机器学习19:自监督式学习在语音和影像上的运用
摘要
本讲系统介绍了自监督式学习在语音和影像领域的应用方法与技术进展。首先回顾了文本自监督学习的基本框架,进而重点讲解了语音与影像数据上的自监督预训练策略,包括生成式方法(如语音BERT、GPT)、预测式方法(如图像旋转预测、上下文预测)以及对比学习(如CPC、Wav2vec系列)等关键技术。此外,课程还介绍了无需负样本的Bootstrapping方法与引入正则化的VICReg等先进学习范式,全面展示了自监督学习在多模态数据上的强大适应性与泛化能力。
Abstract
This lecture systematically introduces the application methods and technical progress of self-supervised learning in the fields of speech and vision. The course begins by reviewing the basic framework of text-based self-supervised learning, then focuses on self-supervised pre-training strategies for speech and image data, covering key techniques such as generative approaches (e.g., speech BERT and GPT), predictive approaches (e.g., image rotation prediction, context prediction), and contrastive learning (e.g., CPC, Wav2vec series). Furthermore, the course introduces advanced learning paradigms like Bootstrapping (which avoids negative samples) and regularization-based methods such as VICReg, comprehensively demonstrating the strong adaptability and generalization capability of self-supervised learning across multimodal data.
一.回顾文本自监督式学习
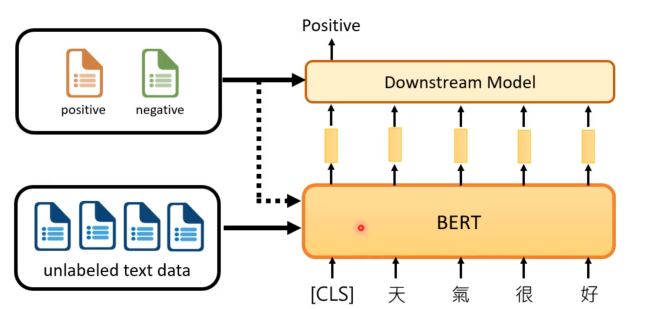
前面学习了自监督模式如何在文字上的运用。这里简单的回顾下BERT,其训练资料是没有标签的文字资料。运行时是接收一段文字,然后输出一排向量,其中文字中每一个token都对应一个向量,假如现在要做的是情绪分析,则就还要去收集些有标注正负面的文章资料,通过这些资料来训练另外一个模型,来接收BERT输出的向量,通过这些向量来判断这段文字的情绪。当然除了用上面的情绪标签资料来训练额外的模型外,也会将其用来微调BERT,以便BERT适应不同的任务。
二.语音和影像自监督式学习
本次学习主要是看怎么将自监督是学习用在语音或影像上,这里先以语音为例。
1.语音
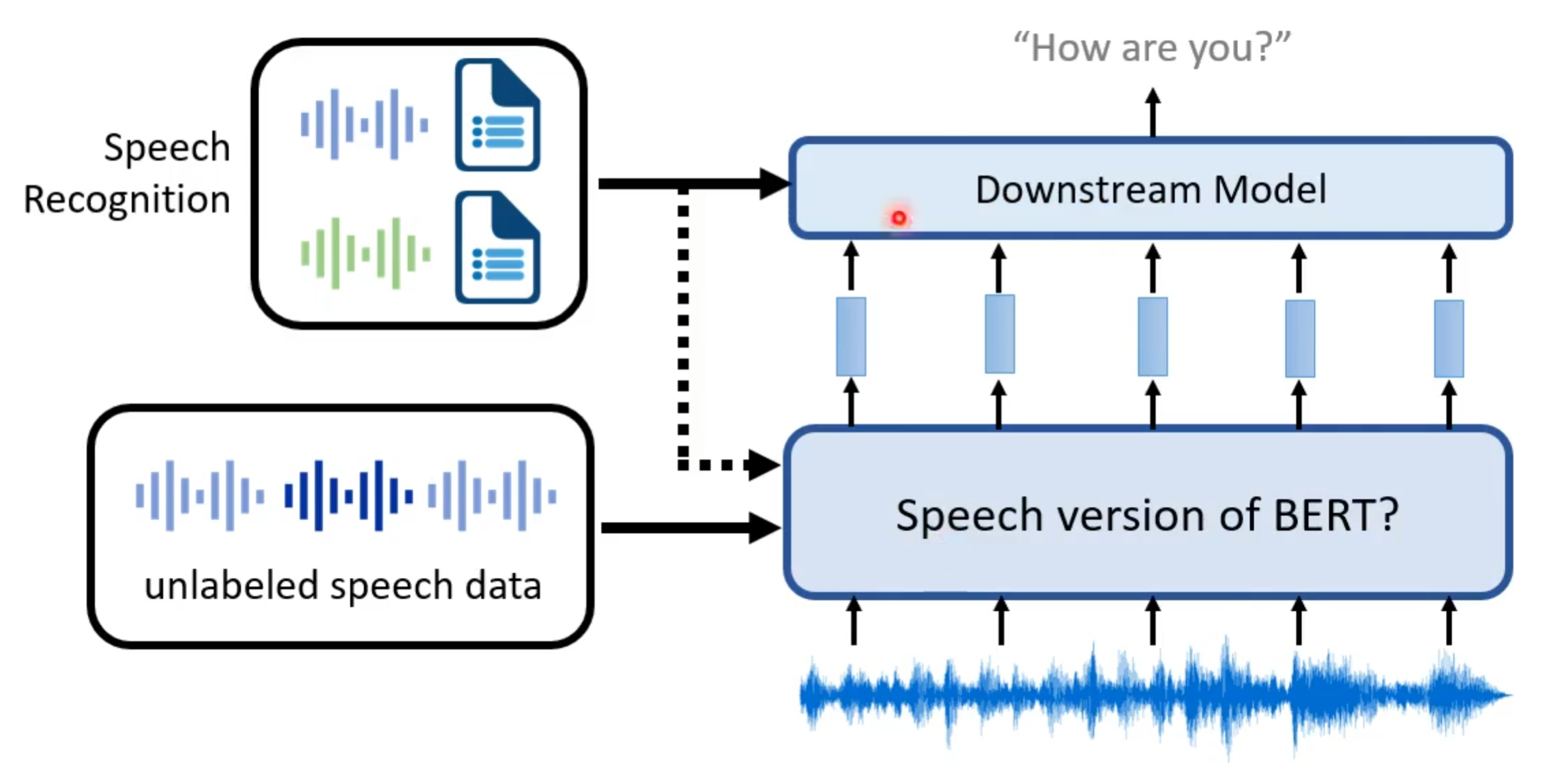
从大框架上来看,将自