Transformer整体结构与自注意力机制的实现
都听过GPT、ChatGPT、BERT这些名称,它们的核心都基于同一个架构Transformer,Transformer是一种用于自然语言处理(NLP)和其他序列到序列(sequence-to-sequence)任务的深度学习模型架构。2017年,谷歌《Attention Is All You Need》论文提出的这一模型,彻底改变了自然语言处理的格局。下面我们将深入解析一下Transformer的内部结构与自注意力机制的实现。
一、传统序列模型的局限性
在Transformer之前,循环神经网络(RNN) 及其变体LSTM是处理序列数据的主流选择。RNN按顺序处理输入,如同人类逐字阅读:
- 顺序依赖:必须等待前一个时间步计算完成才能处理下一个,难以并行化
- 长期依赖衰减:信息在长序列中传递时会逐渐衰减或爆炸
- 计算效率低下:无法充分利用现代GPU的并行计算能力
二、Transformer整体架构揭秘
Transformer采用的编码器-解码器结构,但其实现方式完全突破了序列模型的限制。
Transformer整体结构:
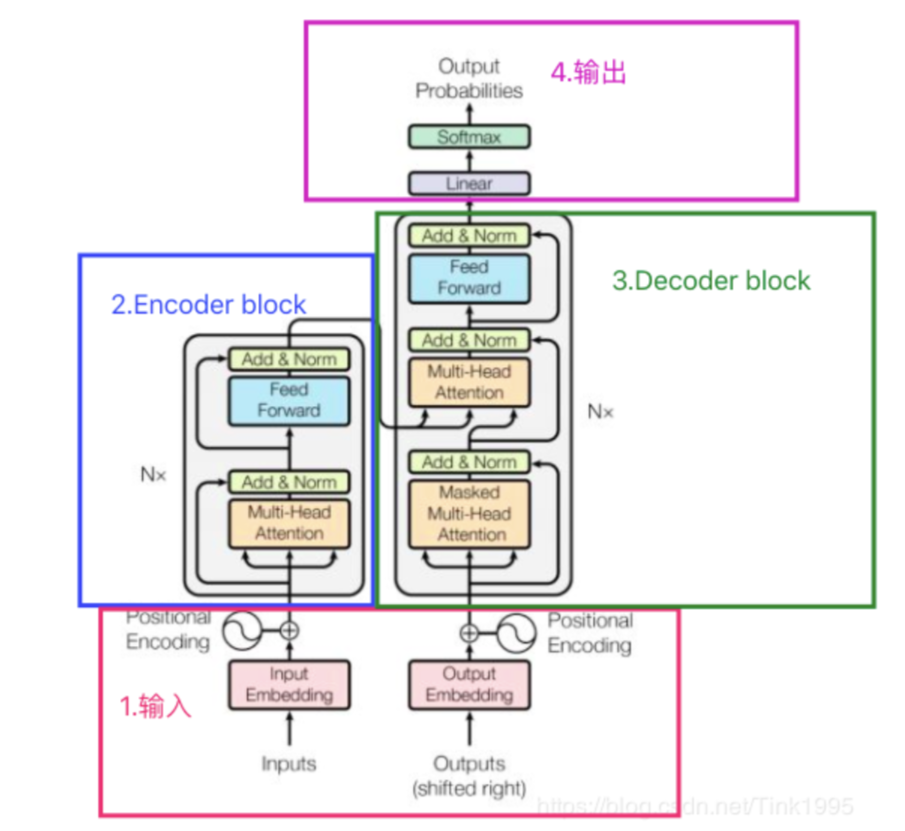
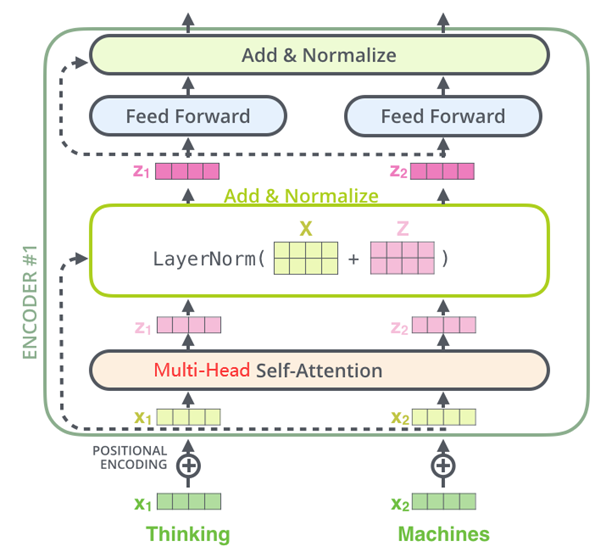
编码器(Encoder)
编码器由N个完全相同的层堆叠而成。每一层都包含两个核心子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Position-wise Feed-Forward Network)
每个子层都采用残差连接(Residual Connection)和层归一化(Layer Normalization),即:
Output = LayerNorm(x + Sublayer(x))
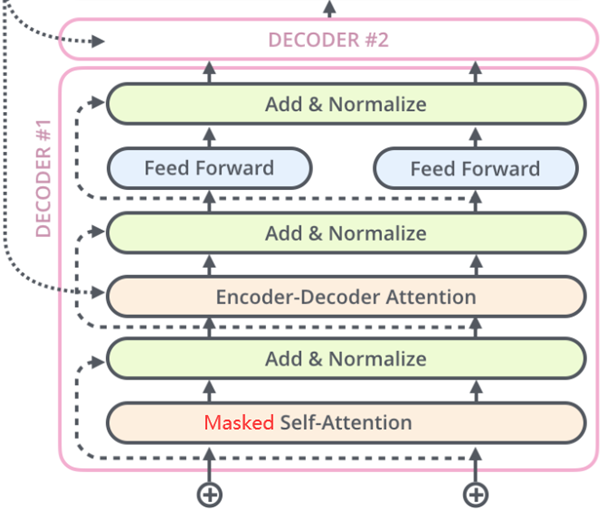
解码器栈(Decoder)
解码器同样由N个相同层堆叠,但结构更加复杂:
- 掩码多头自注意力机制(Masked Multi-Head Self-Attention)
- 编码器-解码器注意力机制(Encoder-Decoder Attention)
- 前馈神经网络
三、自注意力机制
自注意力是Transformer的核心创新,让我们逐步拆解其实现过程。
步骤1:输入表示与位置编码
首先,每个输入词元被转换为词嵌入向量。但由于自注意力本身不包含位置信息,我们需要加入位置编码(Positional Encoding):
位置编码transformer采用sin-cos位置编码,下面是数学公式
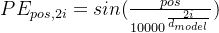
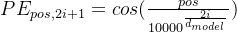
其中pos是位置,i是维度索引。
得到位置编码后与输入词向量相加然后输入编码器
步骤2:查询、键、值矩阵的生成
对于每个输入词嵌入矩阵,我们通过线性变换生成三个向量qkv:
- 查询向量(Q):表示"我正在寻找什么"
- 键向量(K):表示"我包含什么信息"
- 值向量(V):表示"我的实际内容是什么"
数学表达:Q = XW^Q, K = XW^K, V = XW^V
其中X是输入矩阵,W^Q, W^K, W^V是可学习的权重矩阵。
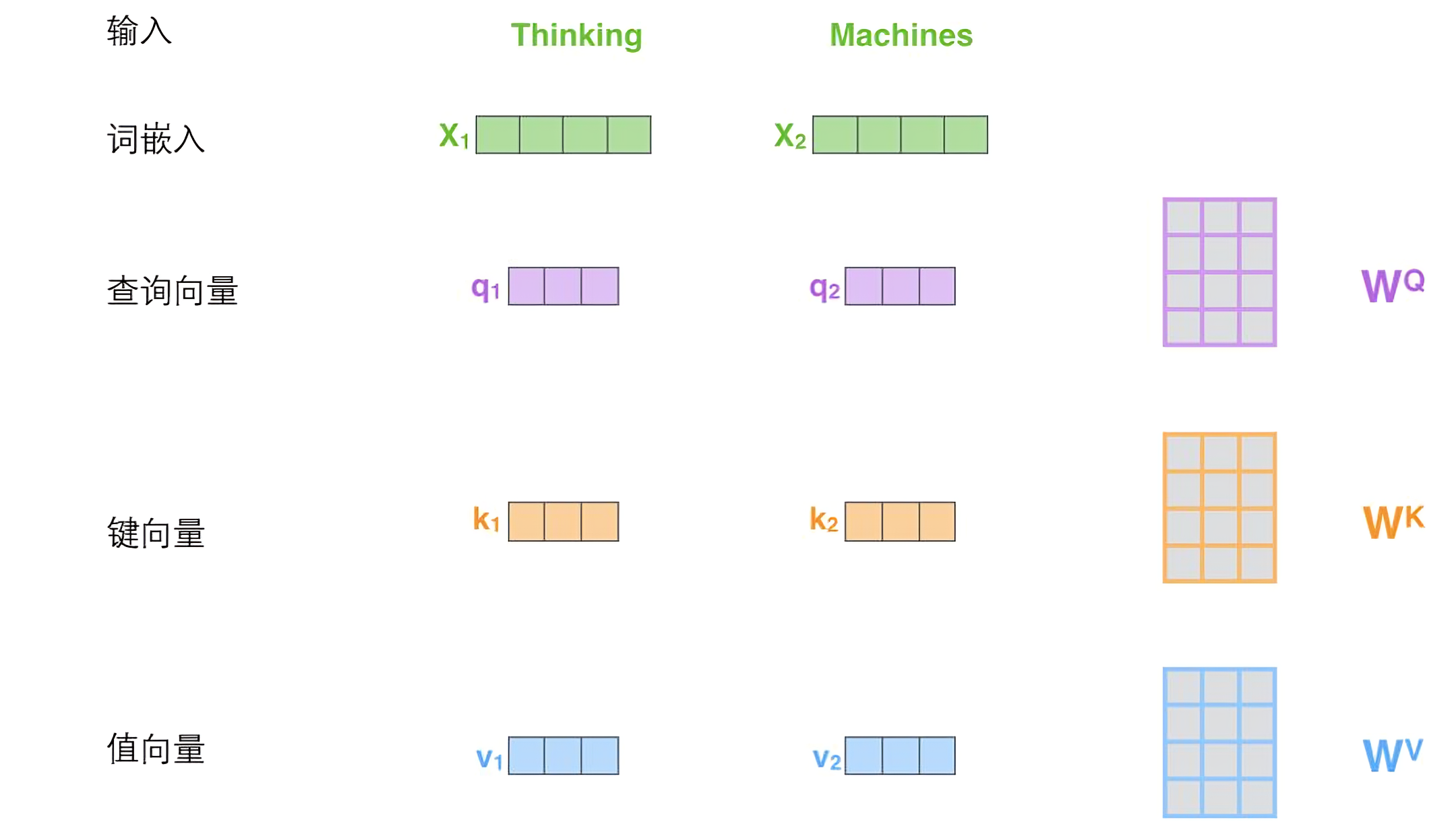
步骤3:注意力分数的计算
计算Thinking与与其他词的关注程度,用Thinking查询向量与每个词(包含Thinking)的键向量点积后得到分数,根据点击后的得分我们可以判断向量的相关性
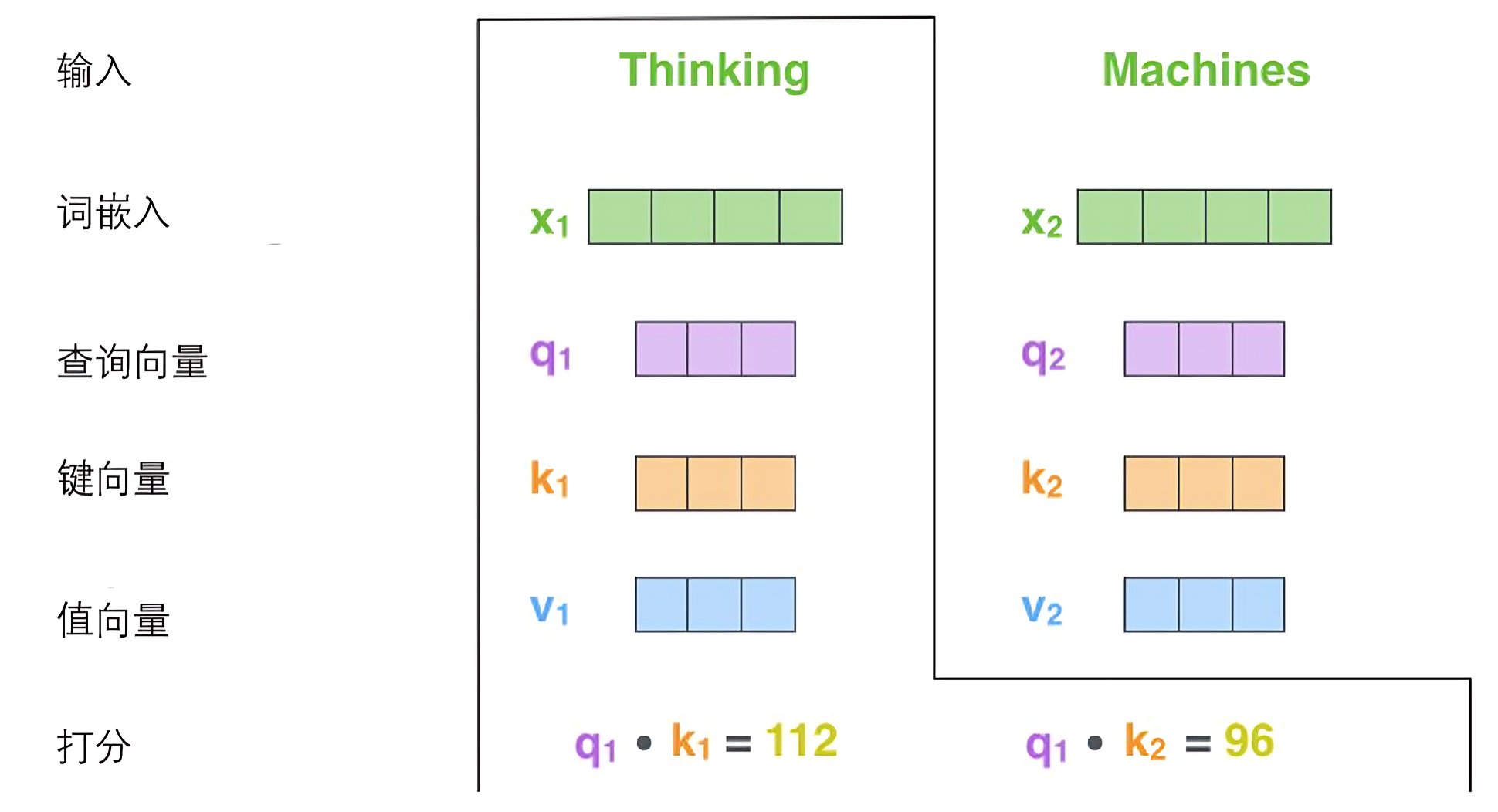
步骤4:Softmax归一化与加权求和
通过softmax函数将注意力分数转换为概率分布,然后对值向量进行加权求和:
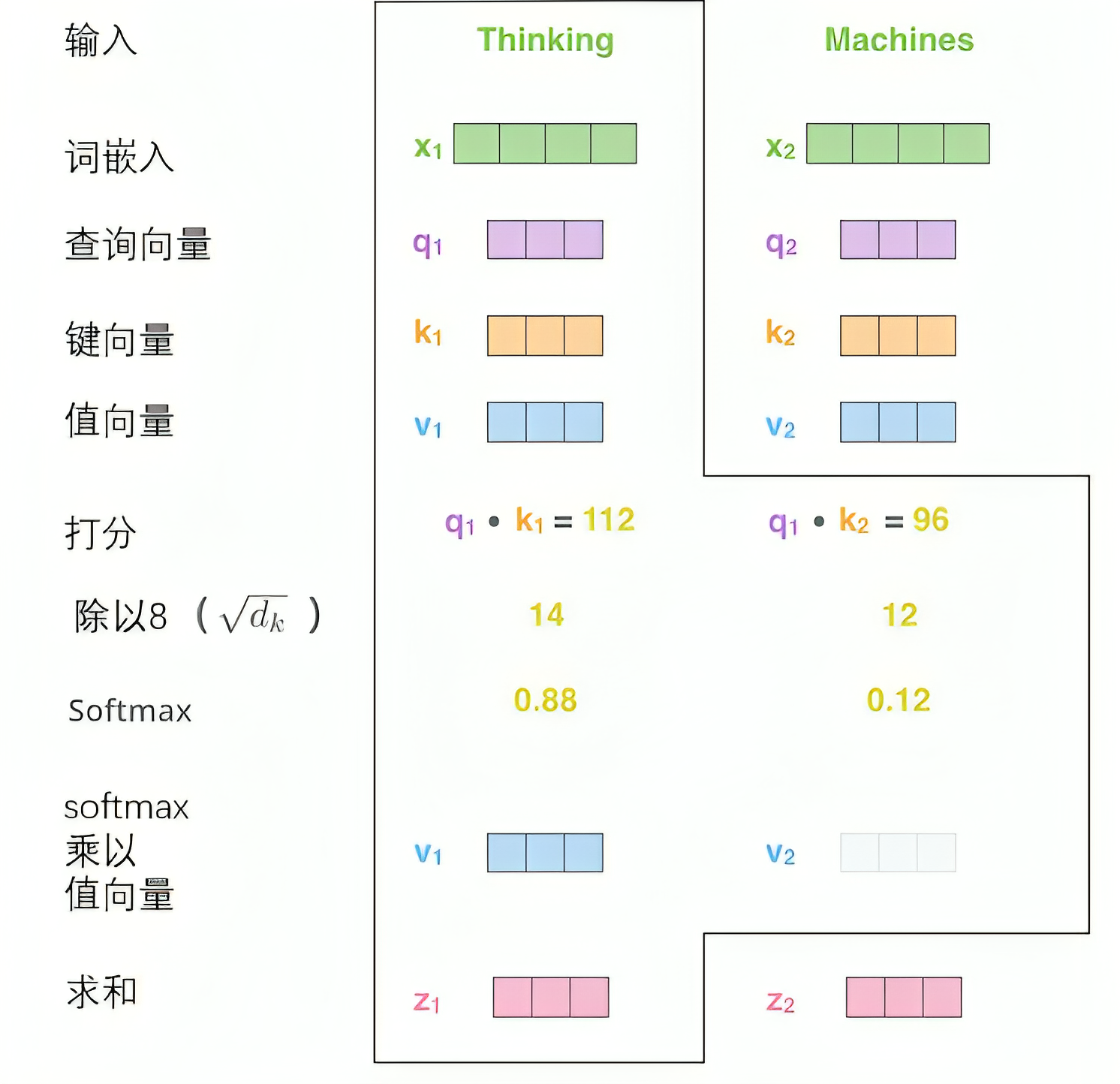
最终每个词的输出向量z_i都包含了其他词的信息,每个词都不再是孤立的了,而且词与词的相关程度可以通过softmax输出的权重进行分析。如此,所有单词的自注意力计算就完成了,得到的向量就可以传给前馈神经网络。
四、多头注意力
单一注意力机制可能不够丰富,Transformer引入了多头注意力:
在transformer中有多组查询/键/值权重矩阵集,输入向量可以被映射到不同的子表达空间中,在多头注意力机制下,每个头都有WQ,WK,WV的矩阵获得独立的QKV矩阵
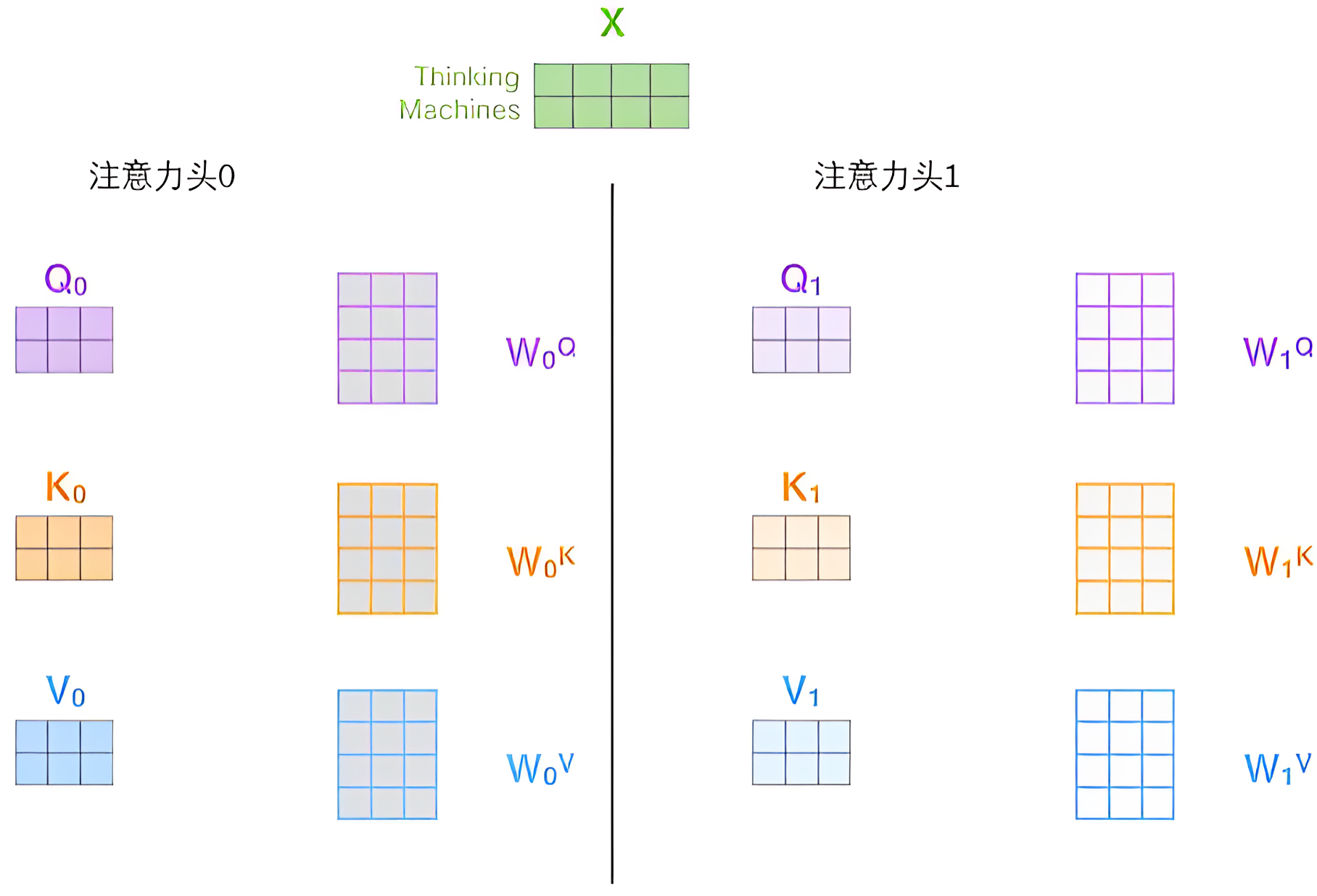
每个头都独立做上面自注意力机制的计算
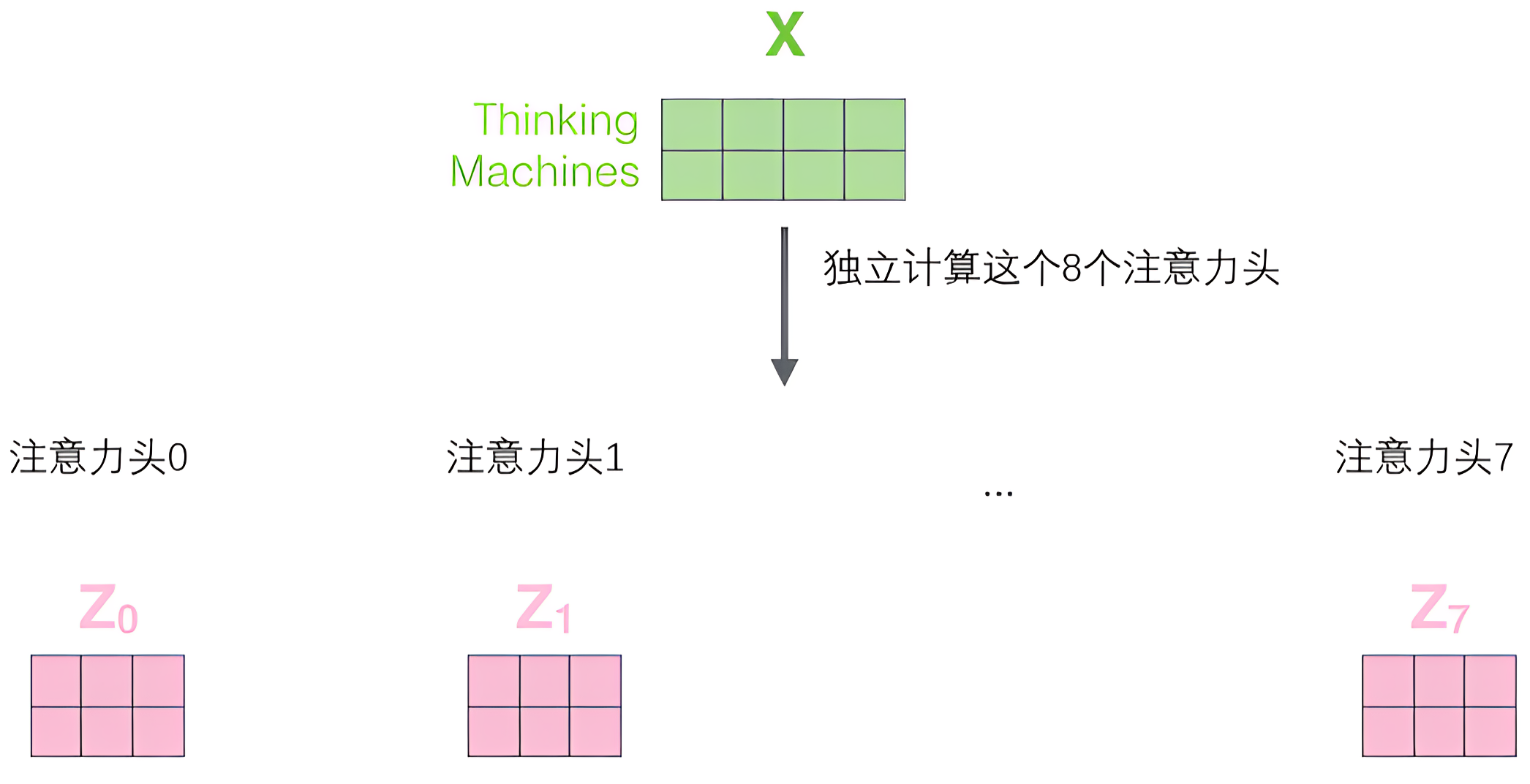
获取注意力头之后,我们无法直接传入前馈神经网络,我们需要将他拼接在一块,然后乘以一个权重矩阵,转变为与原输入词嵌入矩阵相同维度且融合了所有注意头的特征矩阵
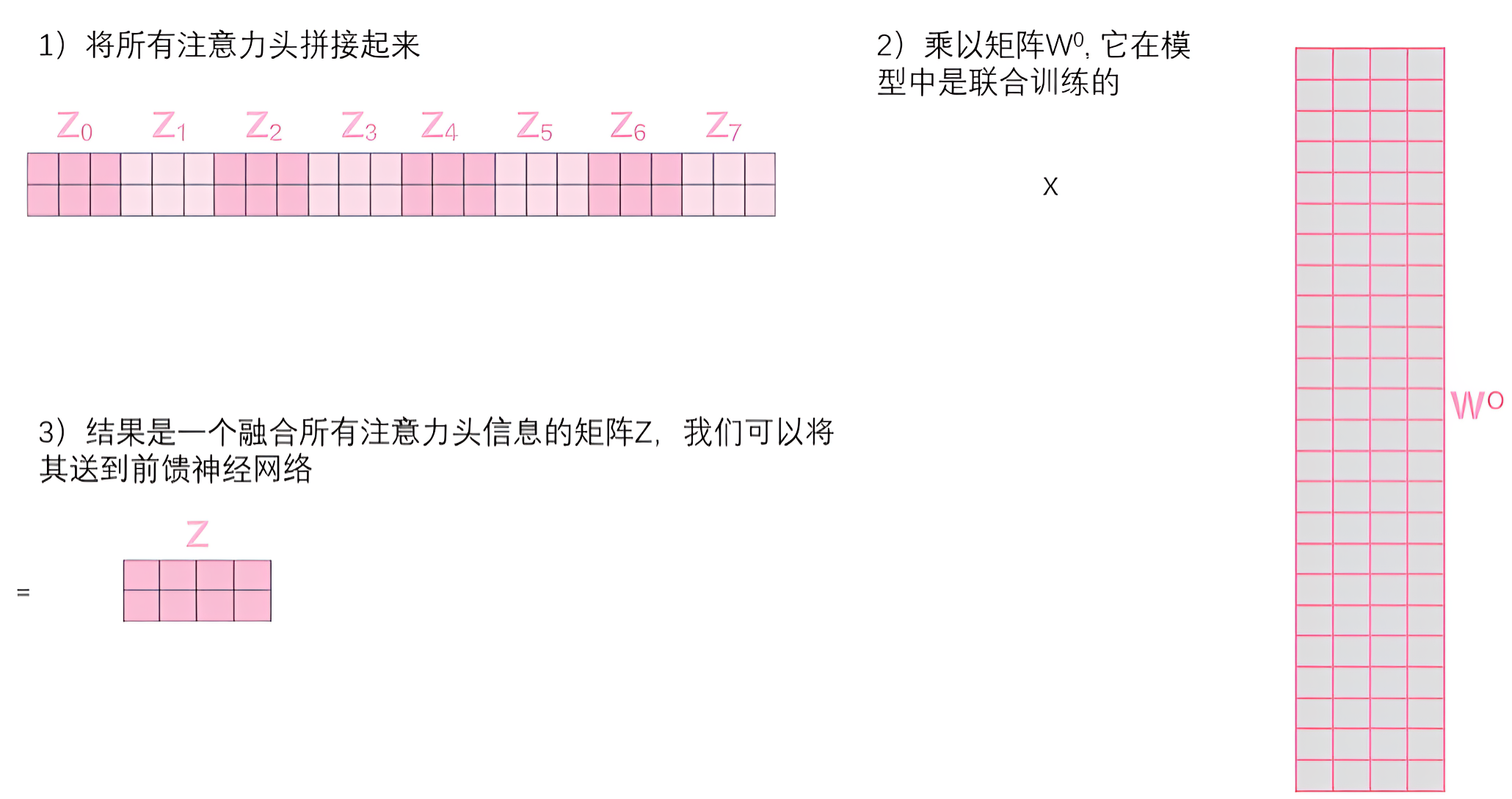
多头机制让模型可以同时关注不同方面的信息,如语法结构、语义关系等。
五、前馈网络与残差连接
前馈网络(Position-wise FFN)
每个位置独立应用相同的前馈网络:
这是一个两层的全连接网络,第一层全连接后relu激活后再接一个全连接输出
残差连接与层归一化
每个子层都采用残差连接相加后批归一化。
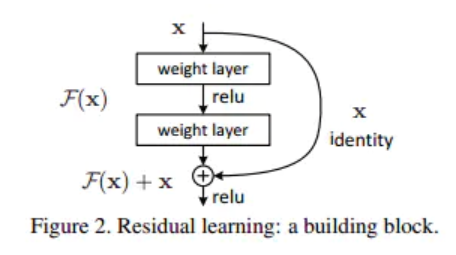
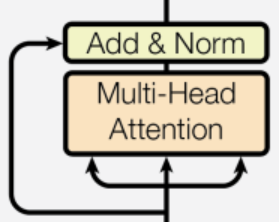
这种设计缓解了梯度消失问题,使深层网络的训练更加稳定。