2v1带您实战12nm高级数字后端
01 后端专家2v1带您实战!
呕心沥血——景芯12nm车规中后端UPF hierarchy实战项目出炉!这一次剑走偏锋,我们的实战只靠文档+一对一辅导!不提供视频!基于景芯团队丰富的SoC/MCU芯片定制经验,我们特选取景芯SoC HD6860项目中的车规处理器(安全岛系统)进行后端全流程实战培训。
【重磅】实战项目原为hierarchy TOP的后端设计,为了满足大家不同层次需求,实战训练营将原工程拆分为core层和TOP层两个工程供大家选择实战。注意:TOP层包括core层。这是我们的招牌课程!牛不牛?大家说了算!
在每个阶段PR结束之后,对子模块或者TOP顶层进行Calibre DRC, LVS,EM,ERC,ANT,ESD等检查,StarRC抽参,STA,lc生成lib文件等。使用xtop/pt进行timing eco修复setup/hold违例,LEC逻辑等价性检查。VCLP低功耗设计静态检查,voltus功耗和压降评估,redhawk功耗和IR Drop分析,后仿真等等。课程的设置真的非常全面,涵盖了芯片DFT+后端物理实现直到tapout的全流程。
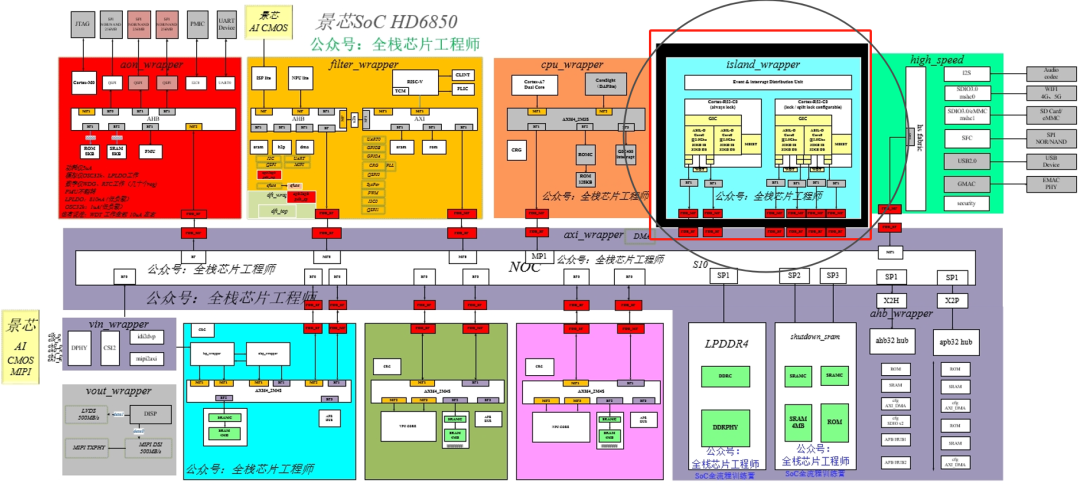
整个项目基于innovus+tessent实现,主要包括芯片顶层的Partition、子模块的DFT+PR和TOP顶层的DFT+PR三个阶段。
在每个阶段PR结束之后,对子模块/TOP顶层进行Calibre DRC, LVS,EM,ERC,ANT,ESD等检查,StarRC抽参,STA,lc生成lib文件等。使用xtop/pt进行timing eco修复setup/hold违例,LEC逻辑等价性检查。VCLP低功耗设计静态检查,voltus功耗和压降评估,redhawk功耗和IR Drop分析,后仿真等等。课程的设置真的非常全面,涵盖了芯片DFT+后端物理实现直到tapout的全流程。
02 core flat实战课目录
Part.01
core flat实战课目录之pre-APR


Part.02
core flat实战课目录之APR+PV

Part.03
core flat实战课目录之STA

Part.04
core flat实战课目录之LEC

Part.05
core flat实战课目录之PA

02
TOP hierarchy实战课目录
Part.06
TOP hierarchy实战之TOP

Part.07
TOP hierarchy实战之CTS基础

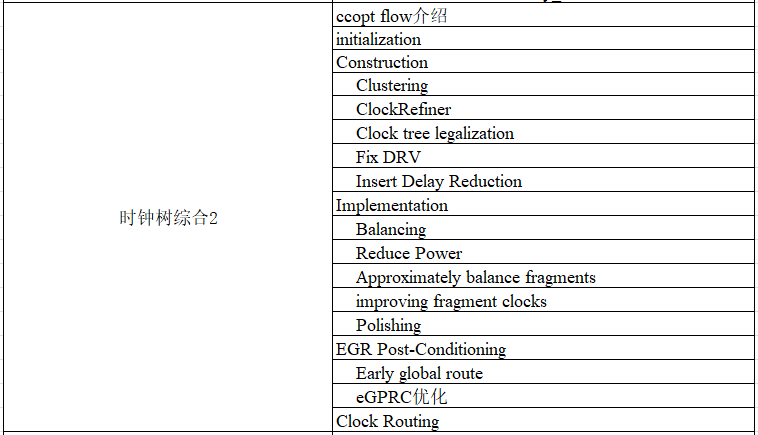
Part.08
TOP hierarchy实战之CTS高级



Part.09
TOP hierarchy实战之高级hierarchy实战

Part.10
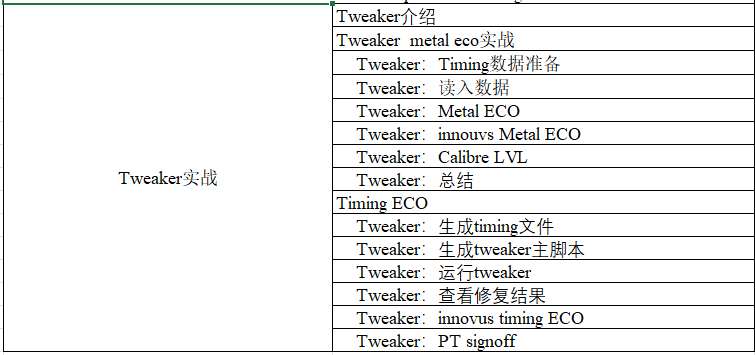
TOP hierarchy实战之Tweaker
掌握FinFET工艺的后端工程师是芯片公司的核心资源。12nm及以下项目经验成为求职时的“硬通货”,尤其是参与过景芯12nm流片(Tape-out)的工程师。下一代工艺(如3nm的GAAFET)的许多挑战与FinFET一脉相承(如3D结构建模、复杂寄生参数提取),早期积累的经验对未来技术升级至关重要。若后端工程师不掌握12nm先进工艺,将无法参与主流芯片项目。
02
FinFET工艺的数字后端难在哪里?
半导体行业长期遵循摩尔定律(晶体管密度每18-24个月翻倍),推动工艺节点不断缩小(如12nm、7nm、5nm等)。12nm及以下节点采用FinFET结构,FinFET通过三维立体结构(鳍片)增强栅极对沟道的控制,显著降低了漏电流(Leakage Power),同时提高了驱动电流(性能),解决了传统平面晶体管(Planar FET)在更小节点下的漏电流和功耗失控问题。FinFET工艺难点主要体现在:
物理效应加剧:在12nm及以下节点,量子效应、工艺波动(PVT)、寄生效应(RC Delay)、电迁移(EM)等问题更加显著,后端工程师需要应对更复杂的时序收敛(Timing Closure)、信号完整性(SI)和功耗优化(如动态IR Drop)。
设计规则复杂化:先进工艺的设计规则(DRC/LVS)和制造约束(DFM)成倍增加,例如多重曝光(Multi-Patterning)、Fin切割规则、金属层堆叠等,需要后端工具和流程的全面升级。
04
景芯12nm车规中后端实战课的价值
AI训练、数据中心、GPU/TPU等需要超高算力和能效比的芯片,必须依赖先进工艺的FinFET甚至更先进的GAAFET(环绕栅极晶体管)。智能手机、物联网设备等对功耗极其敏感,12nm以下FinFET工艺在性能(频率)和功耗(电池续航)之间提供了更优的平衡。
先进工艺芯片(如手机SoC、AI加速器)的利润远高于成熟工艺(如40nm/28nm),企业倾向于将资源集中在高价值项目。虽然12nm以下工艺的流片成本高达数千万美元,但单芯片成本(尤其是高性能芯片)可能更低,推动设计公司必须采用先进工艺。
尽管先进工艺的设计复杂度更高,但这是半导体行业向更高性能、更低功耗、更小面积发展的必经之路。数字后端工程师参与12nm及以下FinFET项目,不仅是技术发展的必然要求,也是市场需求和职业竞争力的直接体现。对于工程师而言,掌握FinFET节点的后端设计能力,等同于掌握了未来十年芯片行业的核心技术话语权。
课程报名微信:

景芯全流程实战附属【知识星球】,一个包括设计、验证、DFT、后端全流程技术的交流平台,也是景芯学员的答疑平台!欢迎扫码加入星球!

05
限时间赠送A72 2.5GHz实战项目,云服务器资源有限,仅送3份!
2.5GHz 12nm 景芯SoC 高性能CPU hierarchy UPF DVFS 后端实战训练营!项目手把手一对一辅导!随到随学!
课程采用hierarchy/partition flow,先完成单核CPU实战,然后完成TOP实战!训练营简介:
Instance:315万
Gate count:2600万
Frequency: 2.5GHz
Power domain:7个,hierarchy UPF设计
EDA工具有VCS/Fusion Compiler/VCLP
EDA工具有innovus/Starrc/PT/Voltus/formality/LEC/Calibre
EDA工具有Redhawk-sc全网首发python版

授课形式:视频+文档+上机实践,真实项目flow,一对一答疑!
ICer加班太多,项目采用视频模式,随到随学!
参与景芯SoC的12nm 高性能CPU训练营,您将掌握以下知识:
掌握hierarchy UPF文件编写,掌握Flatten UPF文件编写、UPF验证。本项目采用hierarchy UPF方式划分了7个power domain、voltage domain。
掌握power switch cell,包括SWITCH TRICKLE、SWITCH HAMMER。掌握低功耗cell的用法,选择合适的isolation cell、level shifter等低功耗cell。
掌握Power gating,Clock gating设计技术。
掌握Multi-VT设计技术,本项目时钟树都是ULVT,动态功耗小,skew小。
掌握DVFS技术,ss0p9 2.5GHz、ss0p72 2.0GHz,,其中sram不支持ss0p63。要做ss0p63的话,给sram vddm单独一个0p7v的电源即可。
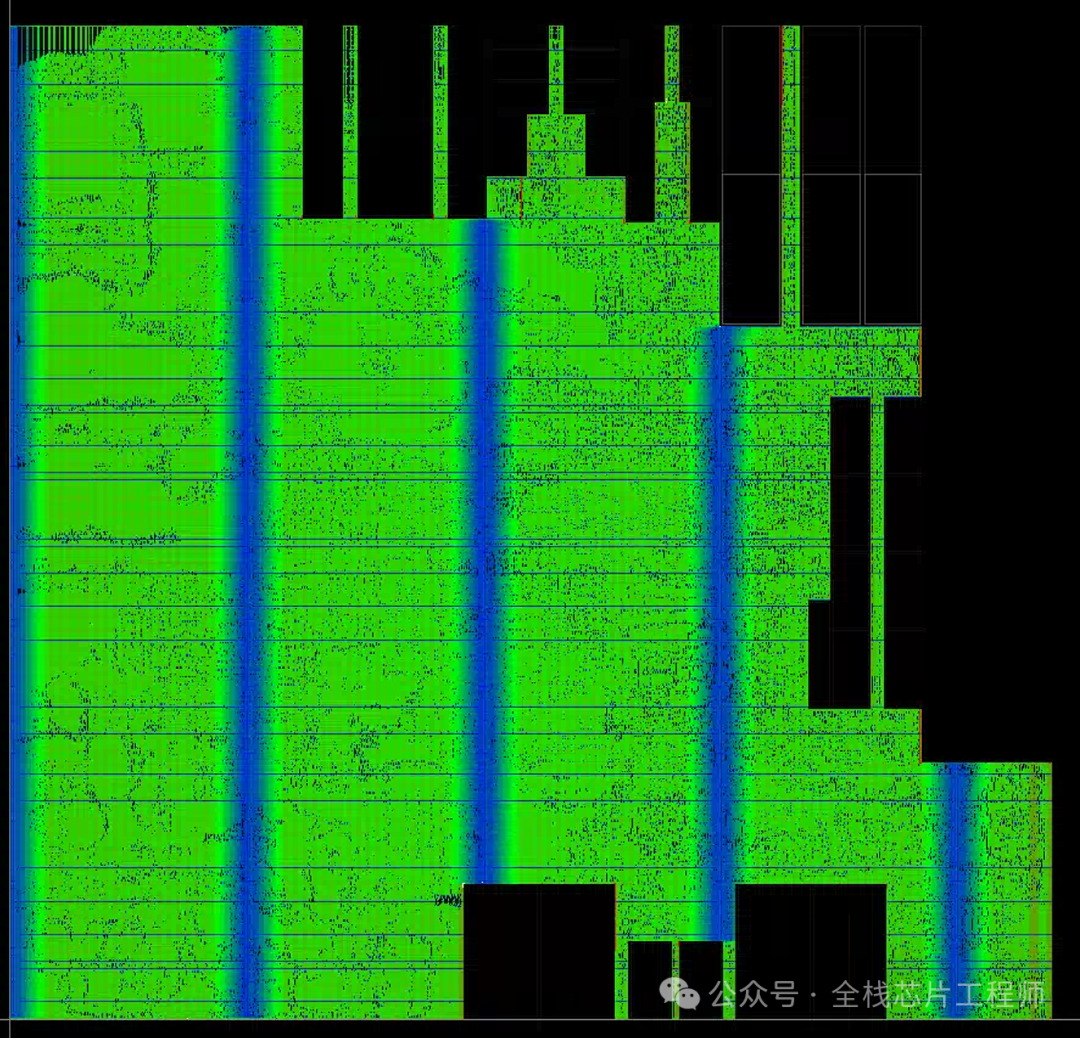
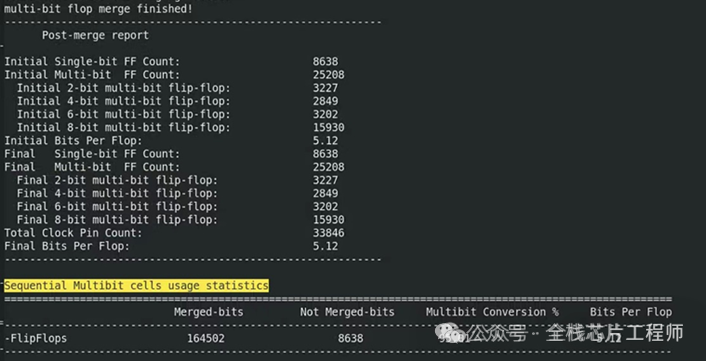
掌握multibit cell的用法,本项目CPU里面的mb高达95%,选择合适的multibit cell得到超高的CPU利用率。INNOVUS里面一般不做mb的merge和split。所以前后一样的,一般综合做multibit的merge split。
根据TOP Floorplan DEF进行CPU子系统的partition以及pin assignment。
Top的Power stripe的规划及其push down。
SpecifyBlackBox,将CPU core镜像partition。
手动manual cut the BlackBox的方法,掌握复杂的floorplan设计方法经验。
VerifyPowerDomain,检查低功耗划分以及UPF的正确性。
Pin assignment,根据timing的需求进行合理的pin脚排布,并解决congestion问题。
掌握Timing budget。
掌握利用Mixplace实战CPU的自动floorplan,掌握AI的floorplan方法学。

掌握Fusion compiler DCG,利用fusion compiler来完成DCG综合,进一步优化timing与congestion。
掌握hierarchy ICG的设计方法学,实战关键ICG的设置与否对timing的重大影响。
掌握Stapling技术,实战power switch cell的布局和特殊走线的方法学,掌握CPU子系统的powerplan规划及实现,保证CPU子系统和顶层PG的alignment。
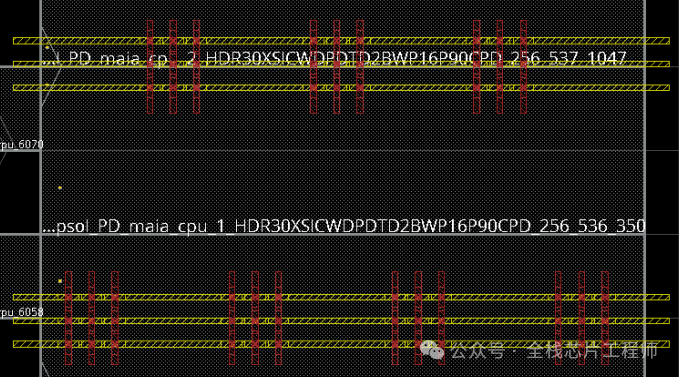
掌握CPU子系统和TOP的时序接口优化。掌握TOP isolation cell的placement以及isolation cell input电学特性检查。
掌握TOP和CPU子系统的clock tree Balance优化处理,common clock path处理。时钟树结构trace和时钟树评价。
CPU子系统的DRC/LVS检查
TOP系统的DRC/LVS检查
Hierarchy & Flatten LVS检查原理及实现方法
静态时序分析&IR-Drop
DMSA flow
根据Foundry的SOD(signoff doc)的Timing signoff标准建立PT环境。
Star RC寄生抽取及相关项检查
Timing exception分析,包括set_false_path、set_multicyle_path解析。
PT timing signoff的Hierarchical和Flatten Timing检查
PT和PR timing的差异分析、Dummy insertion和with dummy的Timing分析
IR-Drop分析

训练营部分文档:
Flow:Partition Flow
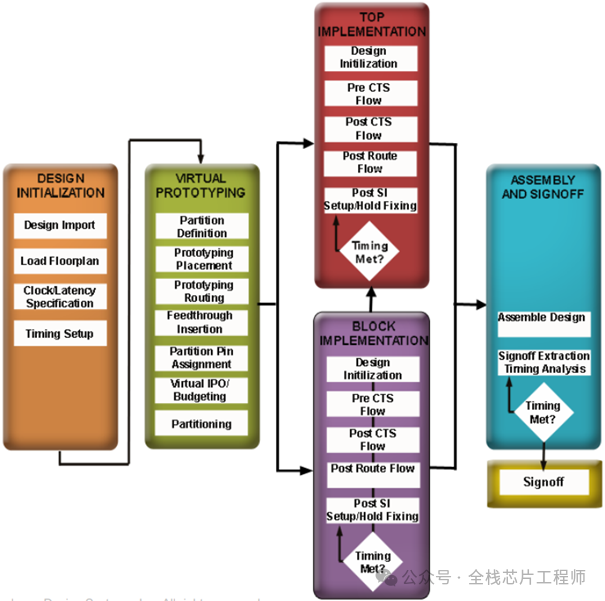
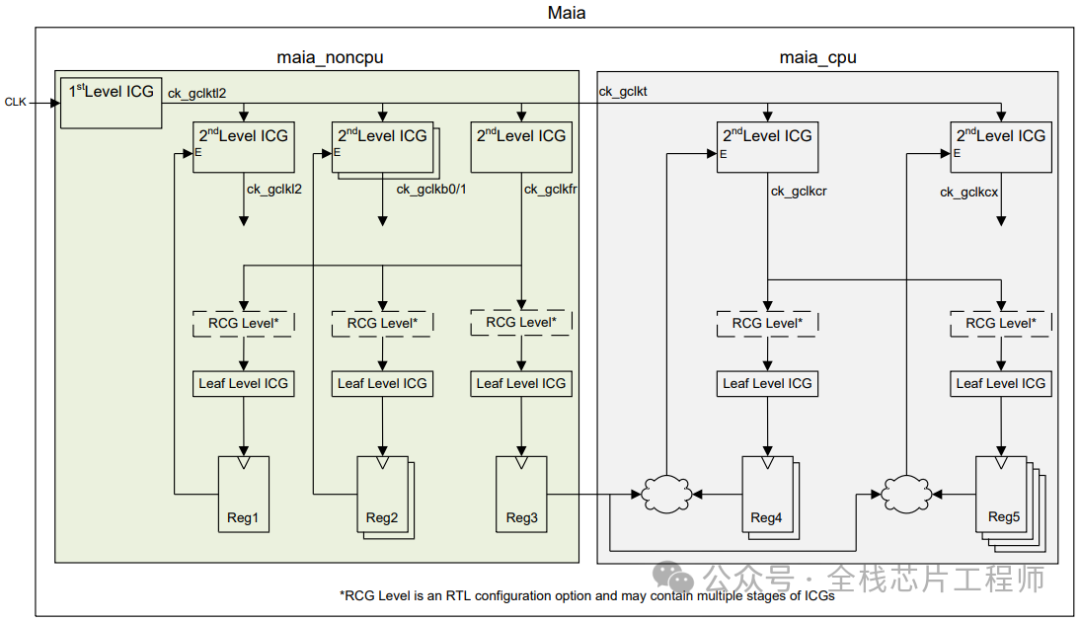
时钟结构分析:
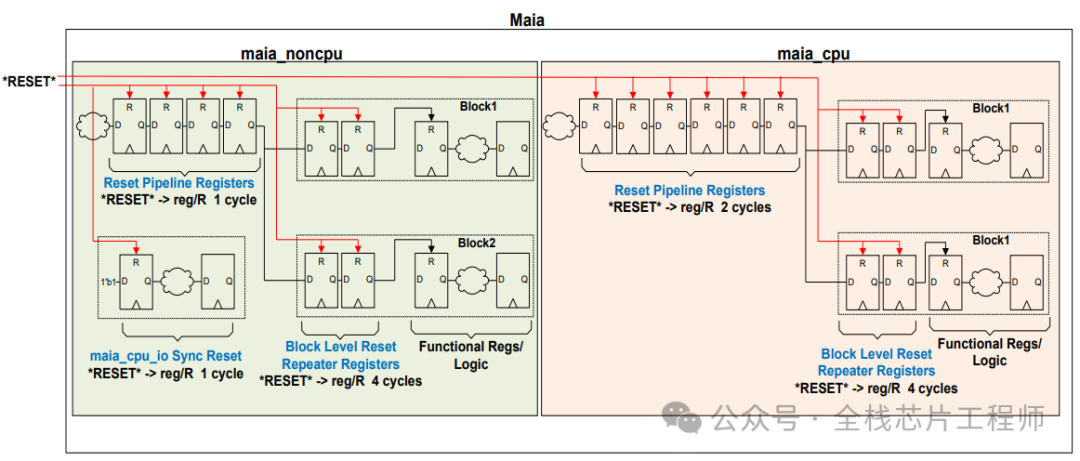
复位结构分析:
06
学员好评
先说结论:课程内容非常全面,讲解到位,会有专门的工程师一对一答疑,整个项目跑下来提升非常大,绝对物超所值!
一些细节:
本人微电子专业研一在读,有过两次简单的数字芯片流片经历,出于学习和科研需要,报名了景芯SoC的12nm 高性能CPU UPF DVFS后端课程。
整个项目基于innovus实现,主要包括芯片partition、maia_cpu的PR和MAIA顶层的PR三个阶段。在每个阶段PR结束之后,对maia_cpu ip核/MAIA顶层进行Calibre DRC, LVS检查,StarRC抽参,pt抽参,lc生成lib文件,使用xtop/pt进行timing eco修复setup/hold违例,LEC逻辑等价性检查,VCLP低功耗设计静态检查,voltus功耗和压降评估,redhawk功耗和IR Drop分析等等。个人觉得课程的设置真的非常全面,涵盖了芯片后端物理实现直到tapout的全流程,本人在跑这套后端flow的过程中也了解到很多非常实用的后端EDA工具和功耗/时序的分析/修复方法。
项目整体流程和部分文档
在partition阶段,进行初步的floorplan,划分电压域,并实现顶层的电源网络。如下图所示,整颗芯片包含两颗高性能cpu核,若干L2 $,一些常开模块和PMU模块等等。整颗芯片共划分了6个电压域。(顺便提一句,我觉得整个项目唯一美中不足的地方是顶层芯片没加PAD,景芯的另一个soc项目有加PAD的流程)

MAIA before partition

MAIA partition
maia_cpu阶段实现单颗高性能CPU的PR,这部分流程就比较常规了,首先导入之前partition好的maia_cpu部分的def,随后进行单颗maia_cpu的floorplan、摆放powerswitch和各种tapcell, endcap、电源网络设计、摆放标准单元、时钟树综合、二级电源连线、信号布线、各种check和verify、release等。但是!让我眼前一亮的有两点,一个是12nm的电源网络的via pillar处理方式,另一个是ICG单元的特殊处理和整个时钟网络的balance,还是学到不少新东西的。
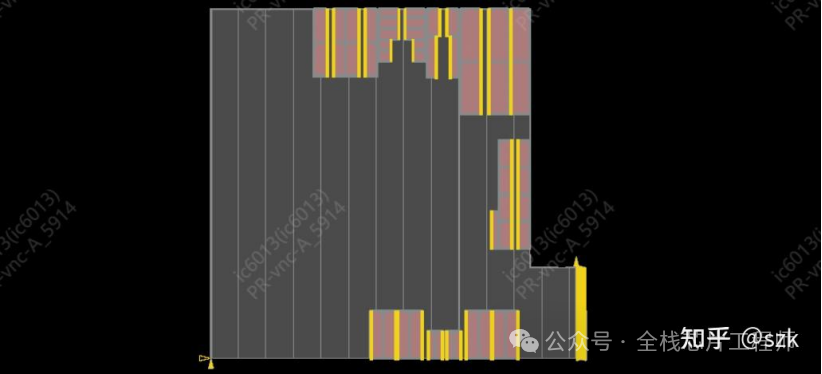
A72 maia_cpu floorplan
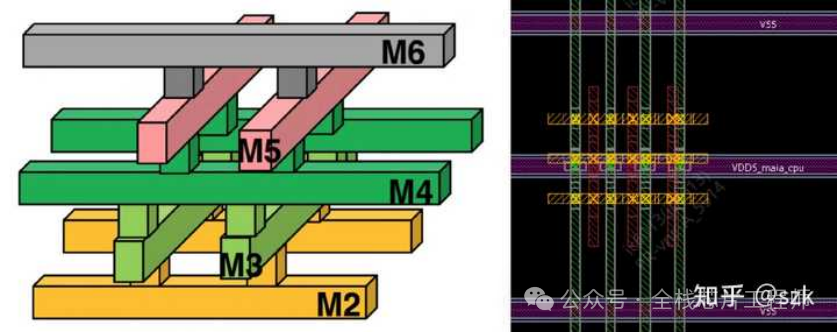
via pillar
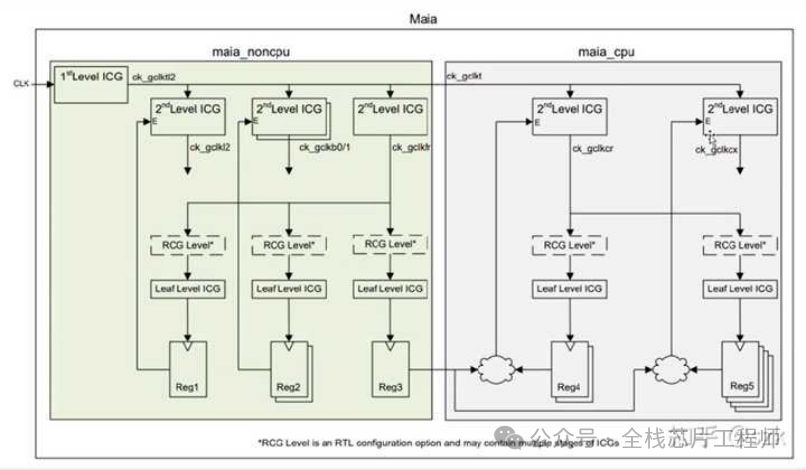
overview of ICGs
完成maia_cpu后,我先进行starRC、pt抽参,随后使用xtop优化setup和hold,并再次打开innovus使用xtop生成的脚本自动进行eco修复timing。确认时序没有违例后,使用Calibre进行DRC、LVS检查,不出所料有很多DRC违例,LVS不通过。但是!!!景芯的一对一辅导真的很靠谱,有几个较难的DRC和LVS问题,工程师会一步步帮忙找bug并进行eco,整个过程非常专业并且工程师真的非常非常有耐心。最后如愿DRC和LVS clean。
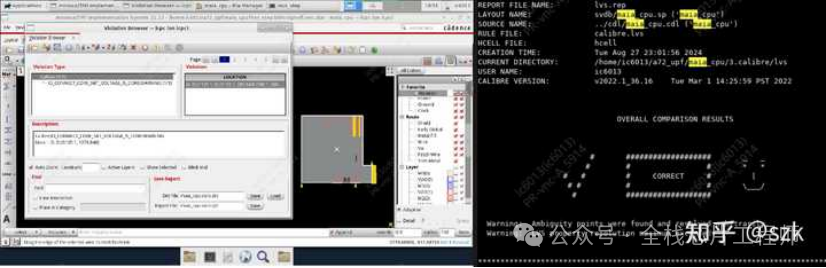
DRC/LVS results
对maia_cpu进行一系列LEC检查和功耗、压降检查后,就可以进行最后一步MAIA顶层的布局布线了。依次读入各种lib和lef文件、maia_cpu的def和partition阶段产生的MAIA顶层的def,随后与maia_cpu相同,进行floorplan、电源网络、时钟树综合等等,不再赘述。
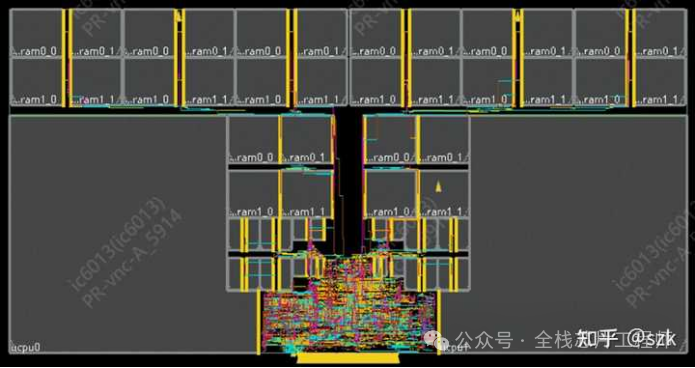
MAIA after CTS
整体来说我觉得这个项目是非常完善的,DRC、LVS、时序、功耗、压降等各种检查都有涉及;同时项目也非常有难度,不仅芯片规模大,制程先进(12nm),还涉及很多UPF的相关内容。景芯课程视频和实践相结合的授课方式也非常有效,课程的课程视频会大量讲解一些原理性的内容,比如MCMM、UPF的一些基本概念和环境配置、时钟树的基本理论和该项目的时钟树结构的设计方法、顶层模块的时序约束、POCV/SOCV时序报告解读等等,而上机实践的部分则需要自己动手跑脚本,发现bug并尝试解决,锻炼工程能力。此外,我觉得课程很贴心的一点是,上机实践的部分在关键步骤都准备了golden结果,如果当下bug不能立即解决可以先跳过,使用提供的golden先体验一下整个后端流程,回过头再来解决一些细节问题。跑完整个项目真的感觉收获满满,在理论和实践上都有很大提升,但是感觉依然有很多内容没有完全掌握,整个flow中的很多细节都没注意到,很多工具也只是马马虎虎跑了个脚本。
最后!我觉得这个课程最值的一点就是有专门的工程师全程答疑,工程师回消息特别快,解决方案也很细致,除了解决一些具体的bug之外,有时候还会讲解一些原理性的内容,分享一些工程经验等等,真的能学到很多除脚本之外的东西!非常推荐!
(另外: 我觉得景芯SoC的12nm 高性能CPU UPF项目整体难度有点大,如果是新手的话建议先报景芯的soc后端实践课,再来尝试景芯SoC的12nm 高性能CPU的进阶课程)
06
2.5GHz UPF hierarchy TOP实战问题分享
12nm 2.5GHz的高性能CPU实战训练营需要特别设置Latency,TOP结构如下,参加过景芯SoC全流程训练营的同学都知道CRG部分我们会手动例化ICG来控制时钟,具体实现参见40nm景芯SoC全流程训练项目,本文介绍下12nm 2.5GHz的A72实战训练营的Latency背景,欢迎加入实战。
时钟传播延迟Latency,通常也被称为插入延迟(insertion delay)。它可以分为两个部分,时钟源插入延迟(source latency)和时钟网络延迟(Network latency)。
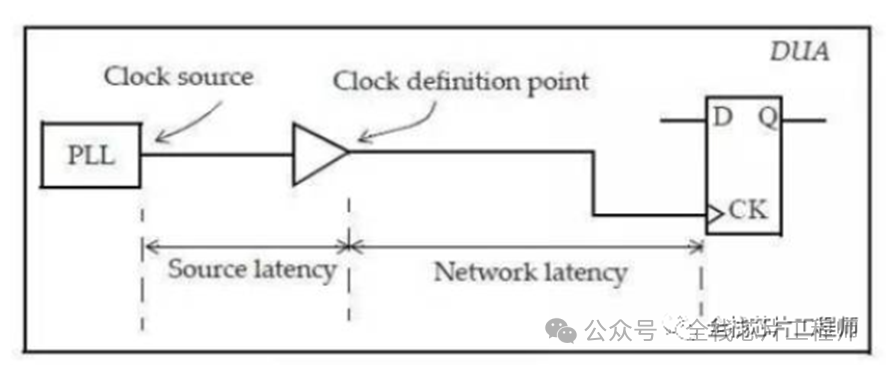
大部分训练营同学表示平时都直接将Latency设置为0了,那latency值有什么用呢?其实这相当于一个target值,CTS的engine会根据你设置的latency值来插入buffer来实现你的latency target值。
下图分为1st Level ICG和2nd Level ICG,请问这些ICG为什么要分为两层?
请问,为什么不全部把Latency设置为0?2nd Level ICG的latency应该设置为多少呢?
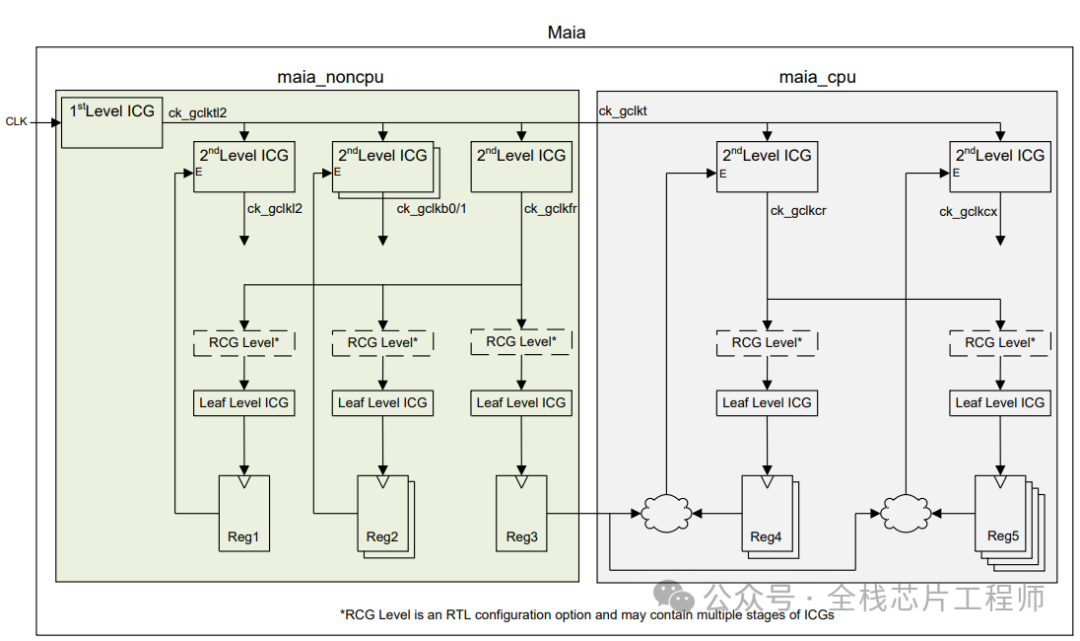
latency大小直接影响clock skew的计算。时钟树是以平衡为目的,假设对一个root和sink设置了400ps的latency值,那么对另外的sink而言,就算没有给定latency值,CTS为了得到较小的skew,也会将另外的sink做成400ps的latency。请问,为何要做短时钟树?因为过大的latency值会受到OCV和PVT等因素的影响较大,并有time derate的存在。
分享个例子,比如,景芯SoC的12nm 高性能CPU低功耗设计,DBG domain的isolation为何用VDDS_maia_noncpu供电而不是TOP的VDD?
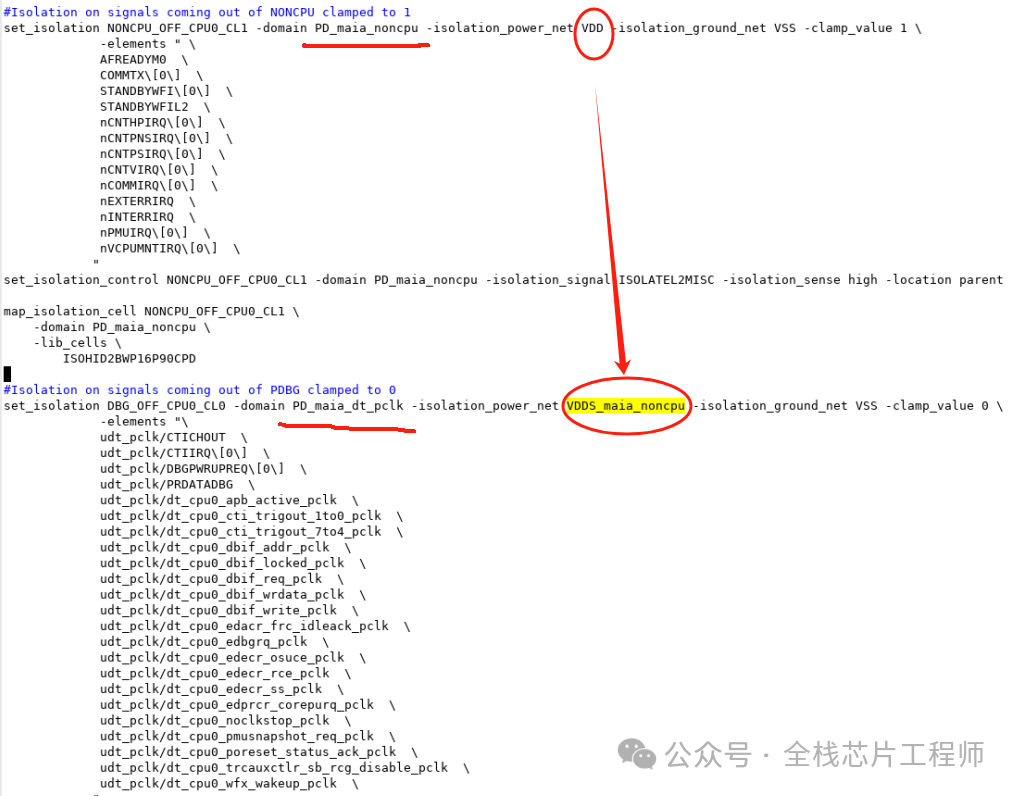
答:因为dbg的上一级是noncpu,noncpu下面分成dbg和两个tbnk。
再分享个例子,比如,景芯SoC的12nm 高性能CPU低功耗设计,这个switch cell是双开关吗?答:不是,之所以分trickle和hammer,是为了解决hash current大电流,先开trickle,然后再开hammer。

再分享个例子,比如,景芯SoC的12nm 高性能CPU课程的低功耗例子:请问,如果iso cell输出都要放parent,输入放self,那么下面-applies_to_outputs对应的-location为何是self?

答:这个需要了解CPU的内部设计架构,tbnk掉电 VDDS_maia_noncpu也必然掉电,pst如下,所以-applies_to_outputs对应的-location是可以的,那么注意下debug domain呢?

实际上,没有tbnk到debug domain的信号,因此脚本如下:

再分享个例子,比如,景芯SoC的12nm 高性能CPU课程的低功耗例子:为何non_cpu的SRAM的VDD VDDM都接的可关闭电源?SRAM的VDD VDDM分别是常开和retention电源吧?

答:本来是VDDM作为retention电源设计的,VDD关掉后 VDDM可以供电作为retention使用,但是此处没有去做memory的双电源,sram当成单电源使用,不然sram无法彻底断电。
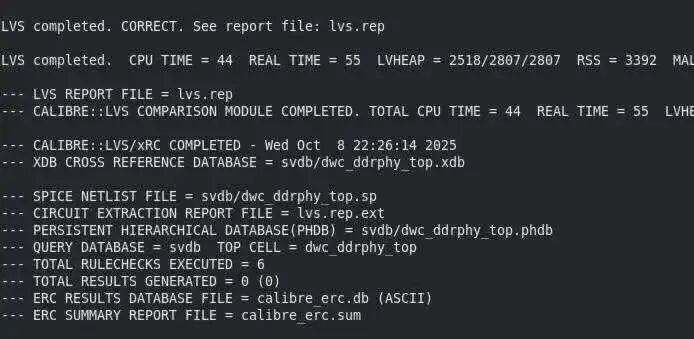
再分享个例子,比如,景芯SoC的12nm 高性能CPU课程有学员的单核cpu LVS通过, 但是多核顶层LVS比对不过,我们来定位一下。
以FE_OFN4326_cfgend_cpu1_o为例,点击下图FE_OFN4326_cfgend_cpu1_o:
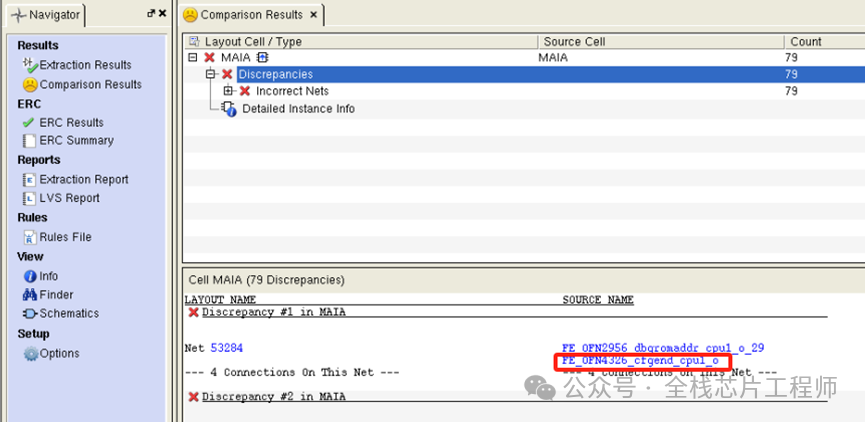
找到calibredrv错误坐标:(1949,139)
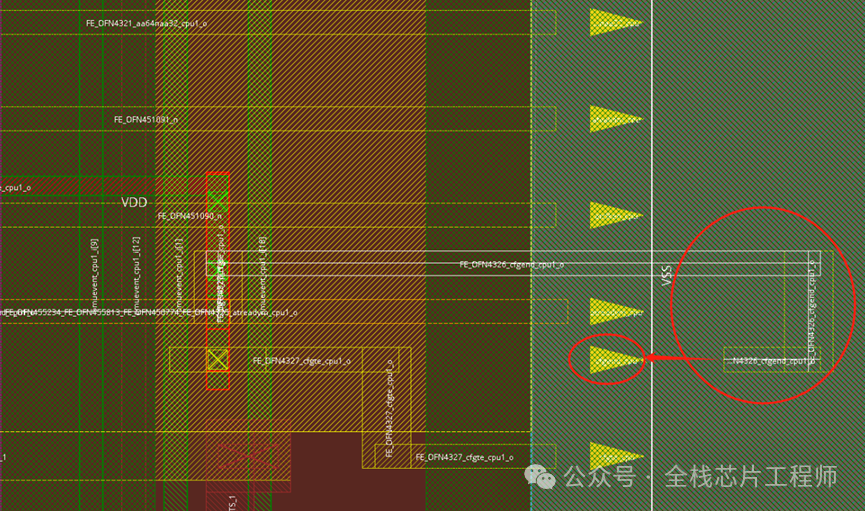
对应到innovus去看坐标:(1949,139)
看到maia_cpu的pin脚过于密集,造成顶层连接pin脚时候会无法绕线,从而导致innovus从maia_cpu上面走线,形成short。尽管maia_cpu带了blockage,但是invs没有足够的连接pin的routing resource,也就只能在maia_cpu上面去try了。
修改办法很简单,具体操作option参见知识星球。
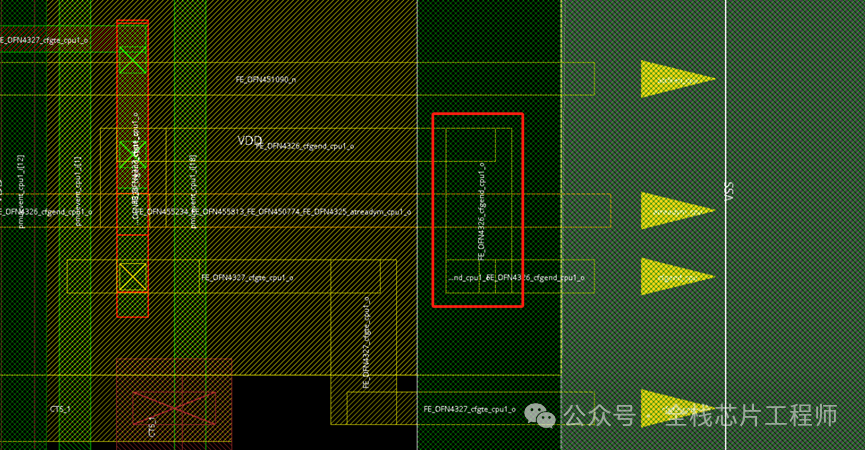
保存db,重新LVS,比对通过。

PLUS:景芯AI SoC创业项目—lpddr专题 LVS pass