negative_samples[batch_index: batch_index + bs])# 正样本# 第一维 4 表示批次中的样本数。第二维 2 表示上下文窗口的大小,即每个中心词有两个上下文词。第三维 2 表示嵌入向量的维度(embedding dimension)。# print("context_emb", context_emb.shape) # torch.Size([4, 2, 2])context_emb = model.embeddings(context_tensor)# 第一维 4 表示批次中的样本数。第二维 2 表示嵌入向量的维度。# print("center_emb", center_emb.shape) # torch.Size([4, 2])center_emb = model.embeddings(center_tensor).squeeze(1)# 将多个上下文词的嵌入向量平均化,从而得到每个样本的平均上下文嵌入向量。这有助于简化计算,并能更好地表示上下文的总体信息。avg_context_emb = torch.mean(context_emb, dim=1) # avg_context_emb 的形状是 [4, 2]"""例如:context_emb = torch.tensor([[[0.1, 0.2], [0.3, 0.4]],[[0.5, 0.6], [0.7, 0.8]],[[0.9, 1.0], [1.1, 1.2]],[[1.3, 1.4], [1.5, 1.6]]])通过执行 avg_context_emb = torch.mean(context_emb, dim=1),我们在 context_window_size 维度上取平均值:对第一个样本:[(0.1 + 0.3)/2, (0.2 + 0.4)/2] = [0.2, 0.3]对第二个样本:[(0.5 + 0.7)/2, (0.6 + 0.8)/2] = [0.6, 0.7]对第三个样本:[(0.9 + 1.1)/2, (1.0 + 1.2)/2] = [1.0, 1.1]对第四个样本:[(1.3 + 1.5)/2, (1.4 + 1.6)/2] = [1.4, 1.5]avg_context_emb = torch.tensor([[0.2, 0.3],[0.6, 0.7],[1.0, 1.1],[1.4, 1.5]])avg_context_emb 的形状变为 [4, 2],2表示每个样本的平均上下文嵌入向量。"""positive_scores = torch.matmul(avg_context_emb, center_emb.t())# 第一维 4 批次中的样本数(batch size)。第二维 4 与批次中的每一个中心词的相似性分数。# positive_scores[i, j] 表示第 i 个样本的平均上下文嵌入与第 j 个样本的中心词嵌入之间的相似性分数。# print("positive_scores", positive_scores.shape) # torch.Size([4, 4])# positive_labels = torch.ones_like(positive_scores)positive_labels = torch.eye(bs) # 生成对角线为1的标签矩阵positive_loss = cri(positive_scores, positive_labels)# 负样本# negative_emb.shape [batch_size, num_negative_samples, embedding_dim]:[4, 2, 2]negative_emb = model.embeddings(negative_tensor)# avg_context_emb->[batch_size, embedding_dim] avg_context_emb.unsqueeze(1)->[batch_size, 1, embedding_dim]# negative_emb.permute(0, 2, 1) -> [batch_size, embedding_dim, num_negative_samples]# torch.matmul() -> [batch_size, 1, num_negative_samples]# 通过 squeeze(1) 去掉维度1,得到 negative_scores 的形状是 [batch_size, num_negative_samples]。# 每个中心词与其负样本(negative)之间的相似性negative_scores = torch.matmul(avg_context_emb.unsqueeze(1), negative_emb.permute(0, 2, 1)).squeeze(1)negative_labels = torch.zeros_like(negative_scores)negative_loss = cri(negative_scores, negative_labels)loss = positive_loss + negative_losstotal_loss += lossoptimizer.zero_grad()loss.backward()optimizer.step()avg_loss = total_loss / len(context)if epoch == 1 or epoch % 50 == 0:print(f"Epoch [{epoch}/{epochs}] Loss {avg_loss:.4f}")# 每个单词的embedding向量word_vec = model.embeddings.weight.detach().numpy()# print(word_vec)x = word_vec[:, 0]y = word_vec[:, 1]selected_word = ["dog", "cat", "milk", "like", "animal", "fish", "banana", "apple"]selected_word_index = [vocab2int[word] for word in selected_word]selected_word_x = x[selected_word_index]selected_word_y = y[selected_word_index]plt.cla()plt.scatter(selected_word_x, selected_word_y, color="blue")# 将每个点的标注加上for word, x, y in zip(selected_word, selected_word_x, selected_word_y):plt.annotate(word, (x, y), textcoords="offset points", xytext=(0, 10))plt.pause(0.5)plt.show()
三、Skip-gram + 负采样(negative sampling)
3.1、词划分

3.2、过程
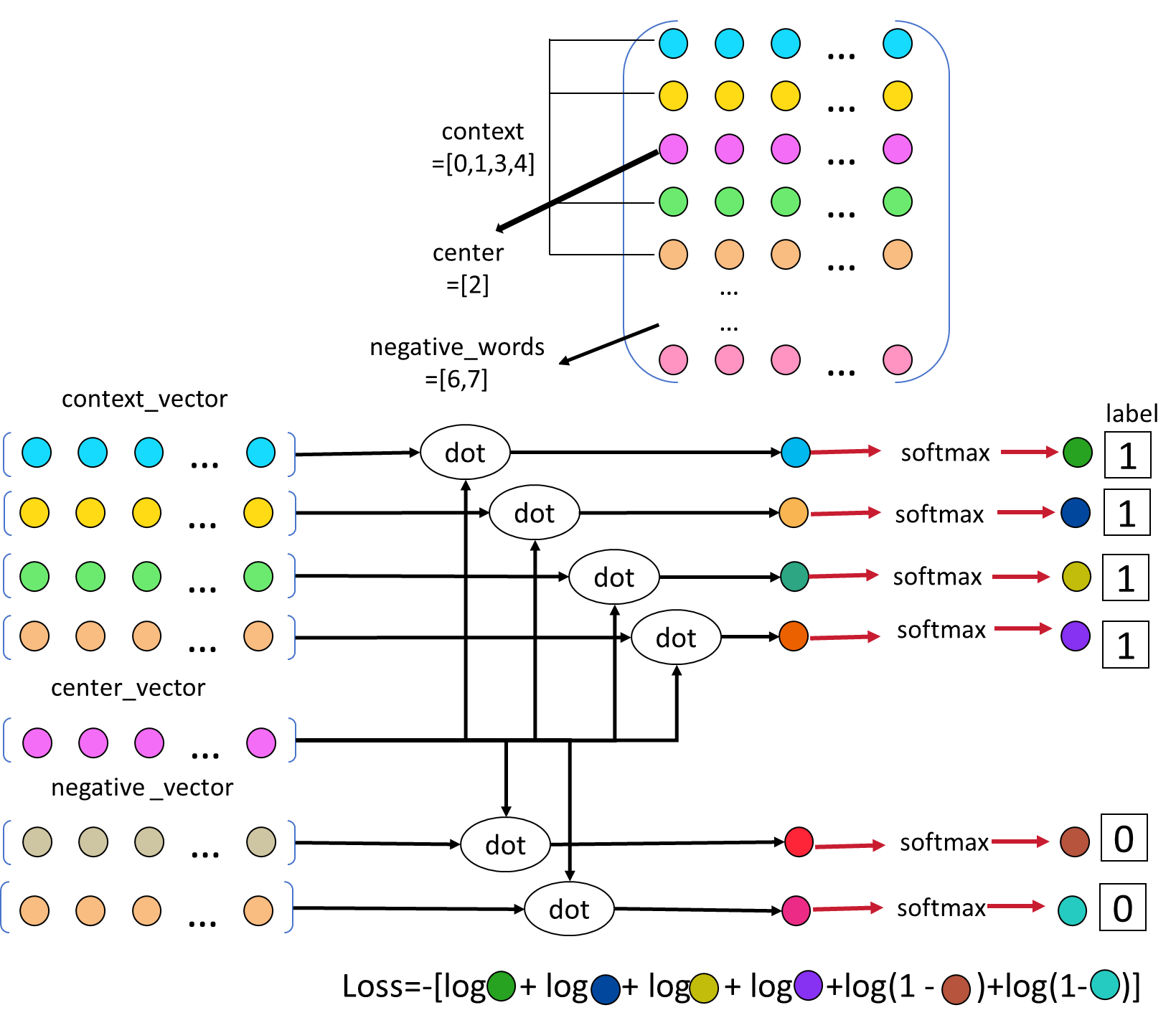
要确定模型对中心词预测的词究竟是真正的上下文还是负样本。
如果是真正的上下文,预测结果为1;如果是负样本,预测结果为0。
点积是衡量两个向量相似度的一种方式,因此只需将预测结果与真正的上下文和负样 本的词向量进行点积,再通过softmax转换为概率,就可以得到0或1的预测结果,从 而实现二分类。
所以,模型的输入包括三个部分:上下文、中心词和负样本。这三个输入根据字典中 的value作为索引,从嵌入矩阵中取得相应的词向量。然后,对于中心词的处理,类 似于原始的Skip-gram模型,进行复制操作,接着经过线性层。随后,分别将结果与 上下文和负样本的词向量进行点积,最终与实际的标签进行二分类交叉熵计算。
最后将这些损失加总,得到总体的损失。
import torch
import torch.nn as nn
import torch.optim as optimimport matplotlib.pyplot as plt
import numpy as np
from collections import Counter
from scipy.spatial.distance import cosine
import re# 数据预处理
corpus = ["jack like dog", "jack like cat", "jack like animal","dog cat animal", "banana apple cat dog like", "dog fish milk like","dog cat animal like", "jack like apple", "apple like", "jack like banana","apple banana jack movie book music like", "cat dog hate", "cat dog like"
]# 将句子分词,并转换为小写
def tokenize(sentence):word_list = []for word in re.findall(r"\b\w+\b|[,.!?]", sentence):word_list.append(word.lower())return word_listwords = []
for sentence in corpus:for word in tokenize(sentence):words.append(word)word_counts = Counter(words)vocab = sorted(word_counts, key=word_counts.get, reverse=True)# 创建词汇表到索引的隐射
vocab2int = {word: ii for ii, word in enumerate(vocab, 1)}
int2vocab = {ii: word for ii, word in enumerate(vocab, 1)}# 将所有单词变成索引
word2index = [vocab2int[word] for word in words]
window = 1
center = []
context = []
negative_samples = []
num_negative_samples = 2
vocab_size = len(vocab2int) + 1 # 词汇表大小for i, target in enumerate(word2index[window: -window], window):center.append(target)con = word2index[i - window: i] + word2index[i + 1: i + 1 + window]context.append(word2index[i - window: i] + word2index[i + 1: i + 1 + window])# 生成负样本,确保不包括中心词和上下文negative_samples_i = []for _ in range(num_negative_samples):negative_sample = np.random.choice(range(1,vocab_size))while negative_sample == target or negative_sample in con:negative_sample = np.random.choice(range(1,vocab_size))negative_samples_i.append(negative_sample)negative_samples.append(negative_samples_i)torch.manual_seed(10)embedding_dim = 2 # 嵌入维度class SkipGramModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(SkipGramModel, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim)self.linear = nn.Linear(embedding_dim, vocab_size)def forward(self, center):center_emb = self.embeddings(center)y = self.linear(center_emb)return ymodel = SkipGramModel(vocab_size, embedding_dim)
cri = nn.BCEWithLogitsLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)bs = 4
epochs = 2000
for epoch in range(1, epochs + 1):total_loss = 0for batch_index in range(0, len(center), bs):center_tensor = torch.tensor(center[batch_index: batch_index + bs]).view(bs, 1)context_tensor = torch.tensor(context[batch_index: batch_index + bs])negative_tensor = torch.tensor(negative_samples[batch_index: batch_index + bs])# 在 CBOW 模型中,计算的是平均上下文嵌入与中心词嵌入之间的相似性,得到的 positive_scores 的形状是 [batch_size, batch_size]。# 在 Skip-gram 模型中,计算的是每个中心词与其上下文词之间的相似性,得到的 positive_scores 的形状是 [batch_size, num_context_samples]。# 正样本# 第一维 4 表示批次中的样本数。第二维 2 表示上下文窗口的大小,即每个中心词有两个上下文词。第三维 2 表示嵌入向量的维度(embedding dimension)。# print("context_emb", context_emb.shape) # torch.Size([4, 2, 2])context_emb = model.embeddings(context_tensor)# 第一维 4 表示批次中的样本数。第二维 2 表示嵌入向量的维度。# print("center_emb", center_emb.shape) # torch.Size([4, 2])center_emb = model.embeddings(center_tensor).squeeze(1)# center_emb->[batch_size, embedding_dim] center_emb.unsqueeze(1)->[batch_size, 1, embedding_dim]# context_emb.permute(0, 2, 1) -> [batch_size, embedding_dim, num_context_samples]# torch.matmul() -> [batch_size, 1, num_context_samples]# 通过 squeeze(1) 去掉维度1,得到 negative_scores 的形状是 [batch_size, num_context_samples]positive_scores = torch.matmul(center_emb.unsqueeze(1), context_emb.permute(0, 2, 1)).squeeze(1)print("positive_scores:", positive_scores.shape)positive_labels = torch.ones_like(positive_scores)positive_loss = cri(positive_scores, positive_labels)# 负样本# negative_emb.shape [batch_size, num_negative_samples, embedding_dim]:[4, 2, 2]negative_emb = model.embeddings(negative_tensor)# center_emb->[batch_size, embedding_dim] center_emb.unsqueeze(1)->[batch_size, 1, embedding_dim]# negative_emb.permute(0, 2, 1) -> [batch_size, embedding_dim, num_negative_samples]# torch.matmul() -> [batch_size, 1, num_negative_samples]# 通过 squeeze(1) 去掉维度1,得到 negative_scores 的形状是 [batch_size, num_negative_samples]negative_scores = torch.matmul(center_emb.unsqueeze(1), negative_emb.permute(0, 2, 1)).squeeze(1)negative_labels = torch.zeros_like(negative_scores)negative_loss = cri(negative_scores, negative_labels)loss = positive_loss + negative_losstotal_loss += lossoptimizer.zero_grad()loss.backward()optimizer.step()avg_loss = total_loss / len(center)if epoch == 1 or epoch % 50 == 0:print(f"Epoch [{epoch}/{epochs}] Loss {avg_loss:.4f}")# 每个单词的embedding向量word_vec = model.embeddings.weight.detach().numpy()# print(word_vec)x = word_vec[:, 0]y = word_vec[:, 1]selected_word = ["dog", "cat", "milk", "like", "animal", "fish", "banana", "apple"]selected_word_index = [vocab2int[word] for word in selected_word]selected_word_x = x[selected_word_index]selected_word_y = y[selected_word_index]plt.cla()plt.scatter(selected_word_x, selected_word_y, color="blue")# 将每个点的标注加上for word, x, y in zip(selected_word, selected_word_x, selected_word_y):plt.annotate(word, (x, y), textcoords="offset points", xytext=(0, 10))plt.pause(0.5)plt.show()四、函数解释
self.embeddings = nn.Embedding(vocab_size, embedding_dim) 和 self.embeddings = nn.Parameter(torch.randn(vocab_size, embedding_dim)) 是实现词嵌入的两种不同方式。它们的主要区别在于功能和用法。
4.1、nn.Embedding
self.embeddings = nn.Embedding(vocab_size, embedding_dim)| 功能 | 是 PyTorch 中专门用来做嵌入查找 (embedding lookup)的层。它接受整数索引并返回相应的嵌入向 量。 |
| 特性 | 自动处理输入的索引值并查找相应的嵌入向量 支持 padding 索引,用于处理变长序列 提供了权重初始化选项 |
| 代码简洁 | 可以简化代码,因为它封装了嵌入查找 的逻辑。 |
import torch
from torch import nn
class CBOWModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOWModel, self).__init__()self.embeddings = nn.Embedding(vocab_size, embedding_dim)self.linear = nn.Linear(embedding_dim, vocab_size)def forward(self, context):context_emb = self.embeddings(context)avg_emb = torch.mean(context_emb, dim=1, keepdim=True).squeeze(1)y = self.linear(avg_emb)return y
4.2、nn.Parameter
self.embeddings = nn.Parameter(torch.randn(vocab_size,embedding_dim))| 功能 | 是一个张量,它被视为模块的一部分,可以被训 练。它只是一个可训练的张量,没有任何额外的功能。 |
| 特性 | 需要手动实现嵌入查找的逻辑。 更加灵活,可以完全自定义嵌入查找的过程。 适合需要对嵌入层进行更多自定义操作的情况。 |
import torch
from torch import nn
class CBOWModel(nn.Module):def __init__(self, vocab_size, embedding_dim):super(CBOWModel, self).__init__()self.embeddings = nn.Parameter(torch.randn(vocab_size, embedding_dim))self.linear = nn.Linear(embedding_dim, vocab_size)def forward(self, context):context_emb = self.embeddings(context)avg_emb = torch.mean(context_emb, dim=1, keepdim=True).squeeze(1)y = self.linear(avg_emb)return y
4.3、使用上的区别
嵌入查找
nn.Embedding 自动处理输入索引并查找嵌入向量。
使用 nn.Parameter 时,需要手动实现索引查找。
功能
nn.Embedding 提供了很多方便的功能,比如处理 padding 索 引、权重初始化等。
nn.Parameter 只是一个可训练的张量,需要手动实现所有功能。