做网络平台的网站公司网站建设的方案
目录
ASR
Zipformer模型详解
模型结构:U-Net 式降采样与 Zip Block 设计
1. 整体架构:多尺度特征建模
2. 核心模块:Zip Block 的 “权重复用” 机制
关键技术创新:从细节优化到范式突破
BiasNorm:保留长度信息的归一化方法
Swoosh 激活函数:解决梯度消失与参数更新不稳定
ScaledAdam 优化器:平衡不同参数的更新幅度
激活值限制:保障模型的收敛效率与推理鲁棒性
Zipformer是新一代kaldi团队最新研发的序列建模模型。 相比较于Conformer、Squeezeformer、E-Branchformer等主流ASR模型,Zipformer具有效果更好、计算更快、更省内存等优点。 Zipformer在LibriSpeech、Aishell-1和WenetSpeech等常用数据集上取得了当前最好的ASR结果。
ASR
自动语音识别(Automatic Speech Recognition,简称 ASR)是人工智能领域中人机语音交互的核心入口技术,融合了信号处理、语言学、机器学习、深度学习等多学科理论,通过计算机算法将人类自然语音信号转化为可理解、可处理的文本信息。
ASR 的本质是 “信号转换 + 语义约束” 的过程,传统架构分为 “预处理 - 声学建模 - 语言建模 - 解码后处理” 四步,端到端架构则将前三者融合,但核心逻辑仍围绕 “特征提取 - 概率建模 - 最优序列生成” 展开。
1. 语音信号预处理:过滤噪声,提取核心特征
原始语音是连续的模拟信号,需先通过 “模数转换(ADC)” 转为数字信号,再进行一系列优化处理,目的是保留语音有效信息,过滤干扰信号,输出标准化的语音特征序列。
2. 声学模型(Acoustic Model, AM):从 “特征” 到 “音素” 的映射
声学模型是 ASR 的 “听觉核心”,负责将预处理后的语音特征序列映射为音素序列(语言中最小的发音单位)。其本质是建模 “语音特征→音素” 的概率分布,即计算 “给定特征序列,最可能对应的音素序列”。
3. 语言模型(Language Model, LM):从 “音素” 到 “文本” 的语义约束
语言模型是 ASR 的 “语言大脑”,负责基于语言规律修正声学模型的输出,从声学建模输出的候选声学单元中筛选出 “符合语言习惯的文本序列”,解决 “哪些发音组合更像正常语言” 的问题。
4. 解码与后处理:生成最优文本序列
解码(Decoding):解码是结合声学模型和语言模型,从 “音素序列候选集” 中找到概率最高的文本序列。
后处理(Post-processing):通过纠错,格式规整,领域适配等,进一步优化文本,提升实用性。
原始语音 → 预处理(去噪提特征)→ 声学建模(特征→音素概率)→ 语言建模(音素→文本概率)→ 解码后处理(概率融合→最优文本),形成 “信号→特征→发音→语义→文本” 的完整转化链路,其中声学建模决定 “识别下限”(能否听清发音),语言建模决定 “识别上限”(能否理解语境),四阶段共同构成 ASR 的技术核心。
Zipformer模型详解
模型结构:U-Net 式降采样与 Zip Block 设计
Zipformer 的整体架构借鉴了 U-Net 的 “下采样 - 中维建模 - 上采样” 思想,配合创新的 Zip Block 模块,在降低计算量的同时保留关键语音特征。
1. 整体架构:多尺度特征建模
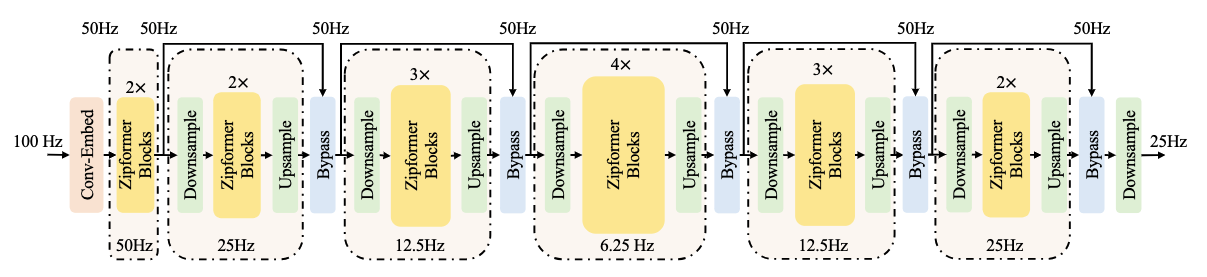
Zipformer 的编码器由 1 个 Conv-Embed 模块 + 6 个 Encoder Stack 组成,通过动态调整特征序列的时间分辨率(采样率),实现 “全局上下文建模” 与 “局部细节捕捉” 的平衡:
-
Conv-Embed 模块:输入为 100Hz 的声学特征,通过 2 层卷积将其下采样为 50Hz,同时提升特征维度,目的是减少后续模块的计算量,同时保留底层声学细节。
-
6 个 Encoder Stack 的尺度变化:6 个 Stack 按 “下采样→中维→上采样” 的顺序处理特征,时间分辨率依次为:50Hz → 25Hz → 12.5Hz → 6.25Hz → 12.5Hz → 25Hz。
- 下采样阶段(Stack 1-3):通过卷积步长进一步降低时间分辨率,减少计算量,聚焦全局上下文建模;
- 中维阶段(Stack 4):在最低分辨率(6.25Hz)下用更大的特征维度建模长距离依赖,捕捉语音的全局语义;
- 上采样阶段(Stack 5-6):逐步恢复时间分辨率,将全局信息与局部细节融合,提升细粒度识别精度。
2. 核心模块:Zip Block 的 “权重复用” 机制
每个 Encoder Stack 由多个 Zip Block 组成,其深度约为 Conformer Block 的 2 倍,但通过注意力权重复用实现了计算量的降低。、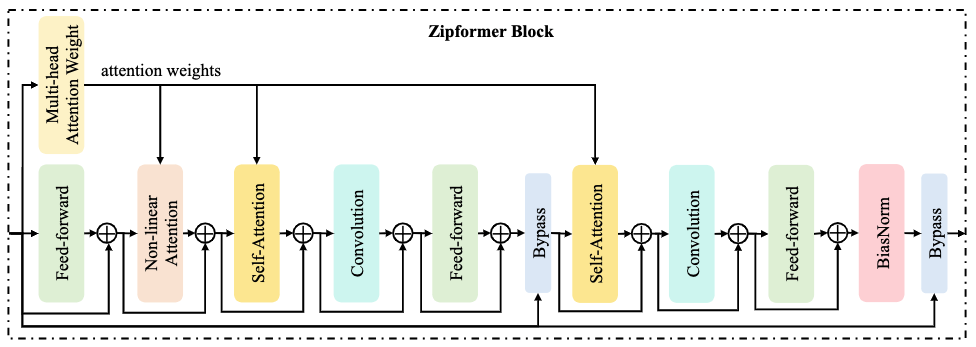
Zip Block 的结构可拆解为 5 个关键步骤:
-
输入预处理:输入特征先经过 BiasNorm(改进的层归一化)和线性投影,分为 “注意力分支” 和 “卷积分支”,分别用于时序建模和局部特征提取。
-
Multi-Head Attention Weight(MHAW)模块:计算一次多头注意力权重,但不直接输出注意力结果,而是将权重分享给后续 3 个模块(NLA + 2 个 SA),避免重复计算 —— 这是 Zipformer 提升效率的核心创新。
-
Non-Linear Attention(NLA)模块:使用 MHAW 输出的权重,结合非线性变换(如 Swoosh 激活函数)对输入特征进行加权,增强对关键语音片段的关注。
-
双 Self-Attention(SA)+ 卷积模块:两组 “SA + 深度卷积 + Feed-Forward” 子模块:
- 每个 SA 均复用 MHAW 的注意力权重,仅需对特征进行加权和残差连接,大幅减少计算;
- 深度卷积捕捉局部时序特征,与注意力的全局建模形成互补。
-
输出归一化:最后通过 BiasNorm 对 Block 输出进行归一化,保证特征分布稳定,便于跨 Block 传递。
关键技术创新:从细节优化到范式突破
Zipformer 的性能优势源于三项核心技术创新,覆盖 “特征归一化、激活函数、优化器” 等关键环节:(摘选自官方https://k2-fsa.org/zh-CN/blog/2023/12/15/zipformer-details/)
BiasNorm:保留长度信息的归一化方法


Swoosh 激活函数:解决梯度消失与参数更新不稳定

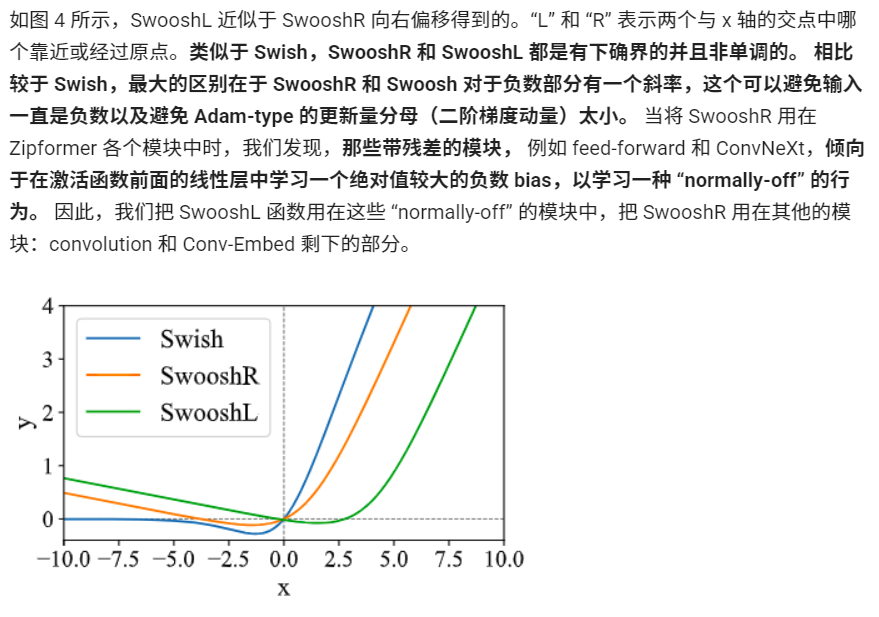
ScaledAdam 优化器:平衡不同参数的更新幅度

激活值限制:保障模型的收敛效率与推理鲁棒性

🕊️🕊️🕊️...