如何制作境外网站新网 如何建设网站
RLPR: Extrapolating RLVR to General Domains without Verifiers![]() https://arxiv.org/pdf/2506.18254v1
https://arxiv.org/pdf/2506.18254v1
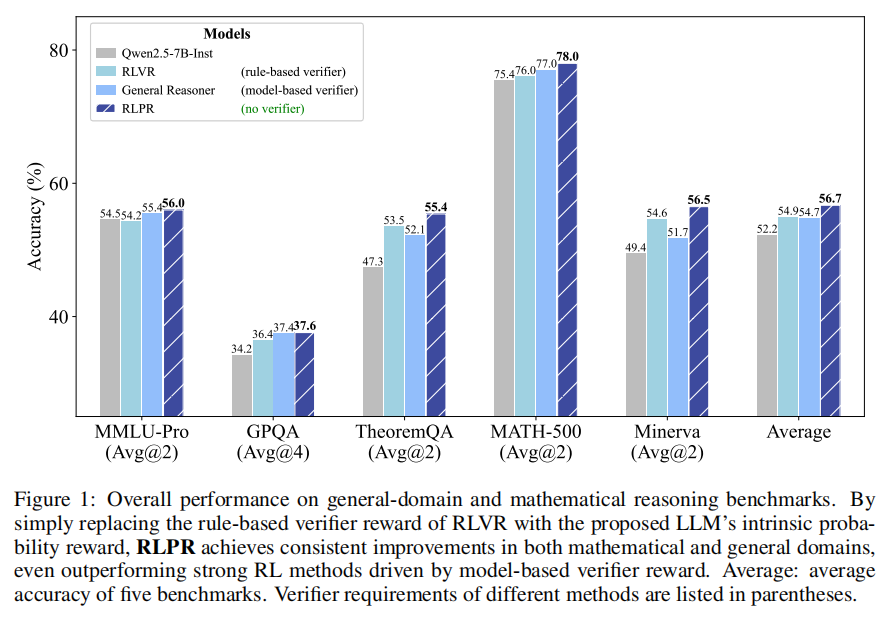
1.概述
大规模的可验证奖励强化学习(RLVR)已成为提升大型语言模型(LLMs)推理能力的有前途的范式(Jaech et al., 2024; DeepSeek-AI et al.,
RLPR: Extrapolating RLVR to General Domains without Verifiers![]() https://arxiv.org/pdf/2506.18254v1
https://arxiv.org/pdf/2506.18254v1
大规模的可验证奖励强化学习(RLVR)已成为提升大型语言模型(LLMs)推理能力的有前途的范式(Jaech et al., 2024; DeepSeek-AI et al.,