特征选择之特征重要性排序(基于树模型)
系列文章目录
第一章 特征选择之相关性分析
第二章 特征选择之卡方检验
第三章 特征选择之递归特征消除(REF)
第四章 特征选择之特征重要性排序(基于树模型)
文章目录
系列文章目录
前言
一、特征重要性排序是什么?
二、特征重要性排序原理以及分析
1.原理
2.分析
三、使用自有数据集的代码实现
1、代码
2、效果图以及结果
四、使用在线公有数据集的代码实现
1、代码
2、效果图以及结果
总结
前言
特征选择在机器学习中起着至关重要的作用,它能够帮助我们理解哪些特征对于模型的预测起到关键作用,从而提高模型的泛化能力和解释性。在基于树模型的特征选择中,特征重要性排序是一种常用的方法,通过评估每个特征对模型预测结果的贡献程度来进行排序。通过对特征重要性进行排序,我们可以快速识别哪些特征对模型性能的提升具有重要作用,进而在模型训练的过程中更加关注和优化这些重要特征。
一、特征重要性排序是什么?
特征重要性排序是指在机器学习任务中,对输入特征进行排序,以确定哪些特征最能影响模型的预测能力。这种排序可以帮助我们了解哪些特征对于模型的性能最为关键,从而帮助我们进行特征选择和优化模型。常用的方法包括使用随机森林、梯度提升树等模型计算特征的重要性得分,然后对这些分数进行排序。
二、特征重要性排序原理以及分析
1.原理
其本质是一种嵌入式方法,嵌入式方法结合了过滤方法(卡方检验)和包装方法(递归特征消除)的优点,它通过在训练过程中自动进行特征选择,它不仅考虑特征与目标变量的相关性,还考虑特征与特征之间的相互关系。是可以在训练过程中自动进行特征选择,不需要单独的特征选择步骤,且能够考虑特征之间的关系。
2.分析
特征重要性排序介绍的是使用随机森林一种集成学习方法,它通过多棵决策树的训练,能够通过特征重要性评分来进行特征选择。特征重要性通常基于每个特征在树的构建过程中对模型性能的贡献。
三、使用自有数据集的代码实现
1、代码
import matplotlib
matplotlib.use('TkAgg')
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
# 设置字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 读取文件
df = pd.read_excel('C:/Users/LENOVO/Desktop/单因素.xlsx')
# 确定特征和目标变量,排除住院号列
target_column = '结局'
X = df.drop(columns=['住院号', target_column])
y = df[target_column]
# 创建随机森林模型
model = RandomForestClassifier()
model.fit(X, y)
# 获取特征重要性
feature_importances = pd.Series(model.feature_importances_, index=X.columns)
print(feature_importances)
# 绘制特征重要性图
plt.figure(figsize=(10, 6))
feature_importances.nlargest(len(X.columns)).plot(kind='barh')
plt.title('Feature Importance')
plt.xlabel('Importance Score')
plt.ylabel('Features')
plt.show()2、效果图以及结果
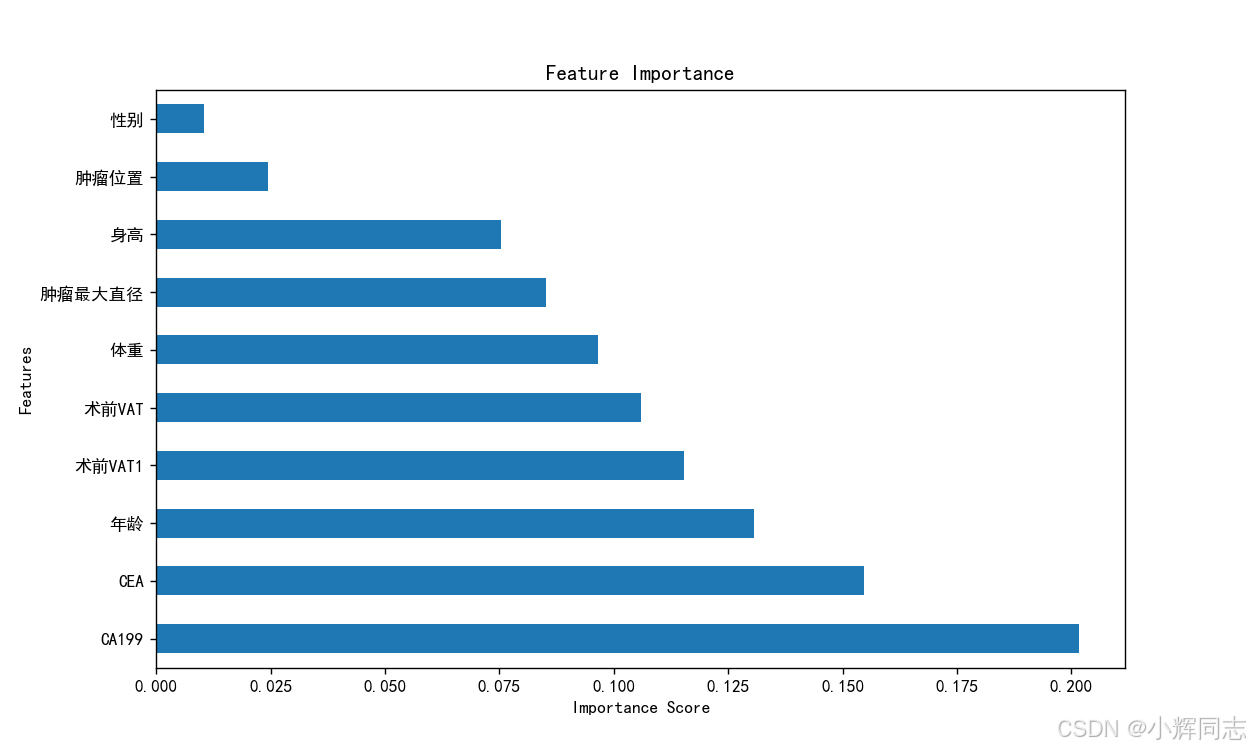
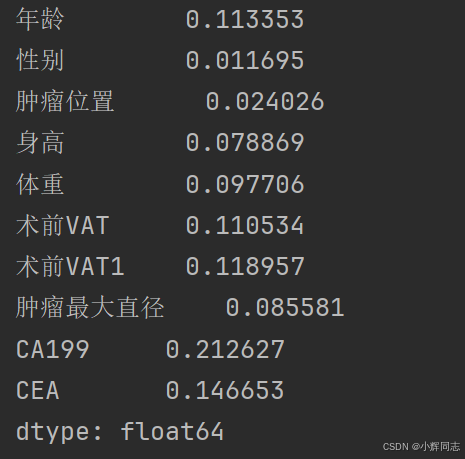
四、使用在线公有数据集的代码实现
1、代码
import matplotlib
matplotlib.use('TkAgg')
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据集
data = load_iris()
X = data.data
y = data.target
# 创建随机森林模型
model = RandomForestClassifier()
model.fit(X, y)
# 获取特征重要性
feature_importances = pd.Series(model.feature_importances_, index=data.feature_names)
# 绘制特征重要性图
feature_importances.nlargest(4).plot(kind='barh')
plt.title('Feature Importance')
plt.show()
print(feature_importances)2、效果图以及结果

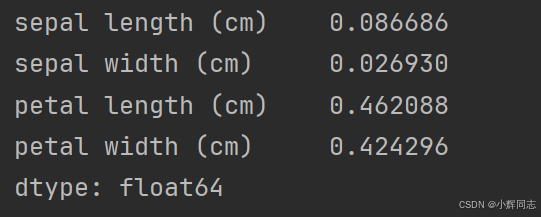
总结
特征选择是机器学习中非常重要的一环,可以帮助提高模型的预测性能并降低过拟合的风险。其中,基于树模型的特征重要性排序是一种常见的方法。以下是特征选择之特征重要性排序(基于树模型)的总结:
-
基本原理:基于树模型的特征重要性排序是通过分析每个特征在构建决策树过程中的贡献程度来确定特征的重要性。通常,特征重要性可以通过节点分裂时的信息增益、基尼系数或者均方误差等指标来计算。
-
优点:基于树模型的特征重要性排序方法简单直观,能够很好地揭示特征对模型的影响程度。此外,这种方法可以帮助筛选出最具代表性的特征,有效降低模型的复杂性和提高预测性能。
-
常用算法:常见的基于树模型的特征重要性排序算法包括随机森林(Random Forest)、梯度提升树(Gradient Boosting Tree)等。这些算法通过多棵决策树的集成学习,能够更准确地评估特征的重要性。
-
结果解释:特征重要性排序的结果通常以排名的形式呈现,数值越高的特征越重要。通过分析这些结果,可以帮助我们理解数据集中哪些特征对模型的预测能力有着重要的贡献,进而指导特征选择和模型优化的工作。
-
注意事项:在使用基于树模型的特征重要性排序时,需要注意过拟合和样本不平衡的问题。此外,对于高维数据集,可以考虑结合特征选择算法进行进一步筛选,以提高模型的泛化能力。
总的来说,基于树模型的特征重要性排序是一种有效的特征选择方法,可以帮助我们识别关键特征、降低模型的复杂性,并提高预测性能。在实际应用中,结合领域知识和模型评估结果,能够更好地利用特征重要性排序结果指导特征工程和模型优化的过程。