【Linux系统编程】自动化构建-make/Makefile
【Linux系统编程】自动化构建-make/Makefile
- 1. 为什么要用make?
- 2. Makefile的基本结构
- 3. Makefile中头文件依赖问题
- 4. Makefile进阶用法与技巧
1. 为什么要用make?
想象一下你正在开发一个C/C++项目,它由以下几个文件组成:
main.c
test.c
process.c
process.h(被所有的.c文件引用)
要生成最终的可执行文件code,你需要执行以下步骤:
gcc -c main.c -o main.o
gcc -c test.c -o test.o
gcc -c process.c -o process.o
gcc main.o test.o process.o -o code
每次修改一个文件,你都要重新执行所有命令。对于大项目,这非常耗时。
make的诞生就是为了解决这个问题:
- 自动化: 只需要一个命令make,自动完成所有构建步骤。
- 增量构建/只能编译:make非常聪明,它能根据文件的修改时间来判断哪些文件需要重新编译。比如:在上面的例子中,如果你只修改了process.c,make只会执行:
gcc -c process.c -o process.o
gcc main.o test.o process.o -o code
它跳过了main.o和test.o的编译,因为它们对应的源文件没有变化,从而极大地加快了构建速度。
2. Makefile的基本结构
Makefile 告诉 make 要做什么。它的核心由一系列规则构成。
一个规则的典型结构如下:
target:prerequisites
<Tab>recipe
- target(目标):规则所要生成的文件名(例如main.o)或是一个动作的名称(例如clean,这个下面讲到伪目标就懂了)。
- prerequisites(先决条件):生成 target 所需要的文件或其他目标(例如main.c,process.h)。这些是 target 的依赖。
- recipe(配方):由先决条件到目标所需要的命令(例如gcc -c main.c -o main.o)。注意:每行命令前必须要按一个Tab键,而不是空格。
一个简单的例子
将我们开头的编译命令写成 Makefile
# 最终目标
code:main.o test.o process.ogcc main.o test.o process.o -o code# 各个中间目标
main.o:main.c process.hgcc -c main.c -o main.otest.o:test.c process.hgcc -c test.c -o test.oprocess.o:process.c process.hgcc -c process.c -o process.o
工作原理:
- 当你在终端输入 make 时,make 会默认寻找当前目录下的 Makefile 文件,并执行文件中的第一个目标(在这里是code)。
- 为了构建 code,它发现 code 依赖于 main.o, test.o, process.o。
- 接着它会检查这些 .o 文件是否存在,以及它们的依赖项(.c 和 .h 文件)的修改时间是否比 .o 文件更新。
- 如果某个依赖项比目标文件新(比如你修改了 test.c,那么 test.c 就比 test.o 新),或者目标文件不存在,make 就会执行该目标下的配方来重新生成它。
- 一旦所有依赖项都是最新的了,make 最后执行生成 code 的配方。
伪目标(Phony Targets)
有些目标并不是要生成一个实际的文件,而是代表一个动作,比如清理构建文件。
clean:rm -f main.o test.o process.o code
如果你的目录下恰好有一个名为 clean 的文件,再执行 make clean 时,make 会发现 clean 文件已经存在,并且没有依赖,于是会认为它是最新的,从而不执行 rm 命令。
为了解决这个问题,我们需要将其声明为伪目标:
.PHONY:clean
clean:rm -f main.o test.o process.o code
这样,每次执行 make clean,make 都会无条件地执行其配方。
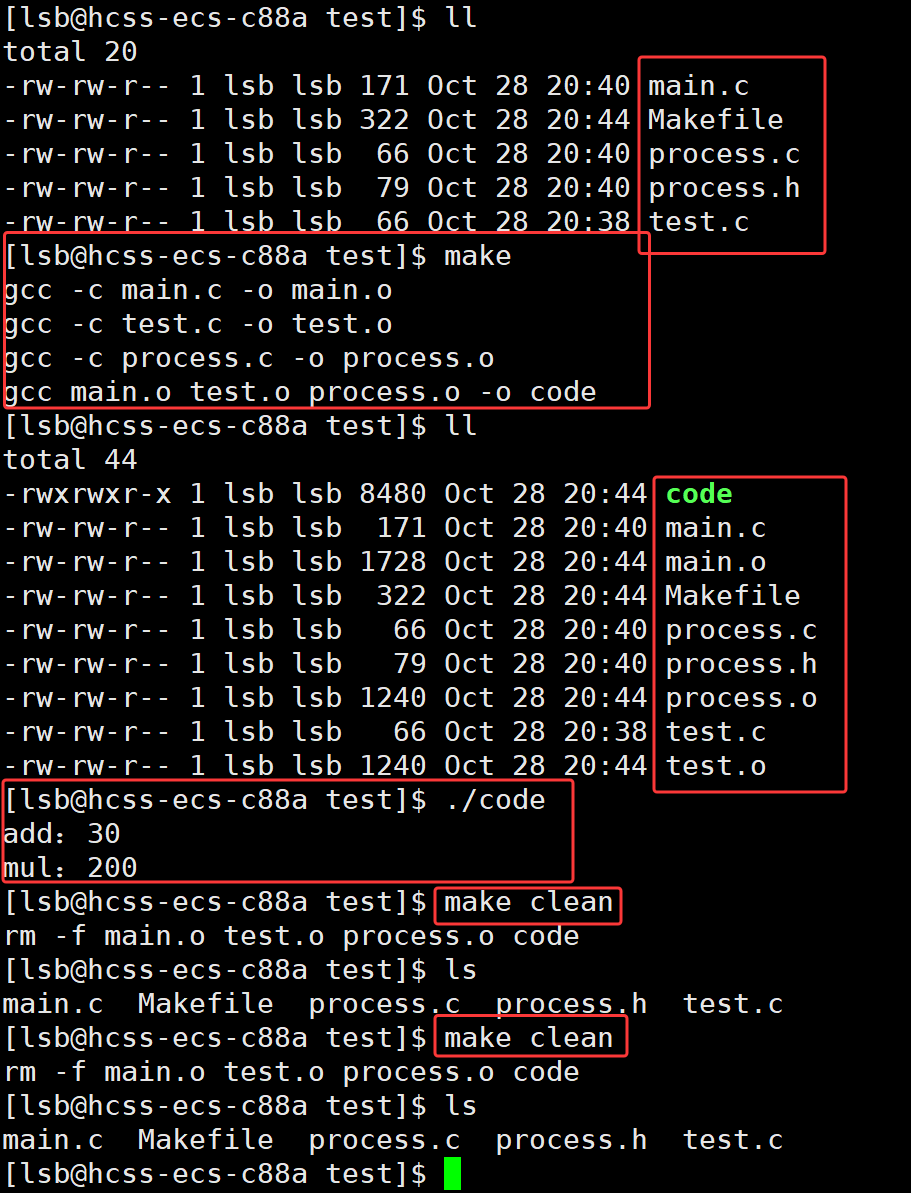
下面我们实际去测试一下上面的主要流程
// main.c
#include "process.h"int main()
{int ret1 = add(10, 20);int ret2 = mul(10, 20);printf("add:%d\n", ret1);printf("mul:%d\n", ret2); return 0;
}// test.c
#include "process.h" int add(int a, int b)
{ return a + b;
} // process.c
#include "process.h" int mul(int a, int b)
{ return a * b;
} // process.h
#pragma once
#include <stdio.h> int add(int a, int b);
int mul(int a, int b);
// Makefile
# 最终目标
code:main.o test.o process.ogcc main.o test.o process.o -o code# 各个中间目标
main.o:main.c process.hgcc -c main.c -o main.otest.o:test.c process.h gcc -c test.c -o test.oprocess.o:process.c process.hgcc -c process.c -o process.o.PHONY:clean
clean:rm -f main.o test.o process.o code
3. Makefile中头文件依赖问题
// Makefile
# 最终目标
code:main.o test.o process.ogcc main.o test.o process.o -o code# 各个中间目标
main.o:main.c process.hgcc -c main.c -o main.otest.o:test.c process.h gcc -c test.c -o test.oprocess.o:process.c process.hgcc -c process.c -o process.o.PHONY:clean
clean:rm -f main.o test.o process.o code
该Makefile中的头文件依赖可以不写吗?为什么?
这是一个非常好的问题,涉及到 Makefile 依赖关系的核心细节。
简短回答:
可以,但不推荐。不写 process.h 在很多简单情况下程序依然能编译成功,但这破坏了 make 的正确依赖关系,可能导致难以发现的构建错误。
详细解释
1. 不写 process.h 会发生什么?
main.o: main.c process.hgcc -c main.c -o main.o
当前行为(有 process.h):如果你修改了 process.h 文件,make 会发现 process.h 的修改时间比 main.o 新,于是重新执行 gcc -c main.c -o main.o,重新编译 main.o。这是正确的。
如果去掉 header.h:
main.o: main.cgcc -c main.c -o main.o
现在,make 只关心 main.c。如果你只修改了 process.h,make 会认为 main.o 是最新的(因为它的依赖 main.c 没变),从而不会重新编译 main.o。
2. 什么时候可以不写?
在极其简单的情况下,比如:
头文件只包含函数声明,没有定义。
你确定头文件的修改不会影响二进制目标文件(.o)的生成。
或者你每次都会执行 make clean && make 来强制全部重新编译。
但作为一种最佳实践,你应该总是列出所有依赖。
4. Makefile进阶用法与技巧
基本的 Makefile 已经能工作了,但我们可以让它更强大、更简洁。
使用变量可以让 Makefile 更易于维护和修改。
# 定义变量
BIN=code
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o)
CC=gcc $(BIN):$(OBJ) $(CC) $^ -o $@
%.o:%.c $(CC) -c $< .PHONY:clean
clean: rm -f $(OBJ) $(BIN)
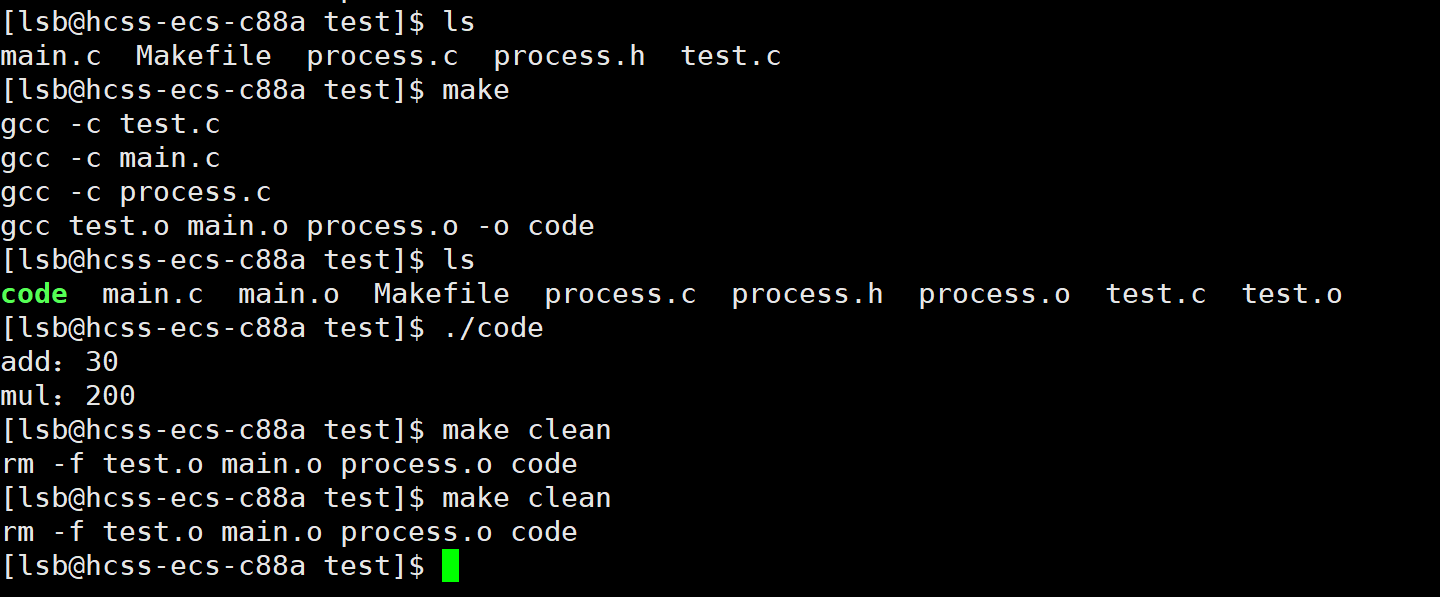
下面对每句代码进行解释
BIN=code
定义变量 BIN,值为 code,这个变量代表最终生成的可执行文件的名称,如果要改变程序名,只需要修改这里。
SRC=$(wildcard *.c)
$(变量名)是获取变量中的值;使用 wildcard 函数自动获取所有 .c 文件;
wildcard 是 Makefile 的内置函数; * .c 是通配符模式,匹配所有 .c 文件;
优点:自动发现源文件,添加新 .c 文件时无需修改 Makefile
OBJ=$(SRC:.c=.o)
将源文件名列表转换为目标文件名列表;
将 SRC 变量中所有的 .c 替换为 .o;
用途:生成编译过程中需要的中间目标文件列表
CC=gcc
定义使用的 C 编译器
$(BIN):$(OBJ) $(CC) $^ -o $@
最终目标规则:
目标:$ (BIN) 即 code
依赖:$ (OBJ) 即所有的 .o 文件
命令:$ (CC) $^ -o $@
$(CC) 展开为 gcc
$^ 是自动变量,代表所有依赖文件(所有的 .o 文件)
-o $@ 中 $@ 是自动变量,代表目标文件名(code)
作用:将所有的 .o 文件链接成最终的可执行文件
%.o:%.c$(CC) -c $<
模式规则:
模式:%.o:%.c
% 是通配符,匹配任意文件名
命令:$(CC) -c $<
$< 是自动变量,代表第一个依赖文件(即 .c 文件)
作用:将每个 .c 源文件编译成对应的 .o 目标文件
.PHONY:clean
clean: rm -f $(OBJ) $(BIN)
清理规则:
rm -f 强制删除文件,不提示错误
$(OBJ) 展开为所有 .o 文件
$(BIN) 展开为可执行文件 code
作用:清理所有编译生成的文件
自动变量总结
$@:规则的目标文件名。
$<:第一个依赖文件的名称。
$^:所有依赖文件的列表,以空格分隔。