【016】Dubbo3从0到1系列之时间轮
文章目录
- 时间轮
- 7.2 ⏱️时间轮
- 7.2.1 时间轮的原优势
- 7.2.2 Dubbo3中的时间轮的核心实现
- 7.2.3 时间轮原理简述(以 Dubbo/Netty 实现为例)
- 7.2.4 任务调度
- 7.2.5 多级时间轮
- 7.2.6 时间轮的原理
时间轮
7.2 ⏱️时间轮
在 Dubbo 3 中,为了高效处理大量定时任务(如心跳检测、超时重试、连接管理等),引入了时间轮(Timing Wheel)机制作为其内部定时任务调度的核心实现。时间轮是一种高性能、低开销的定时任务调度算法,特别适合处理大量短周期、低延迟精度要求的定时任务。
7.2.1 时间轮的原优势
- O(1) 时间复杂度 的任务调度(理想情况下);
- 内存友好,适合高频、短周期任务;
- 天然支持任务分组与批量处理;
- 与 Netty 的时间轮设计思想一致(Dubbo 底层依赖 Netty)
7.2.2 Dubbo3中的时间轮的核心实现
-
Dubbo 3 的时间轮实现在
dubbo-common模块中,核心类为:- HashedWheelTimer:时间轮调度器(直接复用或借鉴了 Netty 的 HashedWheelTimer 实现);
- Timeout/TimerTask:任务抽象;
💡 实际上,Dubbo 并未完全重写时间轮,而是基于 Netty 的
HashedWheelTimer进行封装和适配,以保持与网络层的一致性。
7.2.3 时间轮原理简述(以 Dubbo/Netty 实现为例)
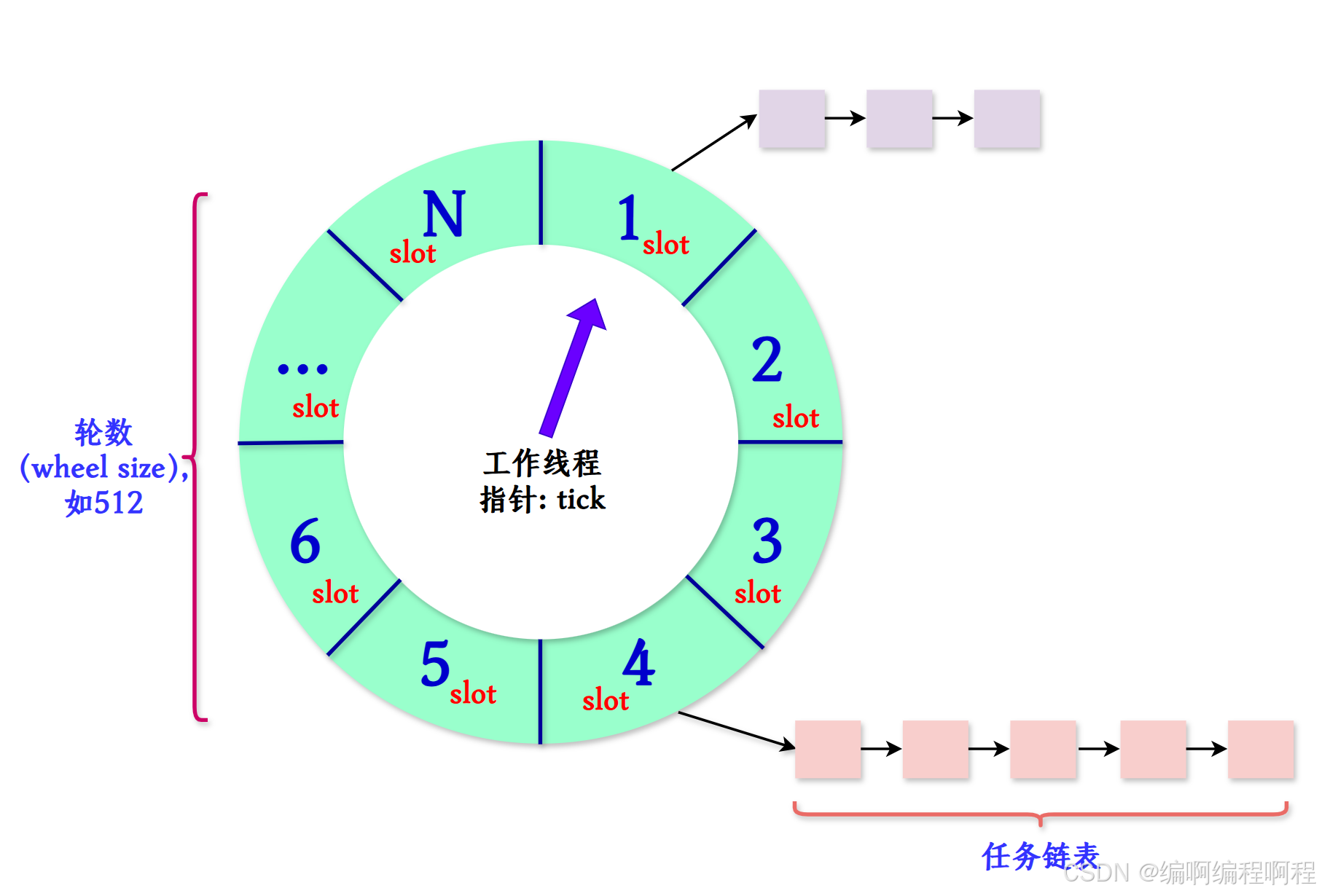
✅ 1. 数据结构
- 一个环形数组(bucket array),每个槽(slot)是一个任务链表;
- 一个工作线程(worker thread) 不断转动“指针”(tick);
- 一个精度单位(tickDuration),如 100ms;
- 一个轮数(wheel size),如 512。
例如:
- tickDuration = 100ms
- wheelSize = 512
- 则时间轮最大支持定时:
100ms × 512 = 51.2秒
超过最大时间的任务会通过“多轮”机制处理(类似多级时间轮)。
7.2.4 任务调度
- 用户提交一个延迟任务(如 250ms 后执行);
- 计算目标槽位:slot = (currentTick + delay / tickDuration) % wheelSize;
- 将任务加入对应 slot 的链表;
- 工作线程每
tickDuration转动一次,处理当前 slot 中所有到期任务; - 若任务未到期(因延迟过长),则重新计算并放入下一轮。
7.2.5 多级时间轮
对于超长时间任务(如几分钟),Dubbo/Netty 的 HashedWheelTimer 采用“降级到普通延迟队列”或“任务重调度”策略,而非实现多级时间轮(如 Kafka 的 Hierarchical Timing Wheels)。
7.2.6 时间轮的原理
HashedWheelTimer 是 Timer 接口的实现,它通过时间轮算法实现了一个定时器。HashedWheelTimer 会根据当前时间轮指针选定对应的槽(HashedWheelBucket),从双向链表的头部开始迭代,对每个定时任务(HashedWheelTimeout)进行计算,属于当前时钟周期则取出运行,不属于则将其剩余的时钟周期数减一操作。
时间轮对外提供了一个 newTimeout() 接口用于提交定时任务,在定时任务进入到 timeouts 队列之前会先调用 start() 方法启动时间轮,其中会完成下面两个关键步骤:
- 确定时间轮的 startTime 字段
- 启动 workerThread 线程,开始执行 worker 任务。
之后根据 startTime 计算该定时任务的 deadline 字段,最后才能将定时任务封装成 HashedWheelTimeout 并添加到 timeouts 队列。
分析时间轮指针一次转动的全流程:
- 时间轮指针转动,时间轮周期开始
- 清理用户主动取消的定时任务,这些定时任务在用户取消时,会记录到
cancelledTimeouts队列中。在每次指针转动的时候,时间轮都会清理该队列。- 将缓存在 timeouts 队列中的定时任务转移到时间轮中对应的槽中
- 根据当前指针定位对应槽,处理该槽位的双向链表中的定时任务
- 检测时间轮的状态。
- 如果时间轮处于运行状态,则循环执行上述步骤,不断执行定时任务。
- 如果时间轮处于停止状态,则执行下面的步骤获取到未被执行的定时任务并加入 unprocessedTimeouts 队列:
- 遍历时间轮中每个槽位,并调用 clearTimeouts() 方法;
- 对 timeouts 队列中未被加入槽中循环调用 poll()。
- 最后再次清理 cancelledTimeouts 队列中用户主动取消的定时任务。
✅ 1. 基本配置和状态管理
INSTANCE_COUNTER: // 用于统计HashedWheelTimer实例的数量,防止创建过多实例
WARNED_TOO_MANY_INSTANCES: // 标记是否已经警告过实例数量过多
INSTANCE_COUNT_LIMIT: // 实例数量限制,默认为64
WORKER_STATE_UPDATER: // 使用原子更新器管理workerState状态
workerState: // 工作线程状态(初始化、已启动、已关闭)
✅ 2. 时间轮核心数据结构
// 每个tick的持续时间(纳秒),决定了时间轮的精度
private final long tickDuration; // 时间轮的桶数组,存储HashedWheelBucket对象
private final HashedWheelBucket[] wheel;// 用于计算时间轮索引的掩码,值为wheel.length - 1
private final int mask;// 执行时间轮任务的工作线程
private final Worker worker = new Worker();// workerThread: 工作线程的实际线程对象
private final Thread workerThread;
✅ 3. 同步和队列管理
startTimeInitialized: // 倒计时锁存器,用于等待工作线程初始化开始时间
timeouts: // 存储待处理的超时任务队列
cancelledTimeouts: // 存储已取消的超时任务队列
pendingTimeouts: // 统计待处理的超时任务数量
maxPendingTimeouts: // 最大允许的待处理超时任务数量限制
✅ 4. 时间管理
startTime: // 时间轮开始时间(纳秒),用于计算相对时间
tick: // 当前的tick计数,表示已经经过的tick数量
✅ 5. 系统相关
IS_OS_WINDOWS: // 标识当前操作系统是否为Windows,用于调整睡眠时间精度