数据库服务器主机重启故障诊断分析
一、故障现象:
告警日志:
Sun Feb 09 14:18:42 2020
Auto-tuning: Shutting down background process GTX2
Sun Feb 09 15:06:00 2020
NOTE: ASMB terminating
Errors in file /opt/oracle/app/diag/rdbms/xxxx/xxxx1/trace/xxxx1_asmb_7463.trc:
ORA-15064: communication failure with ASM instance
ORA-03113: end-of-file on communication channel
Process ID:
Session ID: 68 Serial number: 5
Errors in file /opt/oracle/app/diag/rdbms/xxxx/xxxx1/trace/xxxx1_asmb_7463.trc:
Errors in file /opt/oracle/app/diag/rdbms/xxxx/xxxx1/trace/xxxx1_asmb_7463.trc:
ORA-15064: communication failure with ASM instance
ORA-03113: end-of-file on communication channel
Process ID:
Session ID: 68 Serial number: 5
ASMB (ospid: 7463): terminating the instance due to error 15064
Termination issued to instance processes. Waiting for the processes to exit
Sun Feb 09 15:06:11 2020
Instance termination failed to kill one or more processes
Instance terminated by ASMB, pid = 7463
Sun Feb 09 15:12:24 2020
Starting ORACLE instance (normal)
************************ Large Pages Information *******************
Per process system memlock (soft) limit = UNLIMITED
Total Shared Global Region in Large Pages = 0 KB (0%)
Large Pages used by this instance: 0 (0 KB)
Large Pages unused system wide = 0 (0 KB)
Large Pages configured system wide = 0 (0 KB)
Large Page size = 2048 KB
RECOMMENDATION:
Total System Global Area size is 24 GB. For optimal performance,
prior to the next instance restart:
1. Increase the number of unused large pages by
at least 12289 (page size 2048 KB, total size 24 GB) system wide to
get 100% of the System Global Area allocated with large pages
********************************************************************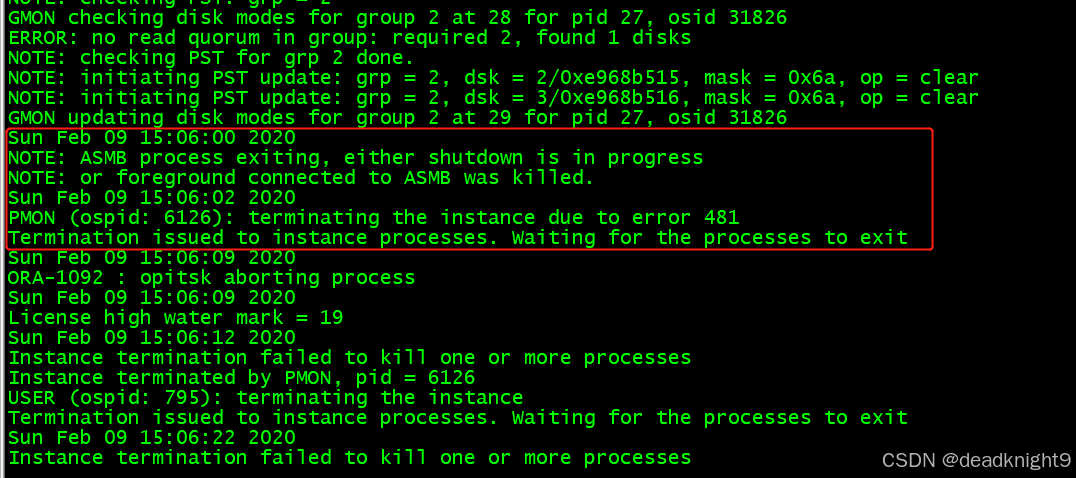
从数据库告警日志可以发现,核心进程asmb 在2.9日15.06分 突然提示正在终止,随后一节点数据库报错,不能与 ASM通信, 也就是连不上 ASM存储,检查ASM告警日志发现,核心进程ASMB 在2.9日15.06分 被kill 掉,随后一节点的ASM实例挂掉,导致一节点数据库也紧跟着挂掉。
二、故障原因
从15:03开始

一节点开始报 voting file所在的磁盘,IO通信有超时的现象,磁盘hang住, 到15.05分开始 ocr_vote磁盘离线,一节点被剔出集群,

后续检查主机,发现主机重启过,检查操作系统日志,发现从15.02分开始,: INFO: task ocssd.bin:16080 blocked for more than 120 seconds. 有任务被hung 住,
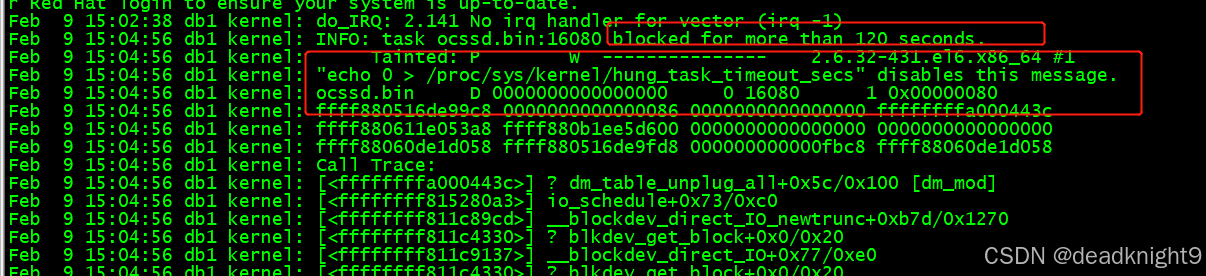
该错误是由于IO子系统的处理速度不够快,不能在120秒将缓存中的数据全部写入磁盘。IO系统响应缓慢,导致越来越多的请求堆积,最终IO 耗尽,系统内存全部被占用,导致系统失去响应,发生故障。
三、故障解决
建议一:
可以调整 操作系统参数,
vm.dirty_ratio=20
vm.dirty_background_ratio=3
目前操作系统配置文件/etc/sysctl.conf
中 没有这两个参数 ,建议调整,sysctl -p 生效,(调整该操作系统参数不用重启主机)
vm.dirty_background_ratio 这个参数指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如5%)就会触发pdflush/flush/kdmflush等后台 回写进程运行,将一定缓存的脏页异步地刷入外存;
操作系统参数说明:
vm.dirty_ratio 这个参数则指定了当文件系统缓存脏页数量达到系统内存百分之多少时(如10%),系统不得不开始处理缓存脏页(因为此时脏页数量已经比较多,为了避免数据丢失需要将一定脏页刷入外存);在此过程中很多应用进程可能会因为系统转而处理文件IO而阻塞。
vm.dirty_background_ratio 默认为10
所有全局系统进程的脏页数量达到系统总内存的多大比例后,就会触发pdflush/flush/kdmflush等后台回写进程运行。
将vm.dirty_background_ratio设置为5-10,将vm.dirty_ratio设置为它的两倍左右,以确保能持续将脏数据刷新到磁盘,避免瞬间I/O写,产生严重等待(和MySQL中的innodb_max_dirty_pages_pct类似)
vm.dirty_ratio 默认为20
单个进程的脏页数量达到系统总内存的多大比例后,就会触发pdflush/flush/kdmflush等后台回写进程运行。
建议二:
另外在检查中,发现该主机未配置大页,建议配置大页,可以极大提升数据库性能
后期调整后至今没有发现主机重启,故障解决。