合肥网站建设网页设计爱上链外链购买平台
一.获取和操作网页元素
1.获取网页中的指定元素
tag_name()方法:获取元素名称。
text()方法:获取元素文本内容。
click()方法():点击此元素。
submit()方法():提交表单。
send_keys()方法:模拟输入信息。
size()方法:获取元素的尺寸
可进入selenium库文件夹下的webdriver\remote\webelement.py中查看更多的操作方法,
2.在元素中输入信息
send_keys()方法可以在元素中输入信息,使用格式如下:
send_keys(*value)
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
chrome_options = Options()
chrome_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=chrome_options)
driver.get('https://www.ptpress.com.cn/')
ele = driver.find_element(by=By.TAG_NAME,value="input").send_keys("python")
a=input("")第8行代码使用find_element(by=By.TAG_NAME,value='inut')方法找到标签名为input的元素(通过网页源代码可知搜索框的标签名位input)获取到标签后使用send_keys()方法实现在搜索框内输入字符串"python"。获取元素的方法比较多,可按照不同的方法灵活实现。
实现在搜索框中输入信息的代码程序后,还可以模拟用户的按键操作,其使用方法为在字符串后面继续增加按键转义字符串信息。示例代码:
from selenium import webdriver
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
chrome_options = Options()
chrome_options.binary_location = r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver = webdriver.Edge(options=chrome_options)
driver.get('https://www.ptpress.com.cn/')
ele = driver.find_element(by=By.TAG_NAME,value="input").send_keys("python"+Keys.RETURN)
a=input("")该示例代码在上一示例代码的基础上只对第8行代码做了修改。第8行代码在send_keys()方法中增
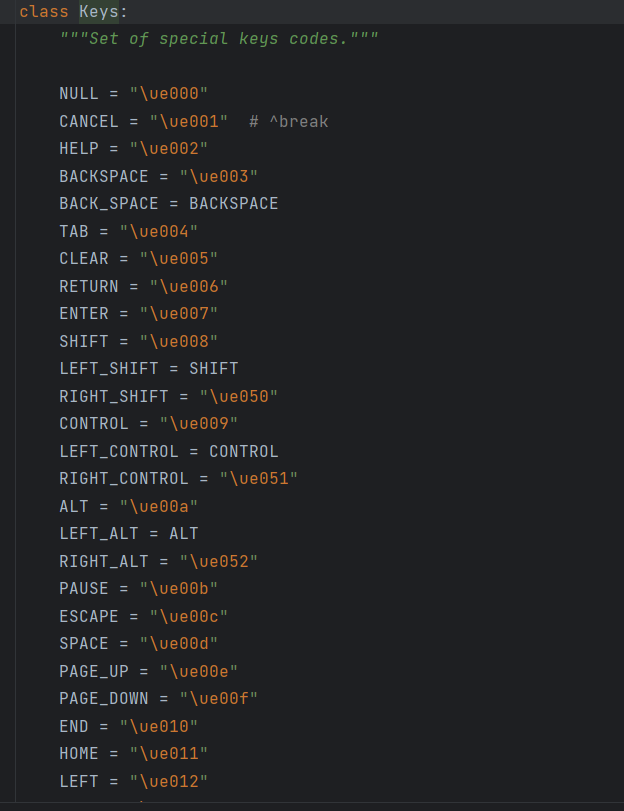
加了Keys.RETURN,Keys.RETURN表示按Enter键。类Keys 中定义了大部分按键的转义字符串。
二.小项目案例:实现上传图片。
项目任务
实现在百度识图官网中上传一张图片。
项日实现代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
edge_options=Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver=webdriver.Edge(options=edge_options)
driver.get("https://graph.baidu.com/pcpage/index?tpl_from=pc")
input_element=driver.find_element(by=By.NAME,value="file")
input_element.send_keys(r'C:\Users\23967\Desktop\befa5206fc1edb77630036d55c9b39b.jpg')
a=input('')第7行代码使用find_element(by=By.NAME,value='file')方法找到标签名为file的元素。
第8行代码直接使用send_keys()方法将图片路径以字符串的形式写入标签名为file的元素中,至此即可实现上传图片。
三.更多操作
1.模拟单击
获取网页元素可以使用click()实现单击该元素,即模拟单击网页中的某个元素所在的位置。为了更方便且快速地自动进入需要访问的网页,示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
edge_options=Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver=webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/periodical')
elments = driver.find_elements(by=By.CLASS_NAME,value='item')
i = 0
for elment in elments:print(i,'个',elment.text)i += 1
elments[3].click()第7行代码使用find_elements(by=By.CLASS_NAME,value='item')找到所有class名为item的元素。通过分析网页源代码可知要点击的位置存在多个元素名称及class名称相同的元素,因此使用find_elements(by=By.CLASS_NAME,value='item')前要先获取class名称为item的所有元素。
第8一11行代码使用for循环分别遍历输出每个元素的内容,以便于找到需要的标签索引号。
第12行代码确定了“图书”在elments列表中的索引号为3,并执行click()方法实现单击。
2.WebDriver对象中的方法
back()功能:返回到上一个页面。
forward()功能:前进到下一个页面。
refresh() 功能:刷新当前页面。
quit()功能:关闭当前浏览器。
close()功能:关闭当前标签页(一个浏览器窗口中展示的每一个网页为一个标签页,当前标签页指当前正在显示的网页。
示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
import time
edge_options=Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver=webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/periodical')
elments = driver.find_elements(by=By.CLASS_NAME,value='item')
elments[3].click() #点击图书
driver.back() #返回上一页
time.sleep(2)
driver.forward() #前进一页
time.sleep(2)
driver.refresh() #刷新网页
time.sleep(2)
driver.quit() #关闭浏览器
第1~9行代码与上一示例代码基本相同,即打开人民邮电出版社官网,并单击“图书”进入图书页。
第10行代码使用back()方法实现返回上一个页面,即从图书页返回到官网主页。
第12行代码使用forward()方法再次从官网主页前进到图书页。
第14行代码使用refresh(方法实现刷新页面。
第16行代码使用quit()方法自动关闭当前的浏览器。
3.不启动浏览器也能获取网页资源
在通过代码获取网页中的资源时,往往并不需要启动浏览器,因为用户需要获取的是处理后的结果,而不是处理的过程。因此在驱动浏览器时,可以设置无窗口模式,即驱动浏览器后并不会打开浏览器窗口,而是将网页代码在内存中处理,类Options中的add_argument()方法即可实现在不启动浏览器的情况下获取网页资源。其使用形式如下
options().add_argument('--headless')示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.edge.options import Options
import time
edge_options=Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
edge_options.add_argument('--headless')
driver=webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/periodical')
elments = driver.find_elements(by=By.CLASS_NAME,value='item')四.项目案列:实现获取图书数据
项目描述:在工作中我们常常需要获取某网站中某款商品的全部信息,例如销量、价格、店铺名称等,以便于分析该商品目前的市场情形。例如工作人员需要统计人民邮电出版社官网中与关键词“python有关的全部图书,包含书名,价格,作者等信息并将获取的信息写入“python图书汇总,txt”文件中。
项目实现步骤:步骤1,使用selenium库实现在人民邮电出版社官网中搜索关键词为“python”的图书,
步骤2,由于该网站存在多个页面,因此需要单击标注框处的“更多”,单击后将会键词“python”有关的全部图书内容。
步骤3,在网页中使用元素查找方法确定与关键词“python”有关的图书信息的元素。这一步的难点在何确定元素,读者需要提前在网页源代码中查询需要获取的信息的元素特征,这是因为包含特征的元素更便于使用代码来进行查找。
步骤4,在每一页中获取完全部信息后,单击“下一页”。
步骤5,在获取信息的同时使用open()函数依次将元素的内容写入TXT文本中。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.edge.options import Options
import time
def get_info(driver):time.sleep(3)elements_p=driver.find_elements(by=By.CLASS_NAME,value="book_item")for element_p in elements_p:element_p.click()handles=driver.window_handlesdriver.switch_to.window(handles[-1])time.sleep(3)name=driver.find_element(by=By.CLASS_NAME,value="book-name").textauthor=driver.find_element(by=By.CLASS_NAME,value='book-author').textprice=driver.find_element(by=By.CLASS_NAME,value='price').textfile.write('书名:{}\t价格:{}\t作者:{}\n'.format(name,price,author))driver.close()handles=driver.window_handlesdriver.switch_to.window(handles[-1])
file=open('python图书.TXT','w',encoding='utf-8')
edge_options=Options()
edge_options.binary_location=r"C:\Program Files (x86)\Microsoft\Edge\Application\msedge.exe"
driver=webdriver.Edge(options=edge_options)
driver.get('https://www.ptpress.com.cn/')
elements=driver.find_element(by=By.TAG_NAME,value="input").send_keys('python'+Keys.RETURN)
handles=driver.window_handles
driver.switch_to.window(handles[-1])
driver.find_element(by=By.ID,value='booksMore').click()
handles=driver.window_handles
driver.switch_to.window(handles[-1])
get_info(driver)
while True:driver.find_element(by=By.CLASS_NAME,value='ivu-page-next')get_info(driver)
file.close()第5~19行代码定义了函数get_info(,其主要功能为分析每一页中与关键词“Excel”有关的图书信息。第10行代码中的window_handles()方法用于获取当前网页中的全部标签页(一个浏览器窗口中所展示的全部网页)并以列表的形式返回。第11行代码使用switch_to.window()方法(功能为切换标签页)进入对应标签页并获取指定的内容。
第20行代码用于创建一个文件“python图书汇总.TXT”,此后会将所有获取的信息写入该文件。
第23行代码add_argument('--headless')方法用于设置浏览器打开模式为无窗口模式。当在开始设计代码时,为了便于观察操作网页的效果,建议不要设置无窗口模式。当整个程序设计结束后,验证结果无误,为了提高代码执行速度(无界面模式仅为不展示真实的窗口,其他操作仍然会真实地在内存中运行,可提高运行速度),可以设置浏览器打开模式为无窗口模式。
第25~27行代码用于获取人民邮电出版社官网中与关键词“python”有关的图书页面。第30行代码用于单击网页中的“更多”按钮。
第33行代码调用函数get_info()获取单击“更多”按钮后出现的第1个网页中的图书信息。第34~36行代码使用while循环获取单击“下一页”按钮之后出现的信息。