评估agent能力benchmark收集汇总
agent是目前LLM时代的新事物,借助于LLM,agent能智能调用多种工具完成复杂任务。
这里收集评估agent能力的benchmark,尝试从多个角度了解和应用agent解决实际问题。
1 MMTB
Multi-Mission Tool Bench,MMTB),25.04
MMTB是腾讯结合自家很多业务场景和工具,构建出来的agent评估工具,主要关注“多任务”和“工具使用”,根据不同目标,灵活地调用不同工具(API、函数库、外部应用等)来完成任务,即Agent 面对复杂指令时,能否理解意图、规划步骤、选择合适的工具、正确地调用并处理返回结果,以及在多个任务间切换和协调的能力,
MMTB强调任务的复合性和工具实用性,贴近现实世界中需要组合多种能力才能解决的问题场景。
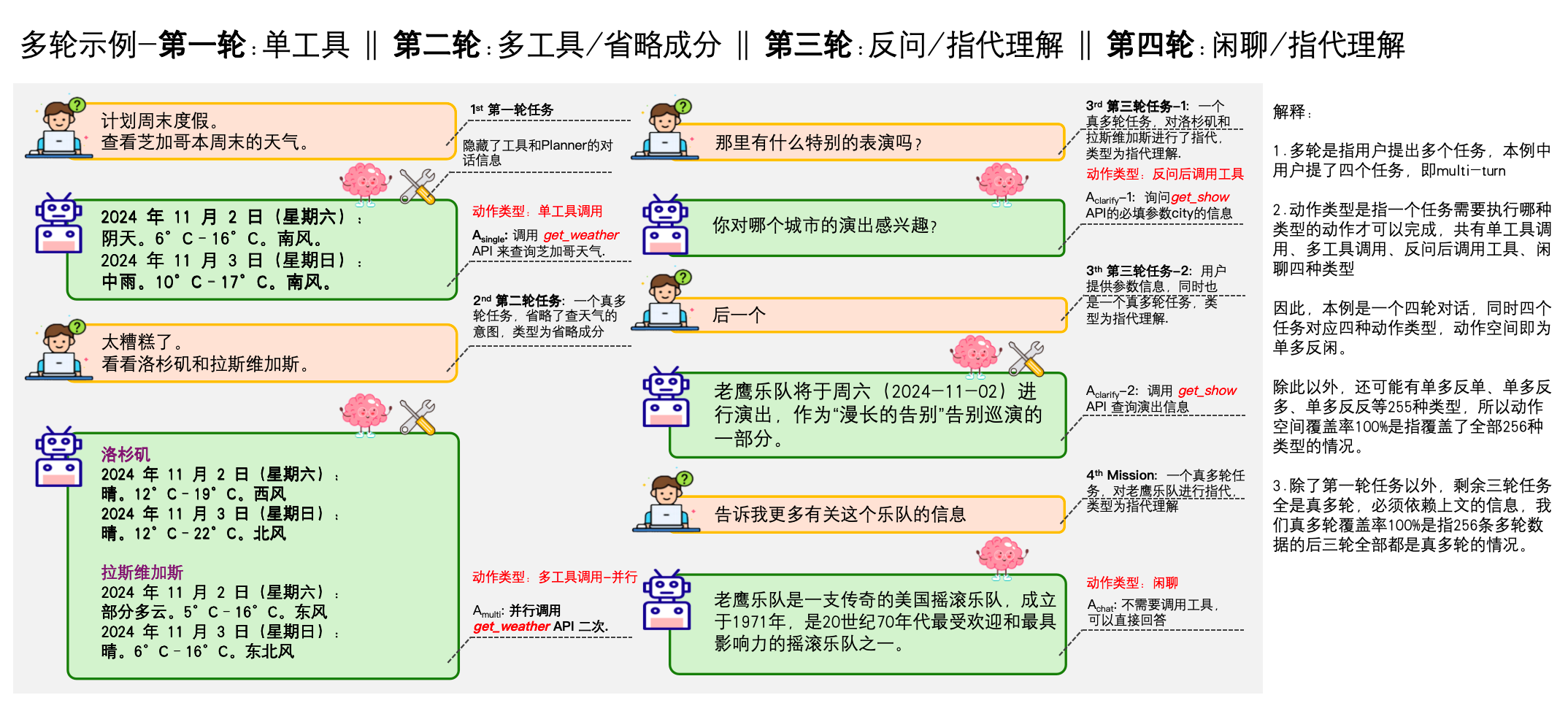
Multi-Mission Tool Bench: Assessing the Robustness of LLM based Agents through Related and Dynamic Missions
https://arxiv.org/abs/2504.02623
MMTB
https://github.com/yupeijei1997/MMTB
2 BFCL-V3
BFCL-V3,Berkeley Function Calling Leaderboard
BFCL - Function Calling Leaderboard,专注于评估大模型进行函数调用的能力,整合了多个专注于函数调用的数据集和评估方法,并非端到端Agent任务执行Benchmark。
BFCL主要评估模型能否准确讲自然语言指令转化为函数调用,能否正确地提取和格式化参数,能否处理复杂的嵌套调用、并发调用、条件调用。
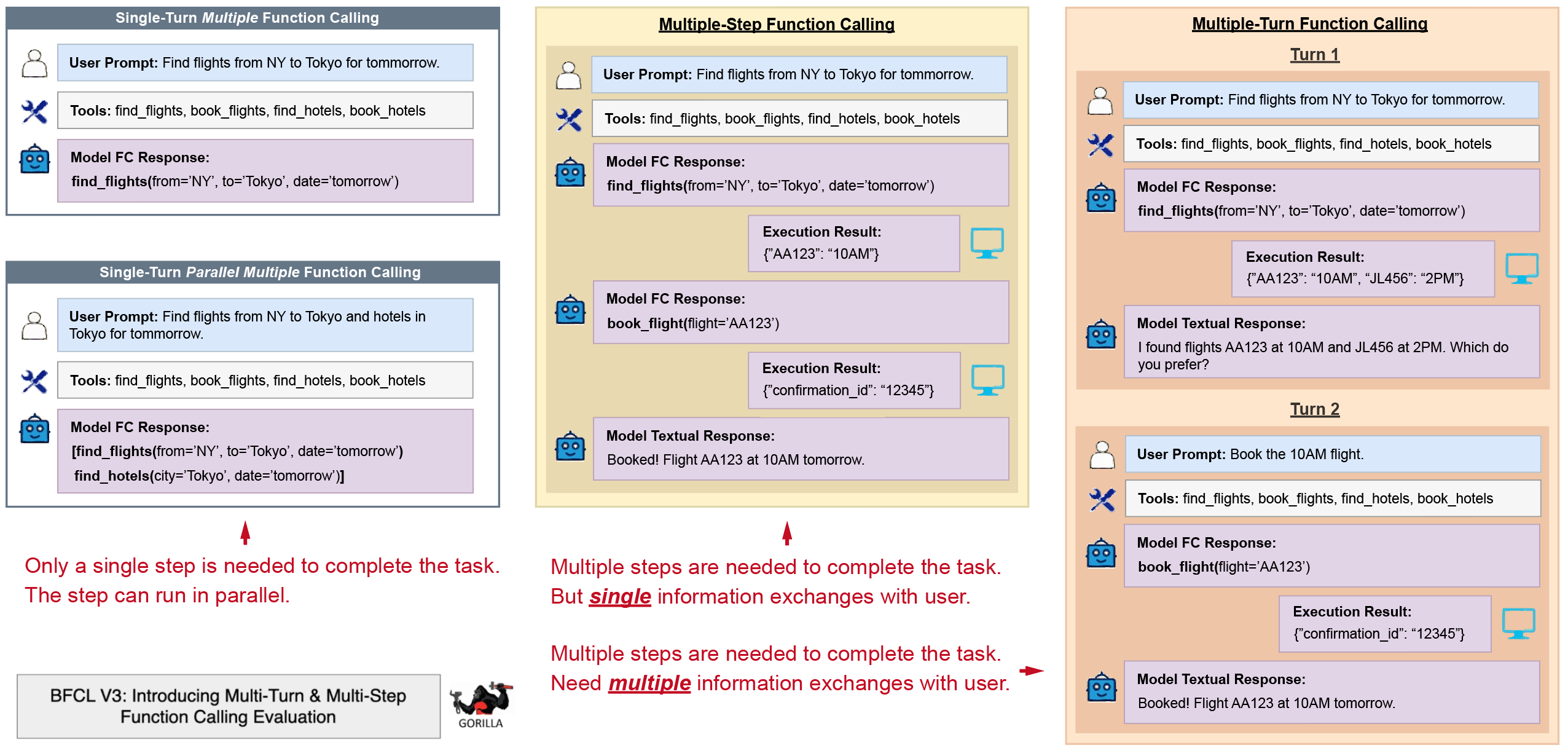
BFCL通过细粒度的评估,能很好地横向比较不同模型在这一核心技能上的优劣。
BFCL较少涉及任务规划、多步推理、结果校验、根据反馈调整策略。
(BFCL V3 • Multi-Turn & Multi-Step Function Calling Evaluation)
https://gorilla.cs.berkeley.edu/blogs/13_bfcl_v3_multi_turn.html
🦍 Gorilla: Large Language Model Connected with Massive APIs
https://github.com/ShishirPatil/gorilla/tree/main
3 Tau-Bench
Tau-Bench关注Agent在动态环境中的反应与适应能力,评估Agent在不断变化的任务和场景中的实时决策和快速调整的应变能力Tau-Bench对时间敏感型任务,如实时游戏、自动驾驶更有价值。
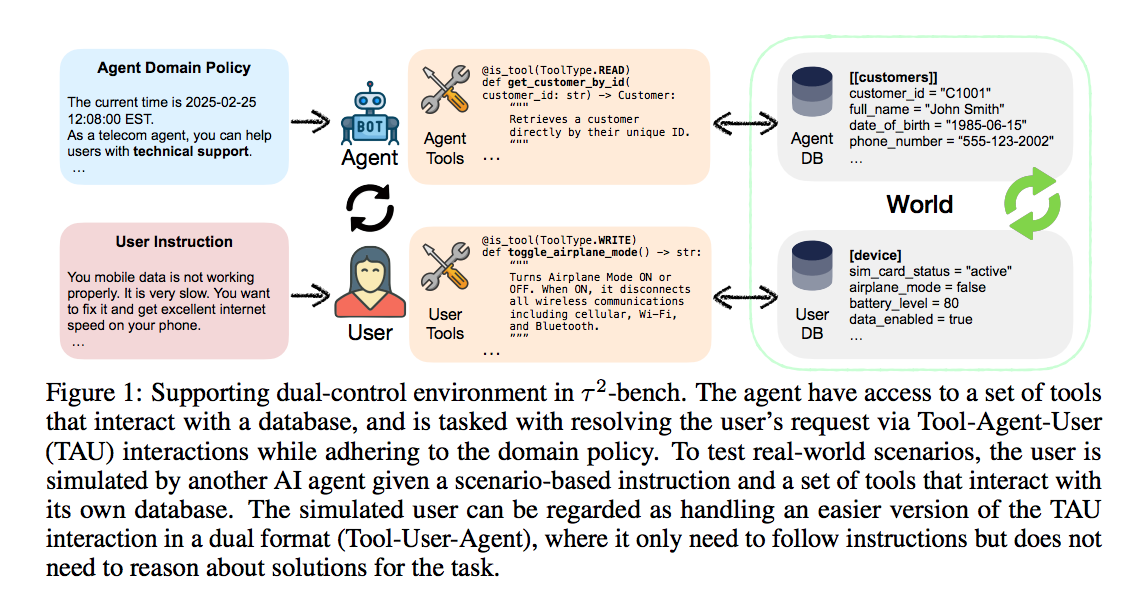
tau-bench
https://github.com/sierra-research/tau-bench
τ2-Bench: Evaluating Conversational Agents in a Dual-Control Environment
https://arxiv.org/abs/2506.07982
4 AgentBench
AgentBench是一个综合的agent benchmark套件,从多个维度如操作系统操作、数据库操作、知识图谱查询、游戏、网页浏览等评估Agent 的能力,评估相对更全面。
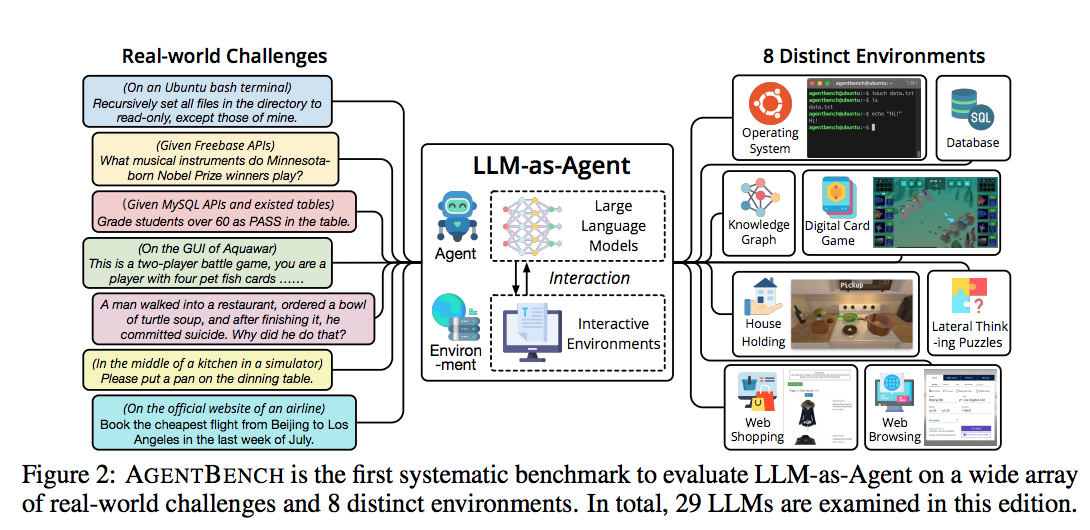
AgentBench
https://github.com/THUDM/AgentBench
AgentBench: Evaluating LLMs as Agents
https://arxiv.org/abs/2308.03688
5 WebArena/WebVoyager
WebArena、WebVoyager专注于评估 Agent 在真实网页环境中完成复杂任务的能力,比如预订机票、在线购物、查找信息等。
该类benchmark测试Agent的视觉理解、HTML 解析、交互鲁棒性。更接近真实应用世界。
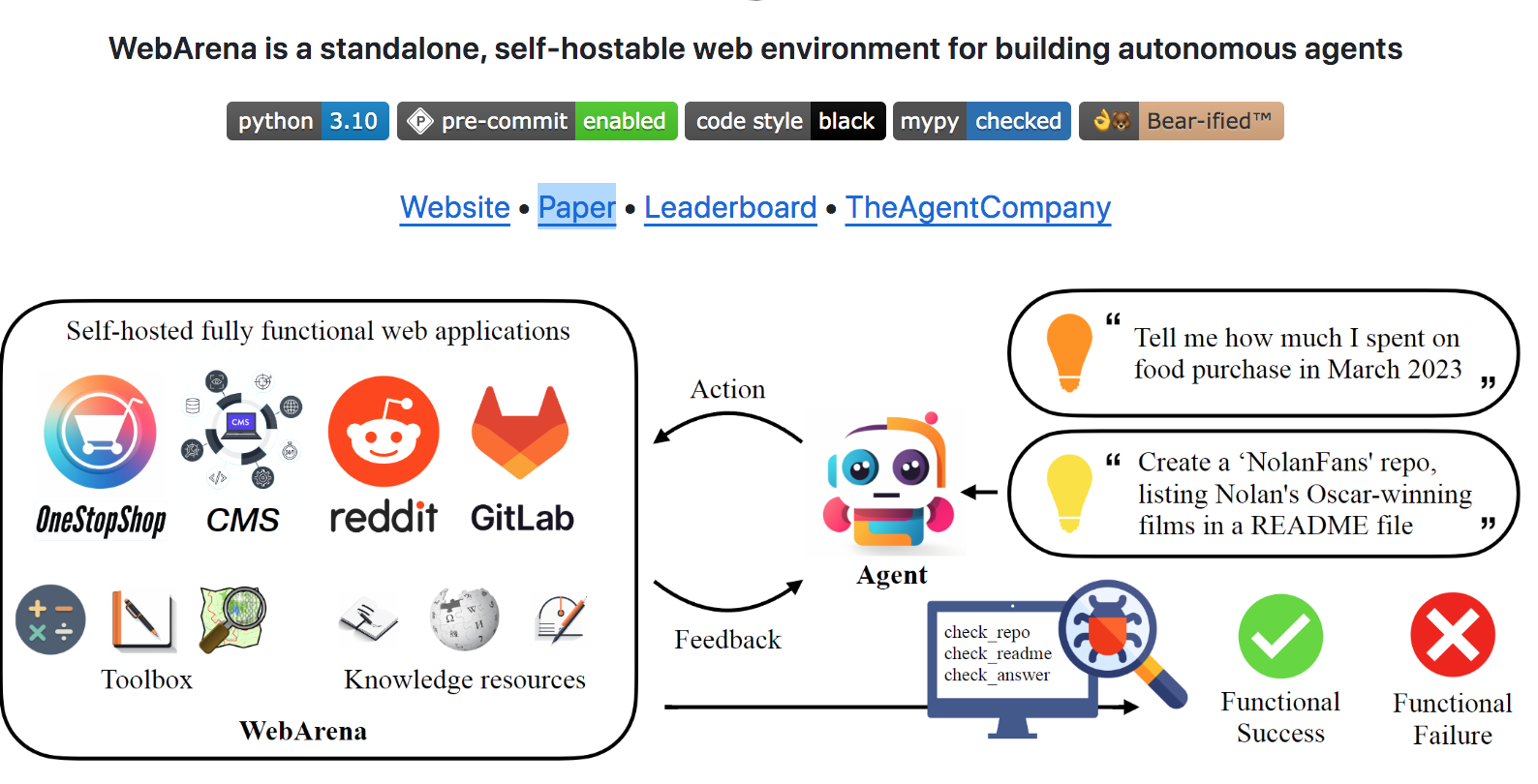
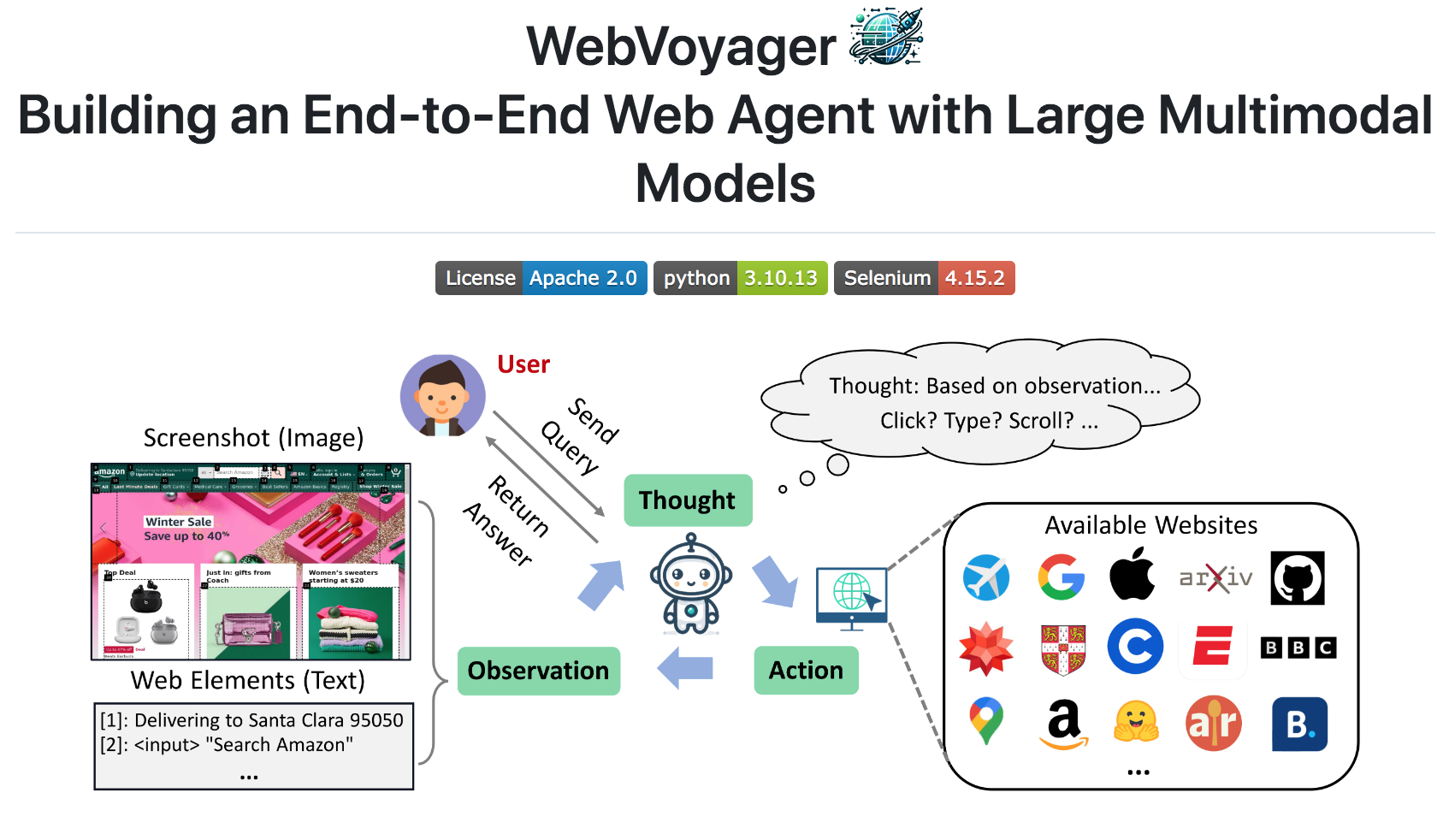
webarena
https://github.com/web-arena-x/webarena
WebArena: A Realistic Web Environment for Building Autonomous Agents
https://arxiv.org/abs/2307.13854
WebVoyager
https://github.com/MinorJerry/WebVoyager
WebVoyager: Building an End-to-End Web Agent with Large Multimodal Models
https://arxiv.org/abs/2401.13919
6 SWE-Bench
SWE-bench专注于评估agent解决真实github仓库项目的软件问题,如修复 bug、添加功能。
SWE-Bench是代码生成领域评估Agent能力的重要标准。

swe-bench
https://www.swebench.com/
SWE-bench
https://github.com/swe-bench/SWE-bench
SWE-bench Multimodal: Do AI Systems Generalize to Visual Software Domains?
https://arxiv.org/pdf/2410.03859
7 Mind2Web
Mind2Web则针对跨网站复杂任务,评估Agent能否理解高层指令,并在多个不同网站之间导航,以交互的方式完成目标。
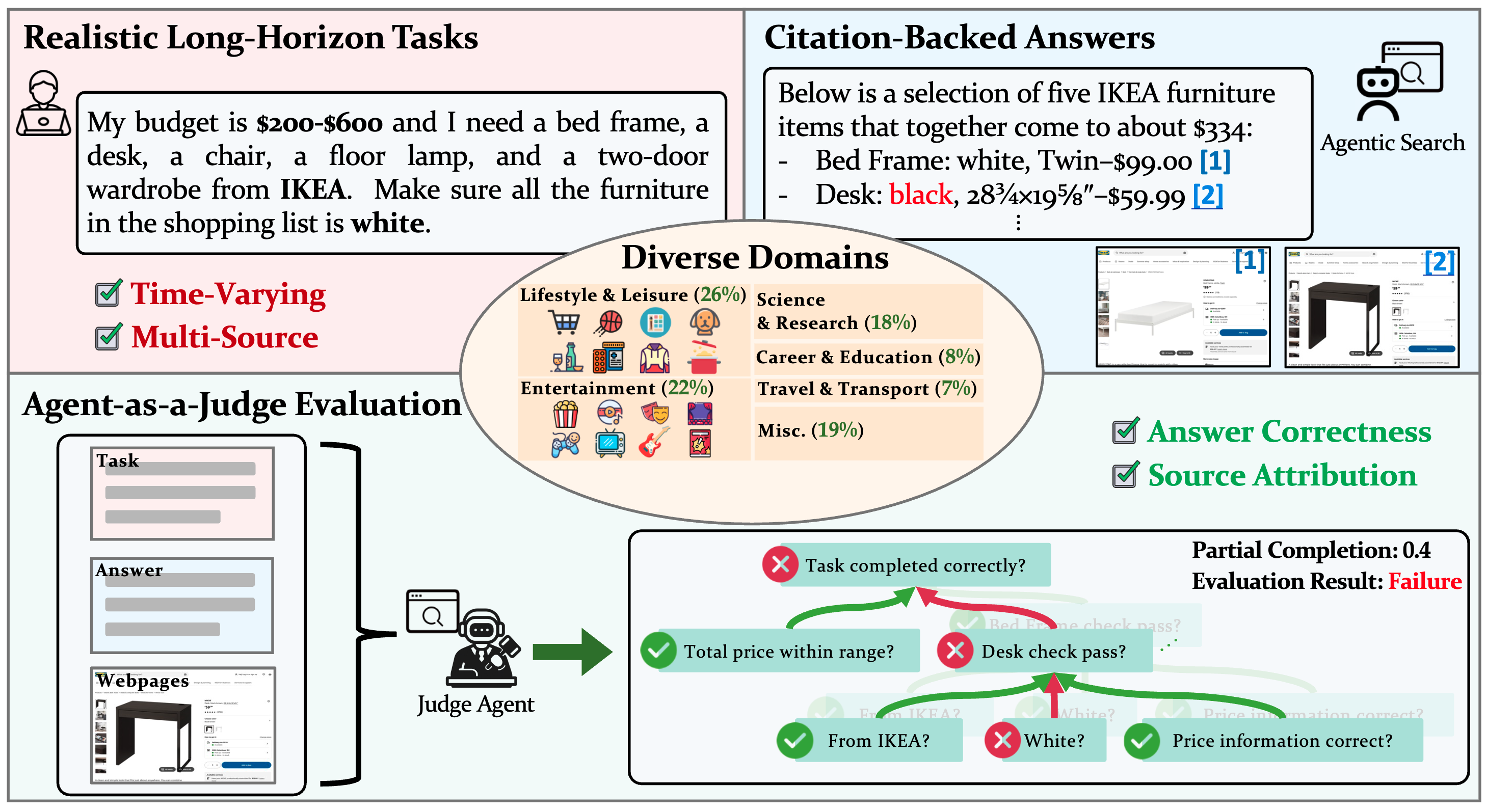
Mind2Web
https://github.com/OSU-NLP-Group/Mind2Web
Mind2Web 2: Evaluating Agentic Search with Agent-as-a-Judge
https://arxiv.org/abs/2506.21506
Mind2Web-2
https://osu-nlp-group.github.io/Mind2Web-2/
Mind2Web-2
https://github.com/OSU-NLP-Group/Mind2Web-2
总结
这些 benchmark对比不同方法、不同模型之间的相对优劣,也能测出Agent在特定技能上的表现,比如工具调用、信息检索、代码生成等。benchmark 环境通常是简化、净化过的,而真实世界充满了噪声、歧义、不确定性、动态变化,API 可能不稳定、文档可能过时、用户需求可能反复无常。benchmark也会不断进化,适应越来越复杂的真实世界场景。
reference
---
现在评估Agent有哪些有代表性的Benchmark?
https://www.zhihu.com/question/1890240528236393875/answer/1890257521496794046