做外贸电商网站营销型网站建设_做网站
我们以订单表为例实现 esProc SPL 数据外置,提速常规过滤及分组汇总计算。
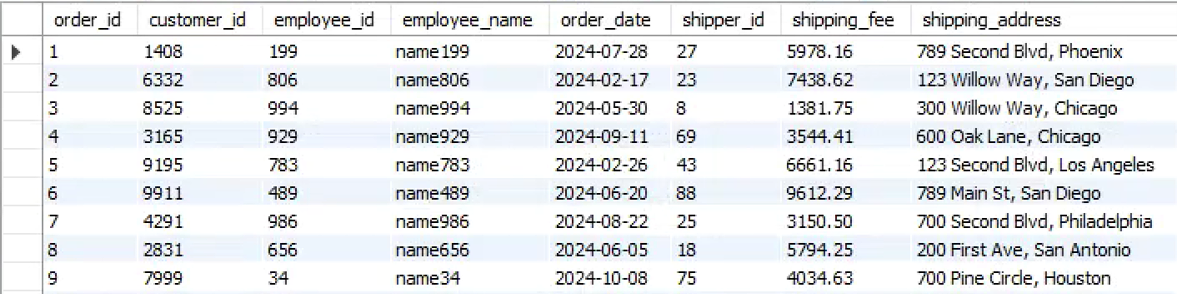
我们使用 SPL 的 ETL 工具来生成脚本,实现数据的转储。在 [SPL 安装目录]\esProc\bin 找到 dft.exe,运行后选择文件 - 新建 ETL。打开工具 - 数据连接:
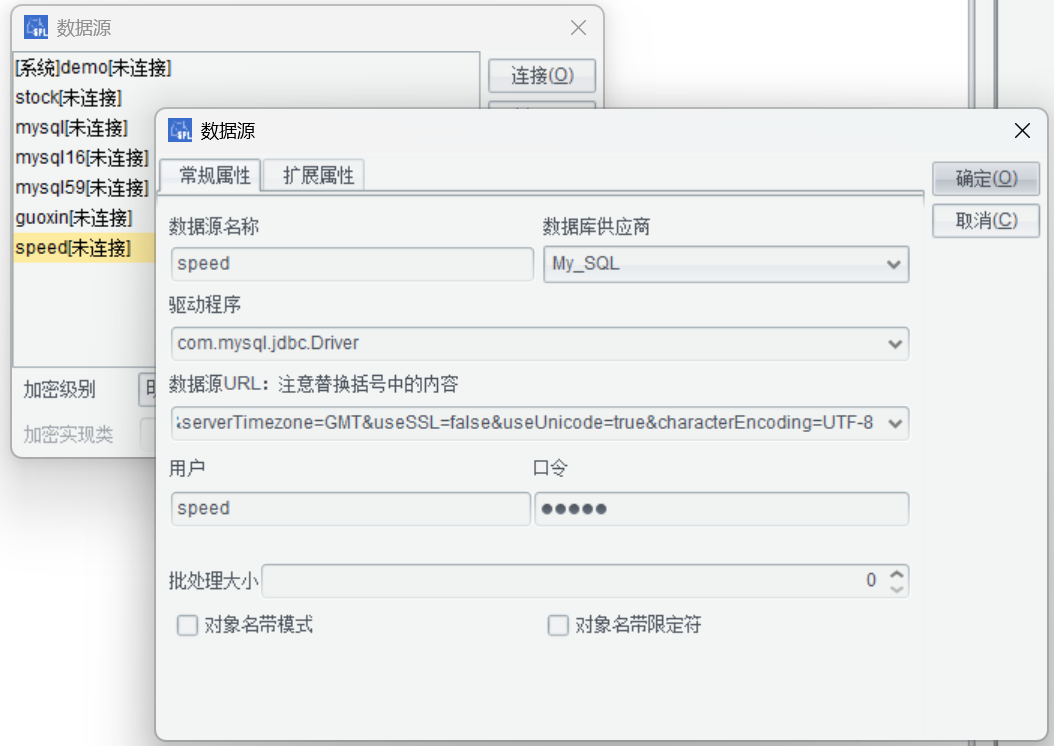
点击连接后,数据库的表可以拖拽到工作区:
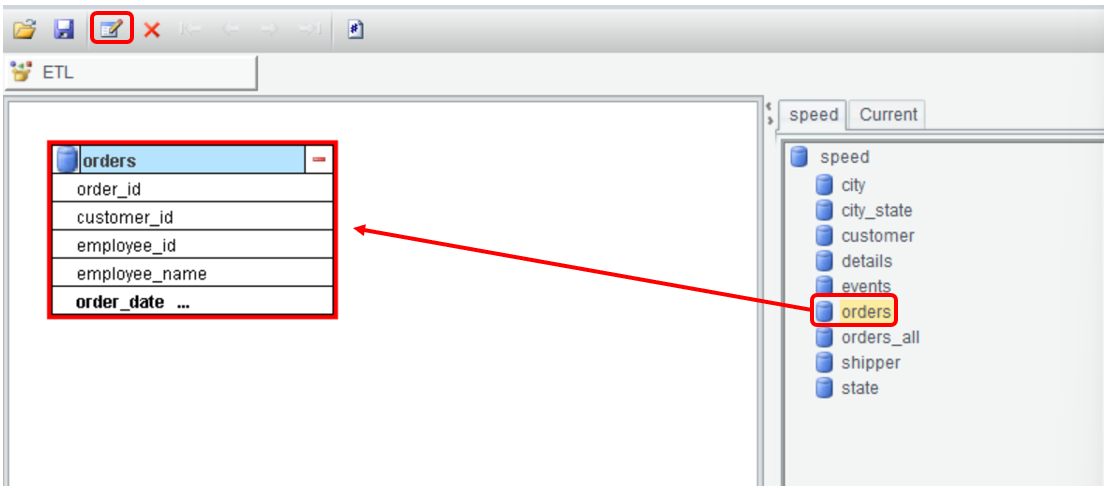
双击数据表或点击编辑按钮,设置导出选项:
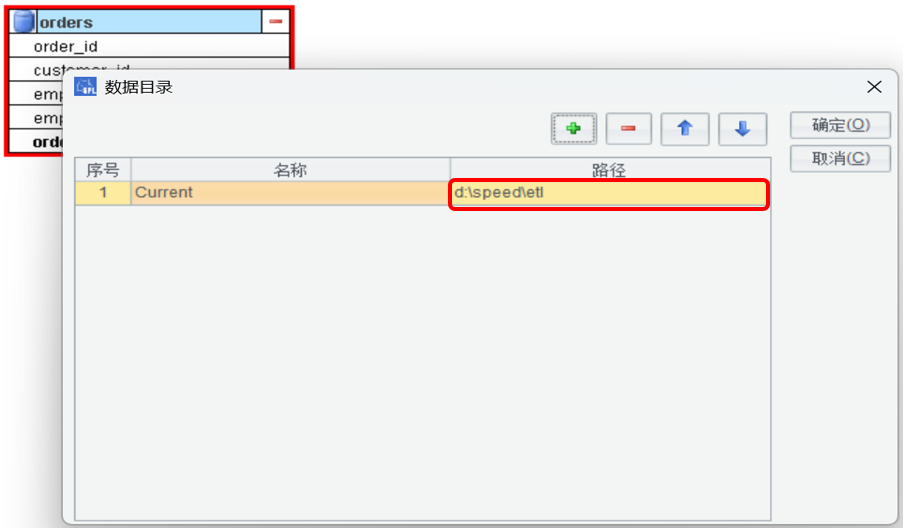
工具 - 数据目录,设置数据文件存储的目录。
工具 - 生成 SPLX 代码:
导出后,记得这次新建的 etl 保存成 Q1.etl 文件。
SPL 代码 2:导出的 SPL 代码,是从 MYSQL 数据库中导出数据,转储成集文件 BTX。
| A | |
| 1 | =connect("speed") |
| 2 | ="d:\\speed\\etl\\" |
| 3 | =A1.cursor("SELECT order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address FROM orders") |
| 4 | =file(A2+"orders.btx").export@b(A3) |
| 5 | =A1.close() |
例 1.1,按雇员分组统计运货费的 SQL 是这样:
select employee_id,count(*) as order_count,sum(shipping_fee) as total,avg(shipping_fee) as average,max(order_date) as latest_order_date
from orders
where order_date between '2024-01-01' and '2024-10-31'and shipper_id<>1 and shipping_fee > 10
group by
employee_id;执行这个 SQL 需要 11 秒
SPL 代码 3:
| A | |
| 1 | =now() |
| 2 | >sd=date("2024-01-01"),ed=date("2024-10-31") |
| 3 | =file("d:/speed/orders.btx").cursor@b(employee_id,shipper_id,shipping_fee,order_date) |
| 4 | =A3.select(order_date>=sd && order_date<=ed && shipper_id != 1 && shipping_fee > 10) |
| 5 | =A4.groups(employee_id; count(1):order_count, sum(shipping_fee):total_fee, avg(shipping_fee) : average_fee, max(order_date) : latest_order_date) |
| 6 | >output("query cost:"/interval@ms(A1,now())/"ms") |
订单表比较大不能全部读入内存,这里 A3 使用的是游标,是分批读入数据,边读边算的。 注意,游标只取出需要的字段,可以减少生成的对象,并减少内存占用,提高性能。
A4 中的 select 函数相当于 SQL 中的 WHERE 子句,用于过滤。
A5 则对过滤后的结果做分组,语法形式和 SQL 不同,但仔细看会发现涉及的要素都是一样的:分号前的部分是分组键,相当于 SQL 的 GROUP BY 部分,分号后是聚合值,相当于 SQL 中 SELECT 中的聚合运算。SPL 的分组会缺省将分组键和聚合值拼成结果集,不像 SQL 那样要在 SELECT 中把分组键再写一遍。
SPL 的执行时间是 2.2 秒。BTX 是行式存储,还不能最大程度发挥 SPL 的性能。
用 ETL 工具编辑 orders 表:
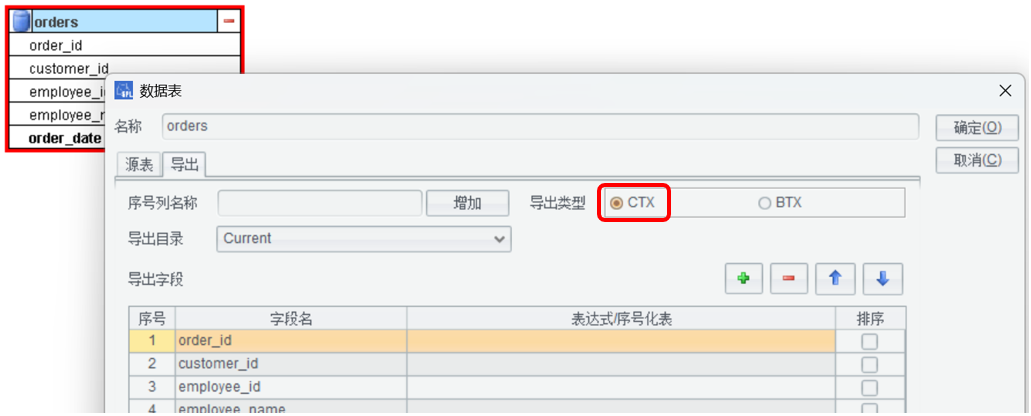
导出 SPL 代码 4:把数据转储成列存组表 CTX。
| A | |
| 1 | =connect("speed") |
| 2 | ="d:\\speed\\etl\\" |
| 3 | =A1.cursor("SELECT order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address FROM orders") |
| 4 | =file(A2+"orders.ctx").create@y(order_id,customer_id,employee_id,employee_name,order_date,shipper_id,shipping_fee,shipping_address).append(A3).close() |
| 5 | =A1.close() |
CTX 默认是列存,适合字段总数较多,而计算的时候用到字段比较少的情况。
CTX 创建时要指明数据结构,会比 BTX 略复杂些。
SPL 代码 5:用 CTX 计算例 1.1 的代码。
| A | |
| 1 | =now() |
| 2 | >sd=date("2024-01-01"),ed=date("2024-10-31") |
| 3 | =file("d:/speed/orders.ctx").open().cursor (employee_id,shipper_id,shipping_fee,order_date) |
| 4 | =A3.select(order_date>=sd && order_date<=ed && shipper_id != 1 && shipping_fee > 10) |
| 5 | =A4.groups(employee_id;count(1):order_count,sum(shipping_fee):total_fee,avg(shipping_fee):average_fee,max(order_date):latest_order_date) |
| 6 | >output("query cost:"/interval@ms(A1,now())/"ms") |
代码和 BTX 基本一样,只是 A3 产生游标的代码不同。CTX 需要先打开组表对象,然后建立游标。
执行时间是 1.9 秒,比 BTX 快。
接下来使用 CTX 游标过滤技术进一步提速:把过滤条件附加到游标上,SPL 先读出用于计算条件的字段值,如果条件不成立就放弃读取其他字段,条件成立才继续读出其它字段并创建这条记录。
这样可以减少硬盘读取,避免产生不必要的对象,提高性能。
SPL 代码 6:
| A | |
| 1 | =now() |
| 2 | >sd=date("2024-01-01"),ed=date("2024-10-31") |
| 3 | =file("d:/speed/orders.ctx").open().cursor(employee_id,shipping_fee,order_date; order_date>=sd && order_date<=ed && shipper_id != 1 && shipping_fee > 10) |
| 4 | =A4.groups(employee_id;count(1):order_count,sum(shipping_fee):total_fee,avg(shipping_fee):average_fee, max(order_date) : latest_order_date) |
| 5 | =output("query cost:"/interval@ms(A1,now())/"ms") |
A3 中的游标取数时,先读出 orders.ctx 的 order_date,shipper_id,shipper_fee 字段用于计算条件,如果条件不成立就放弃读取其他字段,如 employee_id。条件成立才继续读出其它需要的字段并创建这条记录。
游标过滤算法的执行时间是 1.8 秒。
继续用并行技术提高性能,SPL 能方便地写并行代码,只要配置一下并行数,和 CPU 核数一致即可,这里配置了 8 并行。
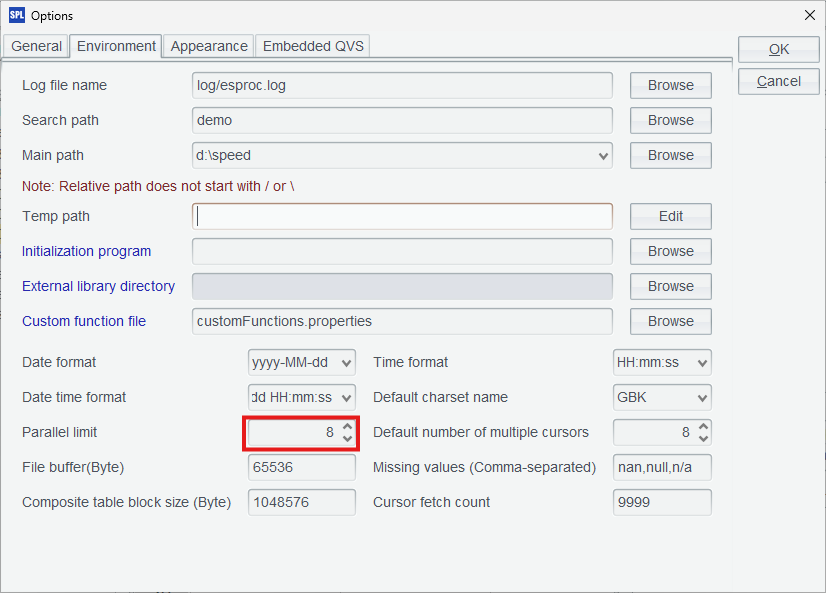
SPL 代码 7:BTX 上并行计算。
| A | |
| 1 | =now() |
| 2 | >sd=date("2024-01-01"),ed=date("2024-10-31") |
| 3 | =file("d:/speed/orders.btx").cursor@bm(employee_id,shipper_id,shipping_fee,order_date) |
| 4 | =A3.select(order_date>=sd && order_date<=ed && shipper_id != 1 && shipping_fee > 10) |
| 5 | =A4.groups(employee_id; count(1):order_count, sum(shipping_fee):total_fee, avg(shipping_fee) : average_fee, max(order_date) : latest_order_date) |
| 6 | >output("query cost:"/interval@ms(A1,now())/"ms") |
cursor 函数增加 m 选项就可以了,执行时间是 0.6 秒
SPL 代码 8:基于 CTX 并行计算。
| A | |
| 1 | =now() |
| 2 | >sd=date("2024-01-01"),ed=date("2024-10-31") |
| 3 | =file("d:/speed/orders.ctx").open().cursor@m(employee_id,shipping_fee,order_date; order_date>=sd && order_date<=ed && shipper_id != 1 && shipping_fee > 10) |
| 4 | =A4.groups(employee_id;count(1):order_count,sum(shipping_fee):total_fee,avg(shipping_fee):average_fee, max(order_date) : latest_order_date) |
| 5 | =output("query cost:"/interval@ms(A1,now())/"ms") |
也是给 cursor 函数增加 m 选项,执行时间是 0.5 秒
小结一下性能(单位 - 秒):
| MYSQL | BTX | CTX | |
| 串行 | 11 | 2.2 | 1.9 |
| 并行 | 11 | 0.6 | 0.5 |
MySQL 在并行方面似乎不够好,设置了并行参数后,性能也没显著提升。这不是本文的关注重点,也就不深究了。
后续的测试未加说明都是指 8 线程并行。
需要注意的是,SPL 文件存储有其特定的适用场景。因为要导出数据,所以更适合计算不变的历史数据,其实这种场景就很多了。
请动手练习一下:
1、按客户分组统计运货费,过滤条件要有 order_date 和 employee_id。
2、从自己熟悉的测试数据库中导出较大的表,生成 BTX、CTX,尝试前面讲到的计算。